

一种基于RGB-D图像序列的协同隐式神经同步定位与建图(SLAM)系统
描述
2. 摘要
提出了一种基于RGB-D图像序列的协同隐式神经同步定位与建图(SLAM)系统,该系统由完整的前端和后端模块组成,包括里程计、回环检测、子图融合和全局优化。为了在一个统一的框架中启用所有这些模块,我们提出了一种新的基于神经点的3D场景表示,其中每个点都保持用于场景编码的可学习神经特征,并且与某个关键帧相关联。此外,还提出了一种从分布式到集中式的协作隐式SLAM学习策略,以提高一致性和协调性。与传统的光束法平差一样,本文还提出了一种新的全局优化框架来提高系统精度。在不同数据集上的实验证明了该方法在相机跟踪和建图方面的优越性。
3. 算法解析
重新理一下思路,NeRF SLAM为啥火?
因为NeRF和SLAM可以相互辅助,SLAM为NeRF训练提供位姿,NeRF可以重建高清晰度的地图、做空洞补全、或者用光度损失反过来优化位姿。
有什么问题?
个人感觉现在NeRF SLAM有两个问题,一个是计算量大难以落地,一个是因为做不了回环和全局优化导致定位精度低。
CP-SLAM的核心思想是什么?
传统的NeRF地图不好做回环和优化,但是改成基于点的NeRF地图,就可以像传统SLAM那样去优化了!
具体是如何实现的?
CP-SLAM本身是一个多机协同SLAM,输入是RGB-D数据流,每个SLAM系统分别执行跟踪和建图,最后执行子地图融合。每个SLAM系统都维护一个神经点辐射场,借助3个MLP(特征融合、颜色场、占用场)来渲染深度图和颜色图。通过计算光度和几何损失来优化辐射场和相机位姿。同时每个单独的SLAM不断地用NetVLAD提取关键帧描述子,并发送到描述子池(有点像ORB-SLAM的关键帧数据库),中央服务器检测到回环以后融合子地图,并执行全局BA。最后再做一个以关键帧为中心的地图优化。
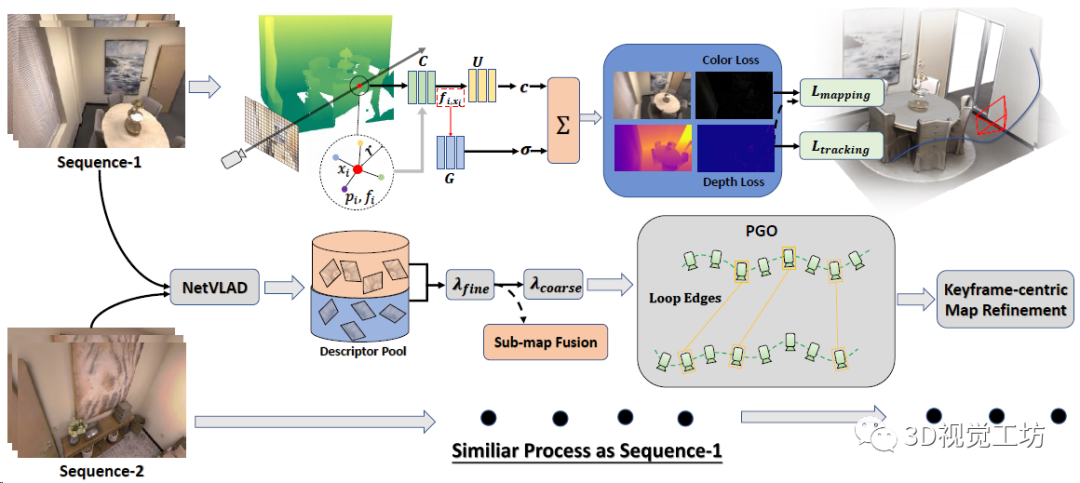
下面来逐个聊聊每个子模块的具体原理。
这个神经点是啥?
