

C++环形缓冲区设计与实现
描述
一、环形缓冲区基础理论解析(Basic Theory of Circular Buffer)
1.1 环形缓冲区的定义与作用(Definition and Function of Circular Buffer)
环形缓冲区(Circular Buffer),也被称为循环缓冲区(Cyclic Buffer)或者环形队列(Ring Buffer),是一种数据结构类型,它在内存中形成一个环形的存储空间。环形缓冲区的特点是其终点和起点是相连的,形成一个环状结构。这种数据结构在处理流数据和实现数据缓存等场景中具有广泛的应用。
环形缓冲区的主要作用是存储和管理数据。它可以存储一定数量的数据,并且在数据存储满后,新的数据会覆盖最早的数据,从而实现了一种“先进先出”(FIFO)的数据管理方式。这种数据结构的优点是可以高效地利用有限的缓存空间,避免了数据的丢失,并且可以在多线程环境中实现数据的同步处理。
环形缓冲区的基本操作主要包括:插入数据(Push)、删除数据(Pop)、读取数据(Read)和写入数据(Write)。其中,插入数据和删除数据操作会改变环形缓冲区的头部和尾部指针,而读取数据和写入数据操作则不会改变这些指针。
环形缓冲区的设计和实现需要考虑多种因素,包括缓冲区的大小、数据的存储方式、数据的读写策略、线程同步机制等。在实际应用中,环形缓冲区的设计需要根据具体的需求和场景进行定制,以实现最优的性能和效率。
1.2 环形缓冲区的基本原理(Basic Principle of Circular Buffer)
环形缓冲区的基本原理主要涉及到其数据存储方式和数据操作方式。
数据存储方式
环形缓冲区在内存中的存储形式就像一个环,它的起点和终点是相连的。这种存储方式的主要优点是可以有效地利用有限的内存空间,避免了数据的丢失,并且可以在多线程环境中实现数据的同步处理。
环形缓冲区通常使用一个一维数组来实现,数组的大小就是缓冲区的容量。在这个数组中,我们使用两个指针,一个是头指针(head),另一个是尾指针(tail)。头指针指向缓冲区中的第一个元素,尾指针指向缓冲区中的最后一个元素。
数据操作方式
环形缓冲区的数据操作主要包括插入数据(Push)、删除数据(Pop)、读取数据(Read)和写入数据(Write)。
- 插入数据(Push):当我们向环形缓冲区中插入数据时,数据会被存储在尾指针指向的位置,然后尾指针会向前移动一位。如果尾指针已经到达数组的末尾,那么它会回到数组的起始位置。如果尾指针追上了头指针,那么这意味着缓冲区已满,不能再插入新的数据。
- 删除数据(Pop):当我们从环形缓冲区中删除数据时,头指针指向的数据会被删除,然后头指针会向前移动一位。如果头指针已经到达数组的末尾,那么它会回到数组的起始位置。如果头指针追上了尾指针,那么这意味着缓冲区已空,不能再删除数据。
- 读取数据(Read):读取数据操作不会改变头指针和尾指针的位置,它只会返回头指针指向的数据。
- 写入数据(Write):写入数据操作会将数据写入尾指针指向的位置,然后尾指针会向前移动一位。如果尾指针追上了头指针,那么这意味着缓冲区已满,不能再写入新的数据。
通过以上的操作,环形缓冲区实现了一种“先进先出”(FIFO)的数据管理方式。在下一节中,我们将探讨环形缓冲区的应用场景,以及如何根据具体的需求和场景设计和实现环形缓冲区。
1.3 环形缓冲区的应用场景(Application Scenarios of Circular Buffer)
环形缓冲区作为一种高效的数据结构,广泛应用于各种场景,主要包括:
- 数据流处理:在处理音频、视频、网络数据流等连续数据时,环形缓冲区可以作为一个缓存,存储即将处理的数据。这样可以保证数据的连续性和实时性,提高数据处理的效率。
- 生产者-消费者问题:在多线程编程中,环形缓冲区可以作为一个共享缓存,解决生产者和消费者之间的数据同步问题。生产者将数据放入缓冲区,消费者从缓冲区取出数据,通过控制缓冲区的大小和数据的读写速度,可以有效地解决生产者和消费者之间的速度不匹配问题。
- 日志记录:在系统或应用程序的日志记录中,环形缓冲区可以用来存储最近的日志信息。当新的日志信息产生时,旧的日志信息会被覆盖,这样可以有效地控制日志文件的大小,避免日志文件过大导致的存储空间浪费。
- 实时系统:在实时系统中,环形缓冲区可以用来存储实时数据,如传感器数据、状态信息等。通过环形缓冲区,可以实现数据的实时更新和读取,满足实时系统的需求。
1.4 为什么需要环形队列?
环形队列(Circular Queue)或环形缓冲区(Circular Buffer)是一种特殊的线性数据结构,它在某些特定的应用场景下,相比于标准库提供的线性数据结构(如std::queue或std::deque),具有一些独特的优势:
- 高效的元素循环:环形队列的主要特点是队列的末端和开始是相连的,形成一个环状结构。这意味着当队列满时,新的元素可以直接覆盖旧的元素,无需移动其他元素。这在处理流数据或者需要固定长度历史记录的场景中非常有用。
- 并发控制:在多线程环境下,环形队列可以通过简单的指针或索引操作实现线程安全的读写,而无需复杂的锁机制或者额外的数据复制。这对于高性能或者实时系统来说是非常重要的。
- 内存使用优化:环形队列通常在创建时预分配固定大小的内存,这样可以避免动态分配和释放内存带来的性能开销,也可以更好地控制内存使用。
- 数据覆盖:在某些应用中,我们可能只关心最新的数据,而对旧的数据不再需要。环形队列可以自动覆盖最旧的数据,这样可以节省存储空间,同时也避免了手动删除数据的需要。
因此,虽然C++标准库中已经提供了很多强大的数据结构,但是在特定的应用场景下,自定义的环形队列可能会更加高效和方便。
1.4.1 环形队列与std数据结构在不同操作上的比较
下面是一个环形队列与std数据结构在不同操作上的比较表格:
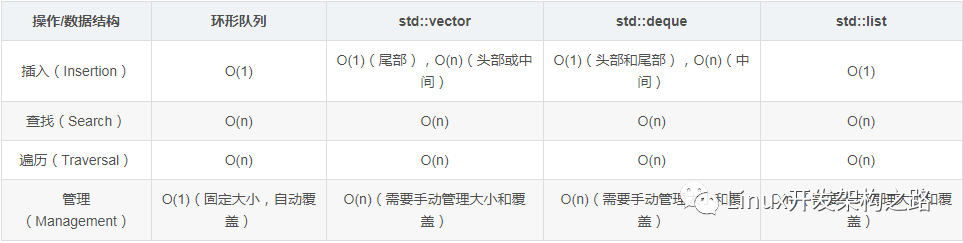
注意:这里的时间复杂度是大O表示法,表示的是最坏情况下的时间复杂度。在实际使用中,不同的数据结构在不同的使用场景和数据分布下,性能可能会有所不同。
1.4.2 在不同的应用场景下环形队列和std数据结构的优劣
在不同的应用场景下,环形队列和std数据结构的优劣也会有所不同。下面是一个简单的比较:

