

英伟达GPU垄断局面下,开源能否成为颠覆市场的关键力量?
处理器/DSP
描述
AMD Radeon最近在X平台发布了一则令人振奋的消息:他们宣布将在五月底开源Radeon GPU的微引擎调度器(MES)固件文档,并计划在之后发布源代码以供外部审查和反馈。随着社区对Radeon GPU上ROCm(Radeon Open Computer)平台的兴趣日增,AMD还建立了一个GitHub跟踪器,以便更好地捕捉社区的反馈并提供最新的更新。作为在GPU领域排名第二的重要玩家,AMD此举可以说是迈出GPU开源重要一步。
说到开源,近年来,RISC-V开源指令集架构在CPU领域已经取得了巨大的成功,其开放、灵活、可定制的特点吸引了越来越多的关注和应用。如今,RISC-V也开始在GPU领域崭露头角,一些项目和产品已经取得了初步的成果。RISC-V能否在GPU领域复制CPU领域的成功?
面对英伟达在GPU领域的垄断地位,开源能否成为破局之道?
芯片大厂推动GPU开源
开源是AMD AI软硬件生态系统的一大卖点,虽然ROCm软件自 2016 年推出以来一直是开源的,但是固件的开源也很重要,AMD GPU 上的MES固件AMD 单独开发的,不是开源的。
在此简单科普下固件的概念。固件是嵌入到硬件设备中的特定软件,它为硬件提供控制指令,使其能够执行预定的任务。虽然固件在技术上属于软件,但它直接与硬件关联并专为特定的硬件设计,通常存储在不易丢失数据的内存中,如ROM、EEPROM或闪存。固件作为硬件和更高级软件(如操作系统和应用程序)之间的桥梁,确保硬件能够按照预期的方式运行和与其他系统组件交互。与普通软件不同,固件不经常更改,更新通常是为了增加新功能或修复错误。
通常来说,固件一般不会轻易开源,固件中可能包含了企业的核心技术和商业机密,这些是公司竞争力的重要组成部分。开源固件可能会泄露这些关键信息,给竞争对手带来机会。
AMD做出固件开源这一决定的背后,有一个推动力量不可忽视,那就是人工智能初创公司Tiny Corp的坚持和倡导。Tiny Corp使用AMD的Radeon 7900 XTX GPU来构建他们的"TinyBox"——一款配备六块显卡的机器,专门用于处理AI工作负载。然而,在今年3月,TinyBox遇到了与MES固件相关的技术问题,Tiny Corp X 帐户(可能由 Hotz 主导)开始抱怨驱动程序和固件问题导致崩溃和挂起,这直接影响了其发布进程。因此,他们多次公开要求AMD开源其MES固件,以便能够修复有问题的错误。Tiny Corp还提出了改用 Nvidia或 Intel GPU的想法。
虽然最开始Lisa Su拒绝了MES固件开源这一提议,但如今看来,AMD最终还是妥协了。
