

网络社交机器人检测的关键技术
描述
来源:中国指挥与控制学会
作者:黄海涛 田虎 郑晓龙 曾大军
在线社交网络面临着网络社交机器人操控的威胁,而现有的检测算法还不能缓解这种威胁。如何有效利用人工智能技术检测社交机器人,规避其潜在的风险并保障网络的良好生态,是当前亟需解决的重要任务。
随着互联网与信息技术的蓬勃发展,在线社交网络吸引了大量用户,成为现今网络空间的重要组成部分。自从在线社交网络出现以来,网络社交机器人就与在线社交网络相伴而生。根据Grimme等人的定义,网络社交机器人涵盖多种自动化与半自动化智能体,这些智能体通过在网络空间中进行单向或多方向的通信来实现特定的目的,并非仅涵盖在线社交网络中的机器人。但在本文中,我们只考虑被广泛研究的在线社交网络中的社交机器人,这些机器人主要通过与其他账户建立好友关系、发布或转发帖子来实现其所有者的特定目的。
由于其自动化特性,网络社交机器人可以用于实现某些需要持续很长时间的有益于网络空间健康发展的简单功能。但同时,我们也应当看到目前网络社交机器人产生的问题和引发的社会矛盾远大于其所能提供的收益。网络社交机器人可能造成用户隐私泄露的问题:在脸书、推特等社交媒体上,大量用户轻易相信未知账号,愿意接受好友请求或反向关注那些关注他们的用户。除信息泄漏外,网络社交机器人也在给用户造成经济损失:它们串通协作推广低价值股票,或是为特定应用程序和销售商品打广告。网络社交机器人对于民主政治、社会分裂和政治冲突的影响也不容忽视:在2016年的美国总统大选中,社交机器人在假新闻传播的早期阶段极大扩展了相关新闻的影响范围,危及总统选举的公正性。2018年佛罗里达校园枪击案后,社交机器人的活动加剧了推特用户关于控枪问题的情绪极化现象,进一步撕裂美国社会共识。部分推特社交机器人在北京冬奥会期间通过放大争议等方式制造有关冬奥会的政治冲突,加剧了奥运会相关舆论宣传的泛政治化。
综上所述,未受到规范的网络社交机器人活动已经引发了各方面的多种损失与问题,网络空间面临着严峻的被操控风险,必须引起我们高度重视,力求通过科学界与产业界的高度合作,尽量遏制恶意网络社交机器人的蔓延。
一、网络社交机器人的产生背景
