

一文详解超标量处理器
电子说
描述
一、引言
处理器(central process unit,简称CPU)是手机的核心部件,其主要功能是取指令并译码执行。CPU主要包括控制器和运算器两个部件,它对在手机中的所有硬件资源(如存储器,输入输出单元)进行控制调配,执行运算。在系统中所有软件层的操作,最终都将通过指令集映射为CPU的操作,因此,它的性能高低直接影响着用户的体验。
得益于半导体工艺的进步,架构的演进,CPU的性能不断地提升。然而,应用程序(APP)的不断发展对处理器性能有了更高的要求,要使得APP运行的稳定、流畅,软件工作者要深入理解处理器的微架构,理解指令的执行过程,做出一些更精细化的改善和优化。
二、超标量处理器简介
目前,手机处理器大部分是超标量处理器(superscalar processor)。想要理解超标量处理器,得先明白流水线技术。流水线技术是将一条指令分解为多个步骤(周期),并且每一个周期时间相同。
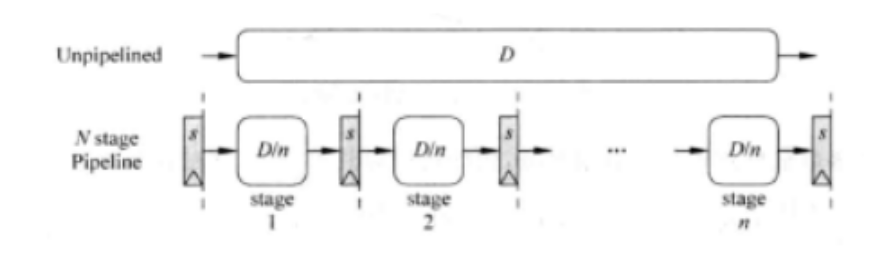
超标量处理器的流水线中,允许多条指令同时存在。这样一条指令不用等待它前面的指令执行完毕,就有可能可以进入处理器的后面得到执行,这种方式提升了处指令并行性(ILP: instruction level parallelism),进而提升性能。如上图所示,当处理器没有使用流水线的时候,它的时间周期是D,在使用了n级流水线之后,一条指令的平均执行周期变成了D/n+S,其中s表示为流水线中间的延迟。
如今,处理器的微架构已经趋于成熟,指令所经过的部件和被处理的过程相似。一个典型的超标量乱序处理器的组织结构如下图所示:
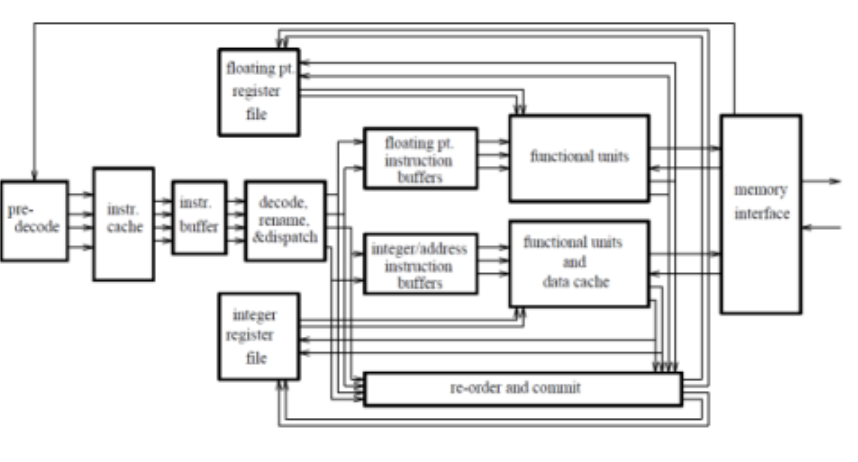
该处理器它包含了取指令(fetch),译码(decode),寄存器重命名(rename),发射(issue),执行(execute),写回(write back),和提交阶段(commit)。
三、处理器流水线介绍
前一小节介绍了超标量处理器的组织结构,本小节将跟踪指令的具体执行过程,介绍处理器在每一个阶段的行为。
1.分支预测/取指令
