

Unity云原生分布式运行优化方案
vr|ar|虚拟现实
描述
元宇宙时代的来临对实时3D引擎提出了诸多要求,Unity作为游戏行业应用最广泛的3D实时内容创作引擎,为应对这些新挑战,提出了Unity云原生分布式运行时的解决方案。LiveVideoStack 2023上海站邀请到Unity中国的解决方案工程师舒润萱,和大家分享该方案的实践案例、面临的问题、解决方式,并介绍了Unity目前对其他方案的构想。
文/舒润萱
大家好,我叫舒润萱,现在在Unity中国担任解决方案工程师,主要负责开发的项目是Unity云原生分布式运行时。
首先介绍一下Unity。Unity是游戏行业应用最广泛的3D实时内容创作引擎。截止2021年第4季度,70%以上移动平台的游戏是使用Unity开发的。
但Unity不止是一个游戏引擎,Unity的业务目前涉及到汽车行业、建筑行业、航空航天行业、能源行业等等各行各业。
Unity的业务在全球都有开展,在18个国家有54个办公室。在中国,在上海、北京、广州都有办公室,在临港也开了一间新的办公室。
Unity覆盖的平台是最广泛的,它支持超过20个主流平台,率先支持了Apple新发布的vision OS。

我今天的分享将从这六个方面进行。
-01-
元宇宙时代的挑战
首先,实时3D引擎在元宇宙时代会遇到什么挑战?

Unity认为元宇宙会是下一代的互联网,它将是实时的3D的、交互的、社交性的,并且是持久的。

元宇宙会是一个规模庞大的虚拟世界,这个虚拟世界里有很多参与者,它将会是一个大量用户实时交互的场景。同时,元宇宙它必须是一个持续稳定的虚拟世界。
参与者在这个虚拟世界里对它进行的改变将会随着时间保留下来,并且它是稳定的状态。这就对实时3D交互造成了很多挑战。

首先,因为这个虚拟世界将会是一个大规模的高清世界,里面将会有数量庞大的动态元素、静态元素,所以它对实时3D引擎提出了渲染的挑战。
其次,它伴随着大量的网络传输,对引擎的可扩展性和可伸缩性提出了很高要求,所以对运行平台来说也是一个不小的挑战。
最后,因为这个虚拟世界会有超大规模的物理仿真,用户将会在其中进行大量的实时交互,所以这对运算资源也是一个巨大的挑战。
-02-
Unity分布式运行时
为了应对这些挑战,Unity提出了分布式运行时的解决方案。