现今社交网络已经深度融入到每个人的生活当中,脸书、微博等平台已经拥有亿万活跃用户,具备令人惊叹的推广传播效果的同时也为网络社交机器人恶意操纵信息传播提供了可乘之机。同时,信息技术的发展也使得能够接触到网络社交机器人等相关技术的人群呈爆炸性增长,Github等开源程序社区上可以公开获取的网络社交机器人程序框架和功能完备的计算机程序已有很多。基于这些框架或程序进行二次开发的难度较低,这也是为网络社交机器人泛滥的提供了技术便利。此外,人工智能技术的发展也大幅提升了网络社交机器人的识别难度和智能水平。目前,社交机器人已经进化成具有昼夜节律、盗用他人账户信息、能够通过转发正常推文和模拟点击等行为掩盖真实目标的智能体,使得许多曾经有效的关键特征失效,大大提高了识别和检测难度。在可预见的未来,基于效果拔群的ChatGPT等预训练语言模型和styleGAN等图像生成技术自主生成具有较高迷惑性消息并进行发布的网络社交机器人很有可能代替现有的需要人工编写所发布消息的网络社交机器人。这种智能水平的提高会进一步提升正常用户识别和算法检测的难度,造成更大的伦理风险。
为了保护社交媒体平台或在线讨论社区产品不被社交机器人控制,同时维持平台用户活跃性的目的,很多互联网公司已经开发和部署网络社交机器人检测算法。比如微信团队已经发表了多个有关网络社交机器人检测的研究工作,并在微信平台上部署了相应的检测算法,取得了很好的检测效果。推特与脸书虽没有发表过相关论文,但这些平台也都在批量暂停网络社交机器人账户,表明其也拥有较强的反制措施。新生代的网络社交机器人就是在这样的持续检测环境中产生,他们已经通过了所在平台的检测机制,并在这样的生成-检测对抗中不断加强,逐渐提高其迷惑性和检测难度。
二、网络社交机器人检测存在的技术挑战
(一)社交机器人持续进化,规避检测能力加强
2015年以前出现的网络社交机器人比较简单,呈现出明显的非智能化和机器人之间相互关联的弱点,经过特征或模型设计很容易与正常用户区分开来。但在2017年,Cresci等人的研究论文证实,新出现的网络社交机器人与早期的网络社交机器人完全不同,它们普遍使用非常详细的伪造的或是盗用的个人信息,能够模仿昼夜节律,且仅在大量正常的推文中穿插少量带有特定目的的推文。在这次社会调查中,人工分类新机器人仅有24%的准确率,也正是这类机器人可以吸引大量正常用户的关注。在这种进化过程中,社交机器人通过改变伪装手段的方式,极大提高了其检测难度,造成检测算法必须面对社交机器人持续进化、规避检测能力不断增强的挑战。
(二)网络社交机器人协调传播行为较为复杂
