

CPU Cache是如何保证缓存一致性的?
电子说
描述
单核CPU
我们介绍CPU Cache的组织架构及其进行读操作时的寻址方式,但是缓存不仅仅只有读操作,还有 写操作 ,这会带来一个新的问题:
当CPU是单核的情况下,CPU执行写入数据操作,当数据写入CPU Cache之后,此时CPU Cache数据会和内存数据就不一致了(这里前提条件:CPU Cache数据和内存数据原本是一致的),那么如何保证Cache和内存保持数据一致?
主要有两种写入数据的策略:
- Write Through写直达
- Write Back写回
Write Through写直达
Write Through写直达是一个比较简单的写入策略,顾名思义就是每次CPU执行写操作,如果 缓存命中 ,将数据更新到缓存,同时将数据更新到内存中,来保证Cache 数据和内存数据一致;如果缓存没有命中,就直接更新内存
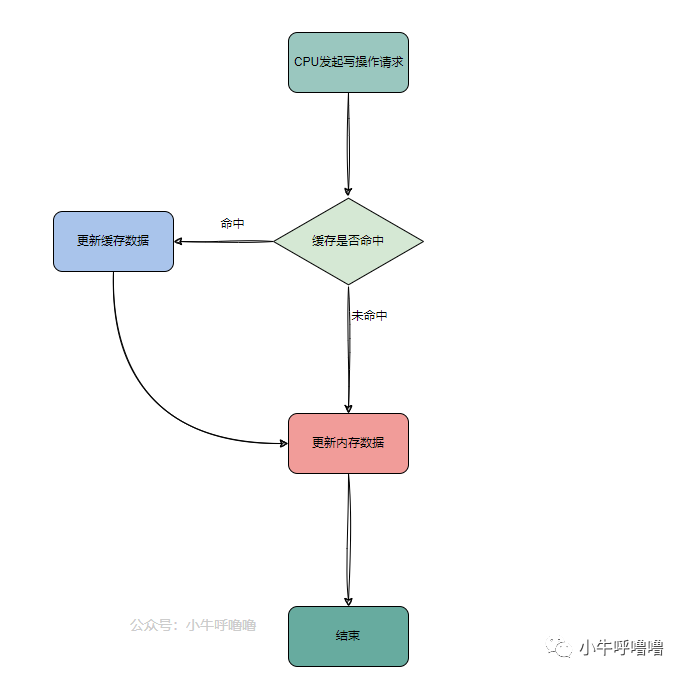
这个策略优点是简单可靠,但是速度较慢,可以从上图看出,每次写操作都需要与内存接触,此时缓存失去意义了,当然读操作时缓存还是能起作用的
Write Back写回
Write Back写回,也被称为 延迟写入 ,相比于Write Through写直达策略每次写操作都需要内存参与;而Write Back策略则是,CPU向缓存写入数据时,只是把 更新的cache区标记为dirty脏 (即Cache Line增加 dirty脏 的标记位 ** ),即来表示该Cache Line的数据,和内存中的数据是不一致的, 并不同步写入内存**
也就是说对内存的写入操作会被 推迟 ,直到当这个Cache Line要被刷入新的数据时,才将Cache Line的数据回写到内存中
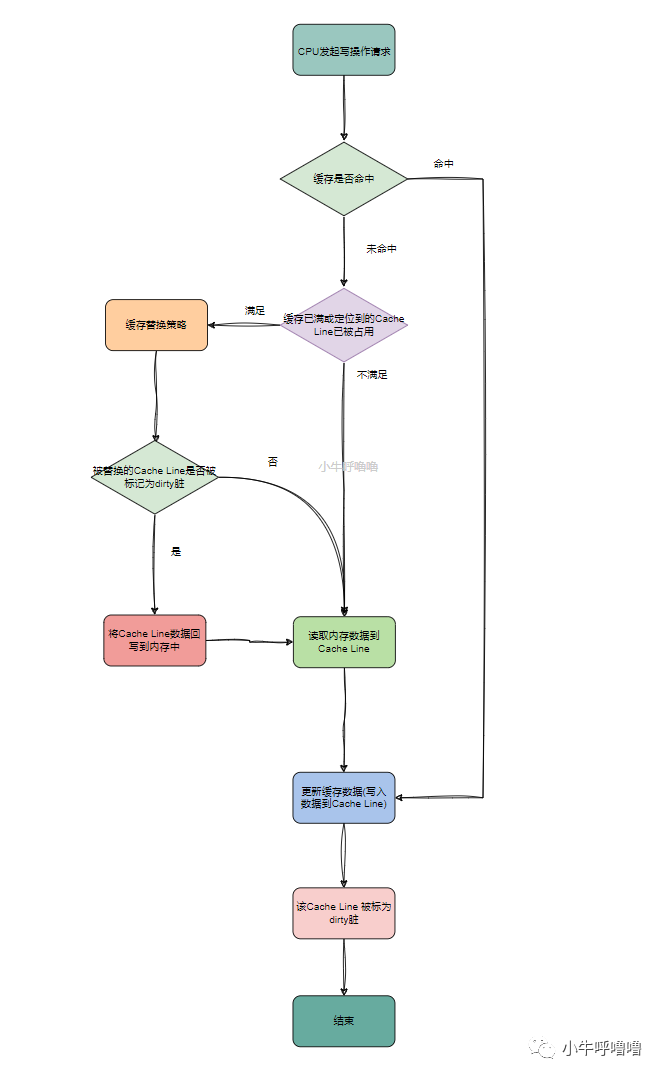
如今CPU Cache更多地采用write back写回的方式,写回的核心就是尽可能减少回写内存的次数,来提升CPU性能,缺点就是实现起来比较复杂
我们来看下它的具体流程是:当CPU发起写入操作请求时,如果缓存命中,就直接更新 CPU Cache 里面的数据,并把更新的Cache区标记为dirty脏
若缓存未命中的话,再判断缓存区已满或者定位到的Cache Line已被占用,缓存就会执行 替换策略 ,常见的策略有:随机替换RR、先进先出FIFO、最近最少使用LRU等,我们后文再详细介绍;
当被替换的Cache Line被标记为脏,也就是该Cache Line的数据,和内存中的数据是不一致的,此时会触发操作: 将Cache Line中的数据回写到内存中 ;然后,再把当前要写入的数据,写入到 Cache里,同时把Cache Line标记成脏
如果Cache Line的数据没有被标记成脏的、缓存区未满、定位到的Cache Line未被占用,那么直接把数据写入到 Cache 里面,同时把Cache Line标记成脏
