

基于大模型的遥感图像变化检测新网络
人工智能
描述
01
/导读/
变化检测是遥感领域的一个重要研究领域,对于观察和分析地表变化起着关键作用。尽管基于深度学习的方法在该领域取得了显著的成果,但在时空复杂的遥感场景中执行高精度的变化检测仍然是一个重大挑战。最近流行的基础模型,凭借其强大的通用能力和泛化能力,为该问题提供了潜在的解决方案。然而,如何弥补不同数据域和任务域之间的鸿沟仍然是一个挑战。在本文中,作者介绍了一种名为“时空旅行”(TTP)的新方法,该方法将SAM基础模型的通用知识整合到变化检测任务中。该方法有效地解决了在通用知识转移中的领域偏移问题,以及大模型在表达多时相图像同质性和异质性特征时的挑战。在LEVIR-CD上取得的SOTA结果证明了TTP的有效性。
02
/引言/
随着对地观测技术的发展,遥感图像变化检测已经成为该领域研究的前沿和热点。其主要目标是分析多时相遥感产品中感兴趣的变化,这些变化通常表现为像素级的二元分类(变化/未变化)。遥感地面的动态属性不仅受自然因素的影响,也受人类活动的影响。精确感知这些变化对于土地覆盖的定量分析具有极其重要的意义,可以作为描绘宏观经济趋势、人类活动和气候变化的有力工具。
高分辨率遥感图像已经成为复杂变化检测的有力工具。然而,在复杂场景中执行稳健的变化检测仍然是一个艰巨的挑战。变化检测聚焦“非语义变化”中的“有效变化”,即,由大气条件、遥感器、配准等引起的非语义变化,以及与下游应用无关的语义变化都应该被忽略。这对开展精准的变化检测任务提出了相当大的挑战。深度学习技术在变化检测领域取得了显著的进步。例如,基于CNN的算法可以通过其强大的特征提取能力揭示变化区域的稳健特征,从而在各种复杂场景中取得了令人印象深刻的性能。最近,基于Transformer的方法进一步加速了这个领域的发展,Transformer可以捕捉整个图像中的长距离依赖关系,赋予模型全局感受野,为需要高级语义知识的任务(如变化检测)开辟了新的途径。尽管这些方法取得了显著的成功,但它们在复杂和不断变化的时空环境中的适应性仍然距离实际应用有相当大的距离。此外,随着模型规模的扩大,变化检测有限的标注数据也显著限制了这些模型的潜力。虽然自监督表示学习和模拟数据生成等取得了一些进展,但它们仍然无法完全覆盖由时空变化引起的遥感图像场景的多样性。也无法推动大参数模型在不同场景中的性能。
基础模型强大的通用性和适应性已经得到了证明。这些模型在大量数据上进行训练,从而获得了通用的知识和表示。视觉领域的基础模型,如CLIP和SAM,已经被研究人员广泛研究和利用。这些模型是大量通用知识的存储库,可以进行跨领域的转移和共享,能够大大减少特定任务标注数据的需求。然而,当前的视觉基础模型主要是为自然图像设计的,这些模型用于遥感图像变化检测任务时会产生领域差异。此外,大多数视觉基础模型擅长理解单个图像,在提取多个图像同质性和异质性特征的方面表现不佳,特别是当图像中发生显著变化时,而这种能力对于变化检测来说是至关重要的。
