

中文大模型测评基准SuperCLUE:商汤日日新5.0,刷新国内最好成绩
描述
编者按:日前,中文大模型测评基准SuperCLUE发布最新榜单,对商汤科技全新升级「日日新SenseNova 5.0」大模型进行了全方位综合性测评,结果显示在SuperCLUE综合基准上,日日新 5.0表现不俗,以总分80.03分的优异成绩刷新国内最好成绩,并在中文综合成绩上超过GPT-4-Turbo-0125。
SuperCLUE是由创立于2019年的CLUE学术社区最新发布的中文通用大模型综合性评测基准,是被行业广泛认可的AI大模型权威评测榜单。以下评测报告转载自 SuperCLUE官方发布报道。
4月23日,商汤科技正式发布全新大模型日日新5.0(SenseChat V5),采用混合专家架构(MoE),参数量高达6000亿,支持200K的上下文窗口。据官方披露,SenseChat V5具备更强的知识、数学、推理及代码能力,综合性能全面对标GPT-4 Turbo。
那么,SenseChat V5在SuperCLUE中文基准上的表现如何?与国内外代表性大模型相比处于什么位置?在各项基础能力上如计算推理、长文本、代码生成、生成创作上会有怎样的表现?
SuperCLUE团队对SenseChat V5在SuperCLUE通用大模型综合性中文测评基准上,进行了全方位综合性测评。
测评环境
参考标准:SuperCLUE综合性测评标准
评测模型:SenseChat V5(官方于5月11日提供的内测API版本)
评测集:SuperCLUE综合性测评基准4月评测集,2194道多轮简答题,包括计算、逻辑推理、代码、长文本在内的基础十大任务。
模型GenerationConfig配置:
temperature=0.01
repetition_penalty=1.0
top_p=0.8
max_new_tokens=2048
stream=false
测评方法:
