

灰度图像均值滤波算法的HDL实现介绍
描述
1.1 均值滤波算法介绍
首先要做的是最简单的均值滤波算法。均值滤波是典型的线性滤波算法,它是指在图像上对目标像素给一个模板,该模板包括了其周围的临近像素(以目标象素为中心的周围 8 个像素,构成一个滤波模板,即去掉目标像素本身),再用模板中的全体像素的平均值来代替原来像素值。
| P11 | P12 | P13 |
| P21 | P23 | |
| P31 | P32 | P33 |
中值滤波算法可以形象的用上述表格来描述,即对于每个 3*3 的阵列而言,中间像素的值,等于边缘 8 个像素的平均值。 算法的理论很简单,对于 C 处理器而言,一幅640*480图像的均值滤波, 可以很方便的通过数组获得 3*3 的阵列,但对于我们的 Verilog HDL 而言,着实不易。
1.2 3*3 像素阵列的 HDL 实现
3*3 阵列的获取,大概有以下三种方式:
(1) 通过 2 个或 3 个 RAM 的存储,来实现 3*3 像素阵列;
(2) 通过 2 个或 3 个 FIFO 的存储,来实现 3*3 像素阵列;
( 3) 通过 2 行或 3 行 Shift_RAM 的移位存储,来实现 3*3 像素阵列。
不过经验告诉大家,最方便的实现方式,非 Shift_RAM 莫属了,都感觉 Shift_RAM 甚至是为实现 3*3 阵列而生的!
在Quartus II中,可以利用下图方式产生,很方便:
首先介绍一下 Shift_RAM, 宏定义模块如下图所示:
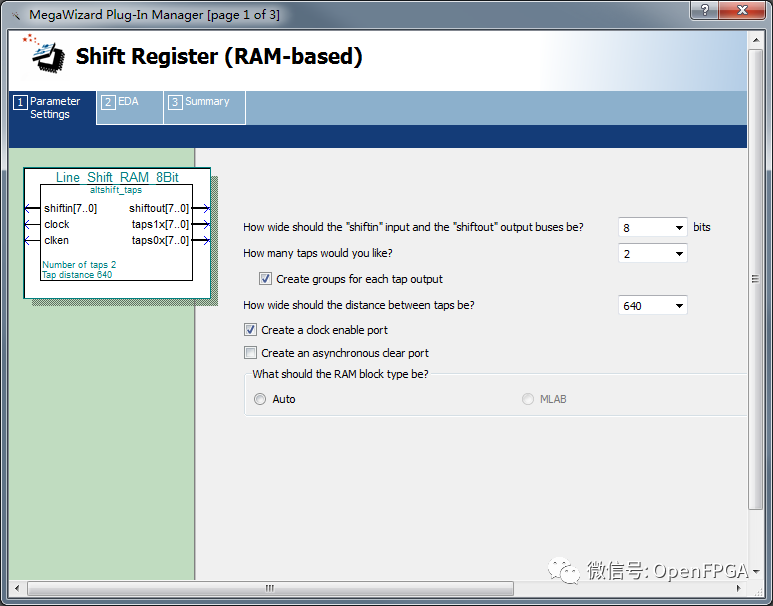
图6‑1 QuartusII Shift_RAM IP使用界面
Shift_RAM 可定义数据宽度、 移位的行数、 每行的深度。 这里我们固然需要8Bit,640 个数据每行,同时移位寄存 2 行即可( 原因看后边)。 同时选择时钟使能端口clken。 详细的关于 Shift_RAM 的手册参数,可在宏定义窗口右上角Document 中查看,如下:
手册给出了一个非常形象的移位寄存示意图,如下所示:
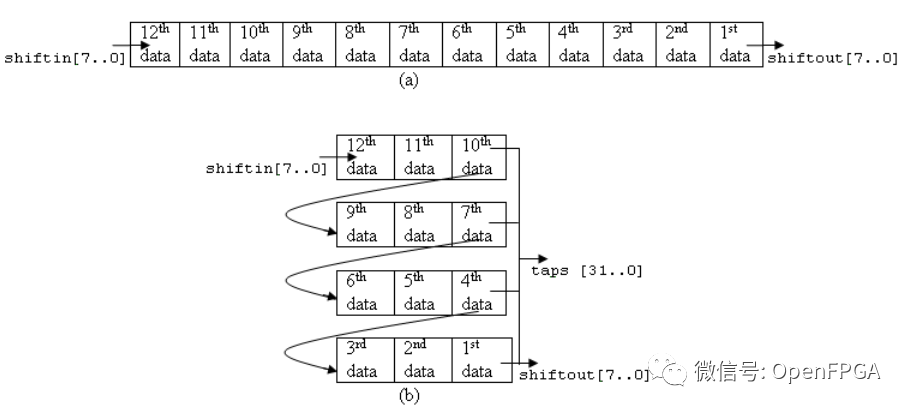
图6‑2移位寄存示意图
实现3*3像素阵列的大概的思路是这样子的, Shift_RAM 中存 2 行数据,同时与当前输入行的数据,组成3 行的阵列。
在Vivado中就没有类似的IP,但是难不倒我,可以利用成熟的IP核实现类似上诉的移位寄存器。
在《Image�06_OV5640_DDR3_Gray_Mean_FilterOV5640_DEMOuserlinebuffer_Wapper》
中实现的就是移位寄存器功能的IP,使用方法类似上诉QuartusII中的使用。
例化方式如下:
代码6‑1
|
1. //--------------------------------------- 2. //module of shift ram for raw data 3. wire shift_clk_en = per_frame_clken; 4. 5. linebuffer_Wapper# 6. ( 7. .no_of_lines(2), 8. .samples_per_line(640), 9. .data_width(8) 10.) 11. linebuffer_Wapper_m0( 12. .ce (1'b1 ), 13. .wr_clk (clk ), 14. .wr_en (shift_clk_en ), 15. .wr_rst (rst_n ), 16. .data_in (row3_data ), 17. .rd_en (shift_clk_en ), 18. .rd_clk (clk ), 19. .rd_rst (rst_n ), 20. .data_out ({row2_data,row1_data} ) 21. ); |
源码VIP_Matrix_Generate_3X3_8Bit 文件中实现 8Bit 宽度的 3*3 像素阵列功能。 具体的实现步骤如下:
(1) 首先,将输入的信号用像素使能时钟同步一拍,以保证数据与Shift_RAM 输出的数据保持同步,如下:
代码6‑2
|
1. //Generate 3*3 matrix 2. //-------------------------------------------------------------------------- 3. //-------------------------------------------------------------------------- 4. //-------------------------------------------------------------------------- 5. //sync row3_data with per_frame_clken & row1_data & raw2_data 6. wire [7:0] row1_data; //frame data of the 1th row 7. wire [7:0] row2_data; //frame data of the 2th row 8. reg [7:0] row3_data; //frame data of the 3th row 9. always@(posedge clk or negedge rst_n) 10.begin 11. if(!rst_n) 12. row3_data <= 0; 13. else 14. begin 15. if(per_frame_clken) 16. row3_data <= per_img_Y; 17. else 18. row3_data <= row3_data; 19. end 20.end |