在取指令阶段,除了需要从I-Cache中取出指令之外,同时还要决定下个周期指令的地址。而分支指令的结果只有在执行阶段才可以得出,因此,有必要对分支指令的行为进行预测,需要预测的内容包含了跳转方向和跳转地址。
a.跳转方向
分支指令可能是发生跳转和不发生跳转,有些分支指令是无条件执行的,它的方向总是发生跳转,其余分支指令则需要进行预测。
对于分支指令方向的预测,主要有以下4种方式:
首先,本文给大家介绍一个简单的分支预测
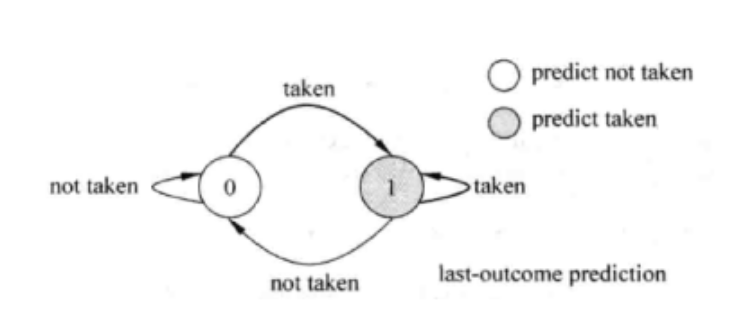
该方法直接使用上次分支的结果,相比于静态分支预测在一些情况下可以获得比较好的结果。如下图,在10000次的for循环语句中,只有两次预测失败了,预测失败率仅有2/10000=0.002%。
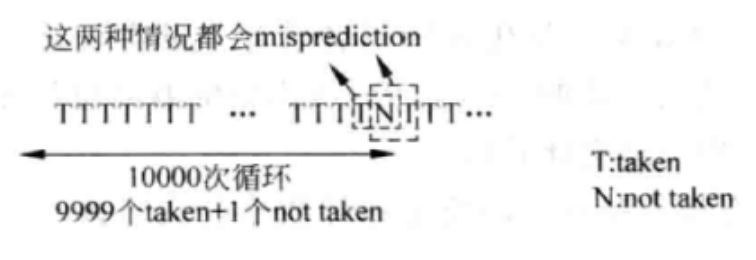
但是在一些情况下,预测的结果是不准确的,如指令的方向不停的发生跳转,那么分支预测的预测失败率可能接近100%.
i. 基于两位饱和数的分支预测
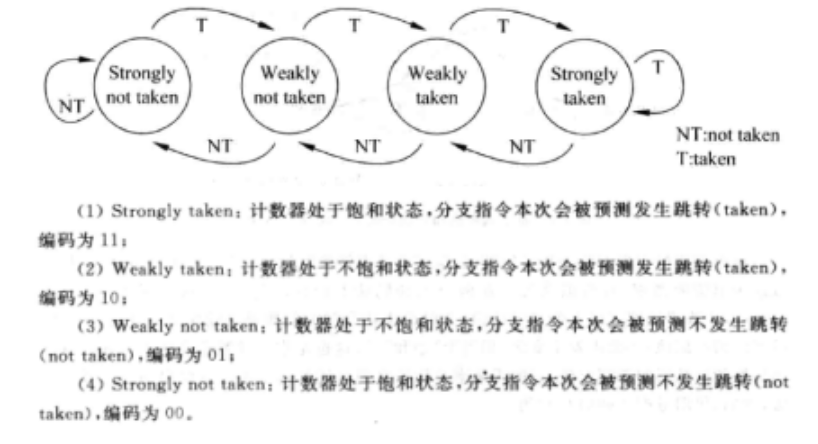
两位饱和数的预测方式在特定情况下有较好的预测结果,但其有一个极限值,因次后来处理器都放弃了这一做法。
ii. 基于局部历史的分支预测
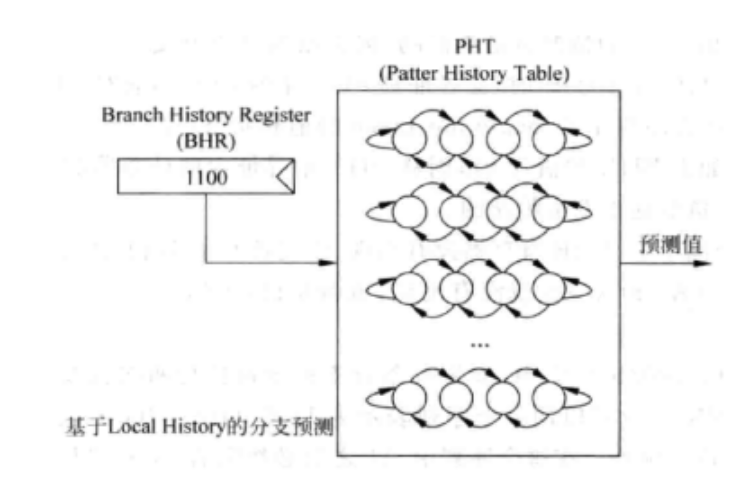
通过将它的每次跳转或者不跳转的结果记录于BHR寄存器中作为历史状态,然后通过PC值索引该表作为参考。如果一条分支指令的执行结果很有规律,那么可以较好地预测正确率。
iii. 基于全局历史的分支预测
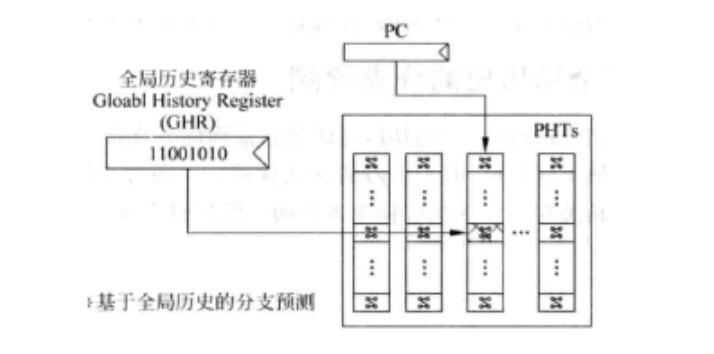
与BHR相似,GHR寄存器记录了最近所有的分支指令的执行结果并作为预测。
i.竞争的分支预测
基于BHR和GHR,在不同场景的应用中,各有优缺点。竞争的分支预设计了一种自适应的算法根据不同的场景自动的选择其中一种预测正确率较高的方法。
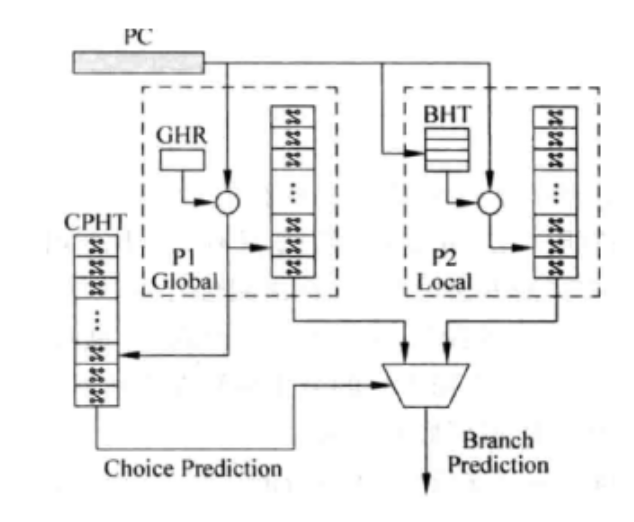
当处理器预测了分支指令会跳转之后,需要对目标地址进行预测:
b. 目标地址
i. 直接跳转:在指令中直接以立即数的形式给出了一个相对PC的偏移值。目标地址是固定的,分支预测器可以准确的找到地址;