本次测评为自动化评测,具体评测方案可点击查阅SuperCLUE综合性测评标准。本次测评经过人工抽样校验。


先说结论
结论1:在SuperCLUE综合基准上,SenseChat V5表现不俗,以总分80.03分的优异成绩刷新国内最好成绩,并且在中文综合成绩上超过GPT-4-Turbo-0125有0.9分。
结论2:在本次测评中,理科任务上SenseChat V5取得国内最好成绩,较GPT-4-Turbo-0125低4.35分,还有一定提升空间;文科任务上SenseChat V5表现十分出色,以82.20分取得国内外最高分。
结论3:在本次测评中,SenseChat V5在各项能力上表现较为均衡,尤其在长文本、生成创作、角色扮演、安全能力、工具使用上处于全球领先位置,适用于智能体、内容创作、长程对话等应用场景。代码能力还有一定提升空间。
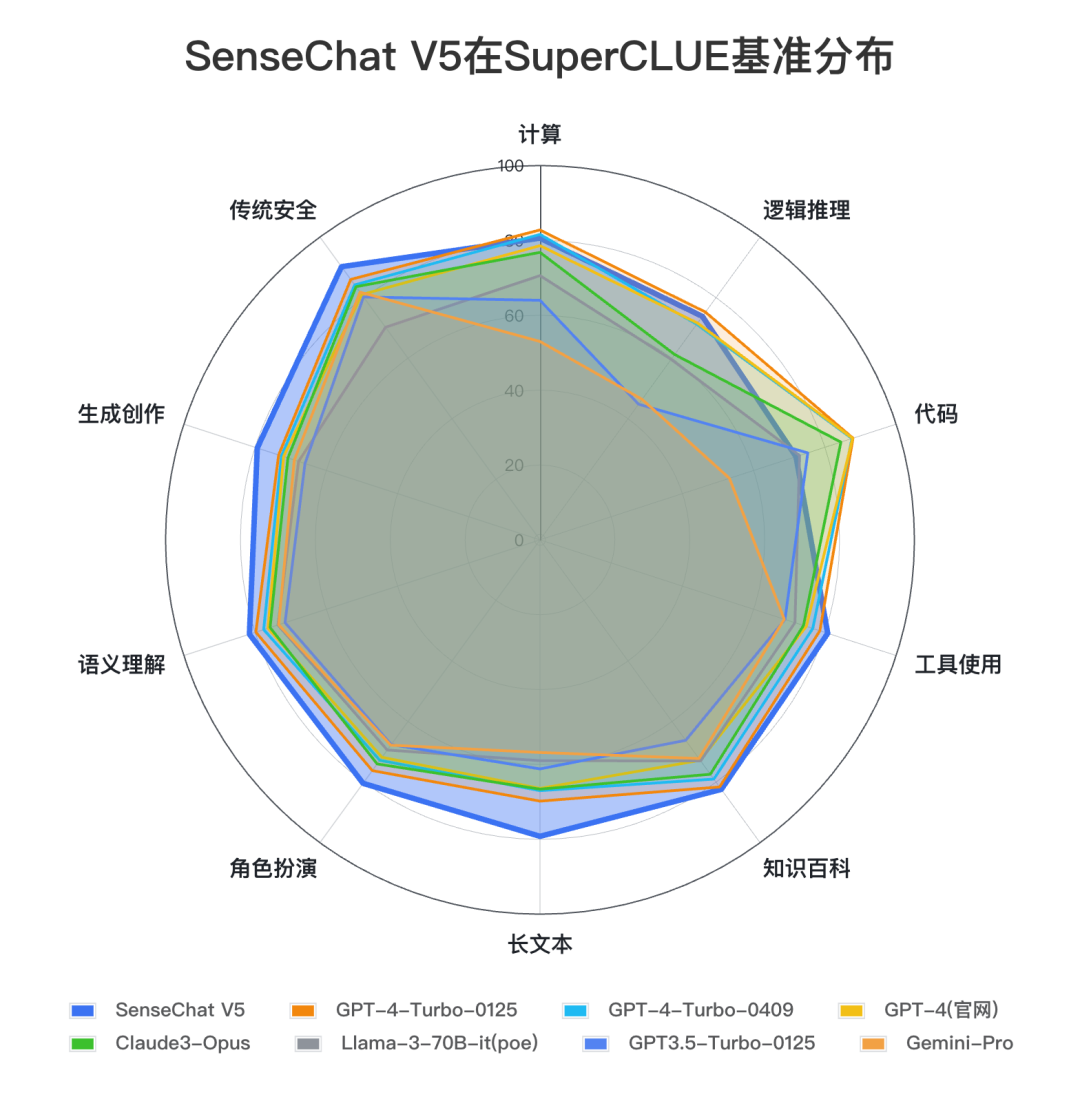
