

自动驾驶数据集的生成模型之WoVoGen框架原理
汽车电子
描述
1. 写在前面
最近自动驾驶数据集的生成模型很火,主要包括NeRF和扩散模型两类。其中扩散模型的难点在于保持世界范围内的一致性和传感器间的一致性。今天笔者为大家推荐一篇复旦大学最新的开源方案WoVoGen,可以根据车辆控制输入生成街区视频,还可以做场景编辑。
下面一起来阅读一下这项工作~
2. 摘要
生成多摄像头的街景视频对于增加自动驾驶数据集至关重要,解决了对广泛而多样的数据的迫切需求。由于多样性的限制和处理光照条件的挑战,传统的基于渲染的方法越来越多的被基于扩散的方法所取代。然而,基于扩散的方法的一个重要挑战是确保生成的传感器数据同时保持世界范围内的一致性和传感器间的一致性。为了解决这些挑战,我们结合了一个额外的显式世界体素,并提出了世界体素感知多摄像头驱动场景生成器( Wovogen )。该系统专门用来利用4D世界体素作为视频生成的基础元素。我们的模型运行在两个不同的阶段:( i )基于车辆控制序列来设想未来的4D时间世界体素,( ii )生成多摄像机视频,由这个设想的4D时间世界体素和传感器互连性知识。4D世界体素的加入使得WoVoGen不仅可以根据车辆控制输入生成高质量的街景视频,而且可以方便场景编辑任务。
3. 效果展示
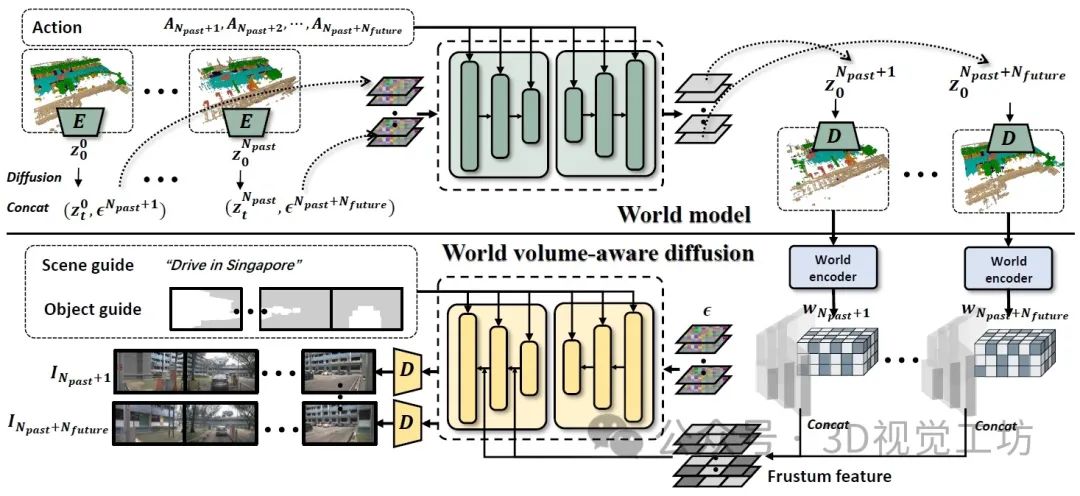
WoVoGen可以预测周围环境并产生合理的视觉反馈,以响应自车的驾驶操作。为了发挥快速发展的生成模型的能力,WoVoGen将结构化的交通信息编码到一个规则的网格框架中,即世界体素,并设计了一种新的基于潜在扩散的世界模型来自回归地执行世界体素预测。

WoVoGen可以很好得生成具有时间一致性的未来世界体素(前两行)。然后,利用世界模型输出的世界体素感知的2D图像特征,合成同时具有多相机一致性和时间一致性的驾驶视频(最下面两行)。

4. 具体原理是什么?
WoVoGen的总体框架。Top:世界模型分支。作者对AutoencoderKL进行微调,从头开始训练4D扩散模型,根据过去的世界体素和自车动作生成未来世界体素。Bottom:世界体素感知合成分支。利用生成的未来量作为输入,通过世界编码器得到Fw。随后的采样产生Fimg,然后进行聚合。该过程通过应用全景扩散来产生未来的视频来完成。
5. 和其他SOTA方法对比如何?
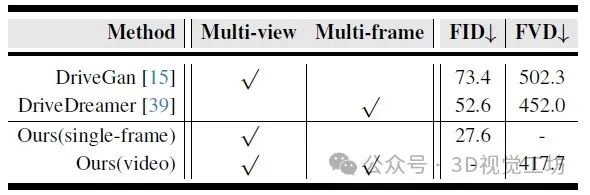
nuScenes验证集上图像/视频生成质量的定量比较。WoVoGen同时实现了多视角和多帧生成,在所有方法中FID和FVD得分最低。
6. 总结
这篇文章提出了WoVoGen,利用4D世界体素将时间和空间数据结合起来,在保证一致性的同时解决了从多传感器数据创建内容的复杂性。这种两阶段系统不仅可以基于车辆控制产生高质量的视频,还可以实现复杂的场景编辑。
审核编辑:黄飞
-
FPGA在自动驾驶领域有哪些应用?2024-07-29 0
-
FPGA在自动驾驶领域有哪些优势?2024-07-29 0
-
【话题】特斯拉首起自动驾驶致命车祸,自动驾驶的冬天来了?2016-07-05 0
-
自动驾驶真的会来吗?2016-07-21 0
-
自动驾驶的到来2017-06-08 0
-
AI/自动驾驶领域的巅峰会议—国际AI自动驾驶高峰william hill官网2017-09-13 0
-
神经网络解决方案让自动驾驶成为现实2017-12-21 0
-
【PYNQ-Z2试用体验】基于PYNQ的神经网络自动驾驶小车 - 项目规划2019-03-02 0
-
如何让自动驾驶更加安全?2019-05-13 0
-
自动驾驶汽车的处理能力怎么样?2019-08-07 0
-
自动驾驶系统要完成哪些计算机视觉任务?2020-07-30 0
-
联网安全接受度成自动驾驶的关键2020-08-26 0
-
nuTonomy发布自动驾驶数据集nuScenes2018-09-19 15286
-
语音数据集在自动驾驶中的应用与挑战2023-12-25 555
-
自动驾驶领域的数据集汇总2024-01-19 996
全部0条评论

快来发表一下你的评论吧 !
