

Prometheus的基本原理与开发指南
描述
导读
本文由梯度科技云管研发部高级工程师周宇明撰写,共分为7章,紧密围绕Prometheus的基本原理与开发指南展开介绍:
监控系统概述
Prometheus入门
PromQL入门
PromQL高级实战
告警引擎深度解析
本地存储与远程存储
梯度运维管理平台监控模块架构
01监控系统概述
导读:本章从监控的作用、架构分类、指标监控发展史、指标监控典型架构等4个方面介绍监控系统的相关概念。
1.1.监控的作用 ★
为了构建稳定性保障体系,核心就是在干一件事:减少故障。

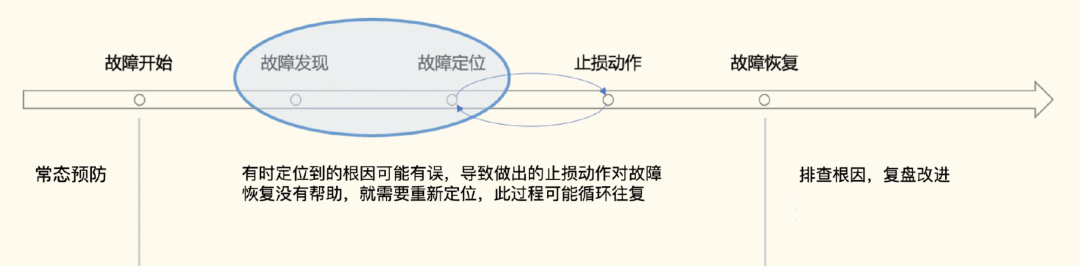
减少故障有两个层面的意思,一个是做好常态预防,不让故障发生;另一个是如果故障发生,要能尽快止损,减少故障时长,减小故障影响范围。监控的典型作用就是帮助我们发现及定位故障。
监控的其他作用:日常巡检、性能调优的数据佐证、提前发现一些不合理的配置。
之所以能做到这些,是因为所有优秀的软件,都内置了监控数据的暴露方法,让用户可以对其进行观测,了解其健康状况:比如各类开源组件,有的是直接暴露了 Prometheus metrics 接口,有的是暴露了 HTTP JSON 接口,有的是通过 JMX 暴露监控数据,有的则需要连上去执行命令。另外,所有软件都可以使用日志的方式来暴露健康状况。
因此,可被监控和观测,也是我们开发软件时必须考虑的一环。
1.2.监控架构分类 ★
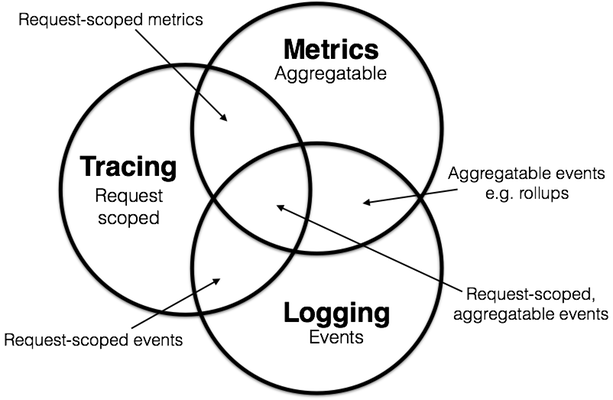
1.1.1. Metrics(指标)
定义:可进行聚合计算的原子型数据,通常通过多个标签值来确定指标唯一性。
特点:指标数据仅记录时间戳和对应的指标数值,通常存储在时间序列数据库中(TSDB),存储成本低,可用于渲染趋势图或柱状图,可灵活配置告警规则,对故障进行快速发现和响应;但是不适合用于定位故障原因。
实现方案:Zabbix、Open-Falcon、Prometheus
1.1.2. Logging(日志)
定义:离散事件,是系统运行时发生的一个个事件的记录。
特点:日志数据可以记录详细的信息(请求响应参数、自定义文字描述、异常信息、时间戳等),一般用于排查具体问题;日志通常存储在文件中,数据非结构化,存储成本高,不适合作为监控数据的来源。
实现方案:ELK、Loki
1.1.3. Tracing(链路)
定义:基于特定请求作用域下的所有调用信息。
特点:一般需要依赖第三方存储,在微服务中一般有多个调用信息,如从网关开始,A服务调用B服务,调用数据库、缓存等。在链路系统中,需要清楚展现某条调用链中从主调方到被调方内部所有的调用信息。不仅有利于梳理接口及服务间调用的关系,还有助于排查慢请求或故障产生的原因。
实现方案:jaeger、zipkin、Skywalking
1.3. 指标监控发展史
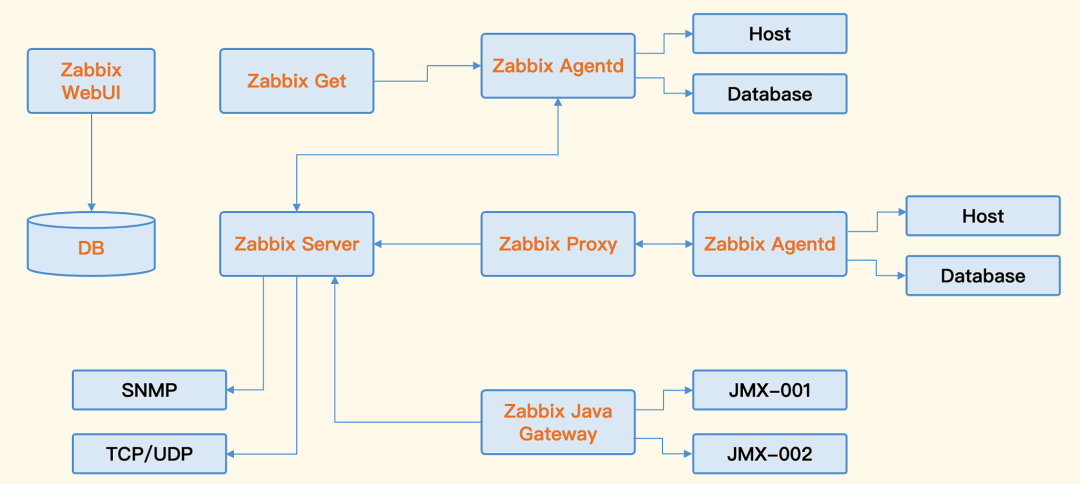
1.3.1. Zabbix
企业级的开源解决方案,擅长设备、网络、中间件的监控。
优点:
平台兼容性好,可运行在 Windows、Linux、Solaris、AIX、OS X等平台上;
架构简单,易于维护、备份。
缺点:
使用数据库存储,无法水平扩展,容量有限;
面向资产管理的逻辑,使得监控指标的数据结构固化,没有灵活的标签设计,无法适应云原生架构下动态多变的环境。
1.3.2. Open-Falcon
Open-Falcon 最初来自小米,14 年开源,当时小米有 3 套 Zabbix,1 套业务性能监控系统 perfcounter。Open-Falcon 的初衷是想做一套大一统的方案,来解决这个乱局。