神经点辐射场来源于CVPR 2022 oral的文章Point-NeRF,用神经点表示三维场景。其实就是让空间中的点同时存储位置信息(xyz)和局部场景信息(单层CNN提取的神经特征向量,CP-SLAM里是32维),原始Point-NeRF的神经点里还存储了[0, 1]范围的置信度,表示这个点有多大概率离真实物体很近。
当然,使用神经点辐射场也有优点有缺点:
优点:执行回环检测和BA优化时,3D点比原始NeRF场景更好调整,所以就很容易引入回环和局部地图优化。
缺点:由于神经点分布在观察对象的表面周围,因此未见区域的空洞填补能力弱于特征网格方法。
位姿跟踪和NeRF建图如何进行?
辐射场采样上也用到了一个trick,就是尽量让采样点贴近物体表面。对于深度有效的点,分别从[0.95D, 1.05D]和[0.95Dmin, 1.05Dmax]区间内均匀采样,D表示点的深度值,Dmin和Dmax表示整个深度图的最小最大深度。
对每个采样点xi,首先检索它半径r范围内的K个邻域点,用一个MLP(框图中的C)分别处理这K个点,使每个点的特征向量都融合了跟采样点的距离信息(对应f~k,x~):
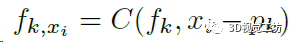
再用一个MLP(框图中的U)来学习采样点xi的RGB信息,这里就需要用到上一步K个点的特征向量了:
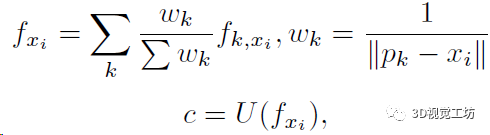
最后还需要用一个MLP(框图中的G)来学习采样点xi的占用概率,这里还是用到上上步计算的K个特征向量,当然如果没有邻域点那占用肯定就是0了:
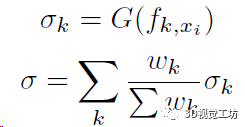
这两步预测的占用和颜色信息实际上表示了射线中止的概率α,再加上深度值z就可以渲染得到当前视角的深度图和RGB图:
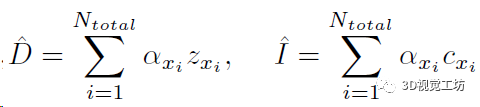
然后就可以使用深度图和RGB图计算几何损失和光度损失来优化位姿、点特征向量、还有3个MLP:
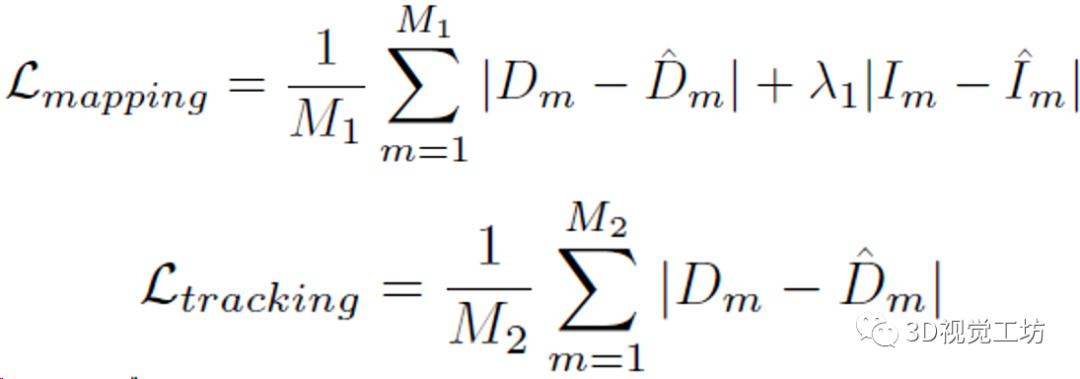
这里还有几个需要注意的点:
1、整个序列的第一帧需要采样很多的点来初始化,优化步骤达到3000∼5000次;
2、位姿表示成四元数和平移格式,当前帧位姿的初始值设置为上一帧的位姿,优化时要固定神经特征向量和3个MLP权重;
3、优化位姿没有用到光度损失,作者认为RGB图是一个高度非凸问题。
基于学习的回环检测如何实现?
