

LiDAR4D:基于时空新颖的LiDAR视角合成框架
MEMS/传感技术
描述
0. 这篇文章干了啥?
目前大多数NeRF研究集中在图像的新视角合成上,而激光雷达则很少被探索。由于激光雷达点云的稀疏性、不连续性和遮挡性,动态场景同时结合了新的空间视角和时间视角合成,重建面临着相当大的挑战。与此同时,动态物体的大幅运动使得对齐和重建变得困难。传统的基于激光雷达的三维场景重建技术直接在世界坐标系中聚合多个稀疏点云帧,并将它们进一步转换为三角形网格等显式表面表示。随后,通过执行光线投射计算激光雷达束与网格表面的交点,从而渲染新视角的激光雷达点云。然而,对于复杂的大规模场景,高质量的表面重建是具有挑战性的,这可能导致重要的几何误差。此外,上述的显式重建方法局限于静态场景,并且难以准确地模拟实际激光雷达点的强度或光线掉落特性。
NeRF-LiDAR将图像和点云模态整合到激光雷达合成中,而诸如LiDAR-NeRF和NFL之类的仅激光雷达的方法探索了在没有RGB图像的情况下进行激光雷达重建和生成的可能性。大多数先前的方法直接将图像NVS流程应用于激光雷达点云。然而,激光雷达点云与2D图像本质上是不同的,这对当前的激光雷达NVS方法提出了挑战,以实现高质量的重建:
(1)先前的方法局限于静态场景,忽视了自动驾驶场景的动态性;
(2)激光雷达点云的庞大规模和高稀疏性对表示提出了更高的要求;
(3)需要进行强度和光线掉落特性建模以实现合成的真实感。