优点:
比Zabbix容量大得多,不仅可以处理设备、中间件层面监控,还可以处理应用层面监控;
Go语言开发,易于二次开发。
缺点:
组件拆分比较散,部署相对比较麻烦;
生态不够庞大,开源软件的治理架构不够优秀。
1.3.3. Prometheus
Prometheus 的设计思路来自Borgmon,就像 Borgmon 是为 Borg 而生的,而 Prometheus 就是为 Kubernetes 而生的。提供了多种服务发现机制,大幅简化了 Kubernetes 的监控。
Prometheus2.0版本开始,重新设计了时序库,性能和可靠性都大幅提升。
优点:
对 Kubernetes 支持很好,Prometheus 是云原生架构下监控的标配;
生态庞大,有各种各样的 Exporter,支持各种各样的时序库作为后端的备用存储,也有很好的支持多种不同语言的 SDK,供业务代码嵌入埋点。
缺点:
设置数据采集和告警策略需要修改配置文件,协同起来比较麻烦。
Exporter 参差不齐,通常是一个监控目标一个 Exporter,管理成本较高。
1.4. 指标监控典型架构 ★
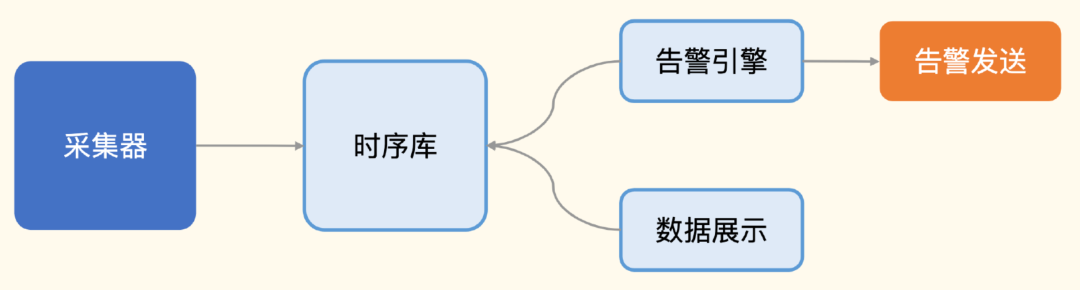
1.4.1. 采集器 ★
有两种典型的部署方式,一种是跟随监控对象部署,比如所有的机器上都部署一个采集器,采集机器的 CPU、内存、硬盘、IO、网络相关的指标;另一种是远程探针式,比如选取一个中心机器做探针,同时探测很多个机器的 PING 连通性,或者连到很多 MySQL 实例上去,执行命令采集数据。
Telegraf:
InfluxData 公司的产品,主要配合 InfluxDB 使用。Telegraf 也可以把监控数据推给 Prometheus存储;
Telegraf 是指标领域的 All-In-One 采集器,支持各种采集插件,只需要使用这一个采集器,就能解决绝大部分采集需求;
Telegraf 采集的很多数据都是字符串类型,但如果把这类数据推给 Prometheus 生态的时序库,比如 VictoriaMetrics、M3DB、Thanos 等,它就会报错
Exporter:
Exporter是专门用于Prometheus 生态的采集器,但是比较零散,每个采集目标都有对应的 Exporter 组件,比如 MySQL 有 mysqld_exporter,Redis 有 redis_exporter,JVM 有 jmx_exporter。
Exporter 的核心逻辑,就是去这些监控对象里采集数据,然后暴露为 Prometheus 协议的监控数据。比如 mysqld_exporter,就是连上 MySQL,执行一些类似于 show global status 、show global variables 、show slave status 这样的命令,拿到输出,再转换为 Prometheus 协议的数据;
很多中间件都内置支持了 Prometheus,直接通过自身的 /metrics 接口暴露监控数据,不用再单独伴生 Exporter;比如 Kubernetes 中的各类组件,比如 etcd,还有新版本的 ZooKeeper、 RabbitMQ;
不管是Exporter还是支持Prometheus协议的各类组件,都是提供 HTTP 接口(通常是 /metrics )来暴露监控数据,让监控系统来拉,这叫做 PULL 模型。
Grafana-Agent:
Grafana 公司推出的一款 All-In-One 采集器,不但可以采集指标数据,也可以采集日志数据和链路数据。
如何快速集成各类采集能力的呢?Grafana-Agent 写了个框架,方便导入各类 Exporter,把各个 Exporter 当做 Lib 使用,常见的 Node-Exporter、Kafka-Exporter、Elasticsearch-Exporter、Mysqld-Exporter 等,都已经完成了集成。对于默认没有集成进去的 Exporter,Grafana-Agent 也支持用 PULL 的方式去抓取其他 Exporter 的数据,然后再通过 Remote Write 的方式,将采集到的数据转发给服务端。
很多时候,一个采集器可能搞不定所有业务需求,使用一款主力采集器,辅以多款其他采集器是大多数公司的选择。
1.4.2. 时序库
Prometheus TSDB
Prometheus本地存储经历过多个迭代:V1.0(2012年)、V2.0(2015年)、V3.0(2017年)。最初借用第三方数据库LevelDB,1.0版本性能不高,每秒只能存储5W个样本;2.0版本借鉴了Facebook Gorilla压缩算法,将每个时序数据以单个文件方式保存,将性能提升到每秒存储8W个样本;2017年开始引入时序数据库的3.0版本,并成立了Prometheus TSDB开源项目,该版本在单机上提高到每秒存储百万个样本。
3.0版本保留了2.0版本高压缩比的分块保存方式,并将多个分块保存到一个文件中,通过创建一个索引文件避免产生大量的小文件;同时为了防止数据丢失,引入了WAL机制。
InfluxDB
InfluxDB 针对时序存储场景专门设计了存储引擎、数据结构、存取接口,国内使用范围比较广泛,可以和 Grafana、Telegraf 等良好整合,生态是非常完备的。
不过 InfluxDB 开源版本是单机的,没有开源集群版本。
M3DB
M3DB 是 Uber 的时序数据库,M3 在 Uber 抗住了 66 亿监控指标,这个量非常庞大。其主要包括4个组件:M3DB、M3 Coordinator、M3 Query、M3 Aggregator,我们当前产品中Prometheus的远程存储就是通过M3DB实现的。
1.4.3. 告警引擎 ★
用户会配置数百甚至数千条告警规则,一些超大型的公司可能要配置数万条告警规则。每个规则里含有数据过滤条件、阈值、执行频率等,有一些配置丰富的监控系统,还支持配置规则生效时段、持续时长、留观时长等。
告警引擎通常有两种架构,一种是数据触发式,一种是周期轮询式。
数据触发式,是指服务端接收到监控数据之后,除了存储到时序库,还会转发一份数据给告警引擎,告警引擎每收到一条监控数据,就要判断是否关联了告警规则,做告警判断。因为监控数据量比较大,告警规则的量也可能比较大,所以告警引擎是会做分片部署的,这样的架构,即时性很好,但是想要做指标关联计算就很麻烦,因为不同的指标哈希后可能会落到不同的告警引擎实例。
周期轮询式,通常是一个规则一个协程,按照用户配置的执行频率,周期性查询判断即可,做指标关联计算就会很容易。像 Prometheus、Nightingale、Grafana 等,都是这样的架构。
生成事件之后,通常是交给一个单独的模块来做告警发送,这个模块负责事件聚合、收敛,根据不同的条件发送给不同的接收者和不同的通知媒介。
1.4.4. 数据展示
监控数据的可视化也是一个非常通用且重要的需求,业界做得最成功的是Grafana,采用插件式架构,可以支持不同类型的数据源,图表非常丰富,基本是开源领域的事实标准。
02Prometheus入门
导读:本章首先介绍了Prometheus主要特点,然后根据特点对其局限性及架构进行剖析。读完本章,可以让读者清晰地了解如何运用Prometheus。
2.1.主要特点
PromQL多维度数据模型的灵活查询;
定义了开放指标数据的标准,自定义探针(Exporter等);
Go语言编写,拥抱云原生;
数据采集方式以pull为主、push为辅;
二进制文件直接启动、也支持容器镜像化部署;
支持多种语言客户端;
支持本地和第三方远程存储、高效的存储;
可扩展,功能分区+联邦集群;
结合Grafana可以做到出色的可视化功能;
精确告警:基于PromQL可以进行告警设置、预测等;另外还提供了分组、抑制、静默等功能防止告警风暴;
支持动态发现机制:Kubernetes;
2.2. 局限性
主要针对性能和可用性监控,不适用日志、事件、调用链等监控;
关注近期发生的事,而不是跟踪数周或数月的数据,监控数据默认保留15天;
本地存储有限,存储大量历史数据需要对接第三方远程存储;
采用联邦集群方式时,没有提供统一的全局视图。
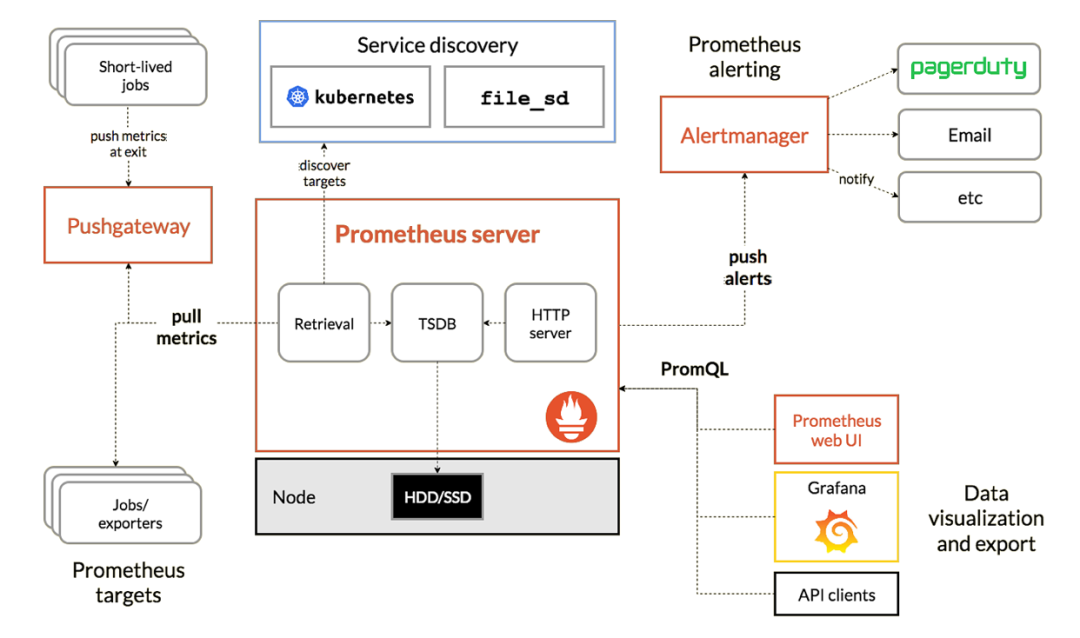
2.3. 架构剖析 ★
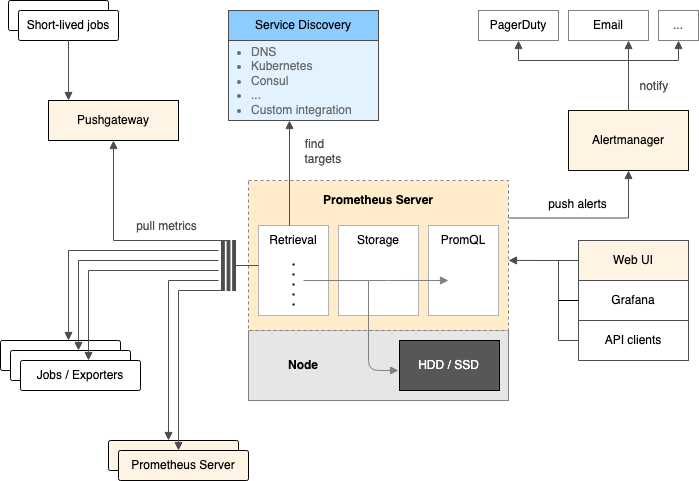
Job/Exporter
prometheus监控探针,共收录有上千种Exporter,用于对第三方系统进行监控,方式是获取第三方系统的监控数据然后按照Prometheus的格式暴露出来;没有Exporter探针的第三方系统也可以自己定制开发。
不过Exporter种类繁多会导致维护压力大,也可以考虑用Influx Data公司开源的Telegraf统一进行管理。使用Telegraf集成Prometheus比单独使用Prometheus拥有更低的内存使用率和CPU使用率。
PushGateway
是支持临时性job主动推送指标的中间网关。
使用场景:临时/短作业、批处理作业、应用程序与Prometheus之间有防火墙或不在同一个网段;
不过该解决方案存在单点故障问题、必须使用PushGateway的API从推送网关中删除过期指标。
Service Discovery(服务发现机制)
可以使用Kubernetes的API获取容器信息的变化来动态更新监控对象;
Prometheus Server(核心监控服务)
i. Retrieval(抓取)
从Job、Exporter、PushGateway3个组件中通过HTTP轮询的形式拉取指标数据;
ii. Storage(存储)
本地存储:直接保存到本地磁盘,从性能上考虑,建议使用SSD且不要保存超过一个月的数据;
远程存储:适用于存储大量监控数据,支持的远程存储包括OpenTSDB、InfluxDB、M3DB、PostgreSQL等;需要配合中间层适配器进行转换;
iii. PromQL(查询)
多维度数据模型的灵活查询。
Dashboard(可视化)
实际工作中使用Grafana,也可以调用HTTP API发送请求获取数据;
Alertmanager(告警引擎)
独立的告警组件,可以将多个AlertManager配置成集群,支持集群内多个实例间通信;
03PromQL入门
导读:本章围绕PromQL基本概念、4大选择器、4大指标类型及13种聚合操作等展开介绍,帮助读者轻松理解PromQL相关知识。
3.1. 初识PromQL ★
3.1.1. 时间序列 ★
按照一定的时间间隔产生的一个个数据点,这些数据点按照时间戳和值的生成顺序存放,得到了向量(vector)。