如果AMD真的开源MES固件,这不仅可能巩固Tiny Corp与AMD的合作关系,还可能促使更多的企业和开发者转向AMD的平台。毕竟英伟达太贵了,按照Tiny Corp公布的价格,若采用AMD GPU,其TinyBox的售价为15,000美元,相比之下,采用Nvidia GPU的价格将高达25,000美元。这两款计算平台都将在今年6月份上市。此外,Tiny Corp 未来也可能推出 Arc A770 TinyBox,不过该公司表示目前只有原型机,目前没有推出的计划。
此举不仅可能增强AMD在AI领域的竞争力,还可能促使ROCm成为英伟达CUDA的有力竞争者,ROCm软件是AMD用于GPU计算的开源堆栈。众所周知,英伟达的CUDA软件虽然好用,但却是闭源的。
在软件方面,英特尔有开放的软件堆栈oneAPI。说到此,一项脱胎于英特尔oneAPI的新标准也意欲打破CUDA霸权!英特尔极擅于制定各种标准,关于此,可阅读《你不一定知道的英特尔》一文。2023年9月,Linux基金会宣布成立统一加速 (UXL,Unified Acceleration) 基金会。该联盟的主要目标是开发能够与各种人工智能芯片组配合使用的开源软件。Linux 基金会执行董事 Jim Zemlin表示:“统一加速基金会体现了协作和开源方法的力量。通过联合领先的技术公司并培育跨平台开发的生态系统,我们将释放新的可能性以数据为中心的解决方案的性能和生产力。”
UXL Group 的开发工作主要集中在英特尔OneAPI的软件工具包上。OneAPI 基于名为 SYCL 的早期框架(SYCL是一种Khronos开放标准),主要目标是简化跨多架构的开发过程(如CPU、GPU、FPGA、加速器),专注于简化应用程序的可移植性。目前英特尔通过多项附加功能扩展了该框架,其中最引人注目的是名为 SYCLomatic 的功能,它的目的是为 Nvidia CUDA 编写的软件转换为能够在其他公司的 AI 芯片上运行的 SYCL 代码。
UXL生态系统副总裁兼基金会指导委员会主席Rod Burns在一篇文章中的说法,在快速发展的异构计算时代下,UXL的推动成立,是产业发展的必然结果。目前,UXL的早期指导成员由高通、谷歌、英特尔、Arm、imagination、三星、VMvare(博通)、富士通八家国际芯片和软件公司组成。在很多分析人士看来,UXL的成立,是这些公司希望能够联合起来,打破CUDA霸权。
高通人工智能和机器学习主管 Vinesh Sukumar 此前在接受路透社采访时表示:“我们实际上是在向开发人员展示如何从 Nvidia 平台迁移出来。”从长远来看,UXL 最终旨在减少将 Nvidia 支持的应用程序迁移到竞争对手芯片所需的工作量和成本。这可能会给英伟达市场领先的显卡带来更多竞争。