为了克服上述限制,这篇文章提出了LiDAR4D,揭示了提升当前激光雷达NVS流程的三个关键见解。为了解决动态物体,引入了从点云导出的几何约束,并聚合多帧动态特征以实现时间一致性。关于紧凑的大规模场景重建,设计了一个粗到细的混合表示,结合了多平面和网格特征,以重建平滑的几何和高频率的强度。此外,采用全局优化来保持区域间的模式以进行光线掉落概率的细化。因此,LiDAR4D能够在大规模动态场景下实现几何感知和时间一致的重建。
下面一起来阅读一下这项工作~
1. 论文信息
标题:LiDAR4D: Dynamic Neural Fields for Novel Space-time View LiDAR Synthesis
作者:Zehan Zheng, Fan Lu, Weiyi Xue, Guang Chen, Changjun Jiang
机构:同济大学
原文链接:https://arxiv.org/abs/2404.02742
代码链接:https://github.com/ispc-lab/LiDAR4D
2. 摘要
尽管神经辐射场(NeRFs)在图像新视角合成(NVS)方面取得了胜利,但LiDAR NVS仍然很大程度上未被探索。之前的LiDAR NVS方法采用了一种简单的从图像NVS方法到LiDAR的转换,同时忽略了LiDAR点云的动态特性和大规模重建问题。基于此,我们提出了LiDAR4D,一个用于新颖时空LiDAR视角合成的可微分LiDAR-only框架。考虑到稀疏性和大规模特性,我们设计了一个4D混合表示,结合多平面和网格特征,以粗到精的方式实现有效的重建。此外,我们引入了从点云中导出的几何约束以提高时间一致性。为了实现LiDAR点云的逼真合成,我们将射线丢失概率的全局优化纳入其中,以保留跨区域模式。对KITTI-360和NuScenes数据集的大量实验证明了我们的方法在完成几何感知和时间一致的动态重建方面的优越性。
