

GPGPU和NPU技术路线对比
人工智能
描述
今年,“能写代码、能写论文”的ChatGPT可谓是火爆全球,AI技术应用迎来了“iPhone时刻”。一时间国内也涌现了众多大模型,部分大模型也陆续开始向公众开放;另一方面,全国各地也都在抢占人工智能的资源,纷纷投巨资建设人工智能算力中心,人工智能赛道可谓“百舸争流”。
在这两个现象的背后,笔者却发现了不一样的地方,各地新建动辄几百PB算力的智算中心,是以半精度(FP16)来作为计量标准的,甚至有些智算算力中心是通过NPU架构芯片堆出来的算力。
但其实业界公认,NPU天生特点决定了其在AI应用领域泛用性不足,因此NPU并不适合作为AI算力通用底座。
那我们就来聊一聊,为什么ChatGPT、自动驾驶这些领域不适合广泛采用NPU芯片?在正式开聊之前,先说明一下这里面的两个关键词:NPU和精度
(1)NPU和精度
在人工智能领域,AI芯片可以分为大概分为GPGPU、FPGA和ASIC。其中,GPGPU在人工智能的计算市场销售额占比最大,据集微咨询(JW Insights)统计,AI类芯片在2022年352亿美元的市场规模中,GPGPU占比接近60%,霸主地位稳固。
我们知道 CPU遵循的是冯·诺依曼架构,核心是存储程序/数据、串行顺序执行。CPU的架构中需要大量的空间去放置存储单元和控制单元,相比之下计算单元只占据了很小的一部分,所以CPU在进行大规模并行计算方面受到限制,相对而言更擅长于处理逻辑控制。
与CPU相比,而GPU芯片空间的80%以上都是计算单元,即GPU拥有更多的计算单元用于数据并行处理,比如实现人工智能的深度学习、比特币挖矿等等。GPU其实也可以简单分为两种,一种是主要搞图形渲染的,也叫做GPU显卡;另一种是主要搞计算的,叫做GPGPU,也叫通用GPU。GPGPU芯片采用统一渲染架构,计算通用性最强,可以适用于多种算法,在很多算法前沿的领域,GPGPU是最佳选择。
FPGA是一种半定制芯片,对芯片硬件层可以灵活编译。但是缺点也比较明显,当处理的任务重复性不强、逻辑较为复杂时,FPGA效率就会比较差。
ASIC是一种为专门目的而设计的芯片(全定制),根据特定算法定制的芯片架构,算力强大,但专业性强缩减了其通用性,算法一旦改变,计算能力会大幅下降,需要重新定制。我们知道的NPU、TPU就是这种架构,都属于ASIC定制芯片。
芯片的算力和精度又有怎样的联系?
根据参与运算数据精度的不同,可把算力分为双精度算力(64位,FP64)、单精度算力(32位,FP32)、半精度算力(16位,FP16)及整型算力(INT8、INT4)。数字位数越高,意味着精度越高,能够支持的运算复杂程度就越高,适配的应用场景也就越广。
举个例子,在科学计算、工程计算等领域,比如药物设计、新材料、航空航天、基因工程,天气预报等,都是需要处理的数字范围大而且需要精确计算的科学计算,需要双精度算力(FP64)的支持;在AI大模型、自动驾驶、深度学习等领域,一般需要单精度算力(FP32)的支持,实现人工智能模型的训练;而像数字孪生、人脸识别等利用训练完毕的模型进行推理的业务,适用于半精度算力(FP16)或者整型算力(INT8、INT4)。