每条时间序列是通过指标名称和一组标签集来命名的。
矩阵中每一个点都可以称之为一个样本(Sample),主要有3方面构成:
指标(Metrics):包括指标名称(__name__)和一组标签集名称;
时间戳(TimeStamp):默认精确到毫秒;
样本值(Value):默认使用64位浮点类型。
3.1.2. 指标 ★
时间序列的指标可以基于Bigtable设计为Key-Value存储的方式:

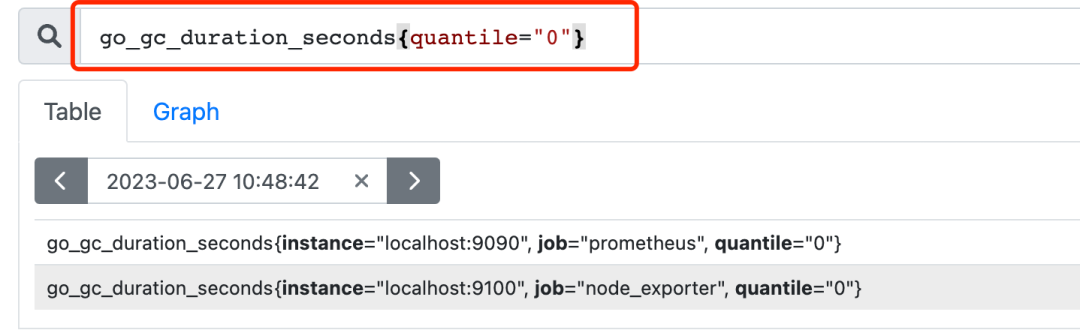
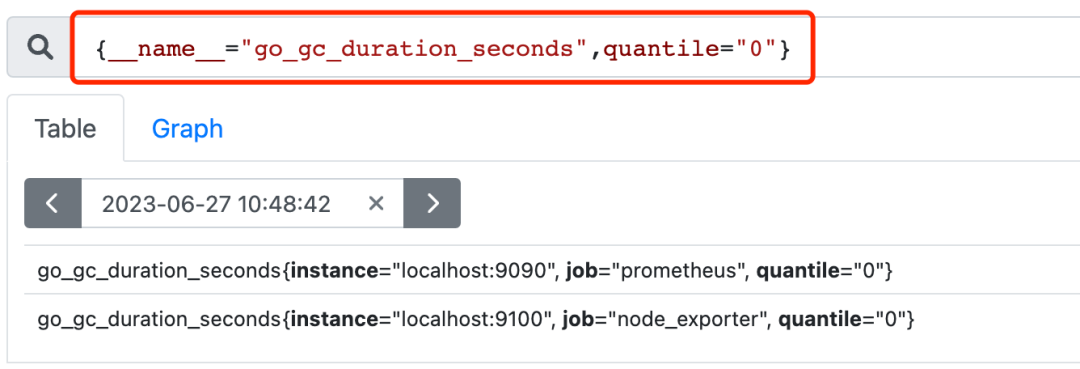
Prometheus的Metrics可以有两种表现方式(指标名称只能由ASCII字符、数字、下划线、冒号组成,冒号用来表示用户自定义的记录规则):

分别对应的查询形式(以下两个查询语句等价):
3.2. 4大选择器
3.2.1. 匹配器
相等匹配器(=):对于不存在的标签可以使用Label=""的形式查询
不等匹配器(!=):相等匹配器的否定
正则表达式匹配器(=~):前面或者后面加上".*"
所有PromQL语句必须包含至少一个有效表达式(至少一个不会匹配到空字符串的标签过滤器),因此,以下三种示例是非法的:

正则表达式相反匹配器(!~):正则表达式匹配器的否定
3.2.2. 瞬时向量选择器
用于返回在指定时间戳之前查询到的最新样本的瞬时向量。

3.2.3. 区间向量选择器
高级应用:
3.2.4. 偏移量修改器
瞬时偏移向量


高级应用:


3.3. 4大指标类型 ★
3.3.1. 计数器(Counter)★
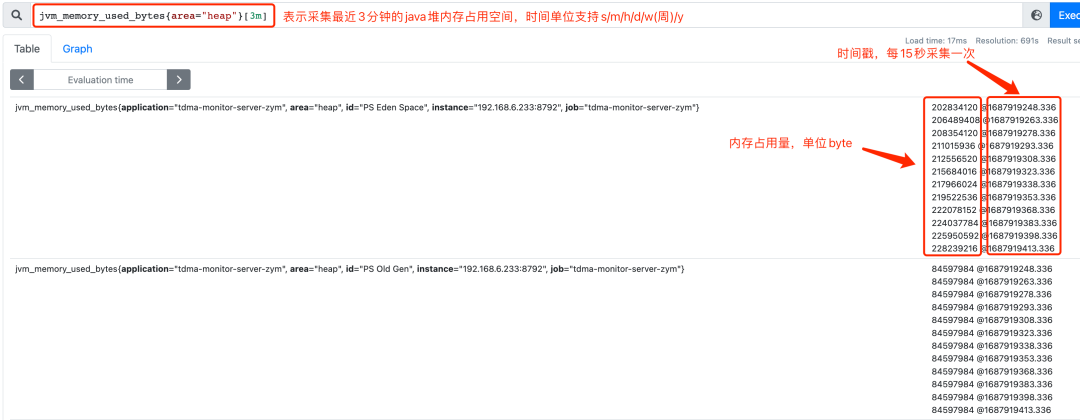
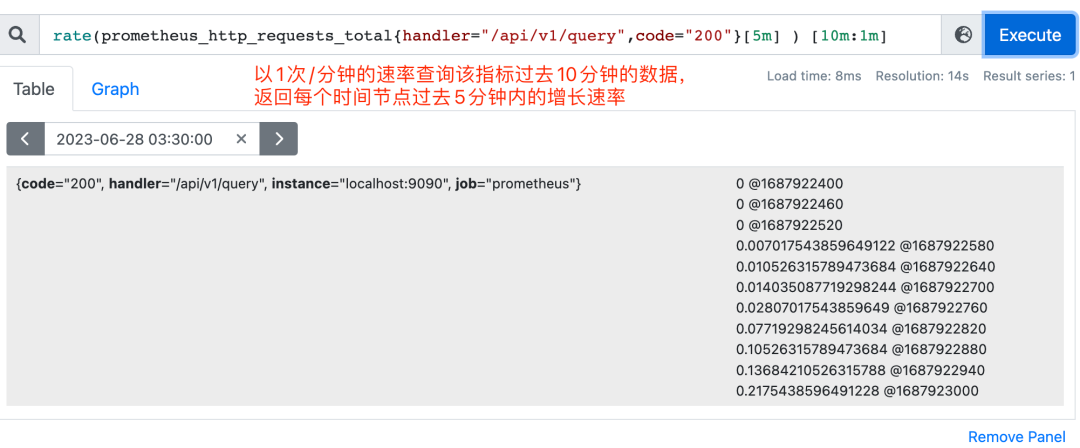
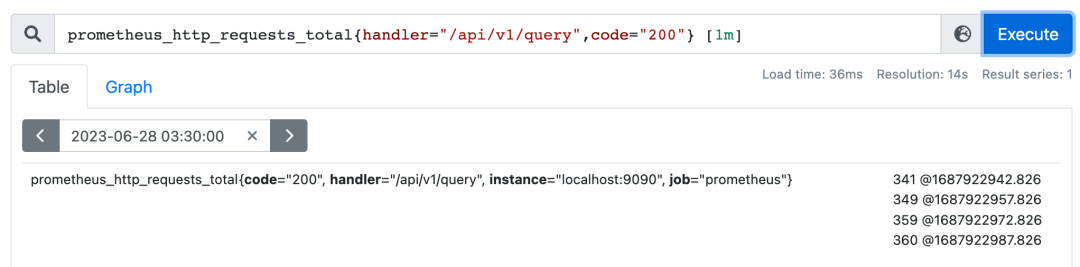
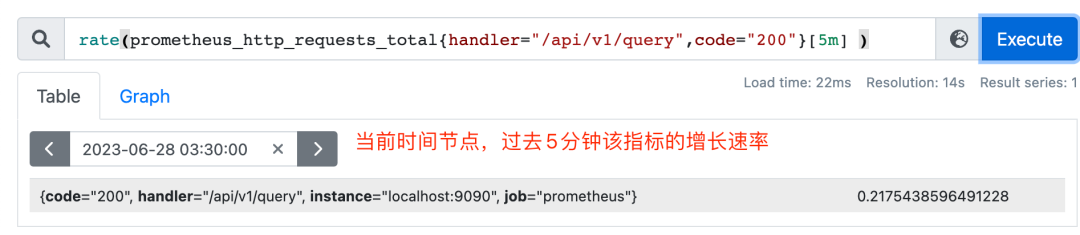
只增不减,一般配合rate(统计时间区间内增长速率)、topk(统计top N的数据)、increase等函数使用;
increase(v range-vector)获取区间向量的第一个和最后一个样本并返回其增长量:

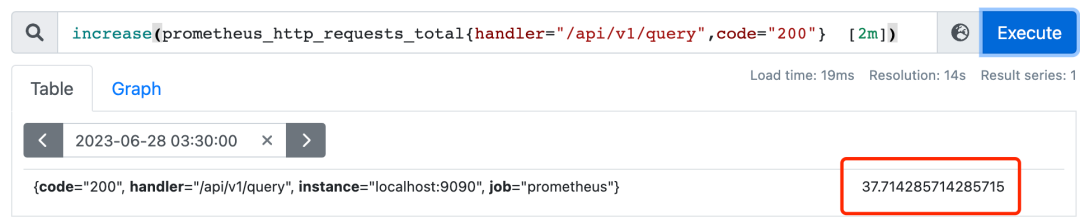
为什么increase函数算出来的值非33?真实计算公式:(360 - 327) / (1687922987 - 1687922882) * 120 = 37.71428571428571
irate(v range-vector)是针对长尾效应专门提供的用于计算区间向量的增长速率的函数,反应的是瞬时增长率,敏感度更高。长期趋势分析或告警中更推荐rate函数。
rate(v range-vector) 求取的是每秒变化率,也有数据外推的逻辑,increase 的结果除以 range-vector 的时间段的大小,就是 rate 的值。
rate(jvm_memory_used_bytes{id="PS Eden Space"}[1m]) 与 increase(jvm_memory_used_bytes{id="PS Eden Space"}[1m])/60.0 是等价的
3.3.2. 仪表盘(Gauge) ★
表示样本数据可任意增减的指标;实际更多用于求和、取平均值、最大值、最小值。
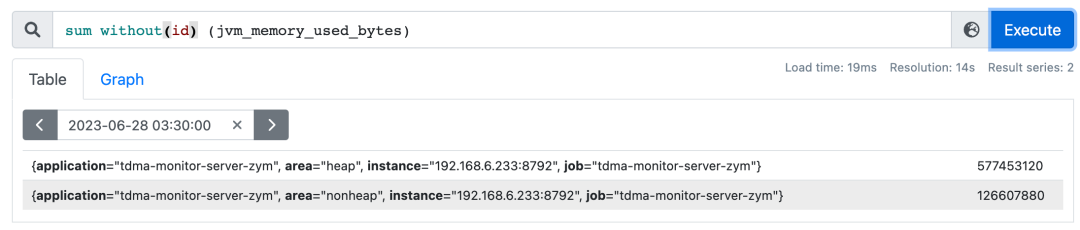
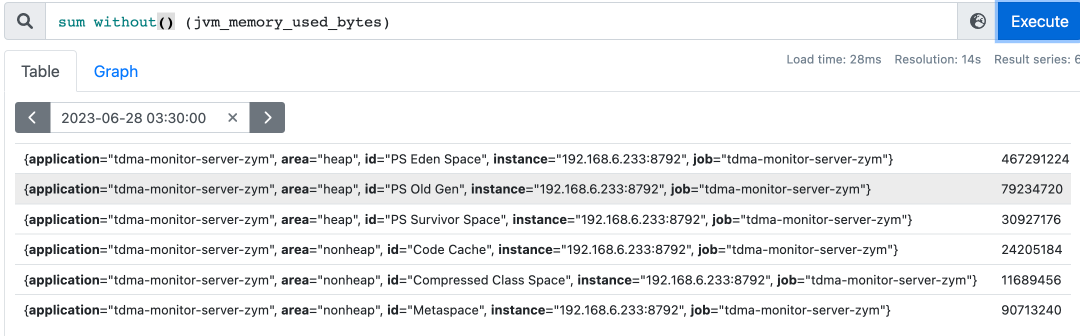
without可以让sum函数根据相同的标签进行求和,但是忽略掉without函数覆盖的标签;如上图,可以忽略掉id,只按照堆/非堆的区别进行内存空间求和。
3.3.3. 直方图(Histogram) ★
用于描述数据分布,最典型的应用场景就是监控延迟数据,计算 90 分位、99 分位的值。
有些服务访问量很高,每秒几百万次,如果要把所有请求的延迟数据全部拿到,排序之后再计算分位值,这个代价就太高了。使用 Histogram 类型,可以用较小的代价计算一个大概值。
Prometheus的Histogram类型计算原理:bucket桶排序+假定桶内数据均匀分布。
Histogram 这种做法性能有了巨大的提升,但是要同时计算成千上万个接口的分位值延迟数据,还是非常耗费资源的,甚至会造成服务端 OOM。
数据解析:http://ip:9090/metrics prometheus_http_request_duration_seconds

3.3.4. 汇总(Summary) ★
在客户端计算分位值,然后把计算之后的结果推给服务端存储,展示的时候直接查询即可。
Summary 的计算是在客户端计算的,也就意味着不是全局(整个服务)的分位值,分位值延迟数据是进程粒度的。
负载均衡会把请求均匀地打给后端的多个实例。一个实例内部计算的分位值,理论上和全局计算的分位值差别不会很大。另外,如果某个实例有故障,比如硬盘问题,导致落在这个实例的请求延迟大增,我们在实例粒度计算的延迟数据反而更容易发现问题。
数据解析:http://ip:9090/metrics go_gc_duration_seconds