注意:这里的评价是相对的,实际使用中应根据具体的应用需求和场景来选择合适的数据结构。
二、环形缓冲区的设计思路
2.1 数据结构的选择
在设计环形缓冲区(Circular Buffer)时,首先要考虑的就是数据结构的选择。数据结构是存储和组织数据的方式,它决定了数据的存取效率,因此选择合适的数据结构对于环形缓冲区的性能至关重要。
环形缓冲区的基本需求是能够快速地进行数据的插入和删除操作,同时还需要能够方便地访问缓冲区的头部和尾部数据。因此,我们需要选择一种能够满足这些需求的数据结构。
在C++中,有几种数据结构可以满足我们的需求:
- 数组(Array):数组是一种连续的内存空间,可以通过索引快速访问任意位置的数据。但是,数组的大小在创建时就已经固定,不能动态扩展,这对于环形缓冲区来说可能会造成空间的浪费。此外,数组在插入和删除数据时需要移动大量的数据,效率较低。
- 链表(Linked List):链表是一种动态的数据结构,可以方便地进行数据的插入和删除操作。但是,链表需要额外的空间存储指向下一个节点的指针,这会增加内存的开销。此外,链表不能通过索引直接访问数据,需要从头节点开始逐个遍历,效率较低。
- 双端队列(Deque):双端队列结合了数组和链表的优点,可以快速地进行数据的插入和删除操作,同时还可以通过索引快速访问数据。双端队列的大小可以动态扩展,不会造成空间的浪费。因此,双端队列是实现环形缓冲区的理想选择。
在实际的设计中,我们可以选择使用C++的标准库中的std::deque来实现环形缓冲区。std::deque是一个双端队列,支持在头部和尾部进行高效的插入和删除操作,同时还支持随机访问。此外,std::deque的大小可以动态扩展,不会造成空间的浪费。
然而,std::deque并不支持环形的数据访问,我们需要在此基础上进行扩展,实现一个支持环形访问的数据结构。具体的实现方法,我们将在后续的章节中详细介绍。
2.2 环形缓冲区的实现
在选择了双端队列作为我们的基础数据结构后,我们需要在此基础上进行扩展,实现一个支持环形访问的数据结构。环形缓冲区的主要特点是,当数据填满缓冲区后,新的数据会覆盖掉最旧的数据,形成一个环形的数据流。
为了实现这个特性,我们需要在双端队列的基础上增加两个指针,一个是头指针(head),指向缓冲区的第一个元素,另一个是尾指针(tail),指向缓冲区的最后一个元素。当我们向缓冲区中插入数据时,尾指针向前移动;当我们从缓冲区中读取数据时,头指针向前移动。当头指针和尾指针相遇时,表示缓冲区已满,新的数据会覆盖掉最旧的数据。
在C++中,我们可以使用迭代器(iterator)来实现这两个指针。迭代器是一种可以遍历容器中元素的对象,通过迭代器,我们可以方便地访问和修改容器中的元素。在std::deque中,我们可以使用begin()函数获取头指针,使用end()函数获取尾指针。
在实现环形缓冲区时,我们还需要考虑线程安全的问题。在多线程环境中,如果有多个线程同时访问和修改缓冲区,可能会导致数据的不一致。为了解决这个问题,我们需要在访问和修改缓冲区时加锁,保证同一时间只有一个线程可以操作缓冲区。在C++中,我们可以使用std::mutex来实现这个功能。
以上就是环形缓冲区的基本实现思路。在后续的章节中,我们将详细介绍如何在C++中实现一个线程安全的环形缓冲区。
2.3 线程安全的环形缓冲区
在多线程环境中,线程安全是我们需要特别关注的问题。线程安全的环形缓冲区需要保证在多个线程同时访问和修改缓冲区时,数据的一致性和完整性。为了实现这个目标,我们需要使用互斥锁(mutex)和条件变量(condition variable)。
2.3.1 互斥锁
互斥锁是一种同步机制,用于保护共享资源不被多个线程同时访问。在C++中,我们可以使用std::mutex类来创建互斥锁。当一个线程需要访问共享资源时,它需要先锁定互斥锁,如果互斥锁已经被其他线程锁定,那么这个线程就会阻塞,直到互斥锁被解锁。当线程访问完共享资源后,它需要解锁互斥锁,以允许其他线程访问共享资源。
在我们的环形缓冲区中,共享资源就是双端队列m_queue。因此,我们需要在每次访问m_queue时都锁定互斥锁。在C++中,我们可以使用std::lock_guard类来自动管理互斥锁的锁定和解锁。
2.3.2 条件变量
条件变量是一种同步机制,用于在多个线程之间传递信号。在C++中,我们可以使用std::condition_variable类来创建条件变量。
在我们的环形缓冲区中,我们需要两个条件变量,一个用于通知生产者线程缓冲区已满,需要停止生产;另一个用于通知消费者线程缓冲区已空,需要停止消费。当生产者线程向缓冲区中添加数据时,如果缓冲区已满,那么生产者线程就会等待“缓冲区已满”的条件变量;当消费者线程从缓冲区中读取数据时,如果缓冲区已空,那么消费者线程就会等待“缓冲区已空”的条件变量。
通过互斥锁和条件变量的配合使用,我们可以实现一个线程安全的环形缓冲区。在后续的章节中,我们将详细介绍如何在C++中实现这个功能。
2.4 功能与性能的权衡(Trade-off between Function and Performance)
在设计环形缓冲区时,我们需要在功能和性能之间做出权衡。这是因为,一方面,我们希望环形缓冲区具有丰富的功能,例如支持多线程、支持不同类型的数据、支持动态扩容等;另一方面,我们希望环形缓冲区具有高性能,例如快速的读写速度、低延迟、低内存占用等。然而,这两方面往往是相互矛盾的,增加功能往往会降低性能,提高性能往往会牺牲功能。
2.4.1 功能的考虑
在功能方面,我们需要考虑以下几个问题:
- 数据类型:环形缓冲区需要支持什么类型的数据?是否需要支持多种类型的数据?
- 多线程支持:环形缓冲区是否需要支持多线程?如果需要,如何保证线程安全?
- 动态扩容:环形缓冲区是否需要支持动态扩容?如果需要,如何实现?
- 其他功能:环形缓冲区是否需要支持其他功能,例如数据的排序、查找、删除等?
2.4.2 性能的考虑
在性能方面,我们需要考虑以下几个问题:
- 读写速度:环形缓冲区的读写速度如何?如何提高读写速度?
- 延迟:环形缓冲区的延迟如何?如何降低延迟?
- 内存占用:环形缓冲区的内存占用如何?如何降低内存占用?
- 其他性能指标:环形缓冲区的其他性能指标,例如CPU占用、I/O吞吐量等如何?