这部分主要是用于融合多个SLAM系统分别建立的子地图,并减少位姿的累计漂移。首先对每个关键帧用预训练的NetVLAD提取描述子,并把描述子扔到池子里(类似ORB-SLAM的关键帧数据库),然后用余弦相似性来检测回环。
局部优化很吃初值,如果两帧运动太快的话,就很容易陷入局部最优,所以CP-SLAM采用了一个由粗到精的回环检测策略。如果相似性超过λfine的话直接执行回环优化和子地图融合,如果低于λfine但高于λcoarse的话就只做一个位姿图优化。当然子地图融合之后肯定有大量的冗余点,还需要做一步非极大值抑制(网格过滤)。
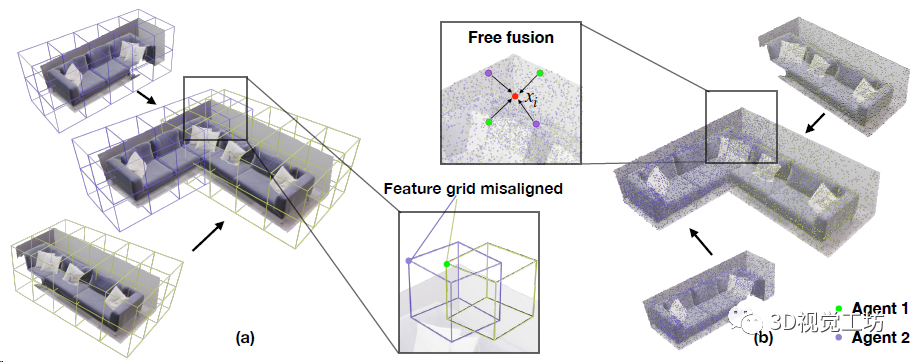
SLAM协同如何实现?
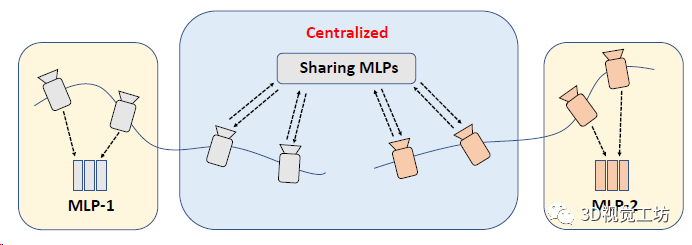
CP-SLAM本身就是一个协同SLAM,协同部分是设计了一个两阶段(从分布式到集中式)的MLP训练策略,来提高协作一致性。分布式阶段就是每个SLAM单独做跟踪和优化,执行回环和子地图融合以后就进入集中式阶段,注意集中式阶段需要一个中心服务器来做子图和优化的全局管理。
这个阶段用的是联合学习,也就是以共享的方式训练单个网络。在子地图融合的同时,对每组MLP进行平均处理,并对所有关键帧上的平均MLP进行微调,随后将共享MLP转移到每个SLAM做训练,并且平均每个SLAM权重作为共享MLP的最终优化结果。
最后简单说一下位姿图优化