3.4. 13种聚合操作
without 和 by 用来保留不同维度的可选操作符,其余11个聚合操作都是用于瞬时向量,使用相同的分组逻辑:
sum
min
max
avg
count
count_values(对value进行计数)
stddev(标准差)
stdvar(标准差异)
bottomk(样本值最小k个元素)
topk(样本值最大k个元素)
quantile(分布统计)
3.4.1. without、by ★
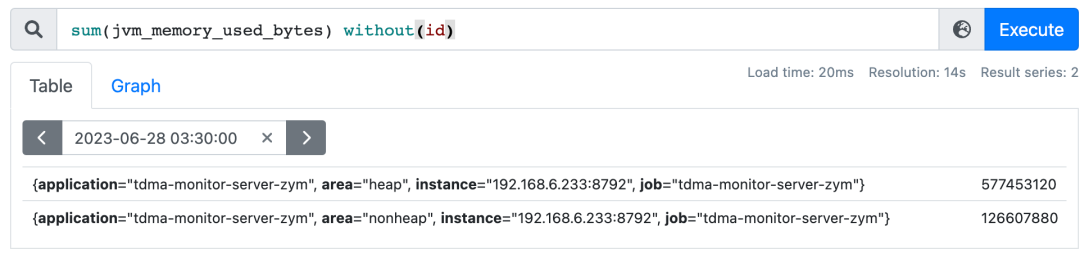
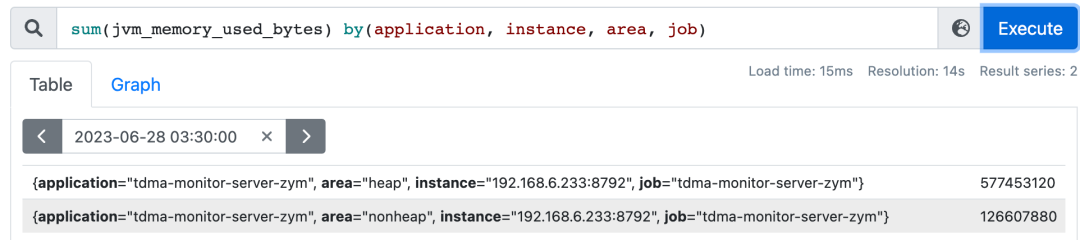
上述两个查询是等价的;同一个聚合语句中不可同时使用by和without,by的作用类似于sql语句中的分组(group by),without语义是:除开XX标签,对剩下的标签进行分组。
3.4.2. stdvar
数学中称为方差,用于衡量一组数据的离散程度:数据分布得越分散,各个数据与平均数的差的平方和越大,方差就越大。
3.4.3. stddev
标准差:用方差开算术平方根。
3.4.4. count、count_values
count:对分组中时间序列的数目进行求和
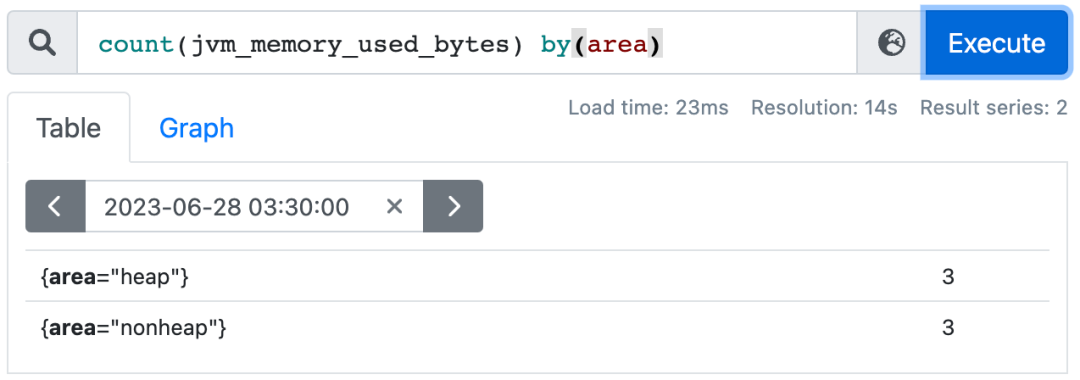
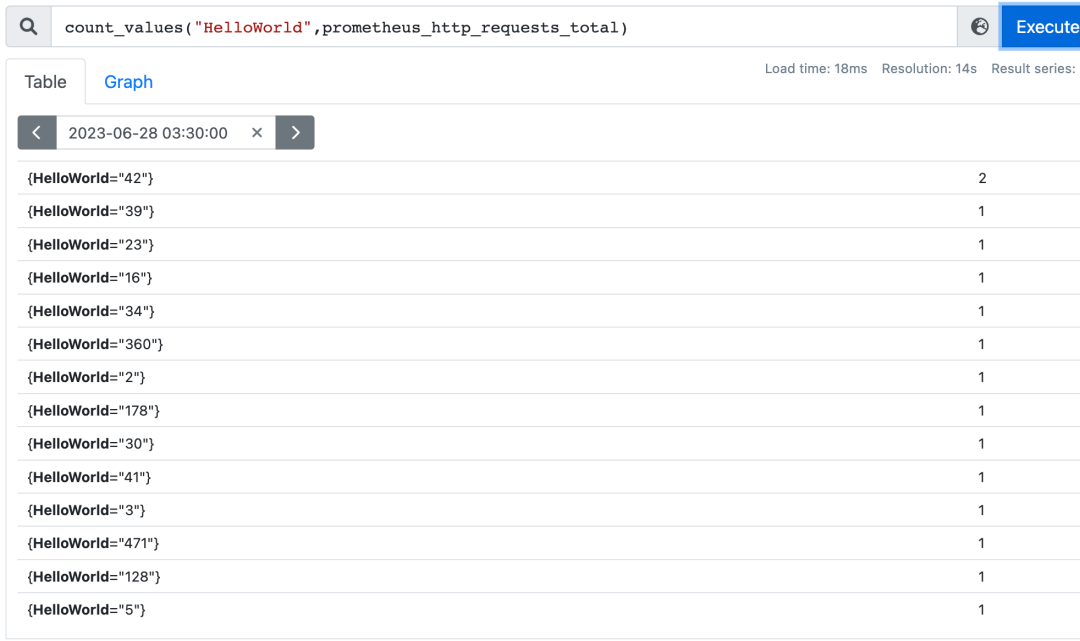
count_values:表示时间序列中每一个样本值(value)出现的次数,实践中一般用于统计版本号。
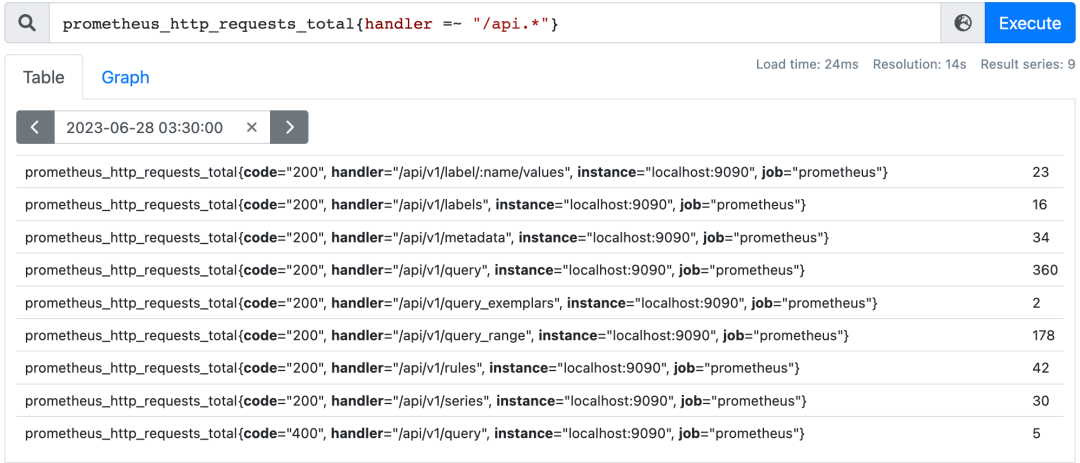
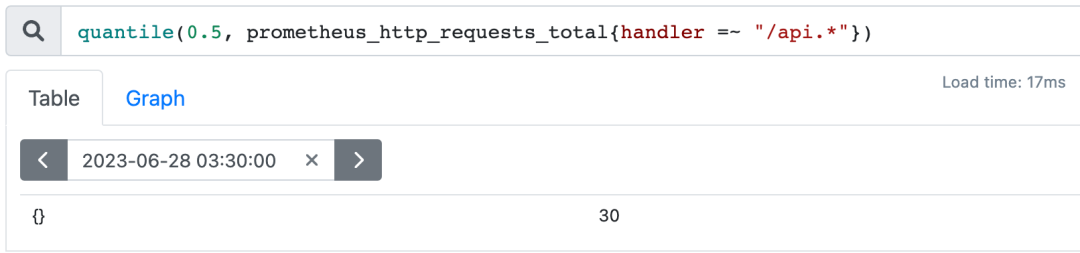
3.4.5. quantile
用于计算当前样本数据值的分布情况,例如计算一组http请求次数的中位数:
3.5. 3种二元操作符
3.5.1. 算术运算符(加减乘除模幂)
3.5.2. 集合/逻辑运算符
仅用于瞬时向量之间,and(并且)、or(或者)、unless(排除)
内置函数absent扮演了not的角色;
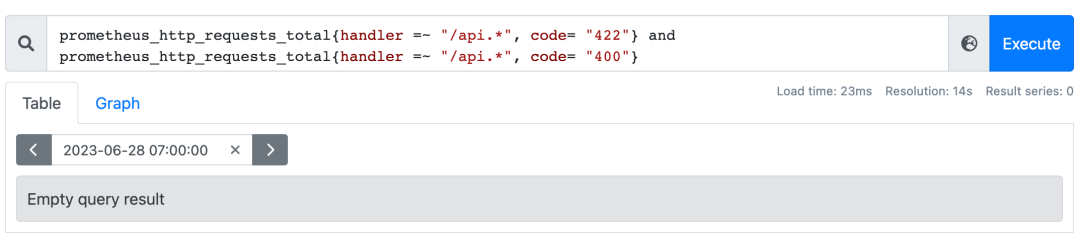
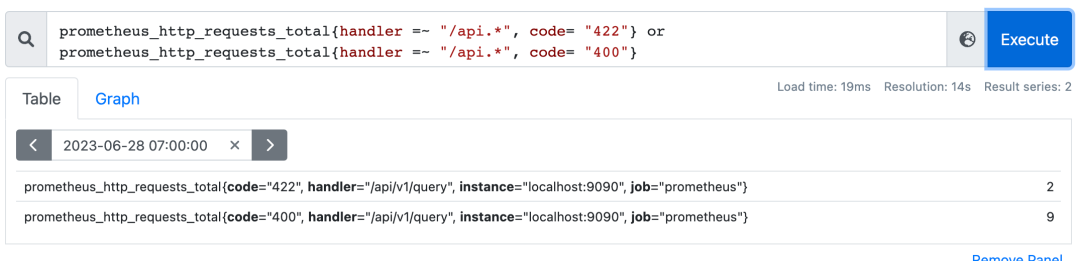
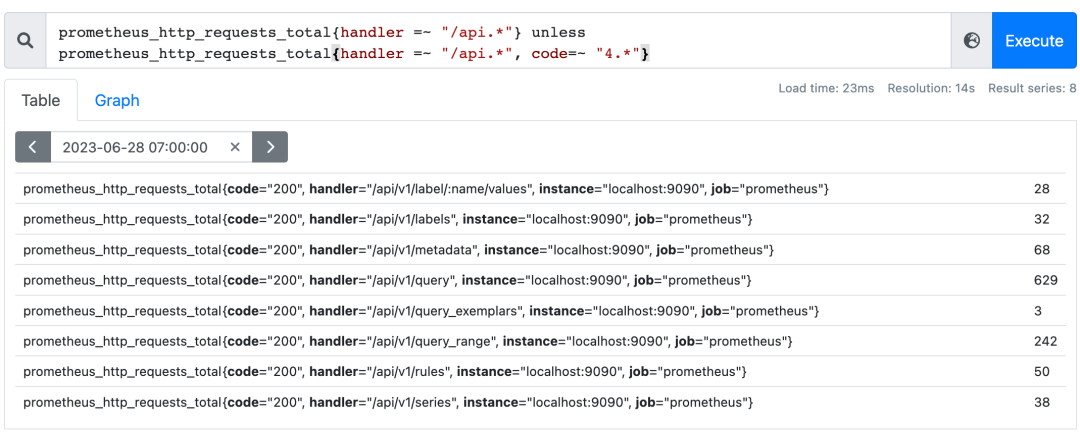
absent应用场景,配置告警规则:
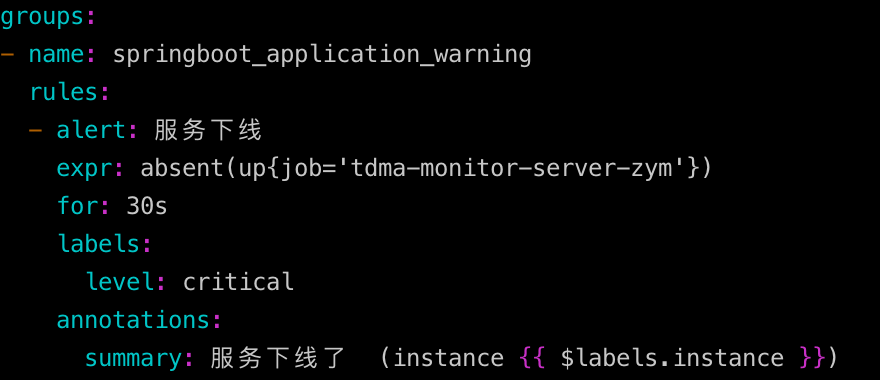
3.5.3. 比较运算符(== != > < >= <=),无需过多解释
04PromQL高级实战
导读:本章首先介绍了Prometheus内置函数,然后通过HTTP API、执行规则、指标抓取与存储等多个知识点,辅以实践案例,全方位介绍了PromQL的高级用法。
4.1. Prometheus内置函数