在最新的网络社交机器人中,机器人之间的相互串通与关联行为已经很难从社交关系中找到蛛丝马迹,即机器人网络演变成由隐藏实体所操控的为达成特定目标而采取协调行为的机器人群体,这些机器人彼此之间却不存在社交关系。Agarwal等人通过分析推特社交机器人发现在社交机器人网络中找不到为其他机器人提供信息的中心节点,印证了这一挑战的存在。这使得我们必须仔细而严谨地思考网络社交机器人在协调传播特定目的信息时所表现出的特征以及协同行为的判断标准,这无疑提高了社交机器人检测难度。
(三)检测算法开发环境与使用环境差异过大
检测算法开发环境与使用环境差异过大有两层含义:其一是指检测算法于平稳的中性环境中开发,而实际使用环境完全不满足此假设;其二是指我们希望检测算法能够在社交机器人尚未传播虚假信息甚至是注册时就能检测到它们,但大部分现有算法仅能实现已传播虚假信息的社交机器人的检测功能。平稳中性的开发环境是指开发过程中使用固定数据集,即假设社交机器人不会产生进化、不会更改策略欺骗检测算法,但这在实际部署检测场景中并不成立,造成检测算法实用效果严重受限。且现有检测算法大多采用社交机器人的发布推文或社交行为特征,只能在认识到新的社交机器人种类出现之后开发对应的检测算法,难以发挥期望的预防社交机器人的作用。以上两方面原因造成目前开发的检测算法并不是我们真正需要的检测算法,构成我们开发新社交机器人检测算法的严峻挑战。
三、网络社交机器人检测的关键技术
现有的网络社交机器人检测方法普遍将社交机器人检测处理成一个二分类问题,并不会对账户在特定时间上是否在进行攻击或是账户属于哪一类网络社交机器人进行区分。但是,这种设计思路由于缺乏对于社交机器人的细致描述,不利于描述混合自动化行为与人工驱动行为的半机器人,也不利于研究人员理解不同类别社交机器人与人类的本质区别,已经成为网络社交机器人检测算法发展之路上的重大阻碍。现有的网络社交机器人检测方法可以依据其检测网络社交机器人的原理分为两类,一类是基于账户特征的方法,另一类是基于网络结构的方法,下面将对这两类方法分别进行概述、介绍典型工作和分析优劣势。两类方法的分类框架及优缺点概括如图1所示。
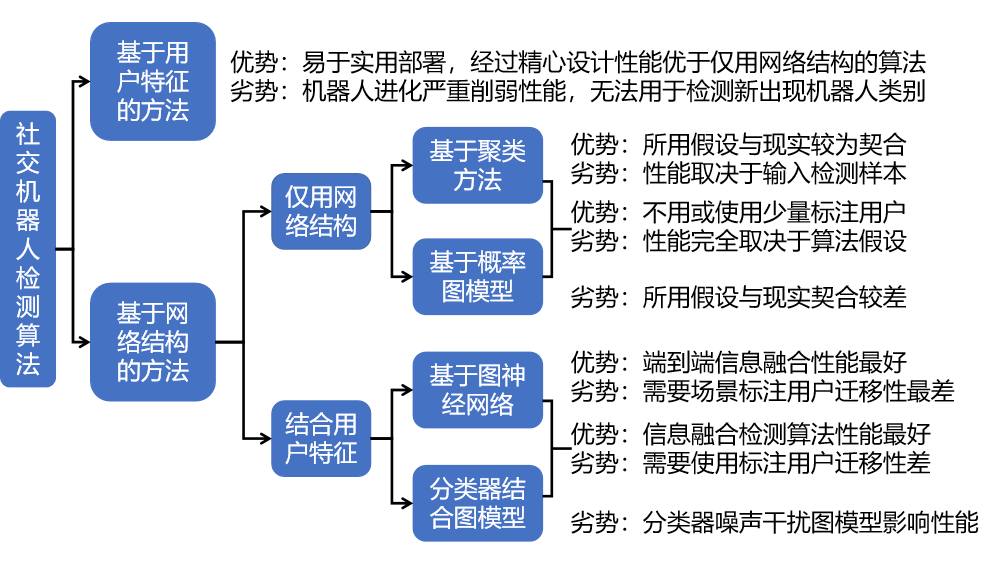
图1 网络社交机器人检测算法分类框架图
(一)基于账户特征的方法
基于账户特征的方法普遍忽视网络社交机器人组成机器人网络协调传播隐蔽关联的特性,将社交机器人视为单独账号进行检测。这种方式无法利用账号协调传播信息,需要大量已标注的账号作为训练样本以训练检测算法,且样本质量对于检测算法性能影响很大。
