

Python利用pandas读写Excel文件
电子说
1.3w人已加入
描述
pandas模块read_excel读取Excel文件
使用pandas模块读取Excel文件可以更为方便和快捷。pandas可以将Excel文件读取为一个DataFrame对象,方便进行数据处理和分析。
以下是使用pandas读取Excel文件的示例代码:
import pandas as pd
df = pd.read_excel('test.xlsx', sheet_name='test1', merge_cells=True, na_values=['NA'])
df = df.fillna('')
# 格式化输出
with pd.option_context('display.max_rows', None, 'display.max_columns', None):
print(df.to_string(index=False, header=True, col_space=4, justify='left'))
在读取Excel文件时,read_excel函数提供了很多参数,可以用于控制读取的方式和行为,例如读取指定的工作表、指定的行和列、指定数据类型、跳过指定的行等等。你可以根据需要设置这些参数。 除了读取Excel文件,pandas还提供了很多数据处理和分析的工具和函数,例如数据重塑、数据聚合、数据可视化等等。如果需要对Excel文件进行复杂的数据处理和分析,pandas将是一个很好的选择。
merge_cells=True
pandas可以通过设置merge_cells参数来控制如何读取数据。当merge_cells设置为True时,pandas将读取合并单元格中的第一个单元格的值,并将其复制到其他合并单元格中。当merge_cells设置为False时,pandas将读取每个合并单元格的值。
na_values=['NA']可以设置na_values参数来指定哪些值被认为是NaN。 使用fillna()函将其设置为空格字符串('')或者设置为Excel文件中的特定值。
with pd.option_context('display.max_rows', None, 'display.max_columns', None):
print(df.to_string(index=False, header=True, col_space=4, justify='left'))
使用to_string()函数将数据格式化输出,将行索引或者列头隐藏,每列的宽度为4,左对齐显示。
注意,在使用pandas输出Excel格式时,使用to_string()函数输出的结果可能无法精确地模仿Excel的外观和格式。这取决于你的数据和你的格式要求,可能需要调整输出的方式来达到目标。
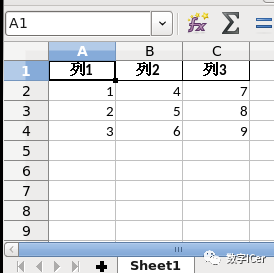
运行结果如下:
pandas模块to_excel写入Excel文件
要将pandas数据写入Excel文件,可以使用pandas模块中的to_excel()函数。
import pandas as pd
# 创建一个数据帧
df = pd.DataFrame({'列1': [1, 2, 3], '列2': [4, 5, 6], '列3': [7, 8, 9]})
# 将数据帧写入Excel文件
df.to_excel('pandas_write.xlsx', sheet_name='Sheet1', index=False)
在这个例子中,首先使用pandas创建了一个包含三列数据的数据帧。
然后,使用to_excel()函数将该数据帧写入了一个名为“pandas_write.xlsx”的Excel文件中,并将工作表命名为“Sheet1”。
通过将index参数设置为False,可以避免在Excel文件中写入数据帧的行索引。
如果要将多个数据帧写入同一个Excel文件中的不同工作表,可以多次调用to_excel()函数,并指定不同的工作表名称。
审核编辑:汤梓红
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
labview 编写的EXCEL文件的读写示例2015-12-16 0
-
基于python读取excel表格2018-12-28 0
-
Excel读写控件安装2016-03-22 922
-
如何通过pandas读取csv文件指定的前几行?2018-09-19 2213
-
abaqus-Python实例-操作excel文件下载2020-12-17 741
-
从Excel到Python数据分析进阶指南资源下载2021-04-06 1415
-
如何读写带有formulas的Excel文件浅析2021-04-26 3035
-
好消息 Python与Excel终于互通了 !2021-04-30 2012
-
详解Python中的Pandas和Numpy库2022-05-25 2586
-
如何用Python来操作Excel文件2022-08-05 1007
-
利用Python读取多份Excel的小技巧2023-02-02 2347
-
如何使用Python和pandas库读取、写入文件2023-09-11 1193
-
如何使用Python和pandas库操作Excel文件2023-09-11 1071
-
如何利用Python和pandas来处理json数据2023-11-01 2388
-
Python中Excel转PDF的实现步骤2023-11-20 1138
全部0条评论

快来发表一下你的评论吧 !