对比模型数据来源: SuperCLUE, 2024年4月30日
以下是我们从定量和定性两个角度对模型进行的测评分析。
测评分析
1 定量分析
在SuperCLUE测评中,SenseChat V5总体表现如下:
SenseChat V5总体表现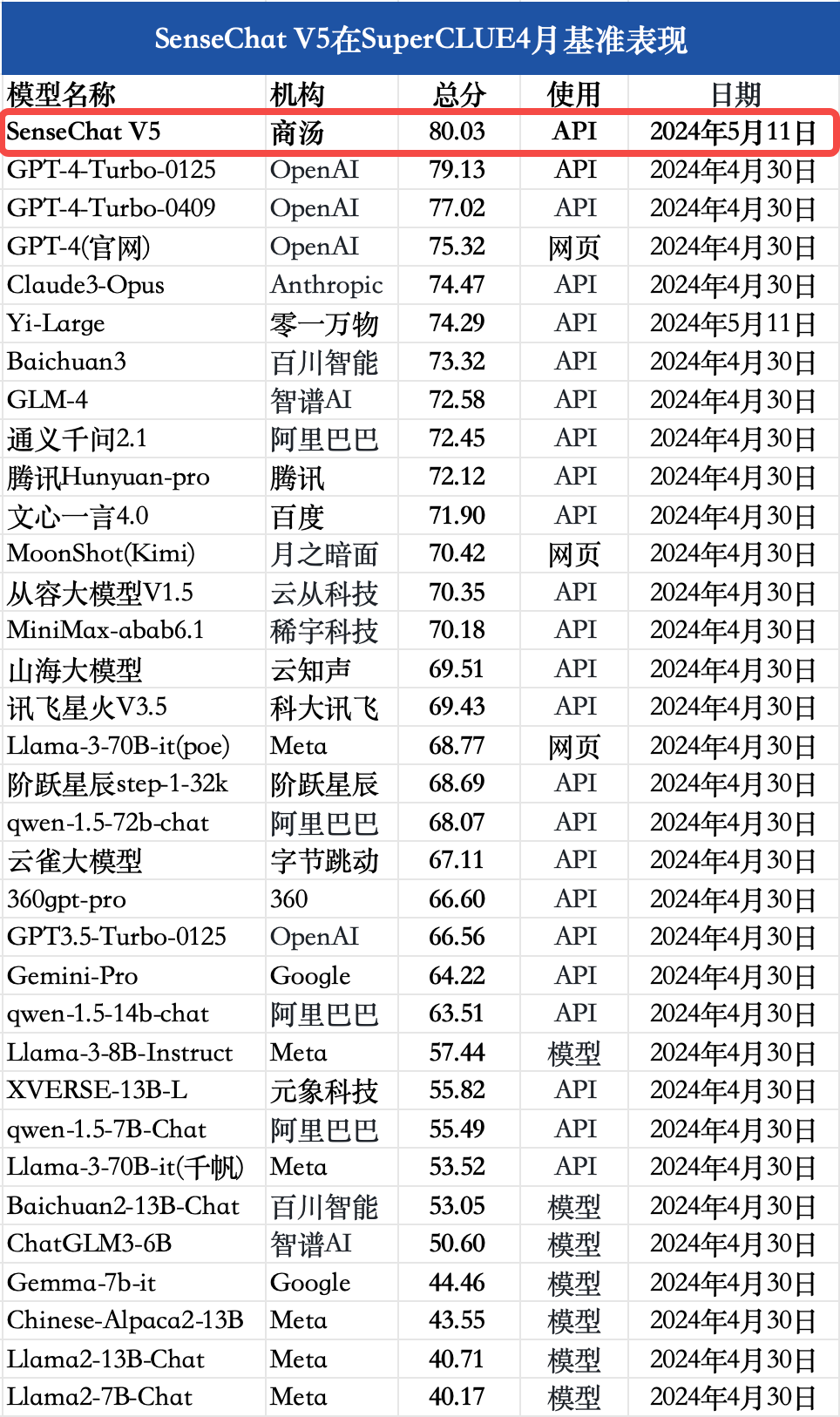
注:对比模型数据均来源于SuperCLUE,SenseChat V5和Yi-Large取自2024年5月11日,其余所有模型取自2024年4月30日。由于部分模型分数较为接近,为了减少问题波动对排名的影响,本次测评将相距0.25分区间的模型定义为并列,以上排序不代表实际排名。
在SuperCLUE通用综合测评基准上,SenseChat V5取得80.03分,表现出色,刷新国内大模型最好成绩。并且,SenseChat V5在中文综合能力上较GPT-4-Turbo-0125高0.9分。
SenseChat V5在理科任务上的表现