基于账户特征的检测方法总体技术框架如图2所示,其类似于传统的机器学习模型,由特征提取部分和分类器部分构成。分类器部分主要采用机器学习领域已经开发成熟的分类模型,故相关研究工作集中于如何进行特征工程或设计神经网络模型以快速有效地提取账户特征方面。这也使得这种方法的有效性取决于社交机器人与正常用户在多种特征上的统计差异。如果社交机器人通过进化等方式在某些关键特征上弥合与正常用户之间的分布差异,这种方法的有效性就要大打折扣,研究人员也就不得不转而开发新算法以解决危机。
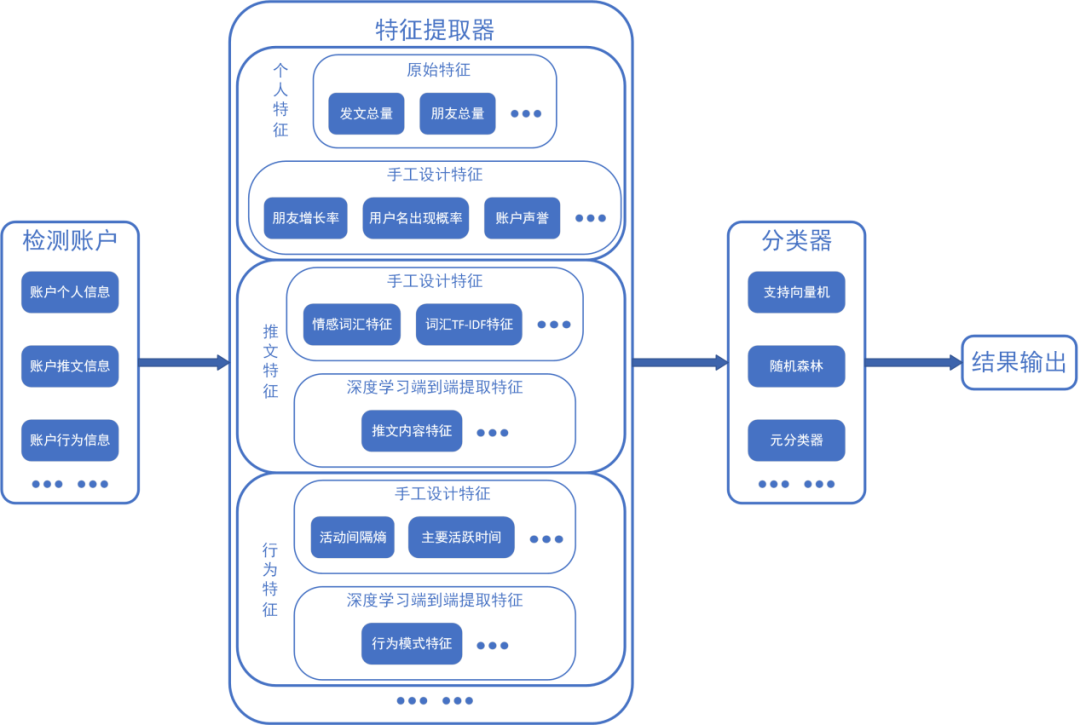
图2 基于账户特征的检测方法技术框架示意图
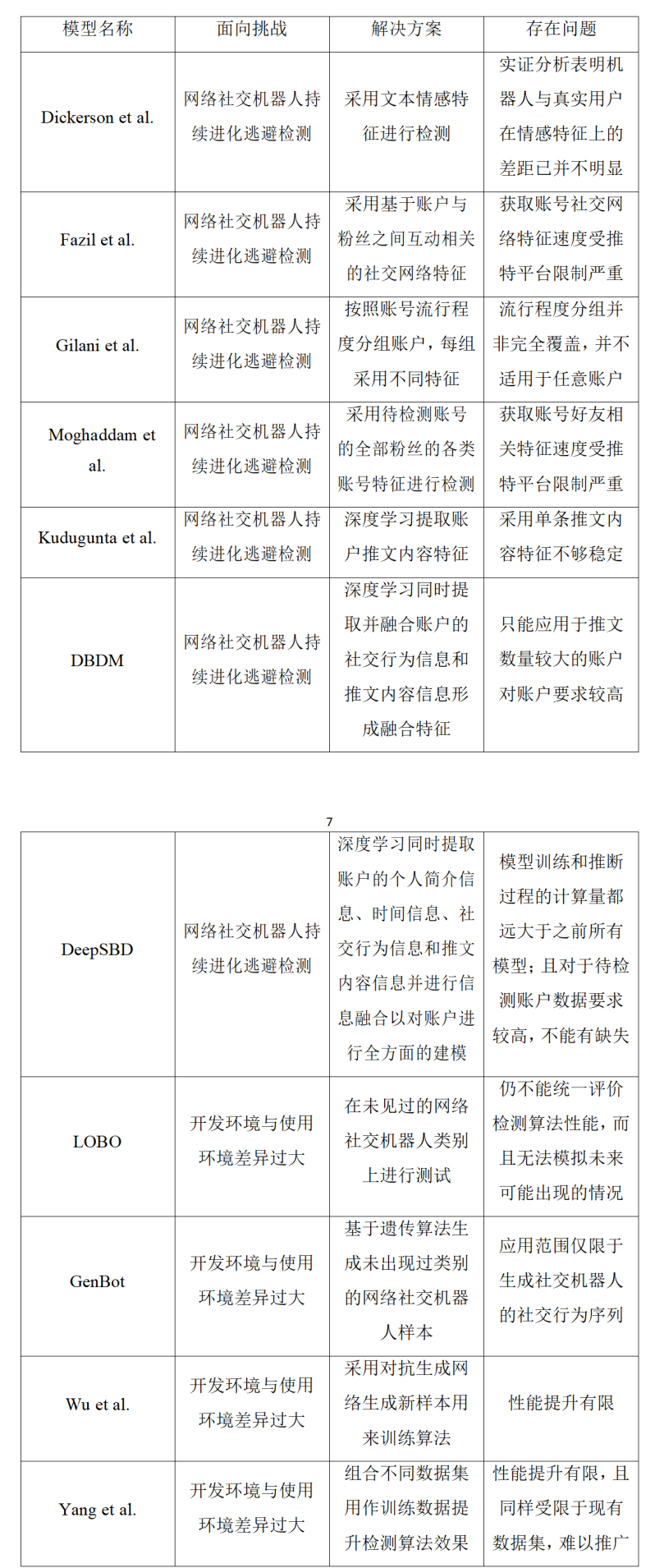
基于账户特征的方法因其检测与部署服务门槛较低,相较于基于网络结构的方法更加贴近实际应用,其中以Botometer为代表的公开检测服务更是提高了公众对于社交机器人的认识程度。Botometer主要通过由账户的个人特征、好友特征、时间相关特征、推文内容特征等构成的千余项特征执行推特上的社交机器人检测任务,是一种面向推特各种类别社交机器人的通用检测算法。但是受限于所采用的训练数据和社交机器人的进化逃避检测特性,Botometer的实际检测准确率较低,难以发挥应有的维护社交网络空间清朗的作用。研究人员为提升基于账户特征方法的性能付出了很多努力,产生的应对机器人进化逃避检测和检测算法开发环境与使用环境差异过大两大挑战的方式如表1所示。目前,研究人员逐步达成共识:网络社交机器人难以操纵的特征或是操纵起来非常昂贵的特征是比较稳健的,较为适合应对网络社交机器人进化逃避检测的挑战,比如待检测账号的全部粉丝的各类账号特征。
表1 基于账户特征的方法解决两类挑战提出的算法
(二)基于网络结构的方法
基于网络结构的检测方法可以按照是否使用账户特征再细分为两类。不使用任何账户特征的一类不需要任何标注用户或仅需少量种子节点用户即可进行检测,较有代表性的分别为基于聚类的方法和基于概率图模型的方法。同时使用账户特征信息和机器人网络协调传播行为信息的一类则需要使用标注用户,以标注用户作为监督信号辅助推断或以标注用户训练分类器,较有代表性的分别为基于图神经网络的方法以及结合分类器与概率图模型的方法。