这个模块分为两部分,一部分是维护子地图的共视图,一部分是是基于帧的地图优化。在执行子地图融合后做全局优化,位姿图中每帧的位姿是顶点,序列相对位姿和回环相对位姿是边,优化还是用的L-M算法。
为了方便优化3D点云位置,作者还做了一个trick:每个3D点都与一个关键帧相关联。
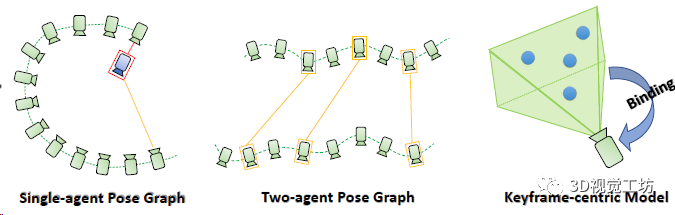
4. 实验结果
实验这一块分别对比了单机SLAM和协作SLAM模式,单机SLAM对比在Replica数据集进行,对比传统SLAM(ORB-SLAM3)和NeRF SLAM(NICE-SLAM和Vox-Fusion),协同SLAM对比的传统SLAM方案(CCM-SLAM、Swarm-SLAM、ORB-SLAM3)。CP-SLAM的运行环境是一块3090,如果需要做协同的话,就再需要一块3090做为中心服务器。
双机协作精度的定量对比,注意ORB-SLAM3本身不是协作SLAM,所以作者的实验方法是融合数据集,然后用ORB-SLAM3的多地图系统来执行地图融合。
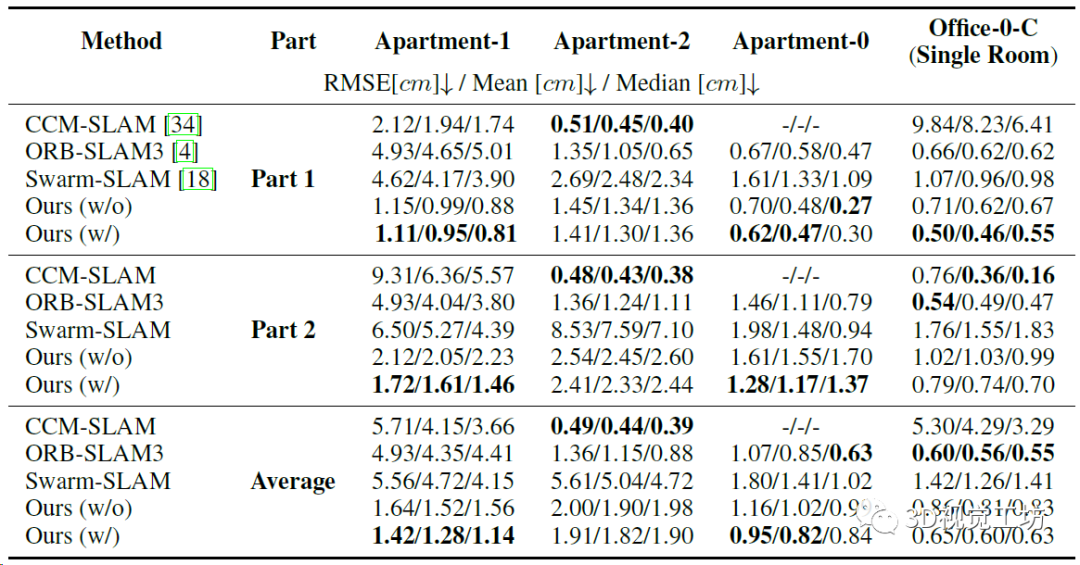
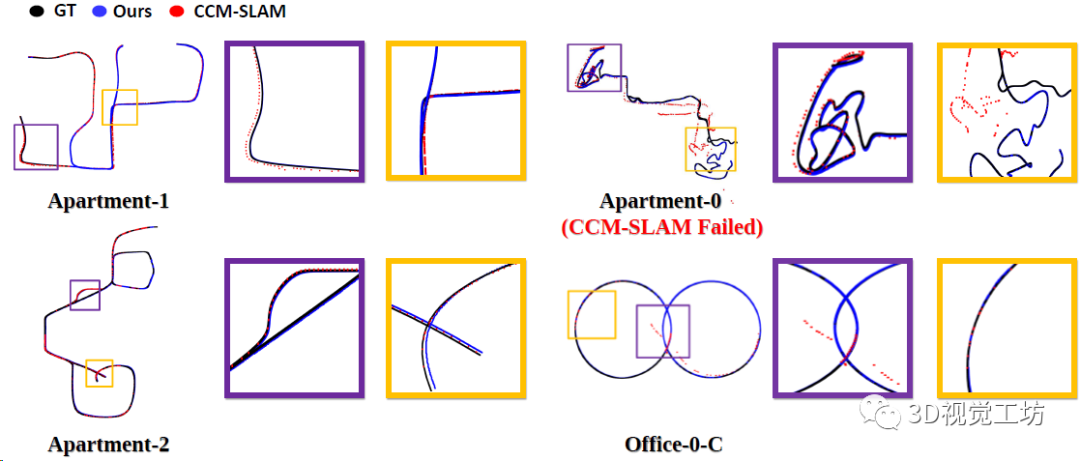
4个场景上CP-SLAM和CCM-SLAM的协作实验轨迹对比,可以发现CP-SLAM的地图融合效果还是比较好的。
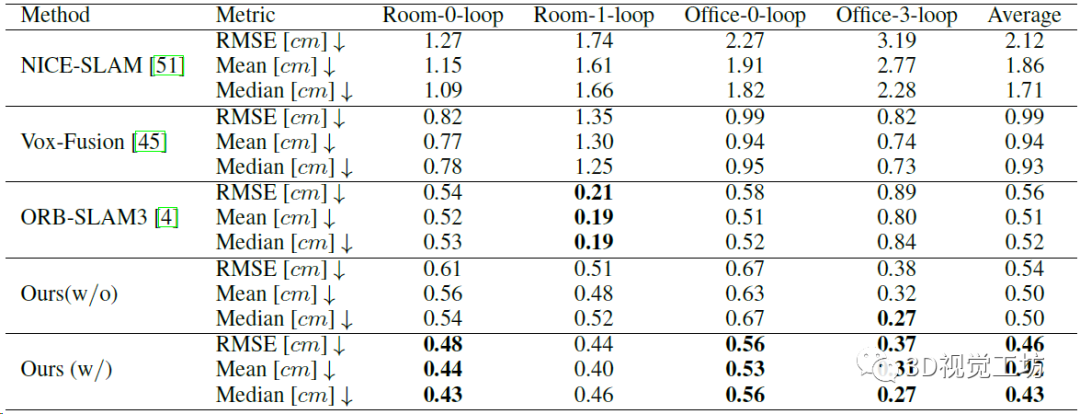