从这个趋势可以看出,虽然 CUDA 在 GPU 编程领域确立了强有力的地位,但是开源和开放标准的推动是行业的一个明显趋势。长期而言,这种开放性有助于降低对单一供应商的依赖,促进更多竞争和合作,推动整个行业的发展。不过,打破现有的“霸权”并非易事,需要时间、资源以及持续地技术创新。
RISC-V开源之风吹向GPU
调研跟踪计算机图形行业35年之久的Jon Peddie Research (JPR) 表示,业界一直在寻求一种足够灵活且可扩展的开放标准GPU,以支持各种市场。
而近年来,开源硬件指令集架构RISC-V的崛起,为处理器技术带来了一股新风潮。这股开源之风现在正吹向图形处理单元(GPU)。不少厂商和学术界的研究者已经稍有动作。
1
IP厂商:GPU IP
X-Silicon Inc. (XSi) 是一家提供开放标准计算图形硅 IP 解决方案的初创公司,他们正在开发一个基于RISC-V矢量的统一图形计算引擎(C-GPU)革新GPU设计。传统的GPU架构是SIMD(单指令流多数据流),受制于主机 CPU、操作系统和图形服务,限制了创新并有助于保持现有企业对其市场的控制。X-Silicon使用的是MIMD(多指令流多数据流)架构,它可以同时在一个芯片中独立运行 CPU 和 GPU 代码,从而降低内存使用量并提高性能。
在该公司的多核设计中,多个 C-GPU 内核被平铺在一个芯片上,并通过片上快速合成器结构连接起来,该结构可将每个内核的输出动态聚合到一个公共缓冲区,即用于图形用例的帧缓冲区,或用于编解码器、视频特效处理和人工智能处理的流水线缓冲区。该公司声称,它还可以通过近内存计算、统一内存架构和其他新颖的硬件配置来加速计算,从而减少 GPU 固有的延迟。他们为此申请了 14 项专利。
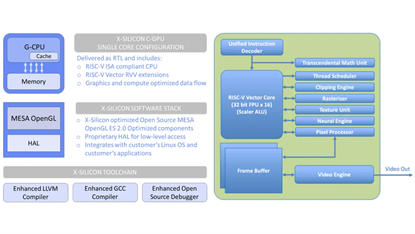
左:X-Silicon的单核概念;右:X-Silicon的单核架构(来源:X-Silicon)
IP巨头Imagination Technology早在前几年就推出了部分采用了RISC-V的GPU IP,该公司对外宣传,其所有GPU 都兼容RISC-V SoC。
另外一家嵌入式系统GPU IP提供商Think Silicon是 Applied Materials (应用材料)旗下公司,在做面向 MCU 市场的基于 RISC-V 的 GPGPU 解决方案,他们提供了在一个 IP 架构中执行 3D 图形和 AII 的独特组合。
2
科研院所:GPGPU开源项目
近年来,通用图形处理单元(GPGPU)在人工智能领域迅速得到大规模应用。GPGPU是高性能并行计算处理器芯片的一种,因为可编程性、易移植性,面对新兴应用具有更低的跟随成本,所以始终占据着高性能计算市场很大的份额。