结束或者可以说是等待下一次CPU请求
常见的内存替换策略
RR
随机替换 (Random Replacement,RR) ,顾名思义就是随机选择被替换的缓存块
实现简单,在缓存大小较大时表现良好,能够减少缓存替换的次数,提高缓存命中率
但是没有利用 “局部性原理”,无法提高缓存命中率;且算法性能不稳定,在缓存大小较小时,随机替换可能导致频繁的缓存替换,降低了缓存的命中率
FIFO
先进先出(First-In-First-Out, FIFO),根据数据进入缓存的顺序,每次将最早进入缓存的数据先出去,也就是先进入缓存的数据先被淘汰。
实现简单,适合短期的缓存数据;但不合适长期存储数据的场景,缓存中的数据可能早已经过时;当缓存大小不足时,容易产生替换过多的情况,从而降低了缓存的效率
FIFO 算法 存在Belady贝莱迪现象 : 在某些情况下,缓存容量增大,命中率反而降低 。概率比较小,但是危害是无限的
贝莱迪在1969年研究FIFO算法时,发现了一个反例,使用4个页框时的缺页次数比3个页框时的缺页多,由于在同一时刻,使用4个页框时缓存中保存的页面并不完全包含使用3个页框时保存的页面,二者不是超集子集关系,造成都某些特殊的页面请求序列,4个页框命中率反而低
下图引用于:Memory management and Virtual memory

LRU
最近最少使用 (Least-Recently-Used,LRU),记录各个 Cache 块的历史访问记录, 最近最少使用的块最先被替换 。LRU 策略利用了局部性原理,来提高缓存命中率:如果一个数据在最近一段时间内没有被访问,那么它在未来被访问的概率也相对较低,可以考虑将其替换出缓存,以便为后续可能访问的数据腾出缓存空间
实现简单,适用于大多数场景,尽可能地保留最常用的数据,提高缓存的命中率;但是当缓存大小达到一定阈值时,需要清除旧数据,如果清除不当可能会导致性能下降;且无法保证最佳性能,可能会出现缓存命中率不高的情况
LRU 不会出现 Belady 现象,因为容量更小缓存中的数据集合始终是容量更大缓存中数据集合的子集
下图来源于:LRU and LFU Cache Algorithms

当然还有许多其他算法,比如LFU、2Q、MQ、ARC等等,大家感兴趣地可以自行去了解
多核CPU
上述都是单核CPU的情况,但如今CPU都是多核的,由于每个核心都独占的 Cache(L1,L2),就会存在当一个核心修改数据后,另外核心Cache中数据不一致的问题,那又该如何保证缓存一致性呢?
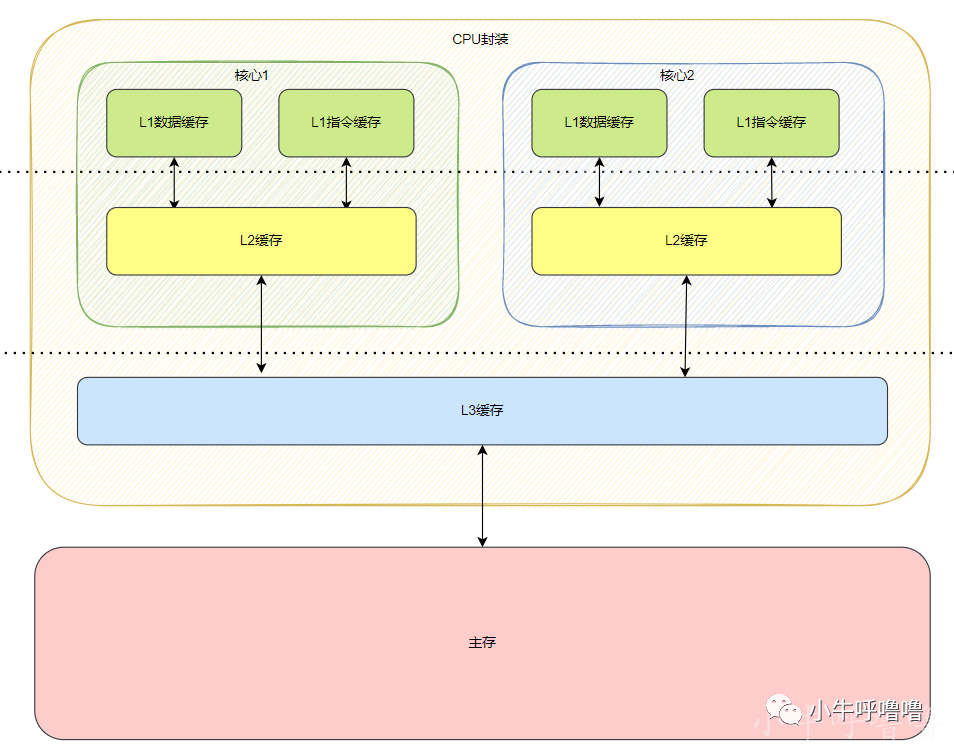
这个时候,单核情况下的写直达策略还是写回策略都无法解决一致性的问题,那么我们需要一种全新的机制来保证缓存一致性