这个方案由两部分组成,第一个部分是Unity云原生的分布式渲染,第二个部分是Unity云原生分布式计算。
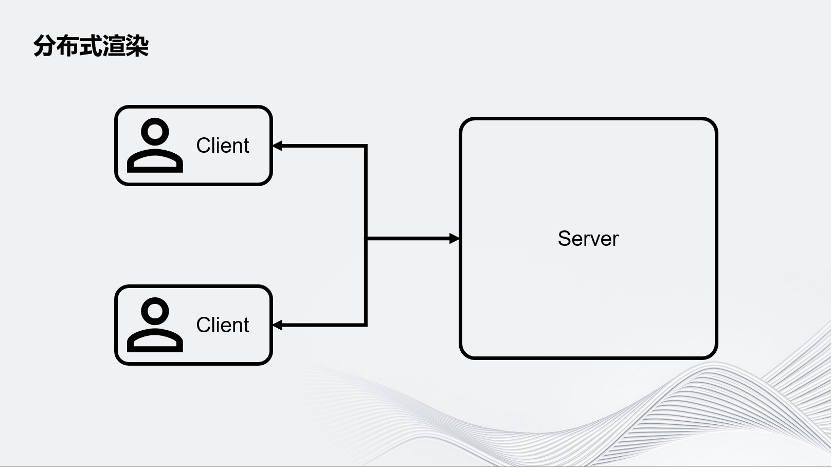
首先介绍分布式渲染。要做一个多人联网的体验,可以从最简单的Server-Client架构入手。如图所示,在这个架构中有一个中心化的Server,它可以服务于多个Client。这张图上画了两个Client,这是最简单的架构。
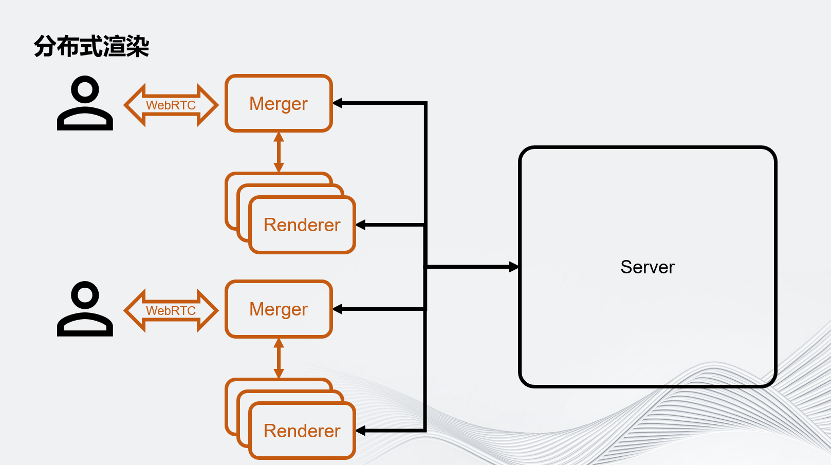
为了对应大规模的渲染压力,Unity把用户的Client端拆成了Merger和Renderer。在这里面,一个Merger对应多个Renderer,这些Renderer将会负责虚拟世界的渲染。我们把一帧的渲染任务拆分成很多个子任务,分别交给这些Render进行。Merger负责把Renderer渲染的画面组合成最终画面,之后通过WebRTC推流的方案推给用户的客户端。要注意,这里除了用户的客户端以外,所有的环境都是运行在云上的。
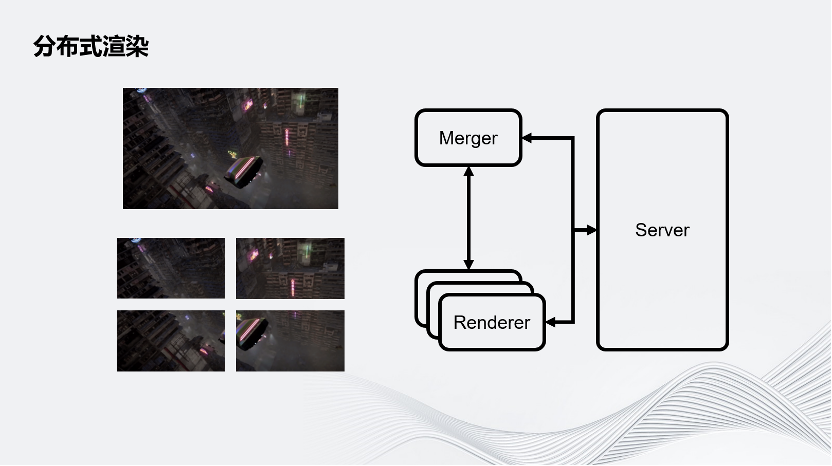
图示为一个最简单的屏幕空间拆分,即把一个完整的画面在屏幕空间上拆成几个部分。除此之外还有其他拆分方式,例如通过时间拆分:假设有4个Renderer,第一个Renderer渲染第一帧,第二个Renderer渲染第二帧,第三个Renderer渲染第三帧……以此类推,再把它们组合成一个完整的序列。
Unity现在也在实验一个新的拆分方式:在Merger上渲染一个比较高清的近景,再把远景拆分到几个Renderer上。Renderer的几个画面可以组成一个天空盒推到Merger上,这样Merger就可以同时拥有细节比较丰富的近景和远景。Unity的架构允许开发者根据自己的业务需求定义自己画面的拆分方式。