一些科研院所开始探索开源GPGPU,其中较为代表的是佐治亚理工学院和清华大学。
佐治亚理工学院的开源RISC-V GPGPU Vortex是一个开源硬件和软件项目。目前,Vortex 已经发布了2.0版本, 它支持 OpenCL 并在 FPGA 上运行,如Altera Arria 10、Altera Stratix 10、Xilinx Alveo U50, U250, U280、Xilinx Versal VCK5000。Vortex 平台具有高度可定制性和可扩展性,拥有完整的开源编译器、驱动程序和运行时软件栈,可用于 GPU 架构研究。
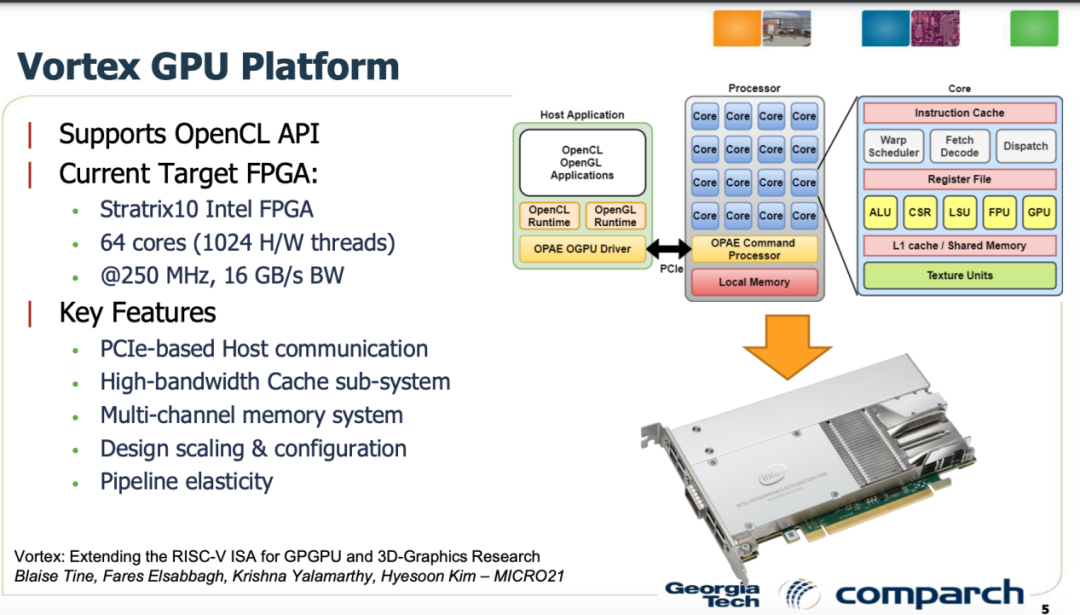
Vortex GPU平台(图源:Vortex)
看到了GPGPU在AI领域的大规模应用,又考虑到我国面临着高性能处理器进口受限、IP授权不可控性的现实挑战。在这样的背景下,清华大学集成威廉希尔官方网站 学院何虎团队希望可以开发一款开源的GPGPU,用于教学和科研目的。清华大学“乘影”GPGPU开源项目于2024年1月26日正式启动,这是一次对GPGPU产业自主创新的一次新的尝试。“乘影”是清华大学集成威廉希尔官方网站 学院何虎老师研发团队历经多年研发,采用RISC-V部分指令和自定义指令构建的通用GPU指令集架构。
众所周知,RISC-V是用于CPU的指令集,他们为何会选用RISC-V指令集来做GPGPU?据何虎告诉笔者:“在决定开发一款开源GPGPU时,选择合适的指令集架构便成为关键考虑因素。观察国际上的开源GPU项目,大多数采用了商业GPU的指令集架构,这导致其后续发展可能会受到私有指令集限制。考虑到开源的指令集架构能够让开源项目不受限制地发展。同时我们希望开发的是面向科学计算和人工智能计算的高性能GPGPU,因此采用了当时即将正式发布的RISC-V Vector扩展作为我们开源GPGPU的基础指令集。与RISC-V的标量指令相比,Vector指令携带的信息更为丰富,支持的计算种类也更多,这为GPGPU应用带来了独特的优势。”
何虎进一步指出,虽然Vector指令集和GPGPU在数据并行处理上有众多相似之处,但Vector基于SIMD架构,而GPGPU基于SIMT架构,因此需要对架构进行深度修改以在GPGPU上实现Vector指令。
据悉,目前该研发团队已经采用Chisel语言完成了完整的GPGPU微架构设计和实现,同时还实现了OpenCL编译器,功能和周期软件仿真器,POCL,驱动软件等整套工具链软件。通过了大部分OpenCL 2.0 CTS测试集的验证。
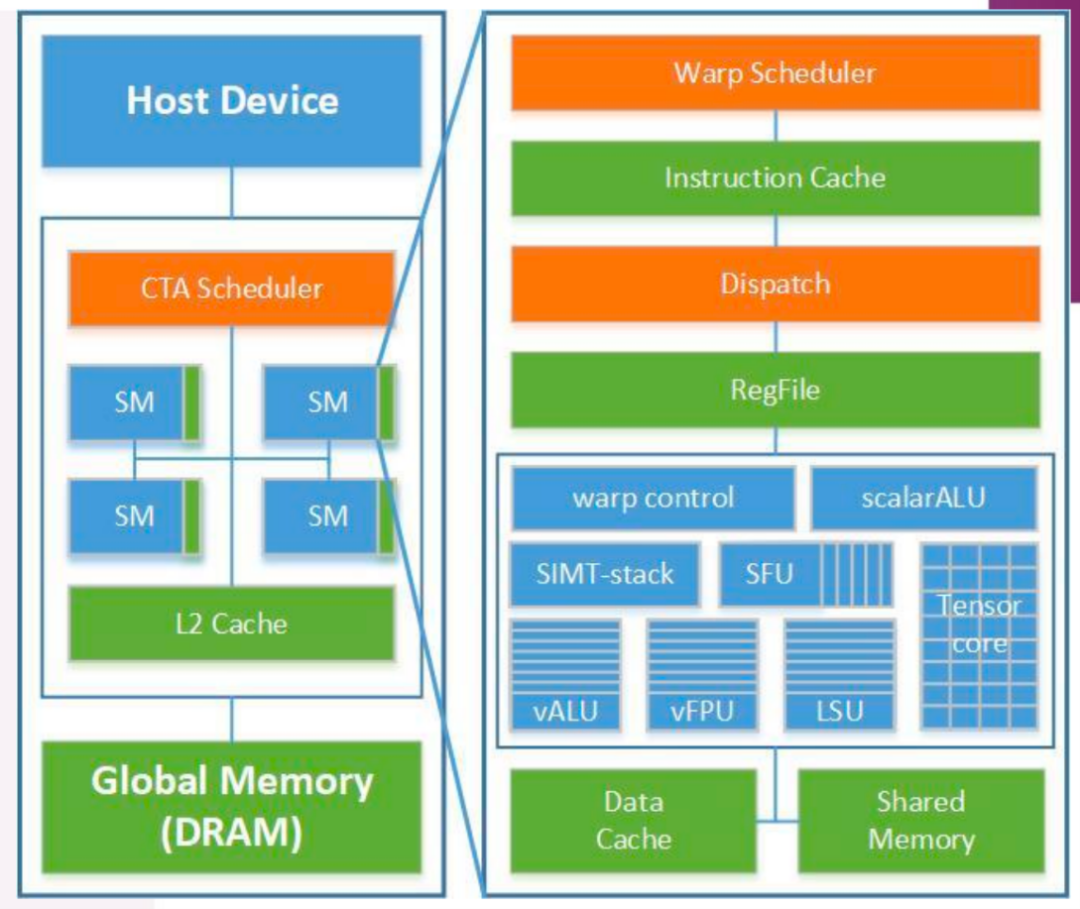