3. 效果展示
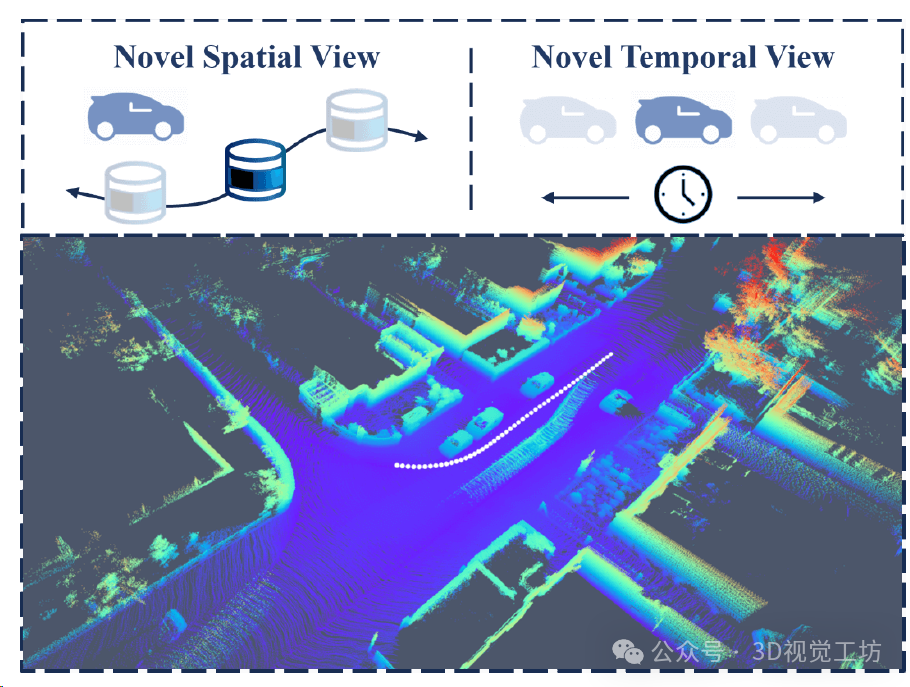
自动驾驶中LiDAR点云的动态场景。 大规模的车辆运动对动态重构和新颖的时空视图合成提出了重大挑战,白点表示自车的轨迹。
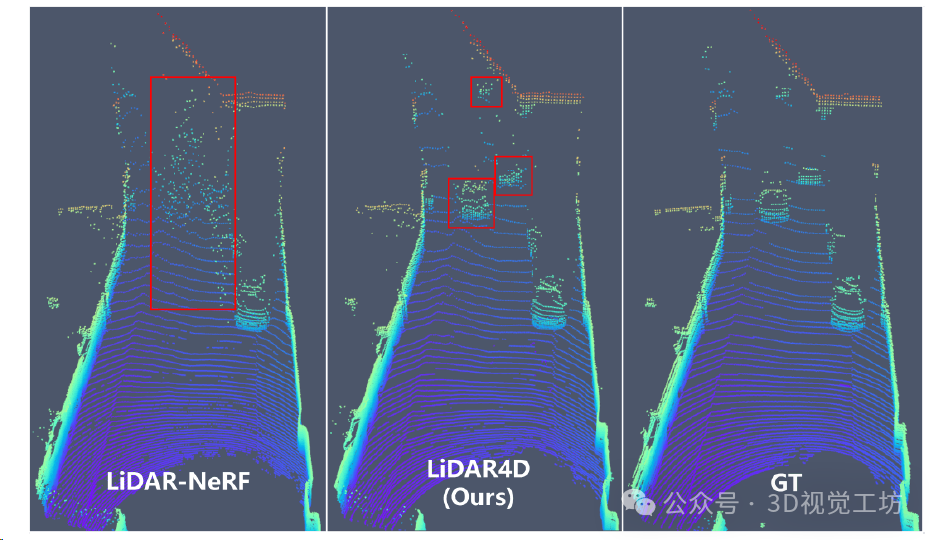
KITTI - 360数据集上定性新视角LiDAR点云合成结果。 LiDAR - NeRF无法重建动态车辆。相比之下,LiDAR4D为移动的汽车生成更精确的几何形状,即使在较远的稀疏点云中也是如此。
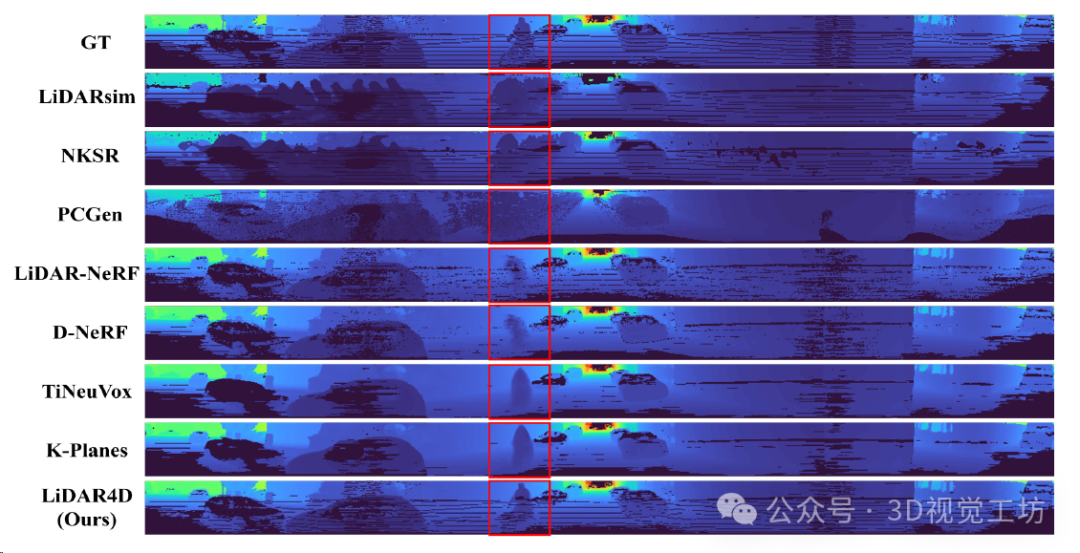
LiDAR深度重建与合成的定性比较。
4. 主要贡献
(1)提出了LiDAR4D,一个用于新颖时空激光雷达视角合成的可微激光雷达框架,它可以重建动态驾驶场景并端到端生成逼真的激光雷达点云。
(2)引入了从点云导出的4D混合神经表示和运动先验,以实现几何感知和时间一致的大规模场景重建。
(3)全面的实验证明了LiDAR4D在具有挑战性的动态场景重建和新视角合成方面的最先进性能。
5. 基本原理是啥?
LiDAR4D概述。 针对大规模自动驾驶场景,利用4D混合表示,将低分辨率的多平面特征和高分辨率的哈希网格特征相结合,实现了有效的重建。然后,通过flow MLP聚合的多级时空特征被输入到神经激光雷达场中进行密度、强度和射线掉落概率的预测。最后,通过可微分渲染合成新的时空视图LiDAR点云。进一步地,构造了由点云导出的几何约束以保证时间一致性,并构造了用于生成真实感的光线下降全局优化。
