

因STM32移植而引发的两个小疑问
描述
有STM32用户将基于STM32F0芯片的代码移植到STM32F4系列时遇到了些麻烦。其中有个问题跟中断处理有关。有个中断服务程序代码在STM32F0芯片里运行正常,移植到STM32F4芯片并使用同样的程序代码却明显异常,感觉每次中断都进了两次。
经过他一番网上搜索,大致找到了问题原因和解决办法。原因就是他在中断服务程序里做中断请求标志清零的代码放在服务程序的结尾处了,将其挪至服务程序的入口处就可以了。
问题是解决了,但依然还是有两个小疑问如鲠在喉。
第一个疑问,为什么同样的操作在F0系列正常,而在F4系列却异常呢?仅仅是因为F4系列跑得快?
其实,这里的主要原因是内核差异导致的。STM32F0系列芯片是基于ARM Cortex-M0内核的微处理器,STM32F4系列芯片是基于ARM Cortex-M4内核的微处理器,二者在内核上存在一些差异,其中一个差异就是,M4内核相比M0内核多了针对写操作的写缓冲以及相应执行机构,这里不妨称之为“缓冲写”单元。

对于F0系列,由于没有“缓冲写单元”,CPU在做中断请求标志清零时需全程执行直到清零完成才能做中断返回。对于F4系列,由于有“缓冲写单元”协助,在做中断请求标志清零时CPU只需执行相应程序,交代清楚写些什么到哪里即可,具体的写操作就交给“缓冲写”单元完成,然后继续执行后续程序,后面跟F0系列就有点不一样了。由于清零操作代码执行时刻与准备出栈时刻太接近,“缓冲写”单元尚未完成对标志的清零,CPU因而再次进了一次中断服务程序。显然程序再运行一次后,一般来讲那个标志的清零都会完成了。因此,类似情况我们往往最多也就看到进了两次中断。
第二个疑问呢?
用户发现在使用STM32F4芯片时,即使清中断标志代码放在服务程序的结尾,一般只需在其后面追加3到4个NOP操作后就保证不会发生1次事件进入2次中断服务程序的情况。也就是说,在清中断标志代码后面稍加延时3~5个时钟就能保证清零完成。
对于Cortex-M内核的芯片,中断出栈不会少于12系统时钟。这样说来,即使不加那几个NOP操作延时,这12个时钟也足以让清零完成。这意味着出栈后中断请求标志早已完成清零,那么第2次再进中断是依据什么而响应的呢?
这里就涉及到ARM Cortex-M内核的中断响应咬尾机制。简单点说,当CPU刚执行完某中断服务程序准备出栈返回时,若内核硬件发现外边正有嗷嗷待哺的其它中断请求候着时,就果断决定不做出栈了,立马响应新的中断请求并执行相应服务程序。
具体到这里,当STM32F4的中断服务程序里最后一行清中断标志代码执行完后(具体写操作交给“缓冲写单元”了),CPU准备做出栈返回时,由于写缓冲单元尚未完成清零,硬件发现有个中断请求存在,于是乎果断决定放弃出栈,稍作准备后也不做压栈就执行当前中断请求所对应的服务程序,这里就是把刚才的中断服务程序再跑一次。
看到这里,我们应该明白了,中断再进一次的关键是CPU准备出栈时发现还有中断请求存在,至于出栈时间多长多短已经不重要,因为这时压根就不做出栈操作了。这也就可以解除上面提到的疑惑了。
下图就是示意中断前后两次执行的情况。【假定中断第一次是打断主程序或强占其它进来的】
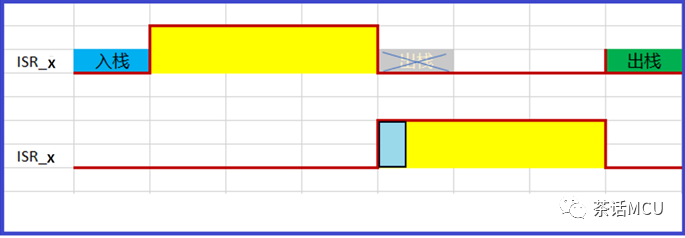
第一次进中断时,发生了压栈。第二次进中断是紧跟着第一次中断服务程序之后,未做出栈稍加准备后就开始执行服务程序,之后才做出栈操作。
看到这里,或许有人会问上面提到的稍加准备难道不要时间吗?也是要的,如果Flash访问取指延时为0等待的话,最短6个时钟。

或许有人继续问,这个6个时钟跟平常压栈的10来个时钟是什么关系呢?
当有压栈时,这个6个时钟就包含于压栈时间里了,它大致用来做中断向量的提取、Exc_return值的拟定等,这些操作跟压栈操作是并行重叠的,有压栈时就不提这几个时钟的时间了,只说压栈时间。
对于前面提到的第2次基于咬尾机制进中断的情形,如果希望得到较为直观地体验、感受,可以借助断点,观察栈帧的变化来满足。我们可以明显地观察到中断服务程序运行了两次,压栈只发生一次。
好,今天的话题就分享到这里,供君参考。下次再聊。
审核编辑:汤梓红
-
新建STM32工程全局声明两个宏的原因2019-08-10 1956
-
multisim 如何叠加两个两个信号2012-03-03 0
-
请问stm32f103ze和stm32f103rb(vb)两个移植模板什么区别?2019-07-05 0
-
STM32F072与STM32F070这两个MCU的USB有什么差异?2022-02-21 0
-
调用派生自两个基类的类的虚函数因硬故障而崩溃怎么解决?2023-01-12 0
-
STM32_UCOS移植2016-07-13 780
-
Obtain_Studio自带两个STM32_GUI实例使用说明2016-07-15 994
-
不同网段的两个路由器如何互通?2021-03-21 11673
-
基于KEIL MDK环境调试STM32的两个误会2022-02-08 207
-
在STM32上移植的一个稳定可靠的FIFO2022-09-26 703
-
分享两个STM32应用中的实战案例2023-01-11 3771
-
两个LED和两个按钮的使用2023-01-30 383
-
STM32F1两个USB中断入口详解2023-07-24 4698
-
stm32单片机如何实现一个按键切换两个程序?2023-09-14 6091
-
stm32一个定时器能同时控制两个灯以不同频率闪烁吗?2023-12-13 2139
全部0条评论

快来发表一下你的评论吧 !