“乘影” GPGPU微架构
“乘影” 开源GPGPU指令集架构大部分指令来自于RISC-V指令集,充分利用RISC-V现有的指令集架构生态,使得市场主体很容易接受和参与到软件开发和芯片设计中,同时采用了GPGPU SIMT架构并设计了多条扩展指令。
“乘影”的乘影自定义指令集包括几个方面:
分支、同步、线程束控制:主要是为了在SIMT架构下运行程序所必需的控制指令。解决多线程锁步执行时,不同的线程要走不同分支的问题。还有核函数结束指令。
寄存器/立即数扩展:主要是是为了解决RISC-V指令集寄存器编码空间和立即数位宽不足的问题。扩展以后的指令集可以支持64个标量寄存器,256个向量寄存器,11位立即数。与主流GPGPU相同。
寄存器对拼接:是为了解决32位寄存器处理64位地址和数据的问题。乘影没有简单的采用RV64扩展寄存器位宽的方式来处理64位地址和数据。因为在GPGPU应用中,64位数据使用非常稀少,64位寄存器将对硬件设计带来浪费。乘影用两个相邻32位寄存器构成64位寄存器的方式来解决这个问题。
自定义访存指令:实现OpenCL定义的访存操作。
张量计算和指数函数:支持Transformer类型的神经网加速设计的
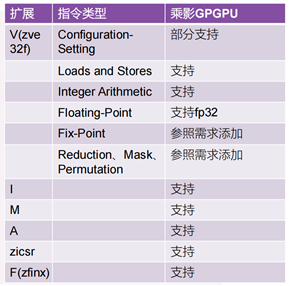
“乘影”GPGPU指令集
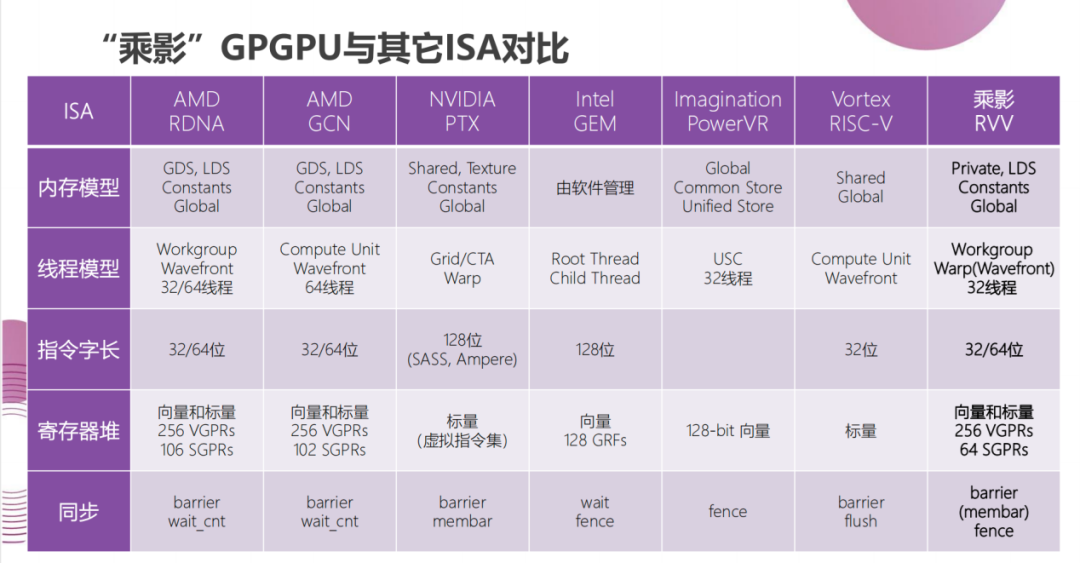
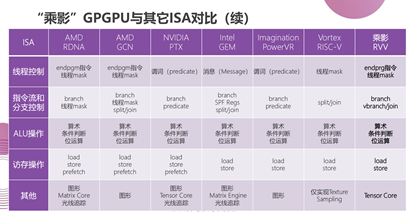
何虎告诉笔者,做开源GPGPU的目的有这么几点:一是推动形成GPGPU指令集架构标准。形成统一软硬件生态。让企业不再重复造轮子,各自构建自己的体系。最终形成行业统一的技术标准和软硬件生态。GPGPU行业企业可以各自发挥所长,找到自己的价值。二是利用开源社区探索先进的GPGPU威廉希尔官方网站 ,避免专利陷阱和技术壁垒。让企业可以放心在开源GPGPU基础上开发商用GPGPU。三是可以培养GPGPU产业所需的各类人才。目前乘影开源GPGPU已经被国内外高校老师应用于教学和科研。
3
芯片公司
今年2月24日,GPU芯片厂商芯瞳半导体发布公告称,其成功开源了一款基于RISC-V指令集的GPU处理器模型RVGPU,这款模型采用SIMT(单指令多线程)技术,能够为GPU设计带来新的灵活性和扩展性。现已成功实现对CUDA的兼容支持,包括CUDA编译器和运行时环境。该公司表示,将进一步强化对CUDA的支持,并积极探索RISC-V在GPU领域的更多可能性。
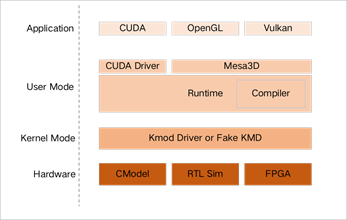
RVGPU软件栈(来源:芯瞳半导体)
为什么是RISC-V?