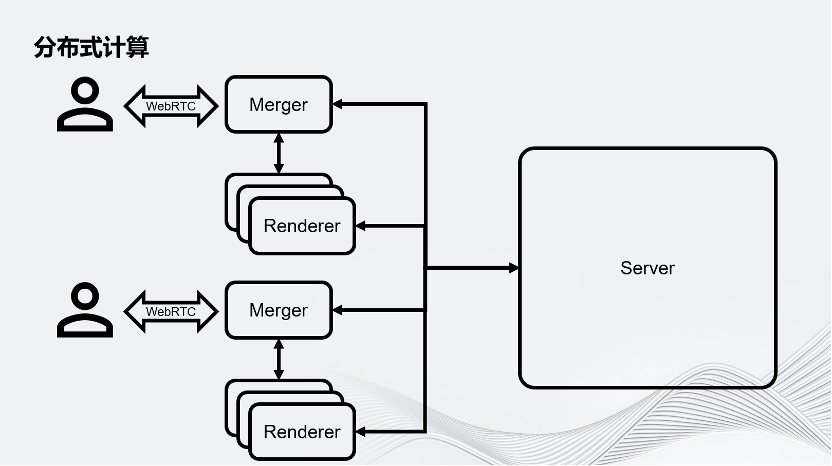
回到这个架构图,想象在一个大型的虚拟世界里,有成千上万用户连入运行时,通过分布式渲染,把原本一个进程服务对应一个用户的场景,拆分成好几个进程服务于一个用户,因此这个场景就会对Server提出巨大的挑战。为了应对这个挑战,Unity提出了分布式计算。
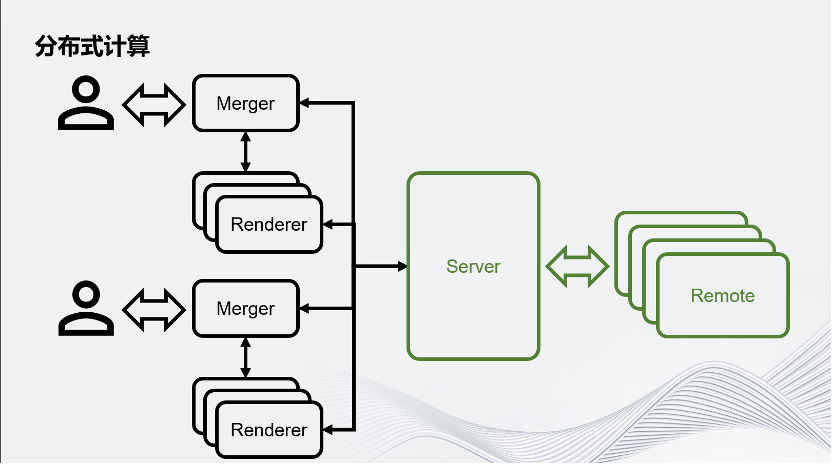
这种分布式计算把Server拆分成了Server和Remote,用 Remote分担Server的一些运算压力。
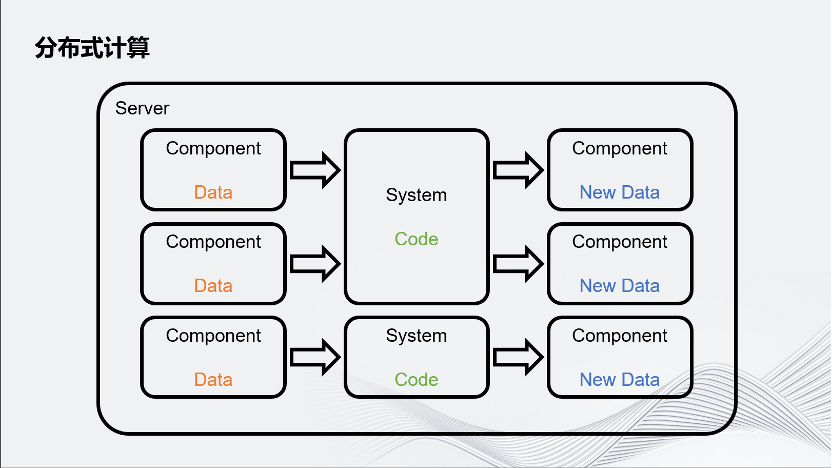
简要概述一下Unity是怎样把计算任务分配给Remote的。Unity游戏的业务流程可以简单拆分成数据和数据处理器,数据叫做Component,数据处理器实际上就是业务逻辑,代码叫System。每个System有自己感兴趣的数据,它会读取这个感兴趣的数据,通过逻辑进行数据更新。
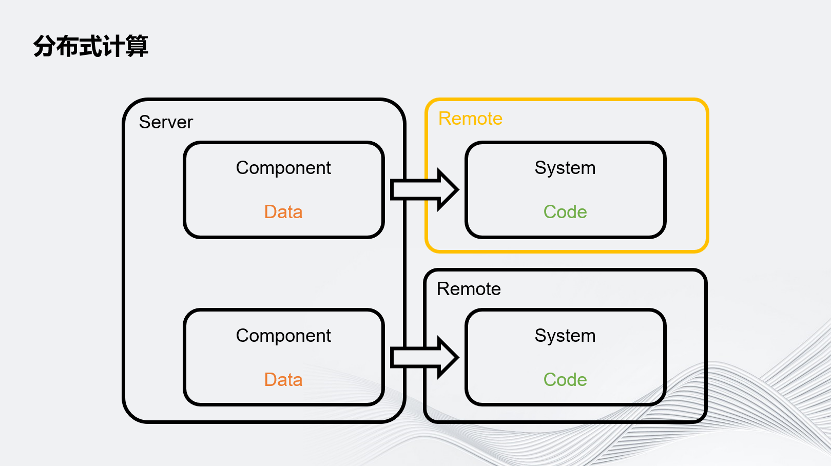
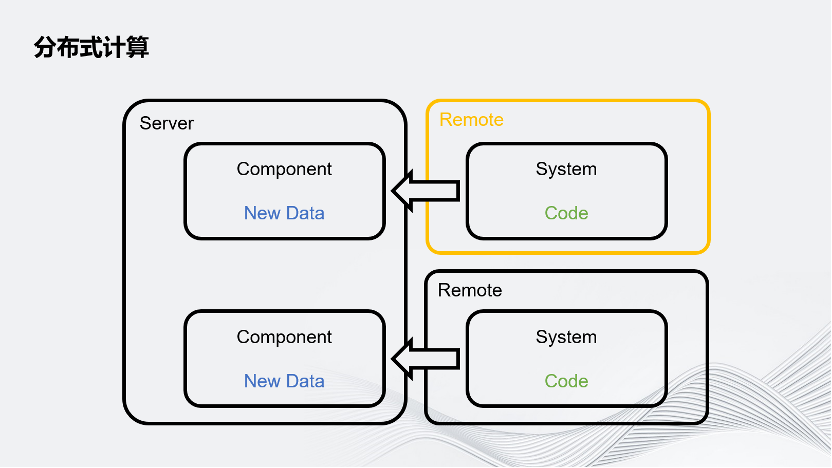
Unity把这个System跑在远程的机器上,而不是本地,之后把它感兴趣的数据通过网络发送给远程的机器,它就可以像本地处理一样处理这个数据,再把更新的数据通过网络发回给Server。
视频编解码与实时渲染
下面进入今天的正题,视频编解码与实时渲染。
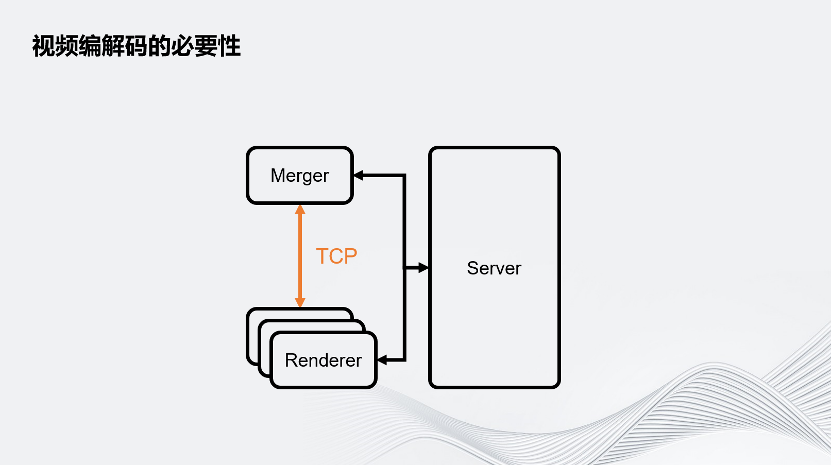
为什么要在分布式渲染中引入视频编解码?
可以看这个简化的分布式渲染架构图。Merger和Renderer之间的通信是通过网络TCP传输的,即图像是通过TCP传输的。