单机SLAM的精度对比,这个就说明CP-SLAM的精度超越ORB-SLAM3了。当然如果不加入回环的话,CP-SLAM精度还是不够,这一点上说明限制NeRF SLAM精度提升的关键就在局部地图优化和回环优化。
单机SLAM轨迹的定性对比,对比的NICE-SLAM和Vox-Fusion这两个NeRF SLAM方案,没有对比ORB-SLAM3。
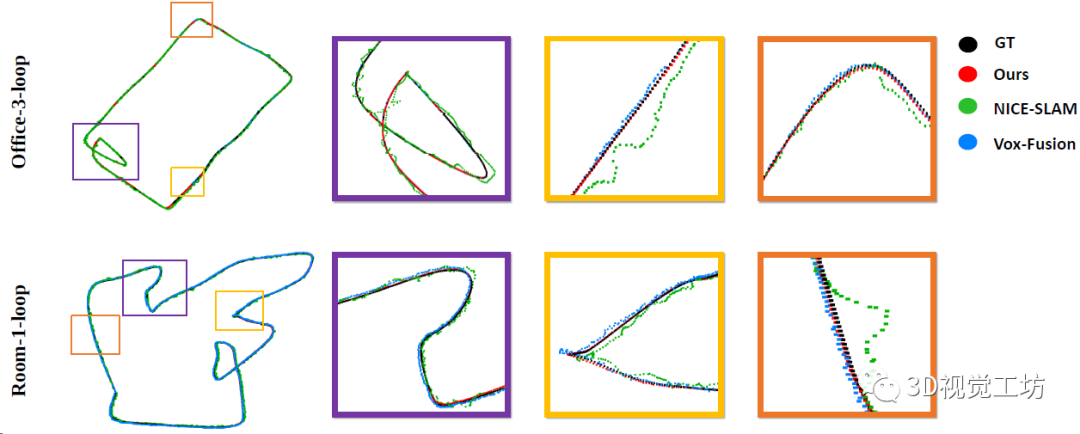
TUM数据集上精度和鲁棒性的定量对比,但对比的还是只有Co-SLAM和ESLAM这两个NeRF SLAM方案,没对比ORB-SLAM3。这里也推荐工坊推出的新课程《彻底剖析激光-视觉-IMU-GPS融合SLAM算法:理论推导、代码讲解和实战》。

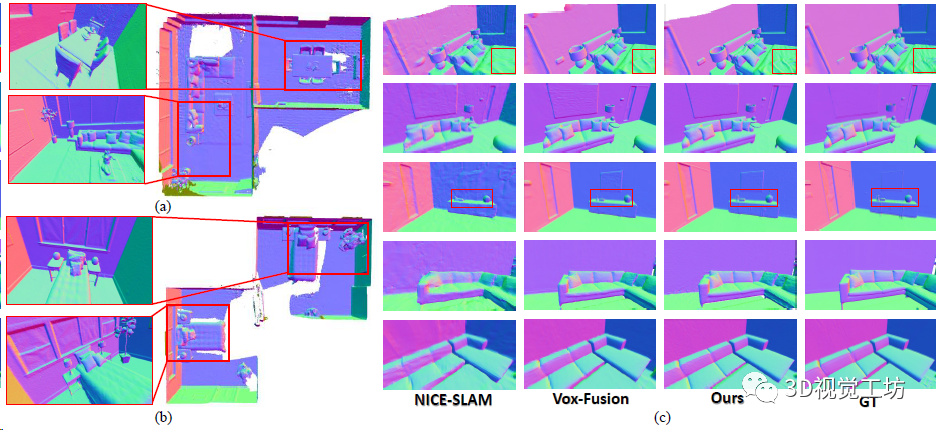
NeRF建图的定量对比,证明三维重建的精度超越了之前的NeRF SLAM方案。

NeRF建图的定性对比。
神经点密度的消融实验,证明神经点不是越多越好,也不是越少越好。

Office-0-loop场景上运行时间和内存消耗的定量对比,包括单帧跟踪时间、建图时间、MLP大小、整个神经场的内存大小。NICE-SLAM神经场的尺寸超级大,这是因为它为了解决遗忘问题设计的多层特征网格。

地图优化和采样点融合的消融实验,还是验证它们的策略是对的。

5. 总结
本文介绍了浙大最新的工作CP-SLAM,号称是第一个基于NeRF的协作SLAM,跟传统SLAM一样具备前后端,定位精度和建图质量都有了很大提升。可惜没有开源。