ii. 间接跳转:分支指令的目标地址在通用寄存器中,处理器通过获取寄存器中的值,然后根据该值进行跳转。对于一些跳转地址有规律情形,如call指令调用固定地址的函数,return函数返回至函数调用的下一条指令,预测的结果比较准确。其余一些不规律情形,预测它的跳转地址则比较困难。
- 译码
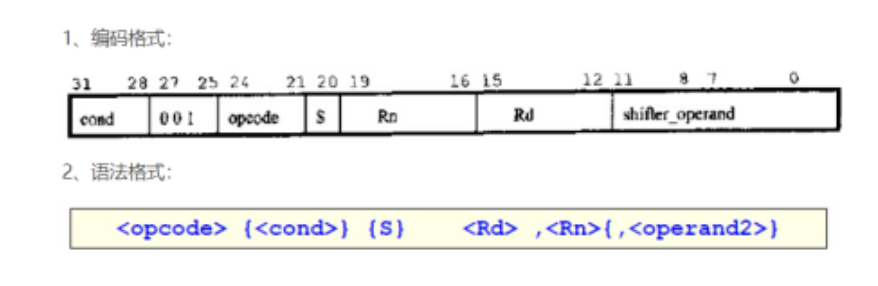
指令解码阶段的任务是将指令中携带的信息提取出来,这时候指令就变成了微操作(uop),处理器的后续阶段将使用这些信息继续执行。对于CICS指令集,指令的长度是不固定的,寻址方式也比较复杂,这增加了译码的难度。目前,在手机处理器中主要用的ARM系列处理器,其指令的长度格式是格式固定的,如在32位处理器中:
- 寄存器重命名
接下来,在超标量乱序处理器中,指令将进入寄存器重命名阶段。首先,本文介绍关于相关性的概念。在处理器执行过程中,指令之间存在一定的相关性,所谓的相关性是指一条指令的执行依赖于另一条指令的执行结果,指令之间的执行顺序不能够改变,这制约了指令发射阶段的选择范围。具体的依赖关系有如下三种:
先写后写(write after write):表示两条指令都将结果写到同一个寄存器;
先读后写(write after read):一条指令的目的寄存器和它前面某一条指令的源寄存器一样;
先写后读(read after write):一条指令的源寄存器来自于它前面某条指令的计算结果;
在采用乱序执行的处理器中,寄存器重命名通过映射表将逻辑寄存器(指令中表示的寄存器)映射到物理寄存器(处理器中参与运算的寄存器)解决了WAR 和WAW依赖关系,不存在依赖关系的指令可以同时执行,提高了ILP(instruction level parallesim)。如下图:
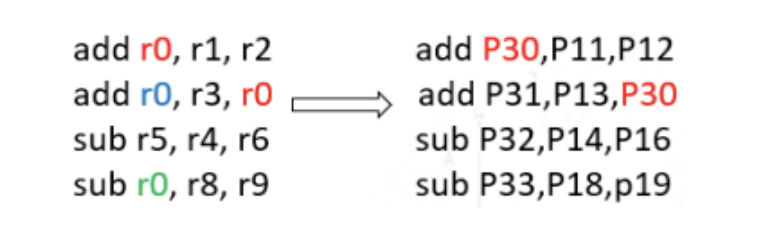
只有第二条指令的源寄存器r0依赖于第一条指令计算的结果,寄存器重命名之后,其余指令之间并无依赖关系。
- 发射