这个做法有两个问题:
一是会遇到网络带宽瓶颈,在实时3D交互的场景下,一般至少要Target到1080p60帧。而如果传的是8 bits RGBA的图像格式,需要的带宽是4Gbps,远远超出了常见的千兆带宽1 Gbps,很多机房没有办法接受。即使对Raw Data进行YUV420的简单压缩,它也要占用约1.6 Gbps的带宽,超过了千兆。
其次是性能问题。因为Unity的画面是从GPU渲染出来的,为了通过网络传输这个画面,要先把GPU显存上的图像数据先回传到CPU端。这个回读就会导致需要暂停渲染的流水线,因为目前Unity优化较好的实时3D引擎的渲染都是流水线形式的,即CPU产生场景数据,再把这个场景数据交给GPU渲染,同时CPU可以进行下一帧的计算。但是如果数据是反过来从GPU回到CPU,意味着需要把流水线暂停,包括GPU、CPU上的所有任务都要等待回读完成之后才能继续工作。
这里截取了一张Unity的回读指令,它消耗的时间是7.22毫秒,在实时交互的场景下,希望做到的是60帧的体验,即16毫秒,因此用7.22毫秒的时间把这张图片读回来是无法接受的。
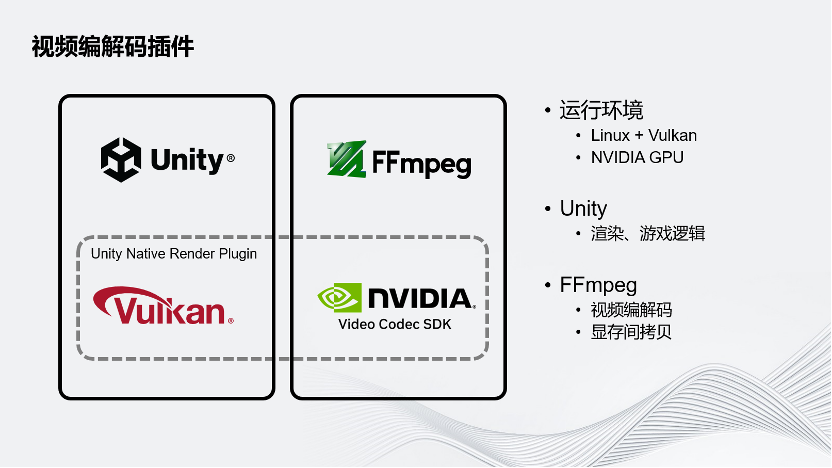
为了解决这两个问题,Unity为分布式渲染的方案开发了Unity Native Render Plugin。Unity的目标运行环境是云端,Linux和Vulkan的图形API。云端一般配备的是NVIDIA GPU,希望采用NVIDIA GPU进行硬件的视频编解码。在这个方案下面,Unity还是负责虚拟世界的渲染和逻辑。FFmpeg负责视频的编解码以及把Unity的图像在显存内部拷贝给NVIDIA的Video Codec SDK,Unity的插件就是连接这两个部分以实现目标。
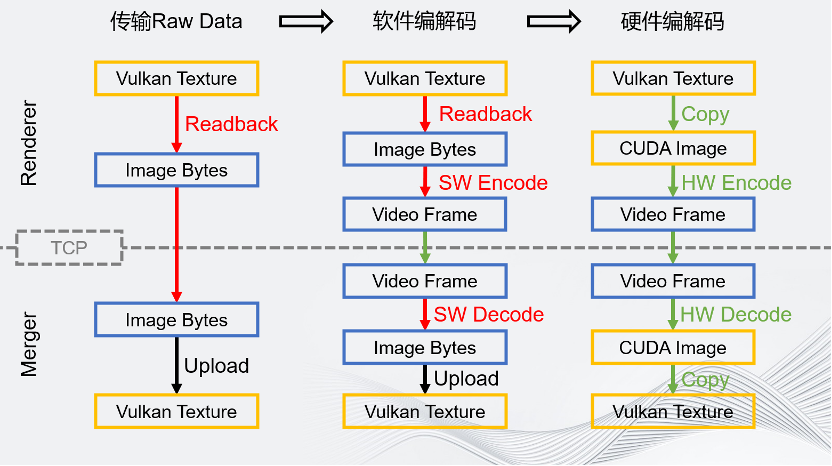
这几个流程图展示了Unity一定要硬件编解码的原因。橙色的框为显存上的数据,蓝色的框为CPU端内存上的数据。
最左边的流程图是最简单的。如果要传输一个Raw Data的方案,在GPU上把图像渲染完成之后,要通过回读把它读到CPU端,这是非常耗时的操作。在读完这个图像之后,把它通过TCP发送给Merger,占用带宽非常大,这是不可接受的。
如果引入的是一个软件编解码的场景,需要图像的数据在CPU端存在。所以回读还是无法避免,操作仍然十分耗时。在软件编解码时进行的编码和解码操作,同样非常耗时。虽然这对视频来说没问题,但是对于60帧的实时场景是不太能接受的。但是这个方案的带宽其实优化了很多,因为视频码率至少比4 Gbps、1.5 Gbps好很多。这是软件面板的情况,它最多只是优化了带宽。
最后是硬件编解码。硬件编解码是在渲染完成之后,通过显存间的拷贝,把渲染的结果拷贝到Media的CUDA端,然后做硬件编码和硬件解码。虽然是一次拷贝,但是因为是在一张显卡的显存上,所以拷贝过程非常快。硬件编码完成之后,视频帧数据会自动回到CPU端。虽然其本质上也是一次回读,但是它和流水线无关,相当于是在另一条线上完成的,所以这个回读消耗的只有从PCIE到CPU到内存的带宽的速度,回读的不是一个完整的图像,而是压缩好的视频帧,它的数据量也大大减小,所以回读非常快。之后通过TCP发送视频帧,带宽非常小,在Merger端解码上传的Buffer也比原来小,解码也很快。最后把解码完成后的Image,Copy 到Vulkan Texture,这也是在同一块GPU内显存里的操作。
可以看到,硬件编解码的流程优化了很多,每一步都能得到很高的提升。