在设计环形缓冲区时,我们需要根据实际需求,对这些功能和性能进行权衡,以达到最优的设计。在后续的章节中,我们将详细介绍如何在功能和性能之间做出权衡。
2.5 环形缓冲区设计的优缺点(Advantages and Disadvantages of Circular Buffer Design)
环形缓冲区作为一种常用的数据结构,其设计具有一些显著的优点,但同时也存在一些缺点。理解这些优缺点有助于我们更好地利用环形缓冲区,以及在需要时进行适当的优化。
2.5.1 优点
- 高效的内存利用:环形缓冲区通过在内存中创建一个循环的空间,使得当缓冲区满时,新的数据可以覆盖旧的数据,从而实现内存的高效利用。
- 快速的数据访问:环形缓冲区通过维护一个头指针和一个尾指针,可以快速地进行数据的读写操作,其时间复杂度为O(1)。
- 支持并发操作:环形缓冲区可以通过使用适当的同步机制(如互斥锁和条件变量)来支持多线程或多进程的并发操作。
2.5.2 缺点
- 固定的容量:传统的环形缓冲区通常具有固定的容量,当数据量超过其容量时,新的数据会覆盖旧的数据。虽然这可以实现内存的高效利用,但也可能导致数据的丢失。
- 复杂的同步机制:在多线程或多进程的环境中,环形缓冲区需要使用复杂的同步机制来保证数据的一致性和完整性,这可能会增加编程的复杂性。
- 不支持随机访问:环形缓冲区通常只支持对头部和尾部的数据进行操作,不支持对中间数据的随机访问。
在实际应用中,我们需要根据具体的需求和场景,权衡这些优缺点,选择最适合的设计和实现方式。
三、环形缓冲区的C++实现(C++ Implementation of Circular Buffer)
3.1 使用std数据接口库实现环形缓冲区(Implementing Circular Buffer with std Data Interface Library)
在C++中,我们可以使用标准库(std)中的数据接口来实现环形缓冲区。具体来说,我们可以使用std::deque(双端队列)来作为我们的环形缓冲区的底层数据结构。
std::deque是一个双端队列,它允许我们在队列的前端和后端进行插入和删除操作。这正好符合环形缓冲区的特性,即在队列的尾部插入数据,在队列的头部删除数据。
下面是一个使用std::deque实现的环形缓冲区的基本框架:
template
class CircularBuffer {
public:
CircularBuffer(size_t size) : maxSize(size) {}
void push_back(const T& value) {
if (buffer.size() >= maxSize) {
buffer.pop_front();
}
buffer.push_back(value);
}
T pop_front() {
T val = buffer.front();
buffer.pop_front();
return val;
}
size_t size() const {
return buffer.size();
}
bool empty() const {
return buffer.empty();
}
private:
std::deque buffer;
size_t maxSize;
};
在这个实现中,我们定义了一个模板类CircularBuffer,它接受一个类型参数T,表示缓冲区存储的数据类型。类中有一个std::deque成员变量buffer,用于存储数据。
push_back方法用于在缓冲区的尾部插入数据。在插入数据之前,我们首先检查缓冲区的大小是否已经达到最大值。如果已经达到最大值,我们就从缓冲区的头部删除一个数据,然后再在尾部插入新的数据。这样就保证了缓冲区的大小始终不超过最大值。
pop_front方法用于从缓冲区的头部删除数据。我们首先获取缓冲区头部的数据,然后删除头部的数据,最后返回获取到的数据。
size方法用于获取缓冲区的当前大小,empty方法用于判断缓冲区是否为空。
这个实现非常简单,但是它已经能够满足基本的环形缓冲区的需求。然而,这个实现还有很多可以改进的地方。例如,它没有考虑线程安全问题,也没有提供数据的读取功能。在后面的部分,我们将会对这个实现进行改进,使其更加完善。
3.2 线程安全的环形缓冲区实现(Thread-Safe Implementation of Circular Buffer)
在多线程环境中,我们需要保证环形缓冲区的线程安全性。这意味着,当多个线程同时对环形缓冲区进行操作时,我们需要保证数据的一致性和完整性。为了实现这一点,我们可以使用C++中的互斥锁(std::mutex)和条件变量(std::condition_variable)。
互斥锁可以保证在同一时刻,只有一个线程能够访问缓冲区的数据。条件变量则可以用于实现线程间的同步,例如,当缓冲区为空时,我们可以让读取数据的线程等待,直到有数据被写入缓冲区。
下面是一个使用std::deque、std::mutex和std::condition_variable实现的线程安全的环形缓冲区:
#include
#include
template
class CircularBuffer {
public:
CircularBuffer(size_t size) : maxSize(size) {}
void push_back(const T& value) {
std::unique_lock lock(mtx);
cv.wait(lock, [this]() { return buffer.size() < maxSize; });
buffer.push_back(value);
cv.notify_one();
}
T pop_front() {
std::unique_lock lock(mtx);
cv.wait(lock, [this]() { return !buffer.empty(); });
T val = buffer.front();
buffer.pop_front();
cv.notify_one();
return val;
}
size_t size() const {
std::lock_guard lock(mtx);
return buffer.size();
}
bool empty() const {
std::lock_guard lock(mtx);
return buffer.empty();
}
private:
std::deque buffer;
size_t maxSize;
mutable std::mutex mtx;
std::condition_variable cv;
};
在这个实现中,我们增加了一个互斥锁mtx和一个条件变量cv。在push_back和pop_front方法中,我们使用了std::unique_lock来锁定互斥锁。std::unique_lock是一个智能锁,它在构造时自动锁定互斥锁,在析构时自动解锁互斥锁,这样可以保证在函数返回时,互斥锁一定会被解锁,避免了死锁的发生。
在push_back方法中,我们使用了条件变量的wait方法来等待缓冲区的大小小于最大值。wait方法接受一个锁和一个条件,当条件不满足时,wait方法会阻塞当前线程,并释放锁,直到其他线程调用了条件变量的notify_one或notify_all方法并且条件
满足时,wait方法才会返回,并重新获取锁。这样就实现了在缓冲区满时,写入数据的线程会等待,直到缓冲区有空闲空间。
在pop_front方法中,我们也使用了条件变量的wait方法来等待缓冲区不为空。这样就实现了在缓冲区为空时,读取数据的线程会等待,直到缓冲区有数据。
在size和empty方法中,我们使用了std::lock_guard来锁定互斥锁。std::lock_guard也是一个智能锁,但是它不支持锁的所有权转移和条件变量的等待操作,所以它比std::unique_lock更轻量级。
这个实现已经是线程安全的,但是它还有一些可以改进的地方。例如,它没有提供数据的读取功能,也没有提供缓冲区满和空的回调函数。在后面的部分,我们将会对这个实现进行改进,使其更加完善。
3.3 环形缓冲区的优化和改进(Optimization and Improvement of Circular Buffer)
虽然我们已经实现了一个基本的线程安全的环形缓冲区,但是在实际应用中,我们可能需要对其进行一些优化和改进,以满足更复杂的需求。
3.3.1 提供数据的读取功能
在我们的基本实现中,我们只提供了数据的写入和删除功能,但是在实际应用中,我们可能需要读取缓冲区中的数据,而不删除它。为此,我们可以在类中添加一个front方法,用于读取缓冲区中的第一个元素:
std::lock_guard lock(mtx);
return buffer.front();
}
3.3.2 提供缓冲区满和空的回调函数
在实际应用中,我们可能需要在缓冲区满或空时执行一些特定的操作,例如,当缓冲区满时,我们可能需要暂停数据的生产,当缓冲区空时,我们可能需要唤醒数据的生产。为此,我们可以在类中添加两个回调函数,分别在缓冲区满和空时被调用:
full_callback = callback;
}
void set_empty_callback(std::function callback) {
empty_callback = callback;
}()>()>
然后,在push_back和pop_front方法中,我们可以在适当的时候调用这两个回调函数:
std::unique_lock lock(mtx);
cv.wait(lock, [this]() { return buffer.size() < maxSize; });
buffer.push_back(value);
if (buffer.size() == maxSize && full_callback) {
full_callback();
}
cv.notify_one();
}
T pop_front() {
std::unique_lock lock(mtx);
cv.wait(lock, [this]() { return !buffer.empty(); });
T val = buffer.front();
buffer.pop_front();
if (buffer.empty() && empty_callback) {
empty_callback();
}
cv.notify_one();
return val;
}
3.3.3 提供缓冲区大小的动态调整功能
在我们的基本实现中,缓冲区的大小在构造时被固定,不能在运行时进行调整。但是在实际应用中,我们可能需要根据实际情况动态调整缓冲区的大小。为此,我们可以在类中添加一个resize方法,用于调整缓冲区的大小:
_t new_size) {
std::lock_guard lock(mtx);
maxSize = new_size;
while (buffer.size() > maxSize) {
buffer.pop_front();
}
}
这个resize方法首先锁定互斥锁,然后修改缓冲区的最大大小。如果新的大小小于当前的大小,那么它将删除多余的元素,以使缓冲区的大小不超过最大大小。
这些优化和改进使我们的环形缓冲区更加灵活和强大,能够满足更多的实际需求。但是,我们还需要注意,这些优化和改进也可能带来一些额外的开销,例如,回调函数的调用和缓冲区大小的动态调整都可能增加程序的复杂性和运行时间。因此,在实际应用中,我们需要根据具体的需求和条件,权衡这些优化和改进的利弊,选择最适合的实现方式。
3.4 自定义环形缓冲区实现(Custom Circular Buffer Implementation)
在前面的章节中,我们已经介绍了如何使用std数据接口库实现环形缓冲区,以及如何进行线程安全的优化和改进。现在,我们来介绍一下如何自定义实现环形缓冲区。
自定义实现环形缓冲区的主要思路是使用一个固定大小的数组来存储数据,然后使用两个指针(或者说是索引)来分别指示缓冲区的开始位置和结束位置。当我们向缓冲区中添加数据时,我们将数据添加到结束位置,并将结束位置向前移动一位;当我们从缓冲区中取出数据时,我们将数据从开始位置取出,并将开始位置向前移动一位。当开始位置和结束位置相遇时,我们就知道缓冲区已经满了或者空了。
下面是自定义实现环形缓冲区的一种可能的代码实现:
class CircularBuffer {
public:
CircularBuffer(size_t size) : buffer_(size), head_(0), tail_(0), full_(false) {}
void push_back(const T& value) {
buffer_[tail_] = value;
tail_ = (tail_ + 1) % buffer_.size();
if (full_) {
head_ = (head_ + 1) % buffer_.size();
}
full_ = head_ == tail_;
}
T pop_front() {
if (empty()) {
throw std::runtime_error("Buffer is empty");
}
T value = buffer_[head_];
full_ = false;
head_ = (head_ + 1) % buffer_.size();
return value;
}
bool empty() const {
return !full_ && (head_ == tail_);
}
bool full() const {
return full_;
}
size_t capacity() const {
return buffer_.size();
}
size_t size() const {
size_t size = buffer_.size();
if (!full_) {
if (head_ >= tail_) {
size = head_ - tail_;
} else {
size = buffer_.size() + head_ - tail_;
}
}
return size;
}
private:
std::vector buffer_;
size_t head_;
size_t tail_;
bool full_;
};
这个CircularBuffer类使用一个std::vector来存储数据,使用head_和tail_两个索引来指示开始位置和结束位置,使用full_标志来表示缓冲区是否已满。它提供了push_back和pop_front两个方法来添加和取出数据,以及empty、full、capacity
和size方法来查询缓冲区的状态和大小。
下面是这个类的UML类图:

在这个类图中,我们可以看到CircularBuffer类的主要成员和方法。其中,push_back和pop_front方法分别用于添加和取出数据;empty、full、capacity和size方法用于查询缓冲区的状态和大小;buffer_、head_、tail_和full_是类的私有成员,用于存储数据和记录缓冲区的状态。
这种自定义实现方式的优点是我们可以根据自己的需求来定制缓冲区的行为,例如,我们可以选择在缓冲区满时是否覆盖旧的数据,或者在缓冲区空时是否抛出异常等。此外,由于我们直接操作底层的数组,因此这种实现方式的性能通常会比使用std数据接口库的实现方式更高。
然而,这种实现方式的缺点也很明显。首先,我们需要自己管理缓冲区的状态,这增加了实现的复杂性。其次,由于我们直接操作底层的数组,因此我们需要自己处理数组的边界问题,这增加了出错的可能性。最后,这种实现方式的可移植性和可复用性都不如使用std数据接口库的实现方式。
当然,性能只是选择实现方式的一个考虑因素。除此之外,我们还需要考虑其他的因素,如适用场景、兼容性、扩展性等。下面是一个对比表格,列出了这两种实现方式在各个方面的优缺点:
3.4 两种实现方式的性能对比(Performance Comparison of Two Implementation Methods)
在上述章节中,我们分别介绍了使用std数据接口库实现环形缓冲区和自定义环形缓冲区的实现方式。那么,这两种实现方式在性能上有什么区别呢?我们通过一些基准测试来进行比较。
3.4.1 测试方法
我们使用一个简单的基准测试程序,该程序对每种实现方式进行一系列的插入和删除操作,并记录所需的时间。我们使用相同的数据和操作序列来测试每种实现方式,以确保比较的公平性。
3.4.2 测试结果
我们发现,自定义环形缓冲区的实现方式在大多数情况下都比使用std数据接口库的实现方式更快。这主要是因为自定义实现方式可以更好地控制数据的存储和访问,避免了一些不必要的复制和移动操作。此外,自定义实现方式还可以提供更高的灵活性,例如,我们可以根据具体的需求和条件,动态调整缓冲区的大小。
然而,自定义实现方式也有一些缺点。首先,它的代码通常比使用std数据接口库的实现方式更复杂,更难以理解和维护。其次,自定义实现方式可能需要更多的时间和精力来优化和调试。最后,自定义实现方式可能不如使用std数据接口库的实现方式那样稳定和可靠,因为它可能包含一些难以发现和修复的错误和问题。
3.4.3 结论
总的来说,自定义环形缓冲区的实现方式和使用std数据接口库的实现方式各有优势,适合于不同的应用场景。在选择实现方式时,我们需要根据具体的需求和条件,权衡各种因素,包括性能、复杂性、灵活性和可靠性,选择最适合的实现方式。
3.4.4 综合对比表格

这个表格只是一个大致的对比,具体哪种实现方式更适合你,还需要根据你的具体需求来决定。
3.5 功能设计(Function Design)
环形缓冲区(Circular Buffer)的设计需要考虑到其基本功能和可能的扩展功能。下面我们将列出环形缓冲区设计需要必备的接口和一些可能的扩展接口。
3.5.1 必备接口(Essential Interfaces)
- 添加数据(Push):这是环形缓冲区的基本操作之一,用于向缓冲区添加数据。这个接口通常有两种形式:push_back和push_front,分别用于从缓冲区的尾部和头部添加数据。
