

Intel Gaudi 3处理器产品细节曝光
处理器/DSP
描述
在SC23上,英特尔和AMD在超级计算机上争霸。
会上,Top500组织发布了半年度全球最快超级计算机排行榜,AMD 驱动的 Frontier 超级计算机以 1.194 Exaflop/s (EFlop/s) 的性能稳居榜首,击败了一半的超级计算机。而来自阿贡国家实验室基于英特尔的 Aurora 超级计算机提交的规模为 585.34 Petaflop/s (PFlop/s)。
阿贡提交的方案仅采用了 Aurora 系统的一半,在 Top500 中排名第二,取代日本的 Fugaku,成为世界上第二快的超级计算机。英特尔还推出了 20 款基于 Sapphire Rapids CPU 的新型超级计算机进入榜单,但 AMD 的 EPYC(霄龙)继续占据 Top500 的位置,目前为榜单上的 140 个系统提供支持,同比增长 39%。
英特尔和阿贡国家实验室目前仍在努力让 Arora 在 2024 年全面上线。Aurora 提交代表了 10,624 个英特尔 CPU 和 31,874 个英特尔 GPU 协同工作,以总共 24.69 兆瓦 (MW) 的功率提供 585.34 PFlop/s。相比之下,AMD 的 Frontier 以 1.194 EFlop/s 的性能夺冠,这是 Aurora 性能的两倍多,但消耗的能源却相对较少,为 22.70 MW(是的,完整的 Frontier 超级计算机的功耗还不到 Aurora 系统的一半)。Aurora 在本次提交中并未进入 Green500(最节能的超级计算机名单),但 Frontier 继续在该名单上排名第八。
然而,Aurora 在完全上线后预计最终将达到 2 EFlop/s 的性能。完成后,Auroroa 将拥有 21,248 个 Xeon Max CPU 和 63,744 个 Max 系列“Ponte Vecchio”GPU,分布在 166 个机架和 10,624 个计算刀片上,使其成为世界上已知最大的 GPU 单一部署。该系统利用 HPE Cray EX(Intel Exascale 计算刀片)并使用 HPE 的 Slingshot-11 网络互连。
AMD 正在劳伦斯利弗莫尔国家实验室部署 El Capitan ,预计其速度比 Aurora 更快,性能可达 2 EFlop/s+。因此,英特尔不断推迟的Aurora 可能永远不会在 Top500 榜单上占据第一的位置——下一轮 Top500 提交的竞赛肯定会在 2024 年 6 月开始。
2018 年。当时,系统设计为使用 Knights Hill 处理器,后来被取消。此后的几年里,该系统经历了多次重新设计和重新安排, 新的 Aurora 于 2019 年宣布, 将于 2021 年提供 1 exaflop 的性能。2021 年末的另一次重新安排声称该系统在完成后将提供 2 exaflop 的性能,这是现在定于明年进行,英特尔、阿贡和慧与将继续致力于系统验证、验证以及在新系统中扩展工作负载。您可以在此处查看Argonne 今天分享的其他 Aurora 基准测试。
与此同时,部署在Azure云中的微软新Eagle超级计算机目前已占据排行榜第三位,将日本富岳推至排行榜第四位。Eagle是第一个突破前十的云系统。芬兰卡亚尼的 LUMI 系统以 379.70 PFlop/s 的性能跻身前五。
英特尔运行 1 万亿参数模型的超算
在 Supercomputing 2023 上,英特尔提供了有关其最新 HPC 和 AI 计划的大量更新,包括有关第五代 Emerald Rapids 和未来 Granite Rapids Xeon CPU、Guadi 加速器、针对Nvidia H100 GPU 的新Max 系列 GPU 基准测试的新信息,以及公司在Aurora 超级计算机上运行的“genAI”1 万亿参数人工智能模型的工作。