4.1.1. 动态标签函数 ★
提供了对时间序列标签的自定义能力。
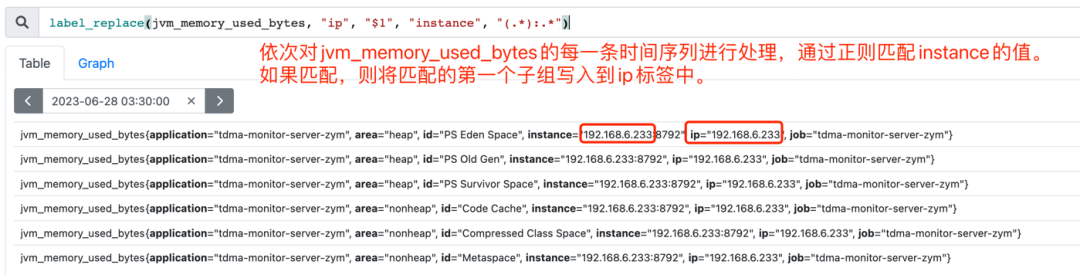
label_replace(input_vector, "dst", "replacement", "src", "regex")
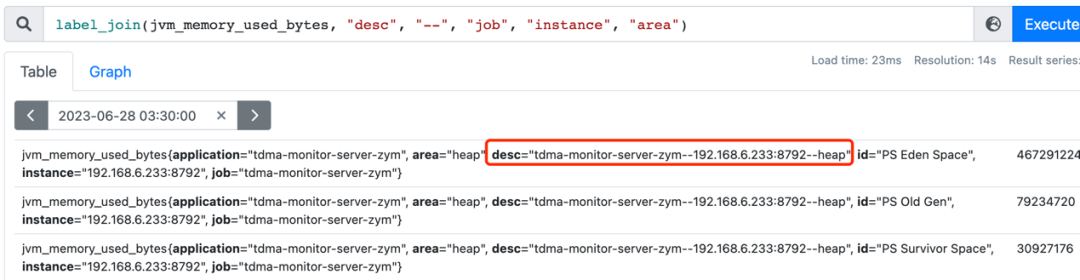
label_join(input_vector, "dst", "separator", "src_1", "src_2" ...)
4.1.2. 时间日期函数(没有时区的概念)
4.1.3. 多对多运算算函数(absent,常用于检测服务是否存活)
4.1.4. Counter函数
resets函数用于统计计数器重置次数,两个连续的样本之间值减少,被认为是一次计数器重置,相当于是进程重启次数。
4.1.5. Gauge函数
predict_linear(v range-vector, t scalar)
预测时间序列v在t秒后的值
deriv(v range-vector)
使用简单的线性回归计算区间向量v中各个时间序列的导数
delta(v range-vector)
计算区间向量内第一个元素和最后一个元素的差值:
idelta(v range-vector)
最新的两个样本值之间的差值,如上图例子,返回值为整数
holt_winters(v range-vector, sf scalar, tf scalar)
要求sf > 0, tf <= 1
霍尔特-温特双指数平滑算法,暂时想不到应用场景
changes(v range-vector)
返回区间向量中每个样本数据值变化的次数,如果样本值没有变化就返回1;
prometheus提供度量标准process_start_time_seconds记录每一个targets的启动时间,该时间被更改则意味着进程重启,可以发出循环崩溃告警:
expr:avgwtihout(instance) (changes{process_start_time_seconds [1h]}) > 3
4.1.6. 时间聚合函数

4.2. HTTP API ★
4.2.1. API响应格式
调用成功会返回2XX状态码
resultType: matrix(区间向量) | vector(瞬时向量) | scalar | string
4.2.2. 表达式查询
/api/v1/query(瞬时数据查询)
入参:PromQL表达式、时间戳、超时设置(可全局设置)
/api/v1/query_range(区间数据查询)
入参:PromQL表达式、起始时间戳、结束时间戳、查询时间步长(不能超过11000)、超时设置(可全局设置)
4.2.3. 其他拓展
/api/v1/targets(获取监控对象列表)
/api/v1/rules(获取告警规则数据)
/api/v1/alerts(获取告警列表)
/api/v1/alertmanagers(获取关联的告警引擎)
/api/v1/targets/metadata(获取监控对象元数据)
/api/v1/metadata(获取指标元数据)
/status(prometheus配置、版本等数据)
TSDB管理API
启动参数带上--web.enable-admin-api
执行以下命令可对数据库进行备份:
curl -X POST http://your_ip:9090/api/v1/admin/tsdb/snapshot
备份目录:/prometheus/data/snapshot
删除序列:
http://your_ip:9090/api/v1/admin/tsdb/delete_series
释放空间:http://your_ip:9090/api/v1/admin/tsdb/clean_tombstones
4.3. 可定期执行的规则
4.3.1. 记录规则
预先计算经常需要用到的或计算量较大的表达式,并将结果保存为一组新的时间序列。
4.3.2. 告警规则
4.4. 指标的抓取与存储 ★
抓取前依赖服务发现,通过relabel_configs的方式自动对服务发现的目标进行重新标记;
抓取后主要指标保存在存储系统之前,依赖作业内的metrics_relabel_configs实现。
4.4.1. 用relabel_configs抓取指标 ★