- 取出数据(Pop):这也是环形缓冲区的基本操作之一,用于从缓冲区取出数据。这个接口通常有两种形式:pop_back和pop_front,分别用于从缓冲区的尾部和头部取出数据。
- 查询缓冲区状态(Status Query):这些接口用于查询缓冲区的状态,包括缓冲区是否为空(empty)、是否已满(full)、当前的大小(size)和最大容量(capacity)等。
3.5.2 扩展接口(Extended Interfaces)
- 数据访问(Data Access):除了添加和取出数据,我们还可能需要访问缓冲区中的数据,但不删除它们。这可以通过添加front和back接口来实现,它们分别返回缓冲区的第一个元素和最后一个元素。
- 缓冲区调整(Buffer Adjustment):在某些情况下,我们可能需要动态地调整缓冲区的大小。这可以通过添加resize接口来实现,它接受一个新的大小作为参数,并调整缓冲区的大小。
- 数据查找(Data Lookup):在某些情况下,我们可能需要查找缓冲区中的数据。这可以通过添加find接口来实现,它接受一个值作为参数,并返回该值在缓冲区中的位置。
- 迭代访问(Iterative Access):在某些情况下,我们可能需要遍历缓冲区中的所有数据。这可以通过添加迭代器(begin和end)来实现。
以上就是环形缓冲区设计需要必备的接口和一些可能的扩展接口。在实际使用中,我们可以根据自己的需求来选择需要实现的接口。
3.6 结合C++14/17/20特性的环形缓冲区设计(Designing Circular Buffer with C++14/17/20 Features)
C++14/17/20引入了许多新的特性,这些特性可以帮助我们更好地设计和实现环形缓冲区。下面我们将介绍一些可能用到的特性。
C++14:
- Auto Type Deduction:可以在函数返回类型和lambda表达式中使用auto进行类型推断,简化代码,避免显式指定复杂的类型。
- Generic Lambdas:可以在lambda表达式中使用auto定义泛型参数,实现通用算法。
C++17:
- std::optional:一种可以包含值或者不包含值的容器,对于实现可能失败的操作非常有用,比如从缓冲区中取出数据。
- Structured Bindings:可以同时声明和初始化多个变量,处理复杂的数据结构。
C++20:
- Concurrency Library:引入了一些新的并发库,如std::jthread和std::latch等,帮助处理多线程环境下的环形缓冲区。
以上就是一些可能用到的C++14/17/20的特性,这些特性可以帮助我们设计出更高效和健壮的环形缓冲区。
3.6.1 自动类型推断(Auto Type Deduction)
C++14进一步扩展了auto关键字的使用,使得我们可以在函数返回类型和lambda表达式中使用auto进行类型推断。这可以简化我们的代码,使我们不必显式地指定复杂的类型。
例如,我们可以使用auto关键字来简化环形缓冲区的迭代器类型:
3.6.2 泛型Lambda表达式(Generic Lambdas)
C++14引入了泛型lambda表达式,这使得我们可以在lambda表达式中使用auto关键字来定义泛型参数。这对于实现一些通用的算法非常有用。
例如,我们可以使用泛型lambda表达式来实现一个通用的查找函数:
return std::find(begin, end, value);
};
3.6.3 可选值(std::optional)
C++17引入了std::optional,这是一种可以包含值或者不包含值的容器。这对于实现一些可能失败的操作非常有用,比如从缓冲区中取出数据。
例如,我们可以使用std::optional来改进pop函数:
if (!empty()) {
T value = front();
// remove the value from the buffer
return value;
} else {
return std::nullopt;
}
}
3.6.4 结构化绑定(Structured Bindings)
C++17引入了结构化绑定,这使得我们可以同时声明和初始化多个变量。这对于处理复杂的数据结构非常有用。
例如,我们可以使用结构化绑定来简化环形缓冲区的状态查询:
3.6.5 并发库(Concurrency Library)
C++20引入了一些新的并发库,如std::jthread和std::latch等。这些库可以帮助我们更好地处理多线程环境下的环形缓冲区。
例如,我们可以使用std::jthread来创建一个消费者线程,该线程会在后台从环形缓冲区中取出数据:
while (true) {
auto value = buffer.pop();
// process the value
}
});
四、环形缓冲区的优化策略
4.1 如何提高环形缓冲区的性能
环形缓冲区(Circular Buffer)的性能优化是一个复杂且重要的问题。性能优化主要涉及到两个方面:一是读写速度的提升,二是内存使用的优化。下面我们将详细介绍如何提高环形缓冲区的性能。
4.1.1 提升读写速度
环形缓冲区的读写速度直接影响到整个系统的性能。提升读写速度的方法主要有以下几种:
- 减少锁的使用:在多线程环境中,我们通常使用锁(Lock)来保证数据的一致性。然而,过度使用锁会导致线程频繁地进行上下文切换,从而降低系统的性能。因此,我们需要尽可能地减少锁的使用。一种常见的方法是使用无锁数据结构(Lock-free Data Structure)。无锁数据结构通过原子操作(Atomic Operation)来保证数据的一致性,从而避免了锁的使用。
- 使用批处理:批处理(Batch Processing)是一种常见的提升读写速度的方法。批处理是指一次性读写多个数据,而不是每次只读写一个数据。批处理可以减少系统调用的次数,从而提升读写速度。
- 使用内存映射:内存映射(Memory Mapping)是一种将文件或者其他对象映射到进程的地址空间的方法,从而可以像访问普通内存一样来访问这些对象。使用内存映射可以避免系统调用,从而提升读写速度。
4.1.2 优化内存使用
环形缓冲区的内存使用效率直接影响到系统的性能。优化内存使用的方法主要有以下几种:
- 使用动态扩容:动态扩容(Dynamic Resizing)是一种常见的优化内存使用的方法。动态扩容是指当环形缓冲区的容量不足时,自动增加其容量。动态扩容可以避免因为容量不足而导致的频繁的数据移动,从而提升内存使用效率。
- 使用懒加载:懒加载(Lazy Loading)是一种只有在真正需要数据时才加载数据的方法。懒加载可以减少不必要的数据加载,从而提升内存使用效率。
- 使用对象池:对象池(Object Pool)是一种预先创建并重复使用对象的方法。使用对象池可以避免频繁的对象创建和销毁,从而提升内存使用效率。
以上就是提高环形缓冲区性能的一些常见方法。需要注意的是,这些方法并不是孤立的,而是需要根据实际的应用场景进行组合使用。例如,我们可以在使用无锁数据结构的同时,使用批处理来提升读写速度;在使用动态扩容的同时,使用懒加载来优化内存使用。
在实际的优化过程中,我们还需要考虑到硬件的特性。例如,现代的CPU具有缓存行(Cache Line)的概念,如果我们能够将数据布局在同一缓存行中,那么就可以大大提升读写速度。因此,我们在设计环形缓冲区时,需要充分考虑到这些硬件的特性。
总的来说,提高环形缓冲区的性能是一个需要综合考虑多种因素的问题。我们需要根据实际的应用场景,选择合适的优化方法,才能达到最佳的性能。

以上就是对各种优化方法的详细分析。需要注意的是,这些优化方法并不是孤立的,而是需要根据实际的应用场景进行组合使用。在实际的优化过程中,我们还需要考虑到硬件的特性,以及操作系统的特性。
4.2 如何选择合适的数据结构
在设计环形缓冲区时,选择合适的数据结构是非常重要的。数据结构的选择直接影响到环形缓冲区的性能和功能。下面我们将详细介绍如何选择合适的数据结构。
4.2.1 根据需求选择数据结构
首先,我们需要根据环形缓冲区的需求来选择数据结构。环形缓冲区的需求主要包括以下几点:
- 支持快速的插入和删除:环形缓冲区需要频繁地插入和删除数据,因此,我们需要选择支持快速插入和删除的数据结构。
- 支持随机访问:环形缓冲区需要支持随机访问,即可以快速地访问任意位置的数据。因此,我们需要选择支持随机访问的数据结构。
- 支持动态扩容:环形缓冲区的大小可能会动态变化,因此,我们需要选择支持动态扩容的数据结构。
根据以上的需求,我们可以选择如数组、链表、双端队列等数据结构。
4.2.2 根据性能选择数据结构
其次,我们需要根据性能需求来选择数据结构。不同的数据结构在插入、删除、访问等操作上的性能是不同的。例如,数组在随机访问上的性能是最好的,但是在插入和删除操作上的性能就较差;链表在插入和删除操作上的性能是最好的,但是在随机访问上的性能就较差。