将符合一定条件的指令从发射队列中选出来,并送到FU(function unit)中去执行。满足发射条件是指指令的操作数准备好了,FU数量充足。然而,对于访存(load/store)指令,只有在执行阶段指令的地址被计算得出,它们之间的依赖关系才可以知道。处理器有一定的做法,来加速这种执行方式。对于存储指令加速的如下的三种方式,当出现违例(memory vialotion)时,在流水线的后续阶段会进行消歧处理。
- 完全的顺序处理
- 部分的乱序指行,如下图
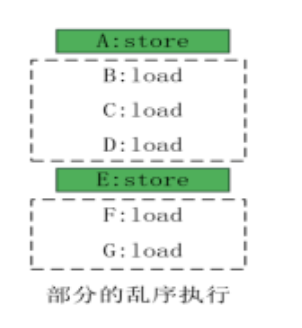
- 完全的乱序指令
- 执行
指令在执行单元获得执行,典型的执行单元有ALU,AGU,BPU。
- 写回
将FU计算的结果写到物理寄存器堆,并通过旁路网络将这个计算结果送到需要的地方,唤醒依赖于这条指令计算结果的指令。如:
add r0, r1, r2 (1)
add r4, r0, r3 (2)
当第一条指令的结果r0计算完成,它会通知第二条指令r0的值已近准备好,那么这条指令才有可能变成准备好的状态并获得发射执行。
- 提交
程序的指令流顺序进入处理器,乱序执行,并按照指令进入ROB(Reorder Buffer,重排序缓存)的顺序进行提交这保证了程序执行正确性。保留提交信息的关键部件是ROB,它的结构如下图:
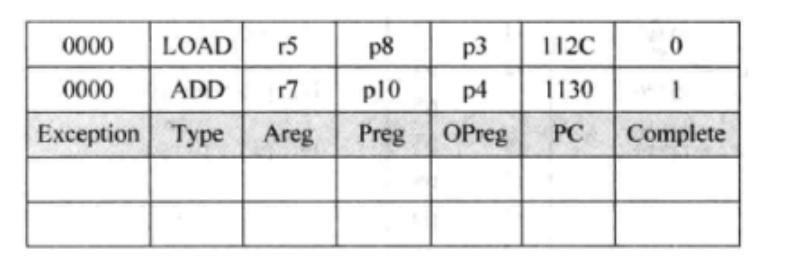
当一条指令到达流水线的这个阶段时,ROB会将这条指令标记为complete状态,但是并不意味着可以提交了,比如异常,分支预测失败等,一条已经完成状态的指令可能从流水线中抹掉。所以,在一条指令没有退休(retire)之前,他的状态都是推测的(speculative),
ROB本质上是一个FIFO器件,存储了一条指令的相关信息。如这条指令的类型、结果、目的寄存器、和异常的类型等。ROB的容量决定了流水线中最多可以同时执行的指令的个数。每一个ROB的表项可以包括的内容如下:
(1)complete, 表示一条指令是否已经执行完毕;
(2)Areg: 在原始程序中指定的目的寄存器,它以逻辑寄存器的形式给出;
(3)Preg:指令的Areg经过寄存器重命名之后,对应的物理寄存器编号;
(4)Opreg: 指令的Areg被重命名为新的Preg之前,对应的旧的Preg, 当指令发生异常(exception), 而进行状态恢复的时候,会使用这个值;