(2) 接着,例化并输入 row3_data,此时可从 Modelsim 中观察到 3 行数据同时存在了, HDL 如下:
代码6‑3 QuartusII例化移位寄存器代码
|
1. //--------------------------------------- 2. //module of shift ram for raw data 3. wire shift_clk_en = per_frame_clken; 4. Line_Shift_RAM_8Bit 5. #( 6. .RAM_Length (IMG_HDISP) 7. ) 8. u_Line_Shift_RAM_8Bit 9. ( 10..clock (clk), 11..clken (shift_clk_en), //pixel enable clock 12.// .aclr (1'b0), 13..shiftin (row3_data), //Current data input 14..taps0x (row2_data), //Last row data 15..taps1x (row1_data), //Up a row data 16..shiftout () 17.); |
代码6‑4 Vivado例化移位寄存器代码
|
22.//--------------------------------------- 23.//module of shift ram for raw data 24.wire shift_clk_en = per_frame_clken; 25. 26.linebuffer_Wapper# 27.( 28. .no_of_lines(2), 29. .samples_per_line(640), 30. .data_width(8) 31.) 32. linebuffer_Wapper_m0( 33. .ce (1'b1 ), 34. .wr_clk (clk ), 35. .wr_en (shift_clk_en ), 36. .wr_rst (rst_n ), 37. .data_in (row3_data ), 38. .rd_en (shift_clk_en ), 39. .rd_clk (clk ), 40. .rd_rst (rst_n ), 41. .data_out ({row2_data,row1_data} ) 42. ); |
在经过 Shift_RAMd 移位存储后,我们得到的 row0_data, row1_data,row2_data的仿真示意图如下所示:

图6‑3 ModelSim仿真截图
数据从 row3_data 输入, 满 3 行后刚好唯一 3 行阵列的第一。 从图像第三行输入开始,到图像的最后一行,我们均可从 row_data 得到完整的 3 行数据, 基为实现3*3阵列奠定了基础。 不过这样做有2个不足之处, 即第一行与第二行不能得到完整的 3*3 阵列。 但从主到次,且不管算法的完美型,我们先验证 3X3模板实现的正确性。 因此直接在行有效期间读取 3*3 阵列,机器方便快捷的实现了我们的目的。
(3) Row_data 读取信号的分析及生成
这里涉及到了一个问题,数据从Shift_RAM存储耗费了一个时钟,因此3*3阵列的读取使能与时钟,需要进行一个 clock 的偏移,如下所示:
代码6‑5
|
1. //------------------------------------------ 2. //lag 2 clocks signal sync 3. reg [1:0] per_frame_vsync_r; 4. reg [1:0] per_frame_href_r; 5. reg [1:0] per_frame_clken_r; 6. always@(posedge clk or negedge rst_n) 7. begin 8. if(!rst_n) 9. begin 10. per_frame_vsync_r <= 0; 11. per_frame_href_r <= 0; 12. per_frame_clken_r <= 0; 13. end 14. else 15. begin 16. per_frame_vsync_r <= {per_frame_vsync_r[0], per_frame_vsync}; 17. per_frame_href_r <= {per_frame_href_r[0], per_frame_href}; 18. per_frame_clken_r <= {per_frame_clken_r[0], per_frame_clken}; 19. end 20.end 21.