介绍一下Unity是怎样配置FFmpeg的CodecContext的。Unity使用了两个CodecContext,Video Context是真正用来做视频编解码的Context,它是一个TYPE CUDA的Hwdevice。第二个CodecContext用的是Vulkan的Context,这个Context的作用是
和Unity的Vulkan Context进行交互,所以在初始化时不会使用到它默认的API,而是从Unity的Vulkan Instance里面取出了所有必要的信息,把它交给FFmpeg的Vulkan Context,最后通过这种方式,就可以让FFmpeg的环境和Unity的环境存在于同一个Vulkan的运行环境中。

Video Context做初始化时,没有用到它默认的Hwdevice Context create的API,用到的是create derived的API。这个API需要传入另一个Hwdevice Context,它能保证做初始化时和另一个Hwdevice Context使用的是同一个物理GPU,这样才能真正地做显存间拷贝。这里选取的边界码的格式是H.264,8 bit,NV 12。 为什么要选用这个格式呢?其实是受硬件限制,因为目前NVIDIA硬件不支持10 bit的H.264的解码。H.265则耗时较大,不太满足60帧的需求,所以不得不选取这个格式。同时Unity是Zero Latency的配置,GOP的Size是0,保证视频每一帧都是Intra Frame。这有两个好处,一是它的延迟非常低。其次,因为分布式渲染在管理的时候可能会随机丢弃帧,如果有预测帧则不好丢弃,在全是I帧的情况下可以随机丢弃。
-05-
画质与性能优化
接下介绍Unity在画质方面和性能方面对插件进行的一些优化。