GPGPU芯片一般会布局大量的双精度和单精度的计算区域,从NVIDIA旗舰产品白皮书中可以看出,其对FP64双精度浮点计算的布局占25%,对FP64/FP32高精度区域的布局占整个芯片的约一半左右。
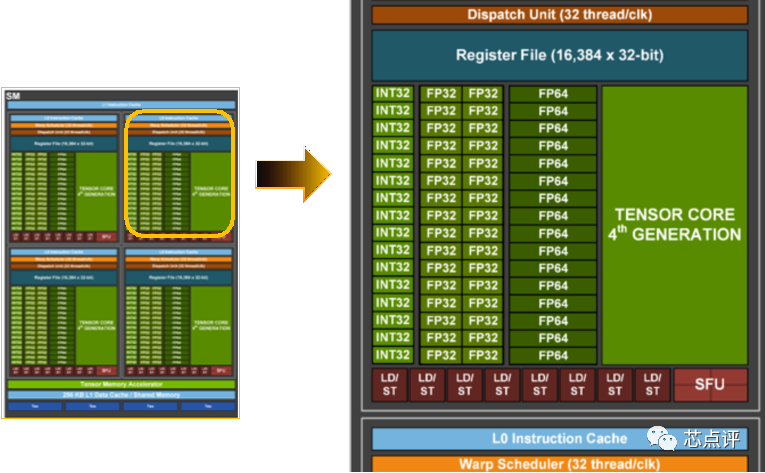
图 NVIDIA高精度GPGPU架构图
而NPU芯片主要用于加速神经网络的运算,解决传统芯片在神经网络运算时效率低下的问题。NPU芯片包括乘加、激活函数、二维数据运算、解压缩等模块。它的优势是大部分时间集中在低精度的算法,新的数据流架构或内存计算能力。NPU芯片的算力一般以半精度算力(FP16)和整型算力(INT8、INT4)为主,擅长处理视频、图像类的海量多媒体数据,不涉及高精度算力应用的领域。
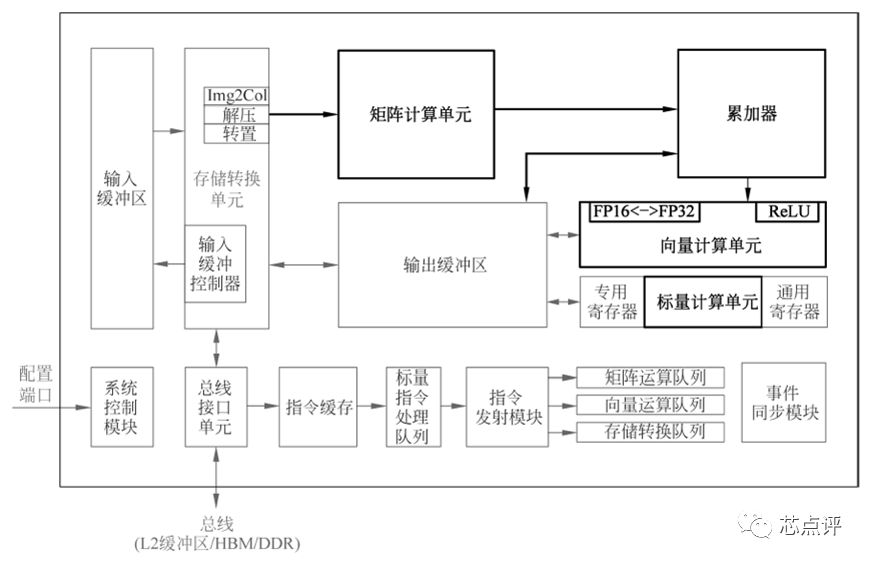
图 华为NPU计算单元图
综上所述,GPGPU可以支持从低精度到高精度所有类型的运算,而NPU仅能支持低精度运算,这就决定了两者可适用的场景存在差距。
在此情况下,某些NPU厂商混淆视听,只说自己是“算力最强的AI处理器”,却没有说清楚计算精度这一前提条件,是一种不负责的行为。
(2)GPGPU和NPU技术路线对比
说了这么多,我们发现GPGPU和NPU属于两个不同应用领域的芯片,GPGPU的算力精度涵盖较广,应用的领域也更广泛,整个产业的生态相对完整,但是芯片设计相对比较复杂,前一阵美国限制向中国出口的AI芯片也是高端的GPGPU芯片。
而NPU芯片主要是覆盖低精度,应用领域比较受限,特别是很多NVIDIA的业务如果迁移到NPU环境下,需要大量的迁移适配工作,而且模型在迁移后也会遇到各种各样的算法、引擎识别精度下降的问题。
| 对比内容 | GPGPU | NPU |
| 算力精度 | 双精度、单精度、半精度、整形 | 半精度、整形 |
| 应用场景 | 高性能计算、AI大模型、自动驾驶、深度学习 | 机器学习、人工智能推理 |
| 迁移工作量 | 基于GPGPU的通用模型需修改少量代码,自研算子、模型2-3天完成环境搭建和测试,时间周期较短 | 架构差异大,适配工作量较大,周期不可评估 |
| 产业生态 | 支持算法厂商众多,产业生态优势大 | 多数算法厂商对NPU路线芯片适配积极性一般 |
表 :GPGPU和NPU技术路线对比
NPU更符合“术业有专攻”,在AI应用推理环节,量身定制的NPU其实也有这效率和能耗的优势;但要是强行广泛应用于科学计算、模型训练等领域,NPU只能表示“臣妾做不到啊”。
(3)ChatGPT背后的算力面纱
当我们了解了GPGPU和NPU技术路线之后,我们再来揭开ChatGPT背后的算力面纱。