//Give up the 1th and 2th row edge data caculate for simple process 22.//Give up the 1th and 2th point of 1 line for simple process 23.wire read_frame_href = per_frame_href_r[0]; //RAM read href sync signal 24.wire read_frame_clken = per_frame_clken_r[0]; //RAM read enable 25.assign matrix_frame_vsync = per_frame_vsync_r[1]; 26.assign matrix_frame_href = per_frame_href_r[1]; 27.assign matrix_frame_clken = per_frame_clken_r[1]; |
( 4) Okay, 此时根据 read_frame_href 与 read_frame_clken 信号,直接读取3*3像素阵列。读取的 HDL 实现如下:
代码6‑6
|
1. //---------------------------------------------------------------------------- 2. //---------------------------------------------------------------------------- 3. /****************************************************************************** 4. ---------- Convert Matrix ---------- 5. [ P31 -> P32 -> P33 -> ] ---> [ P11 P12 P13 ] 6. [ P21 -> P22 -> P23 -> ] ---> [ P21 P22 P23 ] 7. [ P11 -> P12 -> P11 -> ] ---> [ P31 P32 P33 ] 8. ******************************************************************************/ 9. //--------------------------------------------------------------------------- 10. //--------------------------------------------------- 11. /*********************************************** 12. (1) Read data from Shift_RAM 13. (2) Caculate the Sobel 14. (3) Steady data after Sobel generate 15. ************************************************/ 16. //wire [23:0] matrix_row1 = {matrix_p11, matrix_p12, matrix_p13}; //Just for test 17. //wire [23:0] matrix_row2 = {matrix_p21, matrix_p22, matrix_p23}; 18. //wire [23:0] matrix_row3 = {matrix_p31, matrix_p32, matrix_p33}; 19. always@(posedge clk or negedge rst_n) 20. begin 21. if(!rst_n) 22. begin 23. {matrix_p11, matrix_p12, matrix_p13} <= 24'h0; 24. {matrix_p21, matrix_p22, matrix_p23} <= 24'h0; 25. {matrix_p31, matrix_p32, matrix_p33} <= 24'h0; 26. end 27. else if(read_frame_href) 28. begin 29. if(read_frame_clken) //Shift_RAM data read clock enable 30. begin 31. {matrix_p11, matrix_p12, matrix_p13} <= {matrix_p12, matrix_p13, row1_data}; //1th