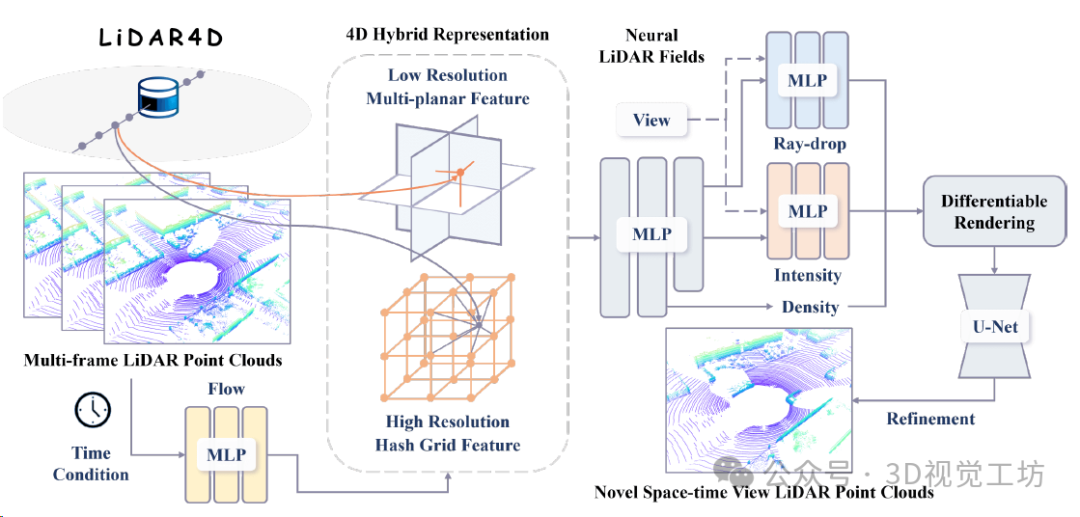
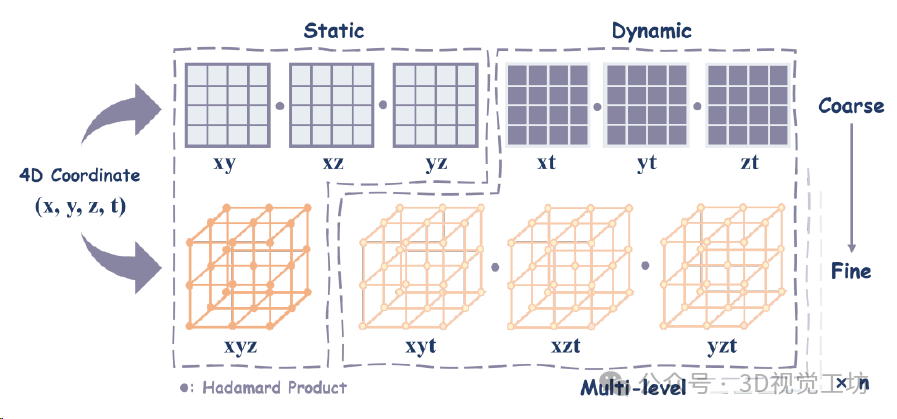
平面-网格混合表示的4D分解,利用流MLP可以进一步聚合动态特征。
6. 实验结果
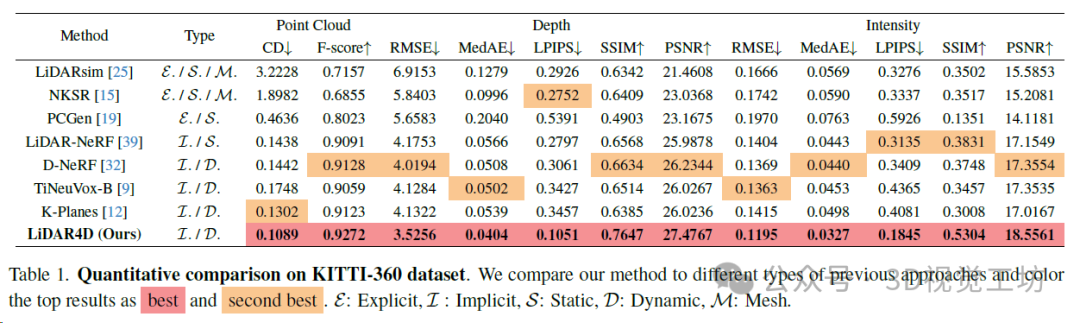
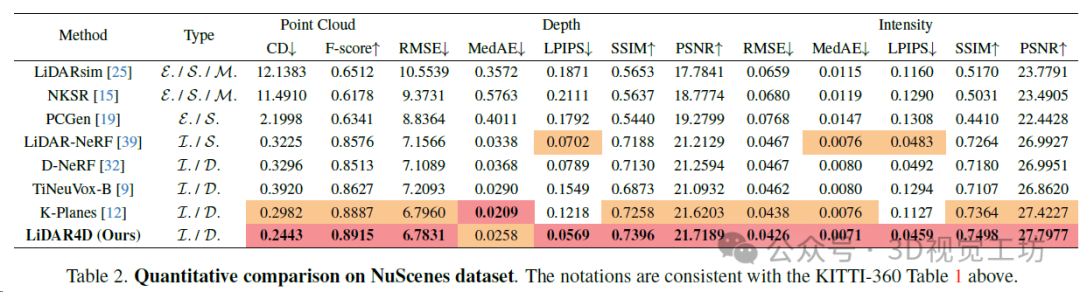
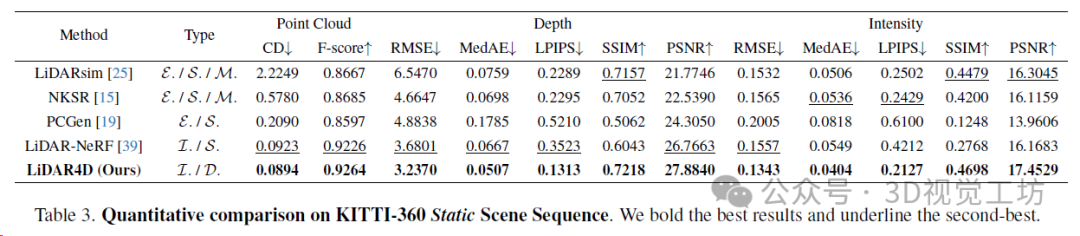
作者在KITTI-360和NuScenes自动驾驶数据集的多样化动态场景上评估了LiDAR4D。通过全面的实验,LiDAR4D显著优于先前最先进的基于NeRF的隐式方法和显式重建方法。与LiDAR-NeRF相比,在KITTI-360数据集和NuScenes数据集上分别实现了24.3%和24.2%的CD误差降低。在距离深度和强度的其他度量方面也存在类似的领先优势。
7. 限制性 & 总结
尽管 LiDAR4D 在大量实验中表现出色,但点云的远距离车辆运动和遮挡问题仍然是开放性问题。与静态对象相比,动态对象的重建仍存在显著差距。此外,前景和背景可能难以分离。此外,基于真实世界数据集,NVS 的定量评估仅限于自车轨迹,并且不允许对新颖的空间和时间视图合成进行解耦。
总体来说,这篇文章重新审视了现有 LiDAR NVS 方法的局限性,并提出了一个新的框架来解决三个主要挑战,即动态重建、大规模场景表征和逼真合成。LiDAR4D 在大量实验中证明了其优越性,实现了对大规模动态点云场景的几何感知和时间一致重建,并生成了更接近真实分布的新颖时空视图 LiDAR 点云。作者认为,未来更多的工作将集中于将 LiDAR 点云与神经辐射场相结合,并探索动态场景重建和合成的更多可能性。