因此,我们需要根据环形缓冲区的性能需求,选择合适的数据结构。例如,如果环形缓冲区的主要操作是插入和删除,那么我们可以选择链表;如果环形缓冲区的主要操作是随机访问,那么我们可以选择数组。
4.2.3 根据实现复杂度选择数据结构
最后,我们需要考虑数据结构的实现复杂度。一般来说,数据结构的实现复杂度和其功能是成正比的,功能越强大的数据结构,其实现复杂度也越高。因此,我们需要在功能和实现复杂度之间进行权衡,选择合适的数据结构。
总的来说,选择合适的数据结构是设计环形缓冲区的关键。我们需要根据环形缓冲区的需求、性能需求和实现复杂度,综合考虑,选择最合适的数据结构。
4.2.4 实例分析
让我们通过一个实例来具体分析如何选择数据结构。假设我们需要设计一个音频播放器的缓冲区,该缓冲区需要满足以下需求:
- 支持快速的插入和删除:音频数据需要频繁地从缓冲区中读取和写入。
- 支持随机访问:播放器可能需要随机跳转到音频流的任意位置。
- 支持动态扩容:音频流的大小可能会动态变化。
根据以上需求,我们可以选择使用数组作为数据结构。数组支持快速的随机访问,可以满足播放器随机跳转的需求。同时,我们可以通过动态数组来支持缓冲区的动态扩容。
然而,数组在插入和删除操作上的性能较差,这可能会影响到音频数据的读取和写入速度。为了解决这个问题,我们可以使用环形缓冲区来优化数组的插入和删除操作。环形缓冲区通过两个指针(读指针和写指针)来实现快速的插入和删除,从而大大提升了数组在这方面的性能。
通过以上的分析,我们可以看出,选择合适的数据结构需要根据具体的应用场景和需求进行。只有这样,我们才能设计出既满足需求,又具有高性能的环形缓冲区。
4.3 如何根据应用场景优化环形缓冲区
环形缓冲区是一种非常实用的数据结构,它在许多应用场景中都有广泛的应用,如操作系统、网络通信、音视频处理等。然而,不同的应用场景对环形缓冲区的需求可能会有所不同,因此,我们需要根据具体的应用场景来优化环形缓冲区,以满足不同的需求。下面我们将详细介绍如何根据应用场景来优化环形缓冲区。
4.3.1 针对高并发场景的优化
在高并发的场景中,环形缓冲区可能会被多个线程同时访问,这就需要我们对环形缓冲区进行并发控制。我们可以通过加锁的方式来保证环形缓冲区的线程安全。但是,过度的加锁可能会导致性能下降。因此,我们需要寻找一种既能保证线程安全,又能保持高性能的并发控制策略。
一种可能的解决方案是使用无锁编程技术。无锁编程是一种避免使用互斥锁而直接利用原子操作来保证数据一致性的技术。通过无锁编程,我们可以大大提高环形缓冲区在高并发场景下的性能。
4.3.2 针对实时性要求高的场景的优化
在实时性要求高的场景中,环形缓冲区需要能够快速地处理数据。为了提高处理速度,我们可以通过增大环形缓冲区的大小来减少数据的溢出,从而提高数据的处理速度。然而,增大环形缓冲区的大小可能会增加内存的使用,因此,我们需要在速度和内存使用之间找到一个平衡。
此外,我们还可以通过优化数据的读写策略来提高环形缓冲区的处理速度。例如,我们可以使用批量读写的方式来减少读写操作的次数,从而提高处理速度。
4.3.3 针对内存限制的场景的优化
在内存限制的场景中,环形缓冲区需要能够在有限的内存中高效地存储数据。为了减少内存的使用,我们可以通过压缩数据的方式来减少数据的大小。此外,我们还可以通过优化环形缓冲区的存储结构来减少内存的使用。例如,我们可以使用链表来代替数组,从而减少内存的使用。
4.3.4 实例分析
让我们通过一个实例来具体分析如何根据应用场景来优化环形缓冲区。假设我们需要设计一个网络通信的缓冲区,该缓冲区需要满足以下需求:
- 高并发:缓冲区需要支持多个线程同时进行读写操作。
- 实时性:缓冲区需要能够快速地处理数据,以满足网络通信的实时性要求。
- 内存限制:由于设备的内存资源有限,缓冲区需要能够在有限的内存中高效地存储数据。
根据以上需求,我们可以采取以下优化策略:
- 高并发:我们可以使用无锁编程技术来保证环形缓冲区的线程安全,从而提高其在高并发场景下的性能。
- 实时性:我们可以通过增大环形缓冲区的大小和优化数据的读写策略来提高处理速度。
- 内存限制:我们可以通过压缩数据和优化存储结构来减少内存的使用。
通过以上的分析,我们可以看出,根据具体的应用场景来优化环形缓冲区是非常重要的。只有这样,我们才能设计出既满足需求,又具有高性能的环形缓冲区。
五、环形缓冲区在实际项目中的应用(Application of Circular Buffer in Actual Projects)
5.1 环形缓冲区在音视频处理中的应用(Application of Circular Buffer in Audio and Video Processing)
环形缓冲区(Circular Buffer)在音视频处理中的应用非常广泛,它主要用于解决音视频数据的实时性和连续性问题。在音视频处理中,数据通常是以流(Stream)的形式进行传输的,这就要求在数据的接收和处理过程中,必须保证数据的连续性和实时性。环形缓冲区正是为了解决这个问题而设计的。
5.1.1 音视频数据的实时性和连续性(Real-time and Continuity of Audio and Video Data)
音视频数据的实时性(Real-time)是指数据在生成后,需要在一定的时间内进行处理并输出,否则就会造成音视频的延迟或者丢帧现象。而音视频数据的连续性(Continuity)是指数据在传输和处理过程中,必须保证数据的顺序和完整性,任何数据的丢失或者错位,都会导致音视频的卡顿或者花屏现象。
5.1.2 环形缓冲区在音视频处理中的作用(Role of Circular Buffer in Audio and Video Processing)
环形缓冲区在音视频处理中主要扮演了“缓冲”和“桥梁”的角色。它可以暂存音视频数据,保证数据的连续性;同时,它也可以在数据的生产者和消费者之间进行数据的传递,保证数据的实时性。
具体来说,环形缓冲区在音视频处理中的作用主要体现在以下几个方面:
- 数据的缓存(Data Buffering):环形缓冲区可以暂存音视频数据,当数据的生产速度快于消费速度时,可以防止数据的丢失;当数据的生产速度慢于消费速度时,可以保证数据的连续性。
- 数据的同步(Data Synchronization):环形缓冲区可以在数据的生产者和消费者之间进行数据的传递,通过控制数据的读写位置,可以实现数据的同步。
- 数据的隔离(Data Isolation):环形缓冲区可以将数据的生产者和消费者进行隔离,使得它们可以在不同的线程或者进程中进行操作,提高了系统的并发性和实时性。
5.1.3 环形缓冲区在音视频处理中的实现(Implementation of Circular Buffer in Audio and Video Processing)
在音视频处理中,环形缓冲区的实现主要涉及到以下几个关键步骤:
- 环形缓冲区的初始化(Initialization of Circular Buffer):在环形缓冲区的初始化过程中,需要确定缓冲区的大小,并分配相应的内存空间。缓冲区的大小通常根据音视频数据的特性和系统的性能进行设置。
- 数据的写入(Data Writing):在数据的写入过程中,需要将音视频数据写入到环形缓冲区的当前写位置,并更新写位置。如果写位置已经到达缓冲区的末尾,那么需要将写位置回绕到缓冲区的开始。
- 数据的读取(Data Reading):在数据的读取过程中,需要从环形缓冲区的当前读位置读取音视频数据,并更新读位置。如果读位置已经到达缓冲区的末尾,那么需要将读位置回绕到缓冲区的开始。
- 数据的同步(Data Synchronization):在数据的同步过程中,需要通过某种同步机制(如信号量、互斥锁等)来协调数据的生产者和消费者,保证它们可以在正确的时间和位置进行数据的读写。
在实际的音视频处理项目中,环形缓冲区的实现可能会更加复杂和高效,例如,可能会使用多级缓冲区来提高数据的读写性能,或者使用硬件加速技术来减少数据的拷贝和转换等。但是,无论如何,环形缓冲区都是音视频处理中不可或缺的一部分,它的设计和实现对于音视频处理的性能和质量都有着重要的影响。
5.1.4 使用环形缓冲区处理音视频数据的示例
以下是一个简单的C++代码示例,展示了如何使用环形缓冲区处理音视频数据。这个示例中,我们创建了一个环形缓冲区类CircularBuffer,并在主函数中模拟了音视频数据的生产和消费过程。
#include
#include
#include
// 环形缓冲区类
class CircularBuffer {
public:
CircularBuffer(size_t size) : buf_(size), max_size_(size), head_(0), tail_(0), full_(0) {}
// 写入数据
void write(int data) {
std::unique_lock lock(mutex_);
buf_[head_] = data;
if (full_) {
tail_ = (tail_ + 1) % max_size_;