shift input 32. {matrix_p21, matrix_p22, matrix_p23} <= {matrix_p22, matrix_p23, row2_data}; //2th shift input 33. {matrix_p31, matrix_p32, matrix_p33} <= {matrix_p32, matrix_p33, row3_data}; //3th shift input 34. end 35. else 36. begin 37. {matrix_p11, matrix_p12, matrix_p13} <= {matrix_p11, matrix_p12, matrix_p13}; 38. {matrix_p21, matrix_p22, matrix_p23} <= {matrix_p21, matrix_p22, matrix_p23}; 39. {matrix_p31, matrix_p32, matrix_p33} <= {matrix_p31, matrix_p32, matrix_p33}; 40. end 41. end 42. else 43. begin 44. {matrix_p11, matrix_p12, matrix_p13} <= 24'h0; 45. {matrix_p21, matrix_p22, matrix_p23} <= 24'h0; 46. {matrix_p31, matrix_p32, matrix_p33} <= 24'h0; 47. end 48. end |
最后得到的 matrix_p11、 p12、 p13、 p21、 p22、 p23、 p31、 p32、 p33 即为得到的 3*3 像素阵列,仿真时序图如下所示:

前面Shift_RAM存储耗费了一个时钟,同时 3*3 阵列的生成耗费了一个时钟,因此我们需要人为的将行场信号、像素使能读取信号移动 2 个时钟,如下所示:
assign matrix_frame_vsync =per_frame_vsync_r[1];
assign matrix_frame_href =per_frame_href_r[1];
assign matrix_frame_clken =per_frame_clken_r[1];
至此我们得到了完整的 3*3 像素阵列的模块,同时行场、使能时钟信号与时序保持一致,Modelsim 仿真图如下所示:

1.3 Mean_Filter 均值滤波算法的实现
不过相对于 3*3 像素阵列的生成而言,均值滤波的算法实现反而难度小的多,只是技巧性的问题。
继续分析上面这个表格。其实 HDL 完全有这个能力直接计算 8 个值相加的均值,不过为了提升威廉希尔官方网站 的速度,建议我们需要通过以面积换速度的方式来实现。 So 这里需要 3 个步骤:
(1) 分别计算 3 行中相关像素的和;
(2) 计算(1) 中三个结果的和;
在(2) 运算后,我们不能急着用除法去实现均值的运算。记住,能用移位替换的,绝对不用乘除法来实现。这里 8 个像素, 即除以 8, 可以方便的用右移动 3Bit 来实现。不过这里更方便的办法是,直接提取 mean_value4[10:3]。
这一步我们不单独作为一个 Step, 而是直接作为结果输出。分析前面的运算,总共耗费了 2 个时钟, 因此需要将行场信号、像素读取信号偏移 2 个时钟,同时像素时钟,根据行信号使能,直接读取 mean_value4[10:3],如下所示:
这样,我们便得到了运算后的时序,实现了均值滤波算法。
最后,在 Video_Image_Processor 顶层文件中例化Gray_Mean_Filter算法模块,完成算法的添加。
最后直接将生成的 post_img_Y 输入给 24Bit 的 DDR 控制器即可。
审核编辑:刘清
-
基于FPGA的HDTV视频图像灰度直方图统计算法设计2012-05-14 0
-
请教一种可识别未受污染点的中值/均值滤波matlab程序2013-03-30 0
-
基于FPGA的均值滤波算法实现2017-08-28 0
-
基于FPGA的中值滤波算法实现2017-09-01 0
-
数字图像空域滤波算法的FPGA设计与实现2011-01-18 954
-
灰度相关和区域特征的图像拼接算法2011-03-07 1029
-
一种加权均值滤波的改进算法2011-05-16 791
-
均值滤波和均值滤波算法程序2017-12-19 6737
-
基于FPGA灰度图像高斯滤波算法的实现2018-02-20 7618
-
基于FPGA的均值滤波算法的实现2019-01-02 5154
-
如何使用FPGA实现图像的中值滤波算法2021-04-01 963
-
如何使用FPGA实现图像灰度级拉伸算法2021-04-01 905
-
详解从均值滤波到非局部均值滤波算法的原理及实现方式2023-12-19 1255
-
高斯滤波和均值滤波的区别2024-09-29 641
全部0条评论

快来发表一下你的评论吧 !