本文将视觉基础模型的通用知识融入到变化检测任务中。该方法克服了在知识转移过程中遇到的领域偏移问题,以及表达多时相图像的同质性和异质性特征的挑战。文中引入了一种名为“时空旅行”(TTP)的方法,该方法将时相信息无缝地集成到像素语义特征空间中。具体来说,TTP利用了SAM模型的通用分割知识,并将引入低秩微调参数到SAM主干中来缓解空间语义的领域偏移。此外,TTP提出了一个时间旅行激活门,允许时相特征渗透到像素语义空间,从而赋予基础模型理解双时相图像之间的同质性和异质性特征的能力。最后,文中设计了一个轻量高效的多层级变化预测头来解码密集的高级变化语义特征。该方法为开展准确高效的遥感图像变化检测铺平了道路。
本文的主要贡献总结如下:
1)作者通过将基础模型的通用潜在知识转移到变化检测任务,解决了注释数据不足的问题。在文章中,通过引入时间旅行像素(TTP)来弥补知识转移过程中的时空领域差距。
2)具体来说,作者引入了低秩微调以缓解空间语义的领域偏移,提出了一个时间旅行激活门以增强基础模型识别图像间相关性的能力,并设计了一个轻量高效的多层级预测头来解码基础模型中封装的密集语义信息。
3)作者在LEVIR-CD数据集上将提出的方法与各种先进的方法进行了比较。结果表明,该方法达到了最先进的性能,突显了其有效性和进一步应用的潜力。
03
/方法/
Overview
为了减轻变化检测的注释需求,本文利用了从基础模型转移过来的通用知识。作者利用SAM的通用分割能力来构建一个变化检测网络,即TTP。TTP主要由三个部分组成:基于低秩微调的基础模型主干;插入双时相图像特征间的时间旅行激活门;以及一个高效的多层级解码头。其结构如图1所示。
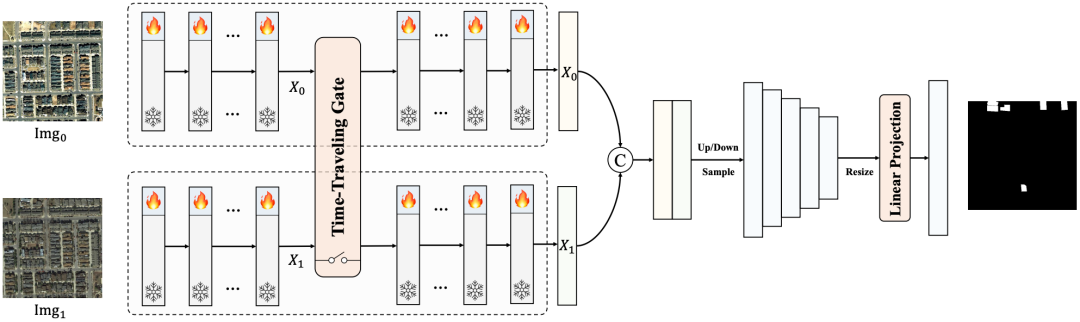
Efficient Fine-tuning of Foundation Model
SAM的主干由Transformer编码器组成,可以分为base版、large版和huge版,分别对应12层、24层和32层。为了提高计算效率,主干中的大部分Transformer层使用局部注意力,只有四层使用全局注意力。在本文中利用预训练的视觉主干,保持其参数处于冻结状态,以加速适应下游任务。为了弥补自然图像和遥感图像领域之间的差距,在多头注意力层中引入了低秩可训练参数,如下式所示,
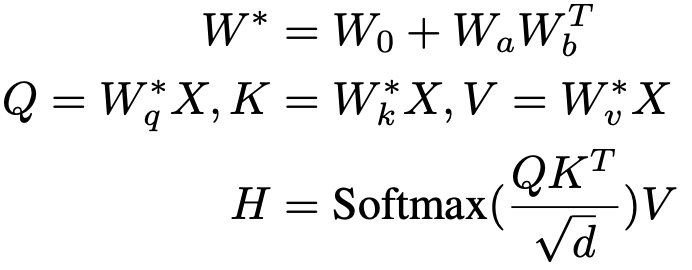
Time-traveling Activation Gate
当前的视觉基础模型擅长理解单个图像的内容,在提取图像间的特征时表现不佳。然而,在变化检测中,专注于双时相图像中的“有效差异”而忽略“无关差异”是至关重要的。为了解决这个问题,文中引入了时间旅行激活门,它促进了时相特征流入像素特征的语义空间。这使基础模型能够理解双时相图像中的变化,并关注“有效变化”。为了提高效率,只在主干中的全局注意力层后加入激活门,按照下面的公式来整合双时相信息,
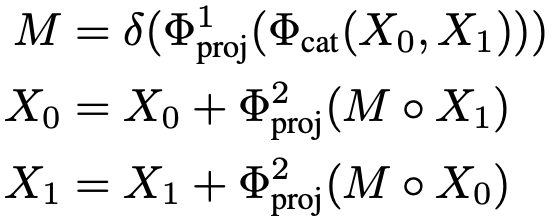
Multi-level Decoding Head