(5)PC:指令对应的PC值,当一条指令发生中断或者异常的时,需要重新保存这个值;
(6)Exception,如果指令发生了异常,会将这个异常的类型记录,当指令要退休的时候,会对这个异常进行处理;
(7)Type:指令的类型会被记录到这里,当指令退休的时候,不同类型的指令会有不同的动作,例如store指令要写入D-cache。
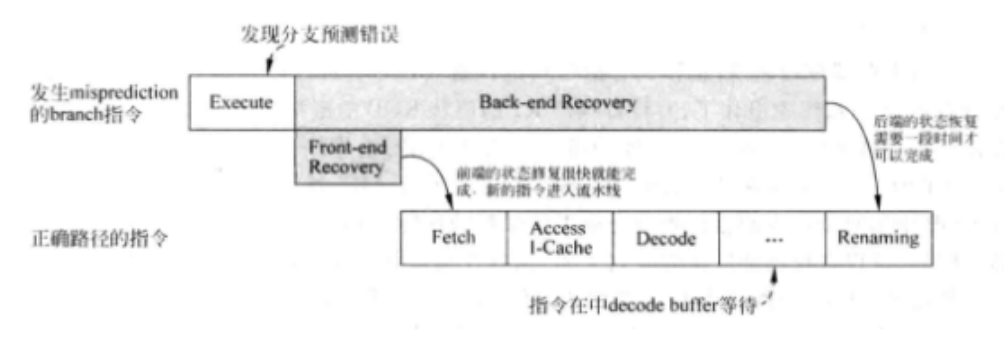
处理器的执行过程中,错误的分支预测也需要处理,这个执行过程如下:
(1) 回滚:将在错误路径上的后续指令从流水线中“冲刷”;
(2) 重新取指:"正确的路径上取出合适的指令执行;
四、处理器性能建模
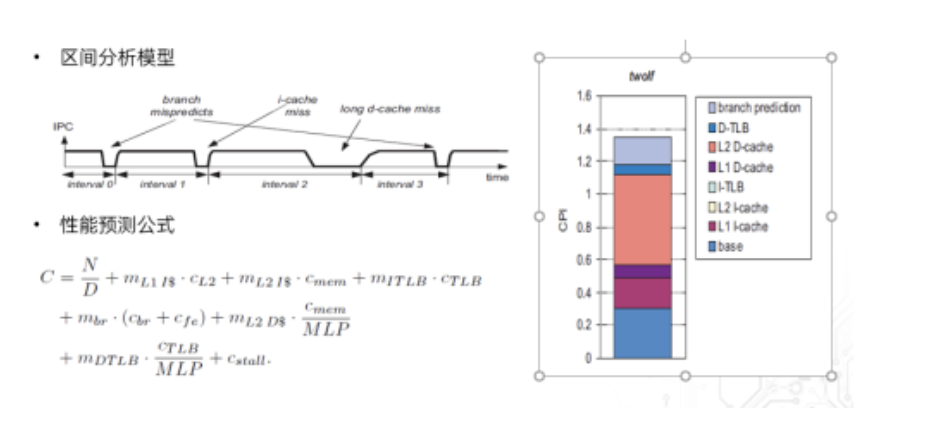
处理器的执行过程中,理想状况下,处理器运行在稳定的状态,没有停顿和“汽泡”。然而总会有各种缺失(miss)事件导致性能的下降。根据区间模型理论,处理器的CPI(cycles per instruction)可以根据硬件PMU参数的值和参考硬件手册中缺失事件的代价,并通过公式进行拟合。这些拟合的结果可以作为应用负载的特性给处理器的调度作为参考。
五、影响处理器发展的三堵墙
- 功耗墙
功耗是影响处理器性能发挥的重要因素,尤其在是嵌入式设备如手机领域,手机通过电池供电,电池容量有限,所以处理器功耗不能过高。

Post-Dennardian(处理器供电电压不变),系统增加S倍,但是因为供电电压不变,电容减少了S倍,所以总功耗增大了S^2倍。为了保持总功耗不变,chip利用率将减小为以前的1/S^2。
- 访存墙
处理器的性能在发展过程中有大量的提升,然而内存受限于工艺,价格,带宽和延迟等发展缓慢。处理器运算速度和内存访问速度不匹配。

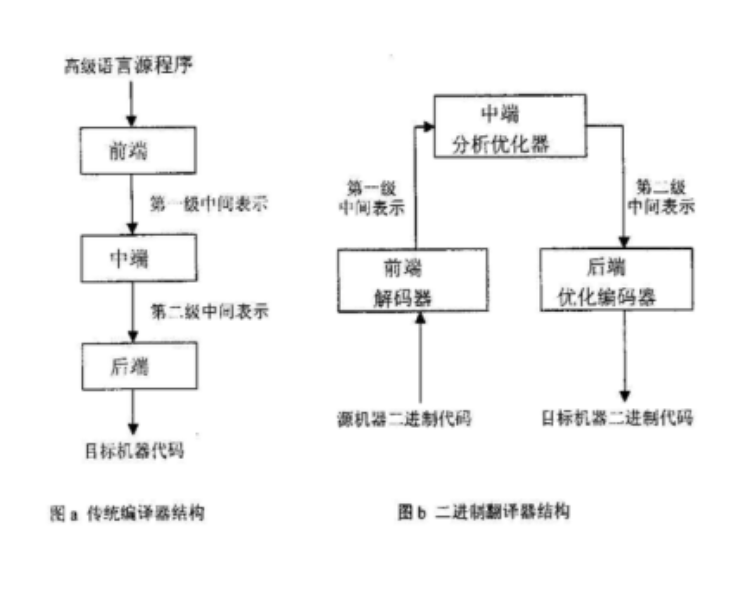
- 编译墙
不同处理器有不同的指令集,需要通过二进制翻译技术将一种处理器上的二进制程序翻译到另一种处理器上的可执行程序,这可以扩大了硬件、软件的适用范围,提高了兼容性。
六、总结