首先介绍不使用任何账户特征的完全基于网络结构的方法。其中,基于聚类的方法的基本假设是不同的正常用户社交行为之间存在较高异质性,用户社交行为相似性较高则说明受到同一主体控制。这类方法的研究专注于网络机器人社交行为信息提取方式,通过抽取对于网络社交机器人检测更加有效的信息提升检测算法的性能。基于概率图模型的方法的基本假设是社交机器人主要与社交机器人相互连接,难以与正常用户建立社交关系。这类方法的研究专注于改进概率图模型算法和修正网络结构的方式,以引入更加符合实际情况的假设从而提升网络社交机器人检测算法的性能。由于这两类方法不使用任何标注信息或仅使用少量标注信息,故其社交机器人检测工作实质上是依赖于研究人员基于领域先验知识所做假设来进行的,所以算法性能取决于研究人员的理解认知程度以及在算法中所采取的假设与实际情形的契合程度。相比之下,基于聚类的方法其基本假设与现实契合程度高于基于概率图模型的方法。Cresci等人发现社交网络中用户的相似行为呈现出对数正态分布特性,证实了正常用户行为具有较高的异质性。Yang等人发现社交机器人并不会形成紧密连接的社区,80%的机器人专注于与正常用户建立社交关系。
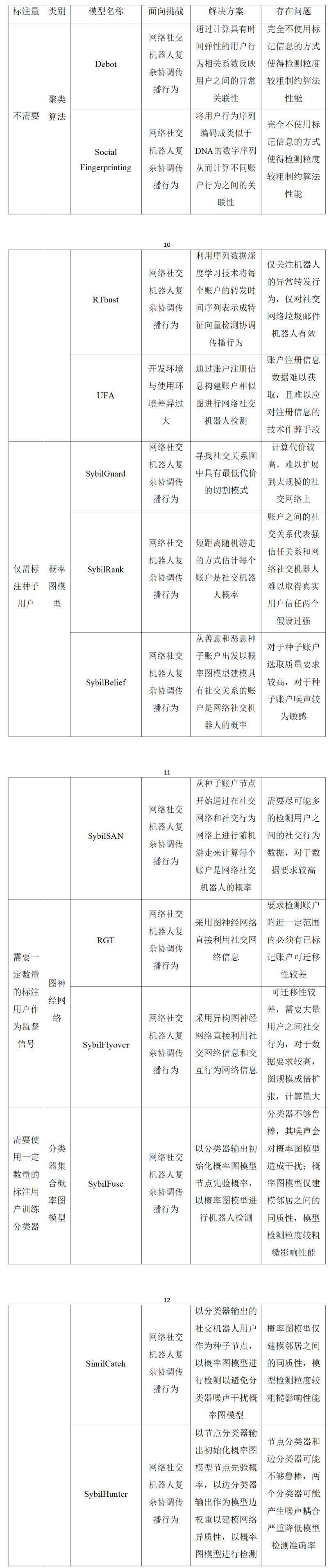
同时使用账户特征信息和机器人网络协调传播行为信息的检测方法的初衷则是将用户特征信息与网络结构信息融合起来,以详细的账户或行为信息补充较为粗糙的社交关联信息来细化检测粒度,以社交关联信息指导检测对抗仅依赖账户特征无法解决的机器人不断进化逃避检测问题。这种指导思想使得经过精心设计的同时使用账户特征和网络结构的方法性能优于仅使用账户特征或网络结构的方法。将用户特征与网络结构结合起来的方式主要有两种:其一是图神经网络,这是一类端到端的将节点信息和结构信息结合起来的方法;其二是以分类器先将节点特征聚合起来形成先验概率,再将先验概率输入概率图模型,集成结构信息形成检测结果的形式。这两类方法仍然需要使用标注用户数据,其中基于图神经网络的方法以标注信息作为监督信号以半监督直接推导的方式进行检测,甚至需要待检测账户网络结构附近存在标注用户,造成检测算法可迁移性较差。而结合分类器与概率图模型的算法同样需要大量标注数据用来训练分类器,还会因为分类器不够鲁棒,被进化逃避检测的机器人特征信息欺骗,从而将噪声传入概率图模型中,产生检测效果仍然不尽如人意的问题。研究人员为提升基于网络结构的方法的检测效果,在应对社交机器人的复杂协调传播行为挑战方面做出了很多努力,典型方案如表2所示。但同时,我们也要注意到,因考虑动态网络结构或早期检测难度较高,故基于网络结构的方法很少考虑开发环境与使用环境差异过大这个问题。