多核CPU缓存一致性主要有2种策略:基于总线监听的一致性策略 和 基于目录的一致性策略
基于总线监听的一致性策略
基于总线监听的一致性策略,也叫 总线嗅探 (Bus Snooping),它的工作原理是:
- 当有一个CPU核心修改了Cache中的值,会通过总线把这个事件广播给其他所有的核心;
- 而每个CPU核心都会去监听总线中的数据广播,并检测是否有相同数据的副本,在本核心的Cache中;如果有副本,就执行相应操作来确保多核心的缓存一致性
其中将相应操作传播到所有拥有该Cache副本的核心中时,一般有2种处理办法:
- write-update写更新协议:某个Cache发生写操作,就传播所有核心中Cache都更新该数据副本,由于需要把对应的数据传输给其他CPU核心,所以该策略成本较高
- write-invalidate写失效协议:某个Cache发生写操作,就把其他Cache中的该数据副本置为 无效 ,这样CPU 只需也只能读取和写入数据的其中一个副本 ,因为其他核心的缓存中该数据副本都已经无效的。这也是最常用的监听协议
基于目录的一致性策略
基于目录的一致性策略会维护一个数据结构,叫做 目录 (directory-based),保存着缓存中不同数据副本写入哪些Cache及其对应的状态等相关信息;
当CPU执行写操作时,不会再向所有核心的Cache进行广播,而是是通过此目录来跟踪所有缓存中数据副本的状态,来仅将其发送到指定的数据副本中;这样相比总线嗅探节省大量总线流量,更具有扩展性
它又分为SI,MSI,MESI策略,我们这里主要介绍MESI协议
MESI协议
MESI协议是一个基于失效的缓存⼀致性协议,通过总线嗅探来处理多个核心之间的数据传播,同时也用 目录状态机制 ,来降低了总线带宽压力。
所谓缓存一致性是指:通过在缓存之间做同步,达到仿佛系统不存在缓存时的行为。一般有 如下要求:
- Write Propagation写传播:在一个CPU核心里,Cache Line数据更新,能够传播到其他核心的对应的Cache Line里
- Transaction Serialization事务顺序化:在一个CPU核心里面的读写操作,不管这些指令最终的先后顺序如何,但在其他的核心看起来,顺序要一样的。
这也对应我们常说的并发可见性和顺序性~
四大状态
MESI名字中,"M", "E", "S", "I"这4个字母分别代表了Cache Line的四种状态(存放再Cache Line),分别是:
- M:代表已修改(Modified),表明
Cache Line被修改过,但未同步回内存(就是上面我们说的脏数据) - E:代表独占(Exclusive),表明
Cache Line被当前核心独占,和内存中的数据一致(数据是干净的) - S:代表共享(Shared),表明
Cache Line被多个核心共享,且数据是干净的 - I:代表已失效(Invalidated),表明