对更多实验结果和文章细节感兴趣的读者,可以阅读一下论文原文~
审核编辑:黄飞
-
实现“三重视野” – LiDAR技术实现安全驾驶2020-08-20 0
-
固态LiDAR发展前景浅析2018-06-01 2864
-
即插即用的自动驾驶LiDAR感知算法盒子 RS-Box2017-12-15 0
-
LIDAR与RADAR在自动驾驶汽车中的比较2018-10-30 0
-
如何选择汽车LiDAR的激光器和光电探测器2018-11-08 0
-
如何利用高速ADC设计用于汽车的LIDAR系统?2021-05-17 0
-
请问LIDAR感知挑战有哪些?2021-06-17 0
-
固态LiDAR与机械LiDAR该如何选择2018-05-16 6400
-
苹果发布新版AR框架 可使用新的LiDAR扫描仪2020-03-25 2781
-
LiDAR如何构建3D点云?如何利用LiDAR提供深度信息2021-04-06 4362
-
LiDAR的作用是什么,iPhone12Pro如何使用LiDAR2020-11-03 13439
-
什么是LiDAR?LiDAR的工作原理2022-02-06 11112
-
LiDAR传感器原理 LiDAR在自动驾驶中的应用2022-11-23 1847
-
基于LiDAR的行人重识别的研究分析2023-12-11 769
-
Valeo为何坚守着LiDAR?2024-02-21 962
全部0条评论

快来发表一下你的评论吧 !