重写instance实现告警同时显示服务名+IP端口
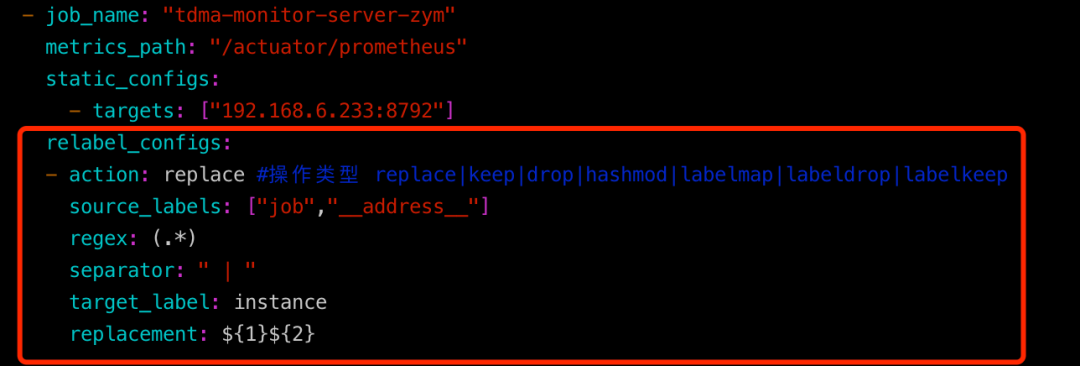
4.4.2. 用metrics_relabel_configs抓取指标将监控不需要的数据直接丢掉,不在prometheus保存,配置方法类似。
05告警引擎深度解析
导读:本章拓展了Alertmanager架构解析、Alertmanager配置文件、告警应用与问题处理等众多知识点。
5.1. Alertmanager架构解析 ★
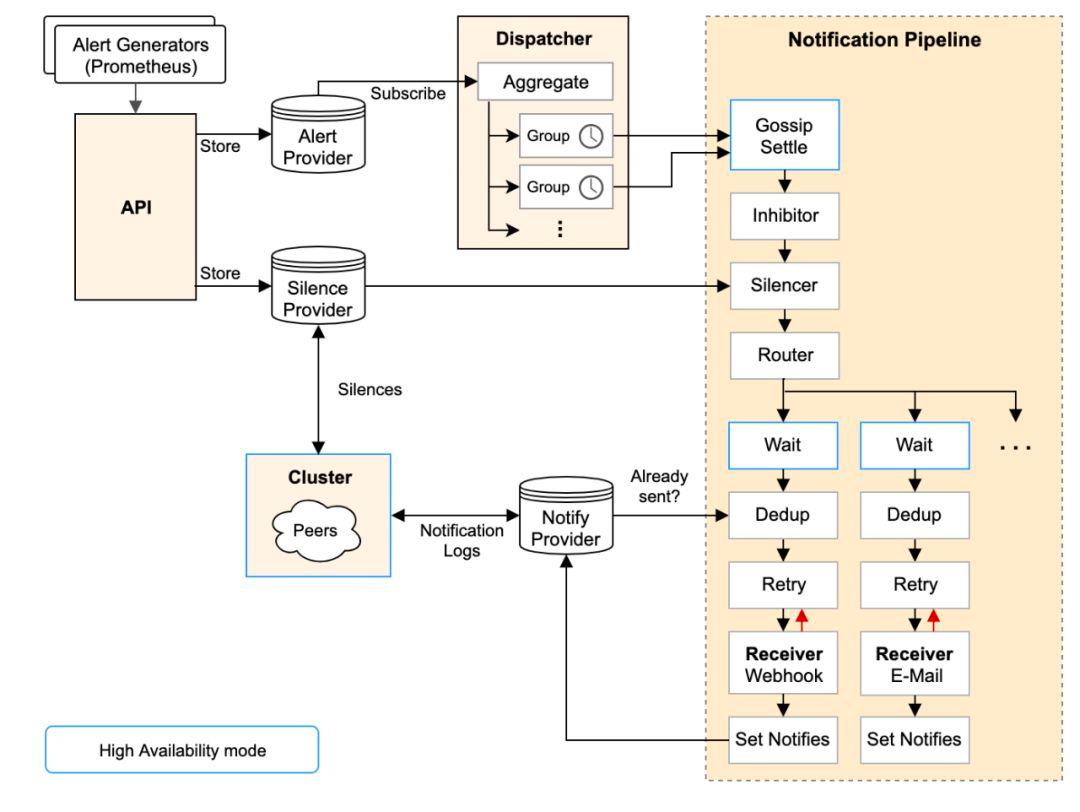
从左上开始,Prometheus 发送的警报到 Alertmanager;
警报会被存储到 AlertProvider 中,Alertmanager 的内置实现就是包了一个 map,也就是存放在本机内存中,这里可以很容易地扩展其它 Provider;
Dispatcher 是一个单独的 goroutine,它会不断到 AlertProvider 拉新的警报,并且根据 YAML 配置的 Routing Tree 将警报路由到一个分组中;
分组会定时进行 flush (间隔为配置参数中的 group_interval), flush 后这组警报会走一个 Notification Pipeline 链式处理;
Notification Pipeline 为这组警报确定发送目标,并执行抑制逻辑,静默逻辑,发送与重试逻辑,实现警报的最终投递;
5.2. Alertmanager配置文件解读 ★
全局配置(global):定义一些全局的公共参数,如全局SMTP设置、Slack配置等;
模板(template):定义告警通知的模板,如HTML模板、邮件模板;
告警路由(route):告警的分组聚合,根据自定义标签匹配,确定当前告警应该如何处理;
接收者(receivers):邮箱、webhook等,一般配合告警路由使用;
抑制规则(inhibit_rules):减少垃圾告警产生;

5.3. 关于告警的应用与问题处理 ★
关键配置参数:
prometheus.yml
scrape_interval:prometheus从采集器抓取数据间隔,默认1分钟;
scrape_timeout:数据抓取超时时间,默认10秒钟;
evaluation_interval:评估告警规则的时间间隔(即多长时间计算一次告警规则是否触发),默认1分钟;
alertmanager.yml
group_wait:初始等待时间,一组告警消息第一次发送前的等待时间,在这个时间内允许为同一组告警收集更多初始告警,此参数的作用是防止短时间内出现大量告警的情况下,接收者被消息淹没。【此参数建议设置为0到5分钟】。
group_interval:睡眠/唤醒周期,一组告警消息被成功发送后,会进入睡眠/唤醒周期,此参数是睡眠状态将持续的时间,在睡眠状态下该组消息可能会有明细内容变化。睡眠结束后进入唤醒状态,如果检查到有明细内容存在变化,则发送新告警消息;如果没有变化,则判断是否达到“重复发送间隔时间”来决定是否发送。【此参数建议设置为5到30分钟】。
repeat_interval:重复发送间隔时间,此参数是指同一个消息组在明细内容不变的情况下,连续多长时间不发送告警消息。不过此参数值并不代表告警的实际重复间隔,因为在上一次发送消息后并等待了“重复发送间隔时间”的时刻,该消息组可能处在睡眠状态;所以实际的告警间隔应该大于“重复发送间隔时间”且小于“重复发送间隔时间”与“睡眠/唤醒周期”之和。【此参数建议设置为3小时以上】。
06本地存储与远程存储
导读:本章主要分析了压缩算法、本地存储文件结构、存储原理、M3DB远程存储技术,并对使用过程中可能出现的问题给出了指导和建议。
6.1. 压缩算法
lPrometheus本地存储经历过多个迭代:V1.0(2012年)、V2.0(2015年)、V3.0(2017年)。最初借用第三方数据库LevelDB,1.0版本性能不高,每秒只能存储5W个样本;2.0版本借鉴了Facebook Gorilla压缩算法,将每个时序数据以单个文件方式保存,将性能提升到每秒存储8W个样本;2017年开始引入时序数据库的3.0版本,并成立了Prometheus TSDB开源项目,该版本在单机上提高到每秒存储百万个样本。
3.0版本保留了2.0版本高压缩比的分块保存方式,并将多个分块保存到一个文件中,通过创建一个索引文件避免产生大量的小文件;同时为了防止数据丢失,引入了WAL机制。