首先是Tone-Mapping。Unity之所以这样做是因为遇到了Color-Banding问题,这个问题由两个因素导致:
首先,传输的图像不是一个普通的SDR图像,而是HDR图像;
其次,选取的格式只有8 bit,它导致了颜色精度和范围都是受限的。
为了理解为什么Unity传输的是HDR图像,我给大家简单介绍一下渲染里面的一帧是怎么生成的。图示为简化的渲染过程,真正的渲染过程要比这复杂很多。
渲染过程可以简单分为三部分:
第一个部分叫Pre-Pass,它的作用是生成后续渲染阶段所需要的Buffer,在这一阶段里会预先生成Depth,即预先生成深度缓冲。深度缓冲预先生成最主要的好处就是可以减少Over-Draw,很多被遮挡的物体直接被剔除掉,后续步骤中就可以不用画。
第二步是渲染中最主要的一个步骤,我把它叫做Lighting Pass,主要的作用是计算光照,生成物体的最终颜色。这种Pass的实现方式有很多种,例如前向渲染、延迟渲染等。无论是使用哪种实现方式,它的最终目的都是生成一张Color Buffer,即颜色数据。
最后一个步骤一般成为后处理Post-Processing。这个步骤的主要作用是对输出的Color Buffer进行图像处理。经过Post-Processing产生的图像,颜色比单纯的Color Buffer自然很多。Post-Processing里面的效果大部分都是屏幕空间效果,例如要做一个辉光的效果,画面中有一盏灯非常亮,在它的边缘会有一些柔和的光效溢出,这个效果基本上就是通过Post-Processing实现的。
屏幕空间效果会有什么问题?在分布式渲染中,渲染任务是被拆分开的,所以真正做渲染的Render的机器,实际上是没有全屏信息的,它没有办法做后处理。
对此Unity的解决方案是将后处理交由Merger进行。Renderer渲染到Color Buffer生成之后,就把Color Buffer传给Merger,Merger先把这个Color Buffer合起来,再总体做一次后处理。
那么,为什么这一过程中传的Colour Buffer是HDR的?因为在渲染中,光照模型一般都是物理真实的,所以为了之后做后处理,Colour Buffer本身是HDR的。
如图所示,这是把Black Point和White Point分成设置成0和1的效果,但是实际上这张图最高的值可以到90以上。如果是室外的场景,最高值可以到一万多,所以这张图的动态范围是非常高的。
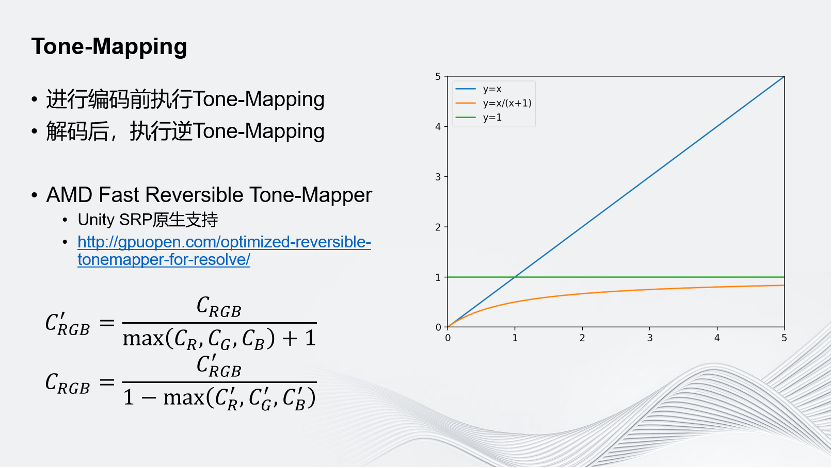
同时,因为传的是动态很高的HDR图像,加上使用的是8bit的编码,所以必须找到一个方法把HDR的Corlor Buffer映射为SDR的Buffer。对于这一映射也有一些要求,其一,它需要可逆;其二,它需要保留更大的表示范围,并且尽量减少精度损失。
Unity在这方面采用的是AMD提出的Fast Reversible Tone-Mapper,它有许多好处: 首先它是Unity SRP原生支持的,是Unity的可编程的渲染管线;其次它是可逆的,如图是它的公式;再次,它保留的数字范围更大,精度损失更小。如图上这一图像,y=x可以理解为原始颜色,经过Tone-Mapper处理后,它的取值范围永远在0~1之间,同时当它的值越小时,斜率越大,代表它能表示的数字越多,可保留的精度越高。有时在渲染中会遇到颜色值非常高的情况,但这种情况少之又少,更多的还是保留在0~1的范围区间内。因此Tone-Mapper能够帮助我们在0~1这个区间范围内保留更多的精度;最后它非常快,在AMD的GCN架构的显卡下,MAX RGB会被编译为一个指令,整个运算中只有3个指令,Max、加法和除法,所以它是非常快的。

如图,可以对比使用Tone-Mapping前后的效果。最左边是未经任何处理的原始图像;中间是不使用任何Tone-Mapping,经过8 bit的编解码、网络传输,再解码回来的情况;最右边是应用了Fast Reversible Tone-Mapping的情况。可以看到里面的背景有很多细节纹理,代表其中高频的信息比较多。在高频信息较多的场景下,应用了Fast Reversible Tone-Mapping之后的效果和原始图像的效果对比,已经看不出什么区别了。
但是如果场景里低频的信息较多,例如渐变较多,即使运用了Tone-Mapping,也没有办法完全解决这个问题。可以看到,原始图像上的渐变非常柔和,在无Tone-Mapping的情况下,色带肉眼可见。但是即使引入了Fast Reversible Tone-Mapping,也只能减缓色带问题,比起原始图像而言还是差了很多,目前没有更好的办法解决这一问题。