遥感图像的场景多样,地物的尺度存在显著变化。然而,基于ViT的视觉编码器通常只生成单一尺度的特征图。尽管这些图包含了高级的全局语义信息,但如果没有多层级的解码头,它们的性能优势可能难以显现。为了解决这个问题,文中设计了一个轻量高效的多层级变化预测头。该头通过转置卷积上采样和最大池化下采样来构建多级特征。然后使用一个轻量级的MLP映射层来输出最终的变化概率图,
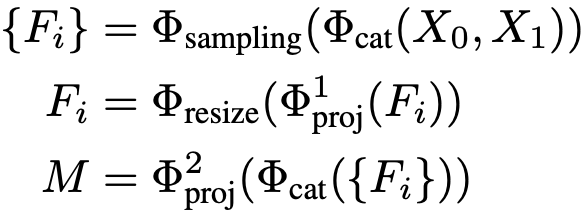
04
/实验/
作者在LEVIR-CD上进行了实验。为了评估性能,采用广泛认可交并比(IoU)、F1分数、精确度和召回率,以及总体准确度(OA)。
作者将提出的TTP与一系列最先进的变化检测方法进行了比较,包括FC-Siam-Di、DTCDSCN、STANet、SNUNet、BIT、ChangeFormer、ddpm-CD、WNet 和CSTSUNet。比较结果如表1所示,提出的TTP达到了最高的性能(92.1/85.6 F1/IoU),显著超过了当前的先进方法,如WNet(90.7/82.9)和CSTSUNet(90.7/83.0)。这表明了从基础模型转移通用知识可以增强变化检测,同时也验证了提出的转移方法的有效性。

如表1所示,当移除时间旅行门(ttg)和多级解码头(ml)时,性能会有所下降。此外,从基础模型中移除低秩微调参数会导致性能大幅下降。这些观察结果强调了本文提出的方法可以有效地弥补领域差距并增强时空理解。它们同时也验证了每个组件在变化检测任务中的有效性。
05
/结论/
本文通过将基础模型的通用知识融入变化检测任务,缓解了复杂时空遥感场景下模型难泛化的挑战。具体来说,作者引入了低秩微调来弥补自然图像和遥感图像之间的空间语义鸿沟,缓解了基础模型的局限性;提出了一个时间旅行激活门,使基础模型具有时相建模的能力。此外设计了一个多层级变化预测头来解码密集特征。在LEVIR-CD数据集上的实验结果表明了提出方法的有效性,该方法能在单卡4090上进行训练。
审核编辑:黄飞
-
做一个波形的峰值变化检测遇到的疑问求解答2024-08-19 0
-
微小电容变化检测2016-11-08 0
-
遥感数字图像的表示和统计描述2010-10-22 886
-
光线变化检测威廉希尔官方网站 图2008-12-24 3452
-
基于多模型表示的高分辨率遥感图像配准方法_项盛文2017-03-19 979
-
基于强监督部件模型的遥感图像目标检测2017-12-18 907
-
高分辨率遥感图像飞机目标检测2018-03-06 1167
-
机器学习在遥感高光谱图像中的应用2020-10-16 6023
-
针对遥感图像场景分类的多粒度特征蒸馏方法2021-03-11 838
-
一种新型的自适应神经网络遥感场景分类模型2021-03-16 603
-
基于神经网络的遥感图像飞机目标检测模型2021-03-30 1016
-
一种针对街景变化检测的神经网络模型2021-04-14 767
-
基于U-net分割的遥感图像配准方法2021-05-28 759
-
基于改进YOLOv2的遥感图像目标检测技术2021-06-16 816
-
基于EBPNN模型的遥感图像变化检测2021-06-22 595
全部0条评论

快来发表一下你的评论吧 !