6.2. 本地存储文件结构解析
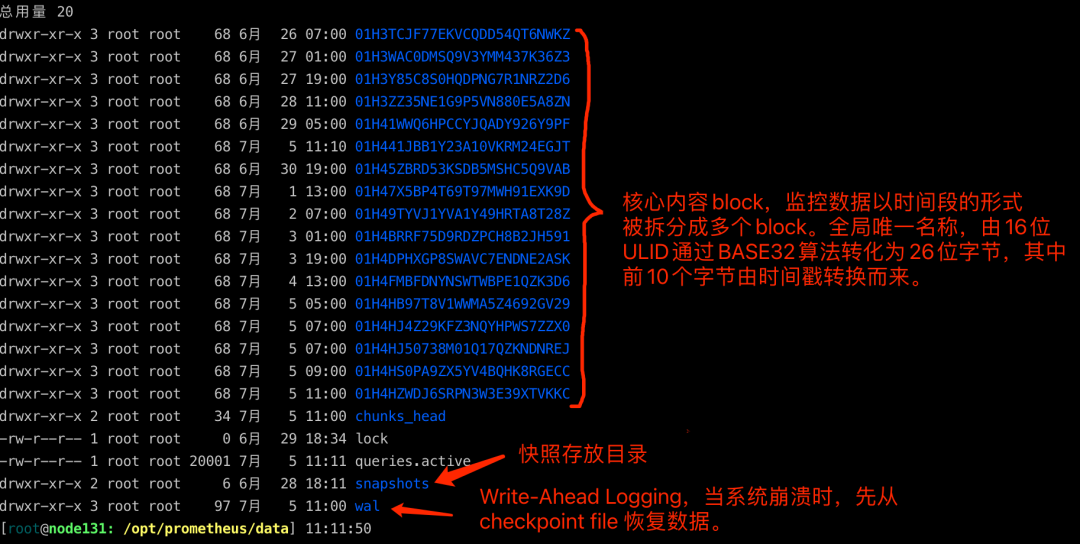

6.3. 存储原理解析
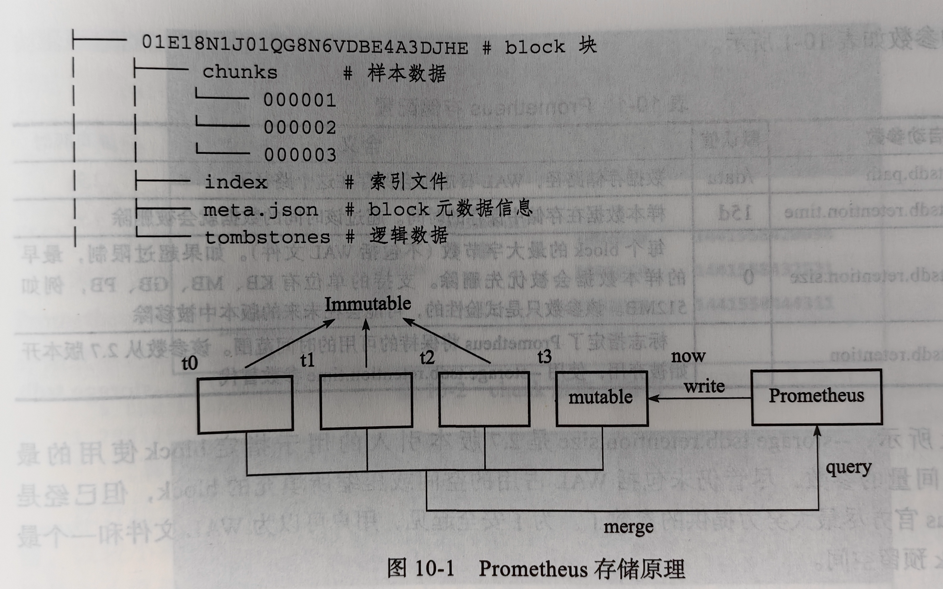
按时间顺序生成多个block文件,其中第一个block称为head block,存储在内存中且允许被修改,其它block文件则以只读的方式持久化在磁盘上。
抓取数据时,Prometheus周期性的将监控数据以chunk的形式添加到head block中,同时写日志。会按2小时一个block的速率进行磁盘持久化。
崩溃后再次启动会以写入日志的方式实现重播,从而恢复数据。
2小时的block会在后台压缩成更大的block,数据被压缩合并成更高级别的block文件后删除低级别的block文件。
6.4. M3DB远程存储技术
6.4.1. M3特性
主要包括4个组件:M3DB、M3 Coordinator、M3 Query、M3 Aggregator
M3DB:分布式时序库,为时间序列数据和反向索引提供了可伸缩、可扩展的存储。
M3 Coordinator:辅助服务,用于协调上游系统(如Prometheus和M3DB)之间的读写操作,是用户访问M3DB的桥梁。
M3 Query:分布式查询引擎,可查询实时和历史指标,支持多种不同的查询语言(包括PromQL)。
M3 Aggregator:聚合层,作为专用度量聚合器运行的服务。
6.4.2. M3DB特性
分布式时间序列存储,单个节点使用WAL提交日志并独立保存每个分片的时间窗口。
集群管理建立在etcd之上(分布式服务注册中心)。
内置同步复制功能,具有可配置的持久性和读取一致性。
自定义压缩算法M3TSZ float64。
6.4.3. M3DB限制
M3DB主要是为了减少摄取和存储数十亿个时间序列的成本并提供快速可伸缩的读取,因此存在一些限制,不适合用作通用时序库。
M3DB旨在尽可能避免压缩,目前M3DB仅在可变压缩时间序列窗口内执行压缩,因此乱序写入仅限单个压缩时间序列窗口的大小。
M3DB针对float64值的存储和检索进行优化,无法将其用作包含任意数据结构的通用时序库。
6.4.4. M3DB分布式架构
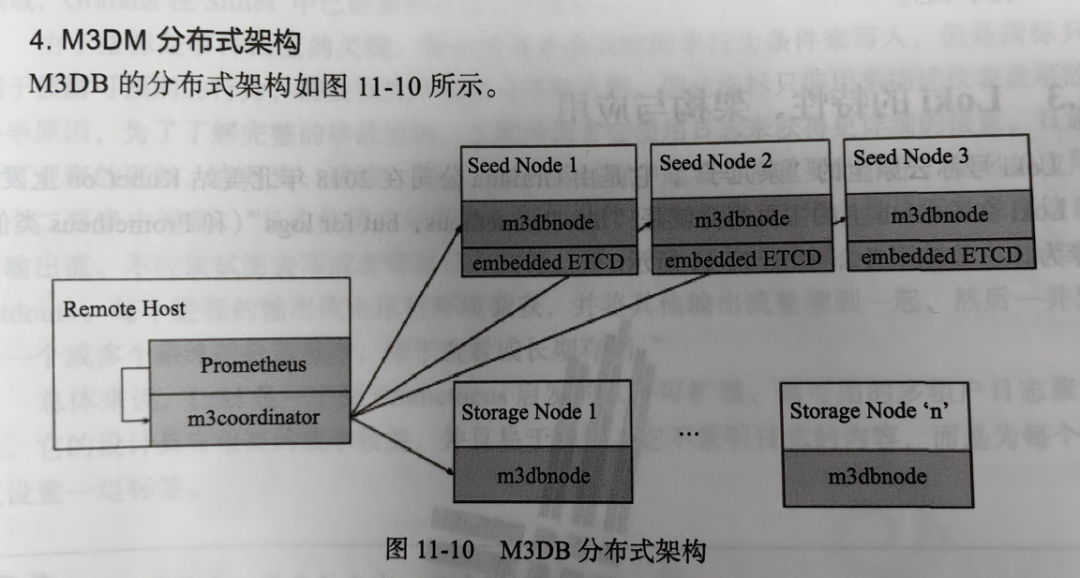
Coordinator:m3coordinator用于协调群集中所有主机之间的读取和写入。这是一个轻量级的过程,不存储任何数据。该角色通常将与Prometheus实例一起运行。
Storage Node:在这些主机上运行的m3dbnode进程是数据库的主力,它们存储数据,并提供读写功能。
Seed Node:首先,这些主机本身就是存储节点。除了该职责外,他们还运行嵌入式ETCD服务器。这是为了允许跨集群运行的各种M3DB进程以一致的方式推断集群的拓扑/配置。
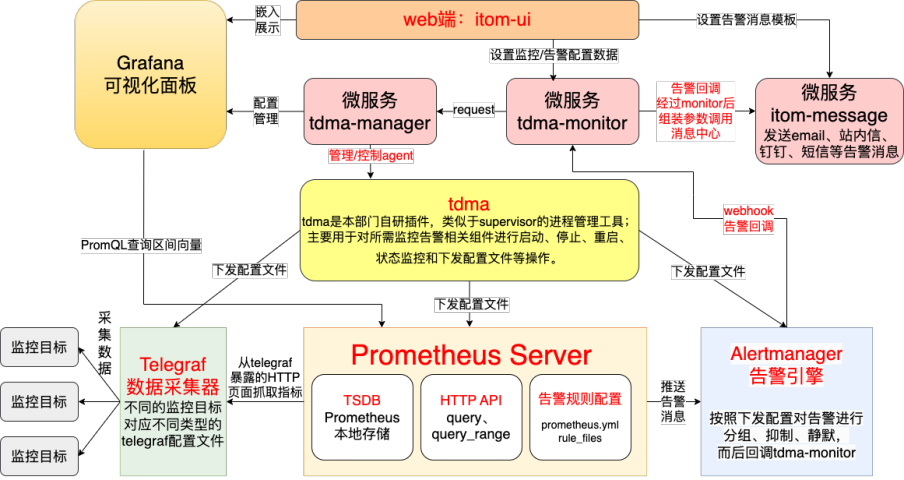
07梯度运维管理平台监控模块架构 ★
审核编辑:彭菁
- 相关推荐
- 模块
- 存储
- 监控系统
- Prometheus
-
nRF52832开发指南-下册2022-06-16 895
-
单片机实用开发指南 目录2006-03-21 876
-
单片机实用开发指南2006-03-21 1209
-
CPLD FPGA高级应用开发指南2010-04-15 424
-
Tiny6410 Linux开发指南详解2011-07-08 1852
-
A64开发板LCD开发指南2016-06-21 1008
-
横版排插开发指南2016-12-29 711
-
电热毯开发指南2016-12-29 929
-
彩光灯开发指南2016-12-29 780
-
取暖器-油汀开发指南2016-12-25 1086
-
《Android基础及典型案例开发指南》--创新移动开发系列2017-02-08 812
-
nRF52832开发指南-上册2022-06-16 1311
-
Tina Linux配置开发指南2023-03-02 16462
-
Linux NOR开发指南2023-03-06 968
-
LVGL开发指南介绍2024-09-09 1488
全部0条评论

快来发表一下你的评论吧 !