Unity对插件进行性能优化的另一个方式是Vulkan同步。因为涉及GPU内部的显存拷贝,而且它是Vulkan拷贝到CUDA的操作,所以它是一个GPU-GPU的异步操作。异步操作要求开发人员对于操作做好同步,即在编码时,要保证Unity渲染完成之后才进行编码,解码时要保证解码完成之后,才能把这张图像Copy给Unity,让Unity把它显示在屏幕上。

Unity Vulkan Native Plugin Interface提供了一种同步方式。这里主要关注框出的两个Flag:
上面的Flush Command Buffer,指在Unity调用自定义渲染事件时,Unity会先把它已经录制好的渲染指令提交到GPU上,这时GPU就可以开始执行这些指令了。
下面的Sync Worker Threads,指在Unity调用自己定义的Plugin Render Event时,会等待GPU上所有的工作全部完成之后才会调用。

这两个方式组合起来确实能满足需求,确实可以做到同步,但是这种方式也打断了渲染流水线。使用这种同步方式,在调用Plugin Event之前,所有程序要全部停下,等待GPU完成操作。因此这个方式虽然能实现同步,但非常耗时。
如图展示的就是在这个同步方式下的情况。在简单的场景下,它耗时5.6毫秒。所以这种方式虽然能同步,但是性能非常差。

Unity只提供了上述的同步方式,因此我们只能转向Vulkan自带的同步原语。Timeline Semaphore是Vulkan在1.2版本的SDK里提出的新型的Semaphore,它非常灵活,而且是FFmpeg原生支持的。这里是FFmpeg的Vulkan Context的Frame,它通过Timeline Semaphore同步。在FFmpeg里,它主要被用于GPU-CPU同步,但它也可以用于GPU-GPU同步。
Unity提供的同步方式只有上述两个Flag,它无法直接使用底层的同步原语,但是它允许我们Hook Vulkan的任何一个API,即在 Hook之后,Unity在调用Vulkan的API时,它其实调用的是我们自己定义的Hook的版本,因此我们使用了Vulkan Hook介入Unity的渲染,在Unity把一帧的渲染提交给GPU之前,通过Hook提交的API,把FFmpeg的Semaphore 塞到提交里面,就可以保证在渲染完成之后会通知Timeline Semaphore,FFmpeg会等Semaphore被通知之后再执行。通过这种方式,这个同步也能达成目的,而且不会打断渲染流水线。
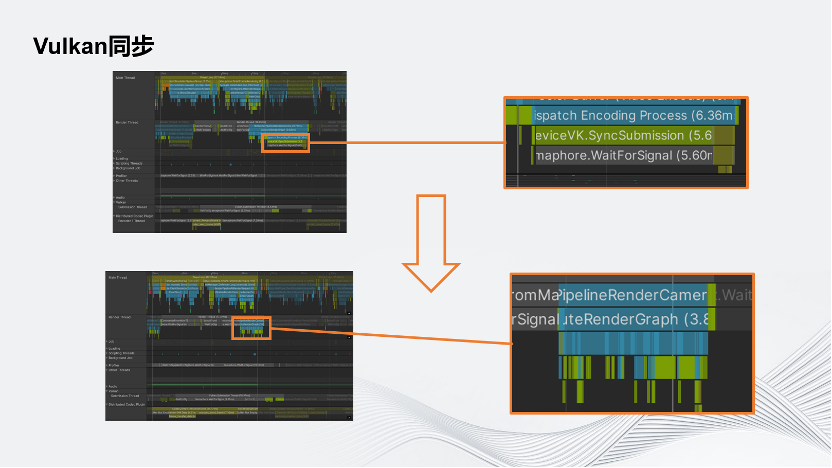
如图所示,上面为5.6毫秒耗时的情况,下面则完全把这一耗时消除了。因为在这个情况下,不需要在调用Render Event之前就提交渲染指令,而是在GPU上通过Timeline Semaphore和FFmpeg的Command进行同步,因此把这一部分完全省去了。在这个简单场景中大概有5.6毫秒左右的提升,经过测试,在复杂场景中则会有10~20毫秒不等的提升。
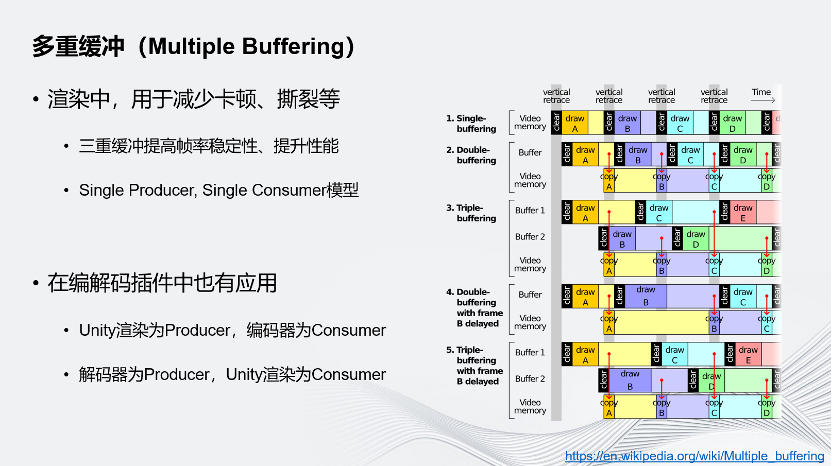
另一个性能优化方案是多重缓冲,这是渲染中非常常用的技巧。在渲染中,常常会用多重缓冲来减少画面的卡顿、撕裂等情况,三重缓冲还能够提高帧率的稳定性、提高渲染性能。
多重缓冲的引入会把渲染变成Single Producer, Single Consumer的流水线模型,即渲染流水线。正是因为有多重缓冲,才能形成流水线,让GPU往一个缓冲中写入时,CPU可以开始准备下一个缓冲,GPU可以同时往另一缓冲区写入下一帧数据。
在编解码的插件中,Unity也引入了多重缓冲来提高性能,使用硬件编解码代替图像上屏操作。渲染的图像没有显示在屏幕上,而是通过网络发走,这是通过多重缓冲的方式实现的,和渲染有同样的效果。在引入多重缓冲后,Unity的渲染和编解码器会分别作为Producer和Consumer进行渲染和编解码的流水线。
-06-
总结与未来展望