表2 基于网络结构的方法解决两类挑战提出的算法
四、网络社交机器人检测的未来研究展望
目前,网络社交机器人检测仍然不能很好地解决三大挑战,所以说网络社交机器人检测的发展仍然任重道远,需要学术界和产业界的通力合作,只有这样才能将网络社交机器人操纵信息传播、操控舆论等危害降到最低。对此提出未来的合作与发展方向:
(一)学术界与产业界需要在算法和数据方面通力合作
目前,对于学术界来说,网络社交机器人检测任务最大的困难在于数据集缺失和质量低下的现状以及缺乏实际部署测试场景。现有数据集主要是各种类别网络社交机器人的混合数据集且仅有是否为机器人的二值化标注信息。况且大量数据集是通过网络社交机器人账户与随机抽取的正常用户账户组成的,对于这样毫不相关的两类账户来说,其检测分类难度相对较低,容易造成检测算法性能较差的问题。另外,现有数据集大多通过众包形式人工标注或是通过蜜罐账号引诱获取,人类标注准确性不足、蜜罐账号不具备普遍适用性,这也是现有数据集质量较差的重要原因。而学术界因不受产品效益制约,在检测算法设计方面拘束较少,在研究过程中积累了很多值得参考的经验。所以,双方合作能够更好地解决社交机器人检测问题。
(二)不同学科需要在网络社交机器人理解与识别方面通力合作
网络社交机器人检测研究需要集成各个学科的力量。网络社交机器人的问题不单单是技术的问题,更是信息传播的问题和社会的问题;当前研究普遍倾向于多极分化:计算机相关学科主要关注通过人工智能技术检测网络社交机器人,复杂系统相关学科主要关注社交机器人网络及其行为演化分析,社会科学领域各学科则主要关注类似于确权问题、公平性问题、信息传播问题等等。这种分裂的现状使得各学科难以参考其他学科的先进研究成果,也不利于对网络社交机器人进行详细的类别划分,有碍于研究人员深入认识网络社交机器人。所以说,社交机器人的理解与识别需要各个学科联合起来,从影响、技术、信息传播、认知方式等多个角度思考,进行深入详细的归类和阐释。
(三)同时采用用户特征与网络结构的检测方法是未来的发展方向
单独使用结构信息进行检测会因信息不充分只能采用邻居同质性假设,产生检测粒度粗糙问题影响算法性能;单独使用用户特征信息进行检测又会因为将账号视为单独个体,难以对抗机器人进化逃避检测问题。况且,在机器人账号创建初期,其账号特征与正常用户差距并不太大。因此,将用户特征信息与网络结构融合起来,以用户特征指导基于网络结构的检测方法,同时建模网络的同质性与异质性,细化其检测粒度才能实现高准确度高可靠性的机器人检测算法。