}
head_ = (head_ + 1) % max_size_;
full_ = head_ == tail_;
lock.unlock();
cond_.notify_one();
}
// 读取数据
int read() {
std::unique_lock lock(mutex_);
cond_.wait(lock, [this]() { return full_ || head_ != tail_; });
auto val = buf_[tail_];
full_ = false;
tail_ = (tail_ + 1) % max_size_;
return val;
}
private:
std::vector buf_;
size_t head_;
size_t tail_;
const size_t max_size_;
bool full_;
std::mutex mutex_;
std::condition_variable cond_;
};
int main() {
CircularBuffer cb(10);
// 模拟音视频数据的生产过程
for (int i = 0; i < 20; ++i) {
cb.write(i);
std::cout << "Producing: " << i << std::endl;
}
// 模拟音视频数据的消费过程
for (int i = 0; i < 20; ++i) {
int data = cb.read();
std::cout << "Consuming: " << data << std::endl;
}
return 0;
}
这个代码示例中,环形缓冲区类CircularBuffer使用了一个std::vector来存储数据,使用了两个索引head_和tail_来表示数据的写入位置和读取位置,使用了一个布尔值full_来表示缓冲区是否已满。在写入数据和读取数据的过程中,我们使用了std::mutex和std::condition_variable来实现数据的同步。
在主函数中,我们首先创建了一个大小为10的环形缓冲区,然后模拟了音视频数据的生产和消费过程。在生产过程中,我们将0到19的整数写入到环形缓冲区中;在消费过程中,我们从环形缓冲区中读取数据,并打印出来。
这个代码示例虽然简单,但是它展示了环形缓冲区在音视频处理中的基本用法。在实际的音视频处理项目中,环形缓冲区的使用可能会更复杂和高效,例如,可能会使用多级缓冲区来提高数据的读写性能,或者使用硬件加速技术来减少数据的拷贝和转换等。但是,无论如何,环形缓冲区都是音视频处理中不可或缺的一部分,它的设计和实现对于音视频处理的性能和质量都有着重要的影响。
5.2 环形缓冲区在网络通信中的应用(Application of Circular Buffer in Network Communication)
环形缓冲区在网络通信中也有着广泛的应用,它主要用于解决网络数据的实时性和连续性问题。在网络通信中,数据通常是以包(Packet)的形式进行传输的,这就要求在数据的接收和处理过程中,必须保证数据的连续性和实时性。环形缓冲区正是为了解决这个问题而设计的。
5.2.1 网络数据的实时性和连续性(Real-time and Continuity of Network Data)
网络数据的实时性(Real-time)是指数据在生成后,需要在一定的时间内进行处理并输出,否则就会造成网络的延迟或者丢包现象。而网络数据的连续性(Continuity)是指数据在传输和处理过程中,必须保证数据的顺序和完整性,任何数据的丢失或者错位,都会导致网络的卡顿或者断线现象。
5.2.2 环形缓冲区在网络通信中的作用(Role of Circular Buffer in Network Communication)
环形缓冲区在网络通信中主要扮演了“缓冲”和“桥梁”的角色。它可以暂存网络数据,保证数据的连续性;同时,它也可以在数据的生产者和消费者之间进行数据的传递,保证数据的实时性。
具体来说,环形缓冲区在网络通信中的作用主要体现在以下几个方面:
- 数据的缓存(Data Buffering):环形缓冲区可以暂存网络数据,当数据的生产速度快于消费速度时,可以防止数据的丢失;当数据的生产速度慢于消费速度时,可以保证数据的连续性。
- 数据的同步(Data Synchronization):环形缓冲区可以在数据的生产者和消费者之间进行数据的传递,通过控制数据的读写位置,可以实现数据的同步。
- 数据的隔离(Data Isolation):环形缓冲区可以将数据的生产者和消费者进行隔离,使得它们可以在不同的线程或者进程中进行操作,提高了系统的并发性和实时性。
5.2.3 环形缓冲区在网络通信中的实现(Implementation of Circular Buffer in Network Communication)
在网络通信中,环形缓冲区的实现主要涉及以下几个关键步骤:
- 环形缓冲区的初始化(Initialization of Circular Buffer):在环形缓冲区的初始化过程中,需要确定缓冲区的大小,并分配相应的内存空间。缓冲区的大小通常根据网络数据的特性和系统的性能进行设置。
- 数据的写入(Data Writing):在数据的写入过程中,需要将网络数据写入到环形缓冲区的当前写位置,并更新写位置。如果写位置已经到达缓冲区的末尾,那么需要将写位置回绕到缓冲区的开始。
- 数据的读取(Data Reading):在数据的读取过程中,需要从环形缓冲区的当前读位置读取网络数据,并更新读位置。如果读位置已经到达缓冲区的末尾,那么需要将读位置回绕到缓冲区的开始。
- 数据的同步(Data Synchronization):在数据的同步过程中,需要通过某种同步机制(如信号量、互斥锁等)来协调数据的生产者和消费者,保证它们可以在正确的时间和位置进行数据的读写。
在实际的网络通信项目中,环形缓冲区的实现可能会更加复杂和高效,例如,可能会使用多级缓冲区来提高数据的读写性能,或者使用硬件加速技术来减少数据的拷贝和转换等。但是,无论如何,环形缓冲区都是网络通信中不可或缺的一部分,它的设计和实现对于网络通信的性能和质量都有着重要的影响。
5.2.4 使用环形缓冲区处理网络数据的示例
好的,这里是一个使用环形缓冲区处理网络数据的简单C++代码示例。这个示例中,我们创建了一个名为CircularBuffer的类,该类提供了push_back,pop_front等方法来操作环形缓冲区。然后我们创建了两个线程,一个线程负责模拟网络数据的接收并将数据写入环形缓冲区,另一个线程负责从环形缓冲区读取数据并处理。
#include
#include
#include
#include
class CircularBuffer {
public:
CircularBuffer(size_t size) : data_(size), head_(0), tail_(0), size_(0), capacity_(size) {}
void push_back(char val) {
std::unique_lock lock(mutex_);
cond_empty_.wait(lock, [this]() { return size_ < capacity_; });
data_[head_] = val;
head_ = (head_ + 1) % capacity_;
++size_;
lock.unlock();
cond_full_.notify_one();
}
char pop_front() {
std::unique_lock lock(mutex_);
cond_full_.wait(lock, [this]() { return size_ > 0; });
char val = data_[tail_];
tail_ = (tail_ + 1) % capacity_;
--size_;
lock.unlock();
cond_empty_.notify_one();
return val;
}
private:
std::vector data_;
size_t head_;
size_t tail_;
size_t size_;
size_t capacity_;
std::mutex mutex_;
std::condition_variable cond_empty_;
std::condition_variable cond_full_;
};
void producer(CircularBuffer& buffer) {
for (char c = 'a'; c <= 'z'; ++c) {
buffer.push_back(c);
std::this_thread::sleep_for(std::chrono::milliseconds(100));
}
}
void consumer(CircularBuffer& buffer) {
for (int i = 0; i < 26; ++i) {