完成后,人们普遍预计 Aurora 将以 2 Exaflop/s (EFlop/s) 的性能夺得世界上最快的超级计算机的桂冠。然而,英特尔尚未透露有关 Aurora 正式提交 Top500 名单的基准测试的详细信息,该公司表示将把该公告留给能源部和阿贡国家实验室。如果按照惯例,Top500 组织将在今天晚些时候发布这些备受期待的结果。与此同时,英特尔的更新包含了大量值得仔细研究的新花絮。

满负荷运行时,英特尔 Aurora 超级计算机将配备 21,248 个配备 HBM2E 的 Sapphire Rapids Xeon Max CPU 和 60,000 个 Xeon Max GPU,使其成为世界上已知的最大 GPU 部署。如前所述,英特尔尚未发布 Top500 提交的基准测试,但该公司确实分享了一些工作负载的性能以及系统运行的部分补充。
英特尔和阿贡国家实验室在 genAI 项目中测试了 Aurora,这是一个万亿参数 GPT-3 LLM 基础人工智能模型。由于数据中心 GPU Max“Ponte Vecchio”GPU 上存在大量内存,Aurora 可以运行仅包含 64 个节点的大型模型。Argonne 已在总共 256 个节点上并行运行该模型的四个实例。调整工作负载后,该工作负载最终将扩展到 10,000 个节点。
英特尔还强调了药物筛选人工智能推理应用程序 ESP-ML 中从 128 个节点到 256 个节点的强劲扩展,但 Argonne 针对竞争对手 GPU 的基准测试更有趣:英特尔声称,在使用 PyTorch/FP32 进行 CosmicTagger 训练时,单个 Max 1550 GPU 比 AMD MI250 加速器提速 56%,比 Nvidia 上一代 A100 GPU 具有 2.3 倍的优势。结果还表明强大的扩展性,六 GPU Sunspot 测试节点表现出 83% 的性能扩展。结果,Sunspot 节点的性能是使用未知 GPU 的四 GPU AMD 测试系统的两倍多,是使用更老的 Polaris 的四 GPU 节点性能的五倍。
阿贡国家实验室还在模拟小鼠大脑的大脑连接组工作负载 (Connectomics ML) 中测试了 512 个 Aurora 节点与 475 个节点的 Polaris 的对比,突显了其比 Polaris 的 2 倍优势。
英特尔的数据中心路线图仍在按计划进行,第五代 Emerald Rapids 芯片定于 12 月 14 日推出。英特尔公布了旗舰级 64 核 Xeon 8592+ 与其前身 56 核第四代 Xeon 8480+ 的基准测试结果。与往常一样,使用供应商提供的基准测试(您可以在本文的最后一个专辑中找到测试说明)。
正如您对更高内核数量的期望,8592+ 在 AI 语音识别和 LAMMPS 基准测试中实现了 1.4 倍的增益,同时在 FFMPEG 媒体转码工作负载中实现了 1.2 倍的增益。
英特尔还提供了其未来 Granite Rapids Xeon 的性能预测,该处理器将在“Intel 3”节点上生产。这些芯片将添加更多内核、更高频率、FP16 硬件加速,并支持 12 个内存通道,包括可极大提高内存吞吐量的新型MCR 内存 DIMM 。总而言之,英特尔声称 AI 工作负载提高了 2-3 倍,内存吞吐量提高了 2.8 倍,DeepMD+LAMMPS AI 推理工作负载提高了 2.9 倍。
英特尔配备 HBM2E 的 Xeon Max CPU 现已发货。英特尔将其配备 64GB 封装 HBM 内存的 56 核 Intel Max 9480 与 AMD 96 核 EPYC 9654 进行了正面交锋。英特尔为这一系列基准测试选择的工作负载由以下目标用例组成:内存受限的应用自然会让 Xeon 芯片受益。总体而言,英特尔声称在模拟、能源、材料科学、制造和金融服务工作负载等一系列工作负载中,比 EPYC 竞争者平均有 1.2 倍的优势。