ChatGPT的开发逻辑,是近些年逐步替代了RNN(循环神经网络)和 CNN(卷积神经网络) 的Transformer架构语言模型。相较于RNN,Transformer引入了自我注意力(Self-attention)机制,结合算法优化可以实现并行运算,大量节约训练时间。可以看出,Transformer作为人工智能算法的进化是计算机软件层面的一个发展。
因此,为了支撑这种算法的不断进化,需要一整套通用算力系统。通俗而言,ChatGPT算法是在不断优化进步的,结合算法定制NPU很难满足大模型迭代发展需求。
也就是说,想要诞生ChatGPT这样的革命性成果,需要构建的是由高精度GPGPU+ CPU的通用异构计算体系,让各种尝试和各种创新在通用体系上自由生长。
而事实上,ChatGPT以及国内众多的大模型,如紫东太初大模型、文心一言、日日新SenseNova大模型等等,也都是在这种由高精度GPGPU组成的异构计算体系中诞生的。
我国超大规模预训练模型的发展如火如荼,算力需求持续攀升,人工智能计算中心的建设保持快速增长,各地都在加速建设人工智能计算中心,甚至很多算力中心的规划已经超过了1000P,看样子应该能满足各地几年内的所有人工智能算力需求,但这些算力中心的AI芯片大部分都是NPU架构,目前真正应用起来的地方智算中心的寥寥无几,实际使用率也低得可怜。
另一方面,各个大模型的厂商、自动驾驶厂商和都在疯狂抢购高端的GPGPU卡,甚至不惜高价囤积高端GPGPU卡。
在这两个乱象的背后,我们需要去反思:现阶段我们是否需要建设如此大量的、空置的NPU算力中心?我们的算力中心是否应该以几百PB的FP16值作为评价标准?
编辑:黄飞
-
【「算力芯片 | 高性能 CPU/GPU/NPU 微架构分析」阅读体验】--全书概览2024-10-15 0
-
5G标准的技术路线解析2020-12-28 0
-
求大佬分享单片机的技术路线2022-01-18 0
-
全志V853 NPU 系统介绍2022-11-09 0
-
Arm®Ethos™-U65 NPU技术参考手册2023-08-02 0
-
CPU和GPGPU 未来的技术演变方向2022-12-08 850
-
npu是什么意思?npu芯片是什么意思?npu到底有什么用?2023-08-27 41861
-
npu是华为独有的吗?手机有npu和没有npu的区别?2023-08-27 3516
-
从图形到通用计算:GPGPU技术的进化之路2023-12-01 1134
-
GPGPU体系结构优化方向(1)2024-10-09 280
-
什么是NPU?什么场景需要配置NPU?2024-10-11 1587
-
NPU与GPU的性能对比2024-11-14 983
-
什么是NPU芯片及其功能2024-11-14 1135
-
NPU技术如何提升AI性能2024-11-15 435
-
NPU的工作原理解析2024-11-15 657
全部0条评论

快来发表一下你的评论吧 !