在分布式渲染的解决方案中会遇到网络带宽和性能问题。
首先,通过引入视频编解码可以解决了网络带宽的问题,采取硬件编解码避免GPU-CPU的回读,避免打断渲染的流水线。为了实现这个目标,Unity开发了Unity Native Rendering Plugin来对接Unity和FFmpeg底层的Vulkan和NVIDIA Codec 的SDK。
因为选取的编解码格式,方案中还遇到了色带问题,因此在方案中我们引入Tone-Mapping优化画质,通过FFmpeg自带的Timeline Semaphore,把Unity的渲染指令和FFmpeg的拷贝指令和编解码指令进行同步,保证编解码结果正确。
最后,Unity通过引入多重缓冲提升性能,减少帧率不稳的情况。
目前Unity还在探索一些其他的方案。
首先,Unity希望尝试Vulkan自己推出的Vulkan Vider Extensions。它在2023年1月左右才真正进入Vulkan的SDK,成为一个正式的功能。这个Extension非常新,所以到目前为止Unity还没有机会进行尝试,但一直在关注。如果使用这一Extension,就可以完全避免前文所述得到显存间拷贝、同步等问题。因为这一应用程序没有引入别的GPU端的运行环境,完全在Vulkan内部运行,因此我们不需要拷贝,直接使用Unity的结果即可。
其次,Unity在对接其他GPU的硬件厂商,尝试其他硬件编码。Unity目前正在和一些国产的GPU厂商对接,他们表示他们的硬件编解码能力会有所提升,支持的格式不再限制于8 bits了。
最后,Unity还希望尝试一些要使用GPUDirect RDMA、CXL共享内存等特殊硬件的方案。GPUDirect RDMA允许直接把GPU显存里的东西直接通过网络发走,能够减少回读。CXL共享内存,顾名思义是个共享内存,相当于很多台机器共享一个远程的内存池,因此它的带宽和延迟都是内存级别。这一方案至少允许我们在分布式渲染的环境下不进行视频编解码,可以使用Raw Data的方式,把Raw Data存在远程内存中。
编辑:黄飞
-
分布式软件系统2009-07-22 0
-
如何对分布式天线系统(DAS)进行优化?2021-05-24 0
-
性能提升1倍,成本直降50%!基于龙蜥指令加速的下一代云原生网关2022-08-31 0
-
只需 6 步,你就可以搭建一个云原生操作系统原型2022-09-15 0
-
基于分布式电源的微网的设计与运行2011-08-26 637
-
分布式能源系统经济优化运行2018-02-06 1305
-
中国邮政引入阿里云分布式数据库,高效度过2019年双十一2020-09-18 1887
-
简述图文存储常识:单机、集中、分布式、云、云原生存储2021-05-26 3595
-
2022开放原子全球开源峰会云原生分william hill官网 即将开幕2022-07-18 1037
-
云原生技术概述 云原生火爆成为升职加薪核心必备2022-07-27 1309
-
什么是分布式云原生2022-07-27 1570
-
2022开放原子全球开源峰会云原生分william hill官网 圆满召开2022-07-28 1598
-
华为云左少夫:面向分布式云原生构筑无处不在的云原生基础设施2022-12-26 776
-
探索云原生技术发展与应用实践,赋能企业数字化转型 | 2023开放原子全球开源峰会云原生分william hill官网 即将启幕2023-05-30 549
全部0条评论

快来发表一下你的评论吧 !