英特尔分享了有关即将推出的 Gaudi 3 的一些细节,这将标志着该公司将其 Gaudi 和 GPU 系列合并为一个单一产品——Falcon Shores之前的最后一款 Guadi 加速器。5nm Gaudi 3 在 BF16 工作负载方面的性能是 Gaudi 2 的四倍,网络性能是 Gaudi 2 的两倍(Gaudi 2 具有 24 个内置 100 GbE RoCE 网卡),HBM 容量是 Gaudi 2 的 1.5 倍(Gaudi 2 具有 96 GB 的 HBM2E)。正如我们在图中看到的那样,Gaudi 3 转向了具有两个计算集群的基于图块的设计,而不是英特尔为 Gaudi 2 使用的单芯片解决方案。英特尔一直在缓慢提供有关其未来 Falcon Shores GPU 的详细信息。
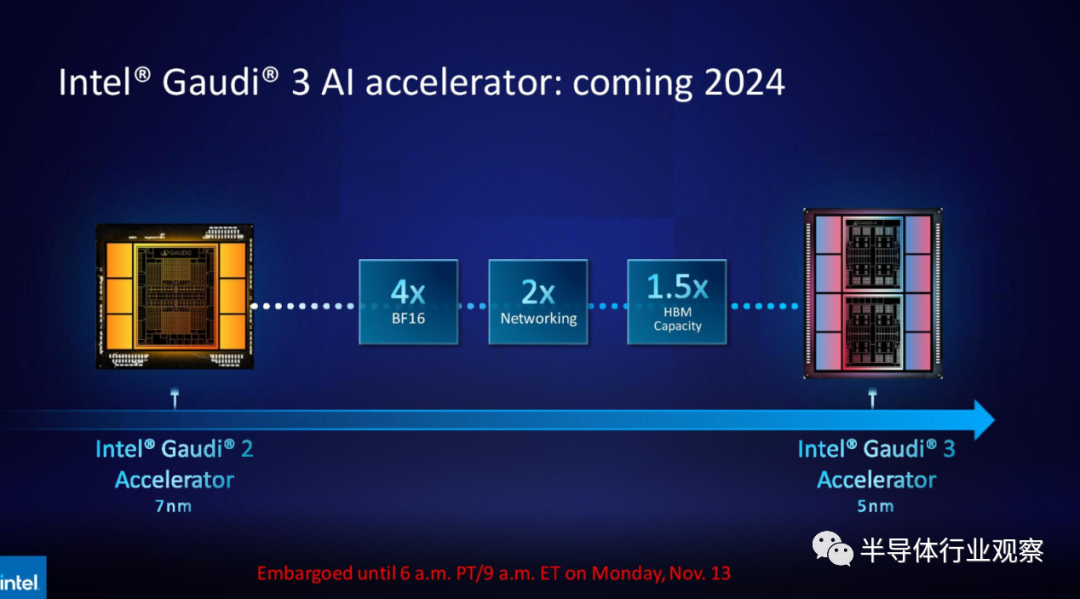
但英特尔重申,尽管合并了 Habana Gaudi IP 和 Xe GPU IP 的各个方面,但基于图块的 Falcon Shores 将通过 OneAPI 编程接口将外观和功能视为单个 GPU。Falcon Shores 将采用 HBM3 内存和以太网交换,并支持 CXL 编程模型。此外,针对 Gaudi 加速器和 Xeon Max GPU 进行调整的应用程序将与 Falcon Shores 向前兼容,从而为客户提供两个截然不同的 GPU 和 Gaudi 系列之间的代码连续性。
此外,英特尔的数据中心 GPU Max 系列现已向客户发货,Supermicro 提供具有 8 个 OAM 规格 GPU 的系统,而戴尔和联想则提供 4 个 OAM GPU 服务器。GPU Max 系列 1100 PCIe 卡也可从多个供应商处广泛获得。
英特尔的基准测试将 OAM 外形尺寸的 Max 1550(600W GPU)与 Nvidia 的 PCIe 外形尺寸 H100(350W 竞争对手)进行比较。因此,这些基准测试并不是比较性能的良好试金石。英特尔表示,基准差异的原因是难以获得 OAM 外形 H100 GPU。
现在我们正在等待阿贡国家实验室提交的 Aurora 超级计算机 Top500 提交,看看英特尔能否取代 AMD 驱动的 Frontier,成为世界上最快的超级计算机。预计该更新将于今天晚些时候进行。
编辑:黄飞
-
Intel 64处理器的基本运行环境2019-05-22 0
-
Cortex-M3处理器是什么2021-07-16 0
-
苹果M2处理器曝光:性能更强 精选资料分享2021-07-23 0
-
GAUDIR HL-2000处理器介绍2023-08-04 0
-
基于Intel PXA250处理器工作状态的功耗仿真模型及分2009-08-31 810
-
Intel 32位处理器 ,Intel 32位处理器结构原理2010-03-26 2008
-
Intel 64位处理器,Intel 64位处理器结构原理2010-03-26 3323
-
Intel详述2011年处理器特色 内建令人惊艳的视觉功能2010-09-30 845
-
麒麟710处理器跑分曝光,比麒麟659提升70%以上,但与骁龙710处理器仍有差距2018-07-24 25553
-
A14处理器性能已超酷睿i9处理器,意味着ARM超越Intel吗?2020-10-21 7732
-
A14处理器的性能超过酷睿i9处理器,ARM胜出一筹2020-10-21 2889
-
Intel Itanium 2处理器的性能特点及适用范围2021-01-28 1565
-
Intel 11代酷睿处理器轻松斩落Zen3处理器2021-01-12 3321
-
英特尔推出先进的Intel Core i7处理器2021-03-25 5799
-
有消息透露称,英特尔Gaudi 2处理器订单增多,Gaudi 3预计明年上市2023-09-20 999
全部0条评论

快来发表一下你的评论吧 !