(四)网络社交机器人的早期检测算法与注册时检测算法才是真正需求
目前的检测手段大多只能检测已经开始根据特定目的散播消息的机器人,难以应对新产生的机器人类别,无法将尚未散播消息的机器人与正常用户区别开来,更无法在注册账号阶段就将机器人拦截下来。这样的算法只能算是亡羊补牢,在发现机器人的社会影响之后避免其进一步扩散,无法实现防患于未然。想要彻底杜绝机器人对网络环境的恶意影响,只有在其尚未发帖的构建社交网络阶段甚至是注册时就将其标记出来,一旦出现问题,立刻暂停账号。所以说,网络社交机器人早期检测算法与注册时检测算法才是真正需要的检测算法。
综上所述,现有的网络社交机器人检测算法仍不能缓解机器人操控网络环境的风险。未来需要学术界各学科之间、学术界与产业界通力合作,深化对于网络社交机器人的认识,制定更加精确、全面的检测算法训练和测试数据集,构建高精度的能够对抗进化的全自动和半自动机器人的检测算法。在此基础上,全面厘清机器人与正常用户之间的区别,构建有效的早期检测算法,实现防患于未然的效果。
审核编辑:汤梓红
-
水下机器人亟待解决的关键技术问题2019-07-17 13266
-
相机如何帮助可以“理解”人类的社交机器人?2021-03-18 1653
-
智能语音机器人2015-12-02 0
-
浅析机器人技术及其应用2016-09-22 0
-
基于深度学习技术的智能机器人2018-05-31 0
-
工业机器人的技术原理2018-11-23 0
-
让机器人实现智能的关键技术到底是什么?2021-07-05 0
-
机器人技术和机器学习2021-12-20 0
-
哈工大:服务机器人的六大关键技术2016-04-21 4443
-
智能机器人的三大关键技术详解2016-11-16 32423
-
工业机器人的关键技术及应用趋势2017-02-07 819
-
Cobot机器人的关键技术解析2017-10-16 741
-
服务机器人区别于工业机器人的关键技术是可以自主行动2018-12-14 2570
-
hachidelight智能机器人关键技术创新与突破 已对接5G2020-11-18 1945
-
焊接机器人关键技术有哪些?2023-10-19 1492
全部0条评论

快来发表一下你的评论吧 !