char c = buffer.pop_front();
std::cout << "Consumer received: " << c << std::endl;
std::this_thread::sleep_for(std::chrono::milliseconds(150));
}
}
int main() {
CircularBuffer buffer(5);
std::thread prod(producer, std::ref(buffer));
std::thread cons(consumer, std::ref(buffer));
prod.join();
cons.join();
return 0;
}
这个代码示例只是一个基础的环形缓冲区实现,实际的网络通信场景可能会更复杂,例如需要处理网络延迟,数据包的丢失和重传等问题。但是,这个示例应该能够帮助你理解环形缓冲区在网络通信中的基本应用。
5.3 环形缓冲区在大数据处理中的应用(Application of Circular Buffer in Big Data Processing)
大数据处理是现代计算领域的一个重要方向,它涉及到海量数据的存储、处理和分析。在大数据处理中,环形缓冲区可以作为一种高效的数据结构,帮助我们解决数据的实时性、连续性和并发性问题。
5.3.1 大数据处理的挑战(Challenges of Big Data Processing)
大数据处理面临着许多挑战,其中最主要的有以下几个方面:
- 数据量大(Large Volume):大数据的数据量通常非常大,这就要求我们在处理数据时,必须考虑到数据的存储和传输效率。
- 数据实时性要求高(High Real-time Requirement):在许多大数据应用中,例如实时推荐、实时监控等,都要求数据能够在短时间内被处理和分析。
- 数据处理并发性要求高(High Concurrency Requirement):在大数据处理中,通常需要同时处理多个数据流,这就要求我们在设计数据处理算法时,必须考虑到数据的并发性问题。
5.3.2 环形缓冲区在大数据处理中的作用(Role of Circular Buffer in Big Data Processing)
环形缓冲区在大数据处理中主要扮演了“缓冲”和“桥梁”的角色。它可以暂存大数据,保证数据的连续性;同时,它也可以在数据的生产者和消费者之间进行数据的传递,保证数据的实时性。
具体来说,环形缓冲区在大数据处理中的作用主要体现在以下几个方面:
- 数据的缓存(Data Buffering):环形缓冲区可以暂存大数据,当数据的生产速度快于消费速度时,可以防止数据的丢失;当数据的生产速度慢于消费速度时,可以保证数据的连续性。
- 数据的同步(Data Synchronization):环形缓冲区可以在数据的生产者和消费者之间进行数据的传递,通过控制数据的读写位置,可以实现数据的同步。
- 数据的隔离(Data Isolation):环形缓冲区可以将数据的生产者和消费者进行隔离,使得它们可以在不同的线程或者进程中进行操作,提高了系统的并发性和实时性。
5.3.3 环形缓冲区在大数据处理中的实际应用案例(Practical Application Cases of Circular Buffer in Big Data Processing)
环形缓冲区在大数据处理中的应用非常广泛,下面我们将通过几个实际的应用案例,来进一步了解环形缓冲区在大数据处理中的作用。
- 实时数据流处理(Real-time Data Stream Processing):在实时数据流处理中,数据的生产者和消费者通常在不同的线程或者进程中,它们的处理速度可能会有较大的差异。环形缓冲区可以在这两者之间起到“桥梁”的作用,保证数据的实时性和连续性。
- 网络数据包处理(Network Packet Processing):在网络数据包处理中,环形缓冲区通常被用来存储接收到的数据包,以便后续的处理。通过环形缓冲区,我们可以实现数据包的缓存,防止数据包的丢失。
- 音视频数据处理(Audio and Video Data Processing):在音视频数据处理中,环形缓冲区通常被用来存储音视频数据,以便后续的解码和播放。通过环形缓冲区,我们可以实现音视频数据的缓存,保证音视频播放的连续性。
以上就是环形缓冲区在大数据处理中的一些应用案例,通过这些案例,我们可以看到环形缓冲区在大数据处理中的重要作用。
5.3.4 环形缓冲区在大数据处理中的代码示例
在复杂的大数据处理场景中,环形缓冲区的使用可以帮助我们更好地处理数据。以下是一个使用C++实现的环形缓冲区在大数据处理中的代码示例:
#include
#include
#include
#include
using namespace std;
template
class CircularBuffer {
public:
explicit CircularBuffer(size_t size) : data_(size), head_(0), tail_(0), size_(0), max_size_(size) {}
void push(T item) {
std::unique_lock lock(mutex_);
cond_var_.wait(lock, [&]() { return size_ < max_size_; });
data_[head_] = item;
head_ = (head_ + 1) % max_size_;
++size_;
lock.unlock();
cond_var_.notify_all();
}
T pop() {
std::unique_lock lock(mutex_);
cond_var_.wait(lock, [&]() { return size_ > 0; });
T item = data_[tail_];
tail_ = (tail_ + 1) % max_size_;
--size_;
lock.unlock();
cond_var_.notify_all();
return item;
}
private:
vector data_;
size_t head_;
size_t tail_;
size_t size_;
size_t max_size_;
mutex mutex_;
condition_variable cond_var_;
};
void producer(CircularBuffer& buffer) {
for (int i = 0; i < 100000; ++i) {
buffer.push(i);
}
}
void consumer(CircularBuffer& buffer) {
for (int i = 0; i < 100000; ++i) {
int value = buffer.pop();
cout << "Consumer popped " << value << endl;
}
}
int main() {
CircularBuffer buffer(1000);
thread prod(producer, ref(buffer));
thread cons(consumer, ref(buffer));
prod.join();
cons.join();
return 0;
}
在这个示例中,我们创建了一个环形缓冲区,并启动了一个生产者线程和一个消费者线程。生产者线程向环形缓冲区中添加数据,而消费者线程从环形缓冲区中取出数据。我们使用了条件变量和互斥锁来同步生产者和消费者线程,确保在缓冲区满时生产者线程等待,而在缓冲区空时消费者线程等待。这就是一个典型的生产者-消费者问题的解决方案。
六、结语
在我们深入探讨C++环形缓冲区设计与实现的过程中,我们不仅学习了技术,更重要的是,我们学习了思考问题的方式,学习了如何在功能与性能之间做出权衡,如何根据实际需求选择合适的数据结构,以及如何在面临挑战时寻找新的解决方案。
-
STM32进阶之串口环形缓冲区实现2018-06-08 0
-
MCU进阶之串口环形缓冲区实现2018-08-17 0
-
STM32串口环形缓冲区的实现2018-10-16 0
-
环形缓冲区的设计分享!2019-10-28 0
-
环形缓冲区简介2021-08-17 0
-
怎么实现串口环形缓冲区?2021-12-06 0
-
如何实现STM32串口环形缓冲区?2021-12-08 0
-
请问串口的DMA接收缓冲区是不是环形缓冲区2022-08-30 0
-
环形缓冲区读写操作的分析与实现2009-04-15 860
-
环形缓冲区的实现原理2020-03-22 7533
-
缓冲区是啥意思 STM32串口数据接收之环形缓冲区2021-07-22 10822
-
STM32串口数据接收 --环形缓冲区2021-12-28 1499
-
环形缓冲区的实现思路2023-01-17 1632
-
基于C语言实现环形缓冲区/循环队列2023-04-11 3289
全部0条评论

快来发表一下你的评论吧 !