超标量处理器是手机平台的核心,处理器的微架构在不断地变化和演进中,软件工程师如何利用硬件特性,写出高质量、高性能的代码成为了一个难点和痛点。
本文详细介绍了超标量处理器的微架构,跟踪了一条指令在处理器每一阶段的具体执行过程,让读者深刻理解了硬件行为。同时,结合性能采样分析工具如perf, vtune, simpleperf,读者可以获取程序的热点(hotspot)或者性能瓶颈。然后,软件工作人员可以通过读取硬件数据PMU(Performance Monitor Unit),深刻理解处理器的性能瓶颈,对代码做出针对性的调整、优化。这可以充分发挥具体处理器的性能,进而提升整个手机应用的体验。此外,深刻理解处理器执行方式,通过建模的方式,可以获悉软件应用的负载大小,这为操作系统的调度提供了进一步的思考。
处理器,特别是在手机平台上的处理器,它的性能发挥受限于存储墙,功耗墙,如何克服这些不利因素,提高未来手机的整体体验,读者可以进一步思考。
-
超标量处理器的微体系结构由哪几部分组成?2022-02-28 0
-
Arm Cortex-R52处理器技术参考手册2023-08-17 0
-
PowerPC芯片特点及超标量体系CPU优化技术2017-10-19 774
-
ARM Cortex-R52处理器技术参考手册2023-08-18 0
-
Arm Cortex-M7处理器产品介绍2023-08-25 0
-
ARM Cortex-R52+处理器技术参考手册2023-08-29 0
-
什么是超标量技术/FADD?2010-02-04 1588
-
处理器种群及种群设计错误详解2016-12-15 503
-
乱序超标量处理器核的功耗优化2017-11-23 796
-
新思科技推出全新ARC处理器,采用超标量ARCv3指令集架构2020-06-01 5418
-
超标量处理器的指令乱序提交机制综述2021-06-07 765
-
一文详解高效能x86处理器2022-10-24 1814
-
小编科普一下超标量处理器中的Cache2023-01-08 946
-
一文详解CP15协处理器2023-10-31 2099
-
什么是超标量处理器的流水线?超标量处理器的特点有哪些?2024-03-04 3053
全部0条评论

快来发表一下你的评论吧 !