指令集架构是开源GPU发展的基石,在开源GPU生态系统中扮演着至关重要的角色。指令集处于软件程序和硬件威廉希尔官方网站 之间,起到接口的作用。在处理器芯片技术栈最重要的中间抽象层是指令集架构(ISA)。对于硬件开发者来说,ISA定义了硬件的功能和行为规范,允许在同一架构下开发出性能和成本各异的多样化产品;对软件开发者来说,ISA可以视为硬件产品的使用手册。
今天,英伟达以指令集为基石的高可编程性,也就是CUDA,成为了其在相关领域取得市场份额和话语权的关键因素。但是在当今的GPU行业中,大部分商业公司选择将指令集架构作为闭源技术标准。应用开发者只能藉由上层的图形应用程序编程接口,或者通用并行编程平台进行编程。商业公司自己负责指令集架构的设计与规划,并提供从微架构实现到应用程序编程接口之间的全套支持。不过英伟达和AMD都选择开放部分指令集架构标准,初衷主要是为了让应用开发者进行更深入的性能优化。
面对国际大厂的闭源策略,开源指令集RISC-V有望突破这一现状。何虎在“乘影”技术研讨会上指出,如果指令集架构变成开源技术标准,上下游开源标准之间分割出的软硬件技术栈有能力供养一批独立的软硬件解决方案公司。对于软件公司而言,建立统一的软件生态系统,减少上层应用和工具软件的开发和迁移成本;对硬件公司来说,可以让芯片公司专注于硬件设计,提高GPU芯片公司的资源投入效率,进而提高技术水平和竞争力。
通过建立大众参与的开放上下游生态,建设积极旺盛的人才培养环境,使部分国内GPU设计公司核心技术摆脱海外IP授权。这样才能为我国GPU产业长期发展奠定坚定基础,使其做大做强。
结语
开源GPU能否与英伟达一搏,尚需时间检验。但可以肯定的是,开源将为GPU市场带来更多竞争和活力。无论结果如何,开源GPU的探索和尝试本身就是科技进步和开源精神的一个重要体现。从长远来看,如果随着技术的进步和社区的壮大,相信开源GPU有潜力在某些特定领域或细分市场中取得一席之地。我们期待着开源GPU生态系统的不断完善,以及更多高质量的开源GPU产品出现。
审核编辑:黄飞
-
如何取替英伟达?如何颠覆英伟达?2023-07-10 1541
-
英伟达被立案调查 英伟达回应反垄断调查2024-12-10 192
-
233.国产GPU和国外竞争对手的差距在哪里?#国产gpu#英伟达小凡 2022-10-04
-
AI开发者福音!阿里云推出国内首个基于英伟达NGC的GPU优化容器2018-04-04 0
-
英伟达发布新一代 GPU 架构图灵和 GPU 系列 Quadro RTX2018-08-15 0
-
英伟达GPU惨遭专业矿机碾压,黄仁勋宣布砍掉加密货币业务!2018-08-24 0
-
英伟达DPU的过“芯”之处2022-03-29 0
-
英伟达自动驾驶软硬件一体化解决方案2018-05-02 8981
-
英伟达的GPU浅析:英伟达在自动驾驶和AI市场前途一片光明2018-10-11 1554
-
英伟达终于选择了开源GPU驱动2022-05-16 7491
-
国内GPU新势力:能否成为英伟达的“终结者”?2024-04-24 453
-
英伟达GPU新品规划与HBM市场展望2024-06-13 804
-
英伟达将全面转向开源GPU内核模块2024-07-19 563
-
市场监管总局启动英伟达反垄断调查2024-12-10 313
-
英伟达被中国立案调查!涉嫌违反反垄断法,最新回应!2024-12-11 213
全部0条评论

快来发表一下你的评论吧 !