Cache Line的数据是失效的,数据未加载或缓存已失效
下图来源于:https://en.wikipedia.org/wiki/MESI_protocol

上图图中,红色表示总线初始化事件,黑色表示处理器初始化事件, MESI其实是一个有限状态机 ,状态转换主要有2种场景,缓存所在处理器的读写、其他处理器的读写。
下面我们一起来看看这2种场景分别有哪些事件:
事件
处理器CPU对缓存的请求,也就是读写操作:
- PrRd: 处理器请求读一个缓存块
- PrWr: 处理器请求写一个缓存块
同步的信息通过总线传递,同步信号(总线对缓存的请求)有下面5种:
- BusRd: 总线窥探器收到其他处理器请求读一个缓存块(总线的请求被总线窥探器监视)
- BusRdX: 窥探器请求指出其他处理器请求写一个该处理器不拥有的缓存块
- BusUpgr: 窥探器请求指出其他处理器请求写一个该处理器拥有的缓存块
- Flush: 窥探器请求指出请求回写整个缓存到主存
- FlushOpt: 窥探器请求指出整个缓存块被发到总线以发送给另外一个处理器(和 Flush 类似,但是缓存到缓存的复制)
状态标记关系
下图是mesi的状态标记图,表示当一个Cache Line的调整的状态的时候,另外一个Cache Line能够调整的对应状态
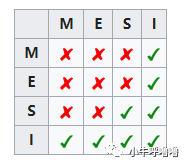
举个例子,假如Cache 1 中存放变量x = 0的Cache Line处于S状态(共享);那么其他拥有x变量的Cache 2、Cache 3等Cache x的Cache line只能调整为S状态(共享)或调整为 I 状态(无效)
状态转化过程
结合上面MESI各个状态含义以及事件,我们再来详细看看状态流转与事件的关系:

Store buffer
如果严格按照MESI协议,某一个核心A在写入Invalid状态的缓存时,需要向其他核心广播RFO获得独占权;当其它 CPU 的Cache Line收到消息后,使他们对应的缓存副本失效,并返回 Invalid acknowledgement 消息;直到这个核心A收到消息才能修改缓存,期间当前核心只能空等待,这对于CPU来说很浪费
整个过程有较长的延时,比较缓慢,一般缓存会通过 Store Buffer写缓冲区和 Invalidate Queue失效队列机制来进一步优化
引入Store Buffer后,当核心写入缓存时,直接写入Store Buffer,当前核心无需等待,继续处理其他事情; 由Store Buffer接手后续工作 ,由Store Buffer向其他核心广播RFO获得独占权,等收到 ACK 后再将修改缓存上。
但是它会导致,虽然核心A以为某个修改写入缓存了,但其实还在Store buffer里。此时如果要读数据,则需要先扫描 Store buffer,另外其它核心在数据真正写入缓存之前是看不到这次写入的