审核编辑:刘清
-
让机器人完美建图的SLAM 3.0到底是何方神圣?2019-01-21 0
-
如何去开发一款基于RGB-D相机与机械臂的三维重建无序抓取系统2021-09-08 0
-
基于RGB-D图像物体识别方法2017-12-07 988
-
RGB-D图像是什么2020-11-01 18257
-
基于UWB、里程计和RGB-D融合的室内定位方法2021-04-25 906
-
一种基于非监督深度学习的闭环检测算法2021-05-10 722
-
用于机器人定位和建图的增强型LiDAR-惯性SLAM系统2023-01-13 584
-
用于SLAM的神经隐含可扩展编码2023-01-30 737
-
一种基于直接法的动态稠密SLAM方案2023-03-13 1281
-
用于快速高保真RGB-D表面重建的神经特征网格优化的GO-Surf2023-03-17 742
-
基于RGB-D相机的三维重建和传统SFM和SLAM算法有什么区别?2023-03-23 1337
-
用于神经场SLAM的矢量化对象建图2023-06-15 821
-
一个动态环境下的实时语义RGB-D SLAM系统2023-08-25 644
-
动态环境中基于神经隐式表示的RGB-D SLAM2024-01-17 898
-
常用的RGB-D SLAM解决方案2024-04-16 1002
全部0条评论

快来发表一下你的评论吧 !