Invalidate Queue
对于其它的CPU核心而言,在其收到RFO请求时,需要更新本地的Cache Line状态,并回复Invalid acknowledgement消息。然而在收到RFO请求时,CPU核心可能在处理其它的事情,无法及时回复。这就会导致当前核心A在等待回复过来的Invalid acknowledgement消息
引入Invalidate Queue后,收到Invalid消息的核心会立刻返回Invalid acknowledgement消息,然后把 Invalid 消息加入 Invalidate Queue ,等到空闲的时候再去处理 Invalid 消息
但是它也会导致,此时核心A可能以为其他核心的缓存已经失效,但真的尝试读取时,缓存还没有置为Invalid状态,于是有可能读到旧的数据

内存屏障
Store Buffer是对MESI发生写操作命令的优化,而Invalidate Queue则是对接受写操作命令时的优化
这些优化,虽然提高了CPU的缓存利用率,但也会带来各自的问题,所以引入了 内存屏障 ,笔者之前在写Java关键字volatile也提及过
内存屏障又可以细分为:写屏障和读屏障
- 这里插入
store buffer写屏障,内存屏障会强制将store buffer的数据写到缓存中,这样保证数据写到了所有的缓存里; - 插入
read barrier读屏障会保证invalidate queue的请求都已经被处理,这样其它 CPU 的修改都已经对当前 CPU可见
-
CMP中Cache一致性协议的验证2010-07-20 713
-
Cache一致性协议优化研究2017-12-30 893
-
c6678cache一致性2018-06-24 0
-
6678多核之间的L1 CACHE一致性是由硬件实现的吗2018-12-25 0
-
改进的基于目录的Cache一致性协议2009-04-02 1859
-
C64x+ DSP高速缓存一致性分析与维护2010-01-04 1449
-
自主驾驶系统将使用缓存一致性互连IP和非一致性互连IP2019-05-09 3224
-
管理基于Cortex®-M7的MCU的高速缓存一致性2021-04-01 724
-
Redis缓存更新一致性的方式2022-11-21 758
-
介绍ARM存储一致性模型的相关知识2023-02-14 1857
-
介绍下cpu缓存一致性(MESI协议)2023-06-09 4663
-
如何解决数据库与缓存一致性2023-09-25 1106
-
如何保证缓存一致性2023-10-19 1094
-
Redis缓存与Mysql如何保证一致性?2023-12-02 925
-
异构计算下缓存一致性的重要性2024-10-24 517
全部0条评论

快来发表一下你的评论吧 !