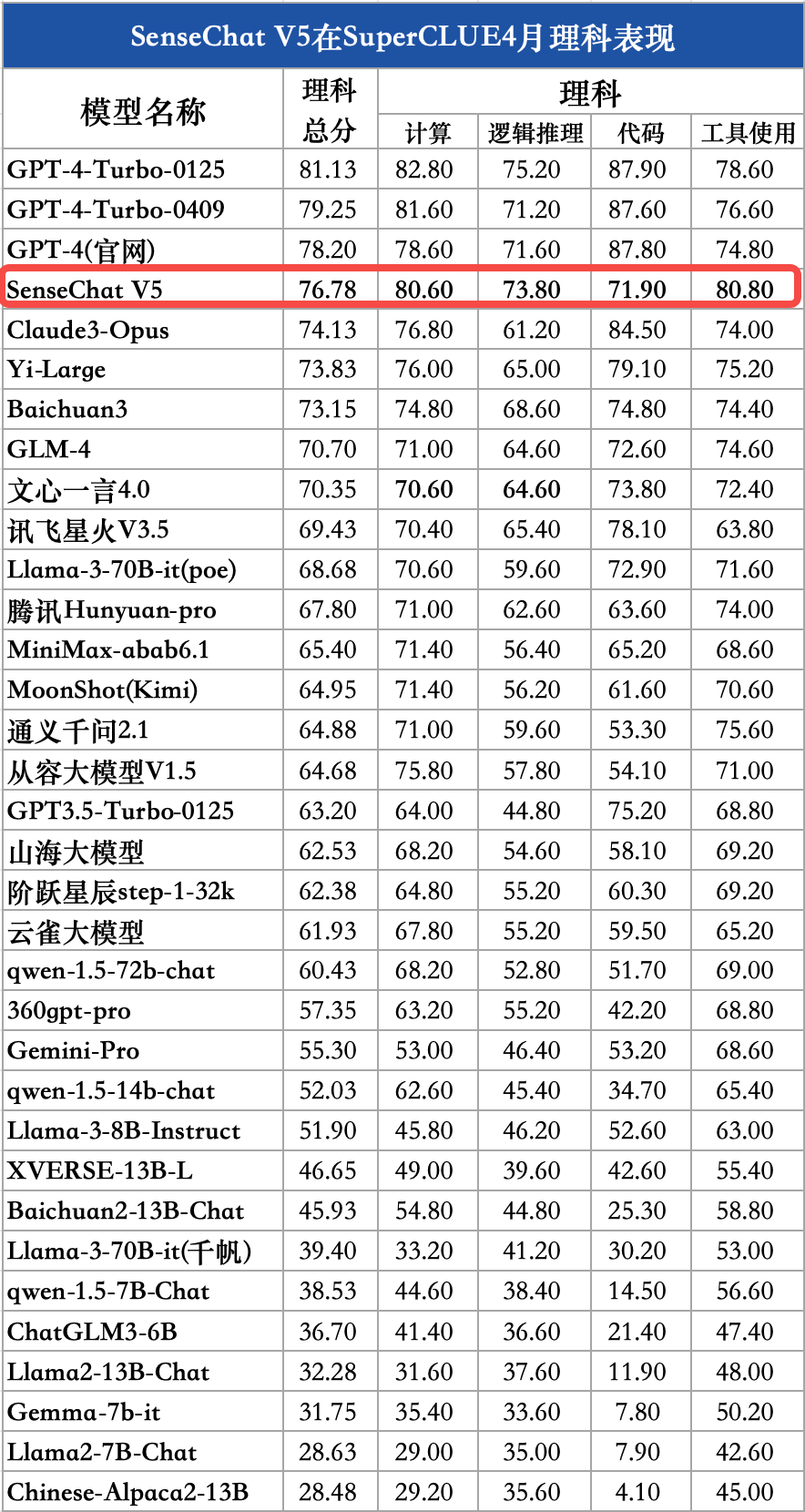
对比模型数据来源:SuperCLUE SenseChat V5在理科任务上表现不俗,取得76.78分,国内模型中排名第一,较GPT-4-Turbo-0125低4.35分,还有一定提升空间。其中,计算(80.6)、逻辑推理(73.8)、工具使用(80.8)均刷新国内最好成绩;在代码能力上还有一定优化空间。
SenseChat V5在文科任务上的表现
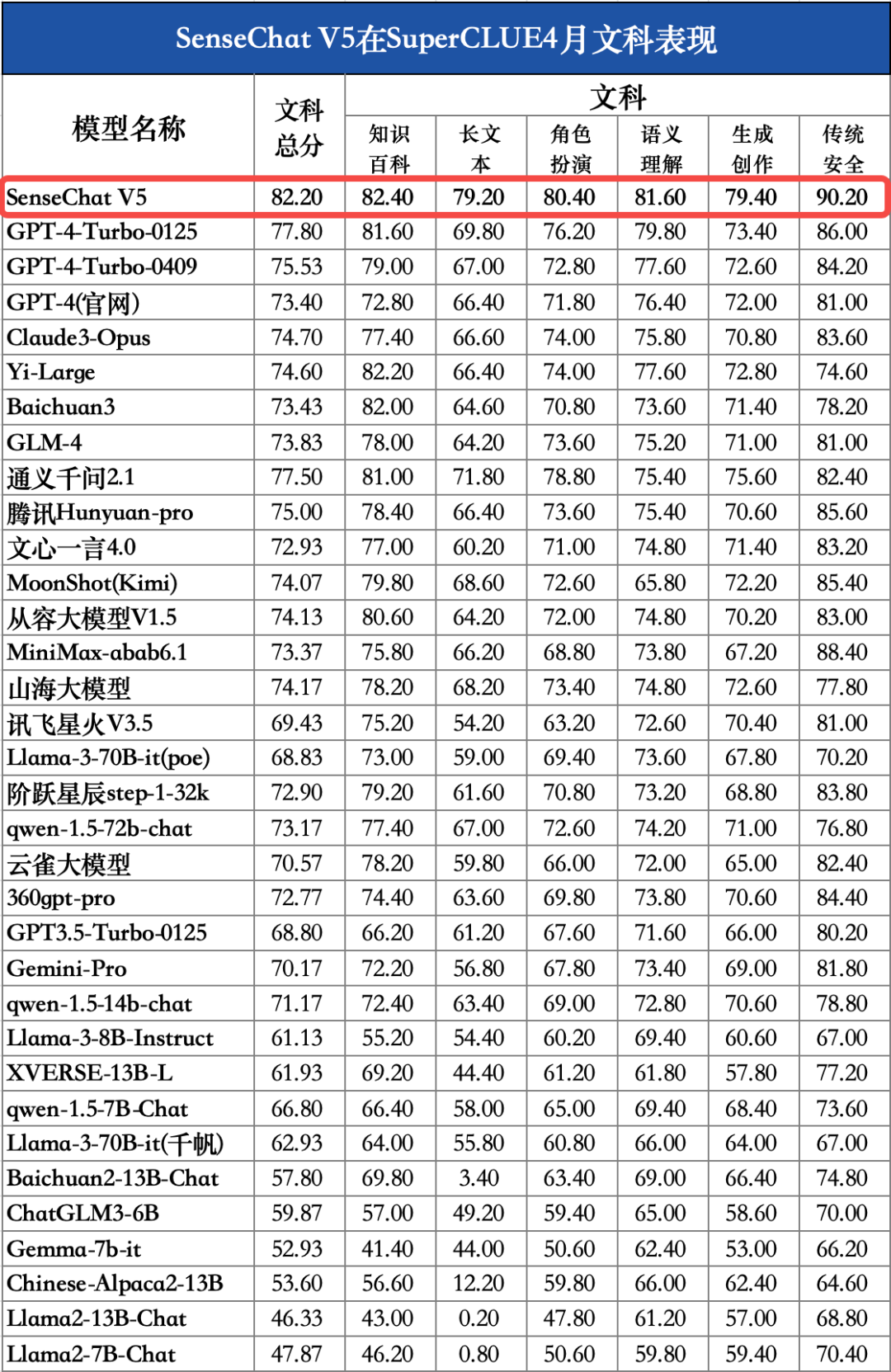
对比模型数据来源:SuperCLUE SenseChat V5在文科任务上表现出色,取得82.20的高分,国内外模型中排名第一,较GPT-4-Turbo-0125高4.40分。其中,知识百科(82.4)、长文本(79.2)、角色扮演(80.4)、语义理解(81.6)、生成创作(79.4)、传统安全(90.2)均刷新国内最好成绩;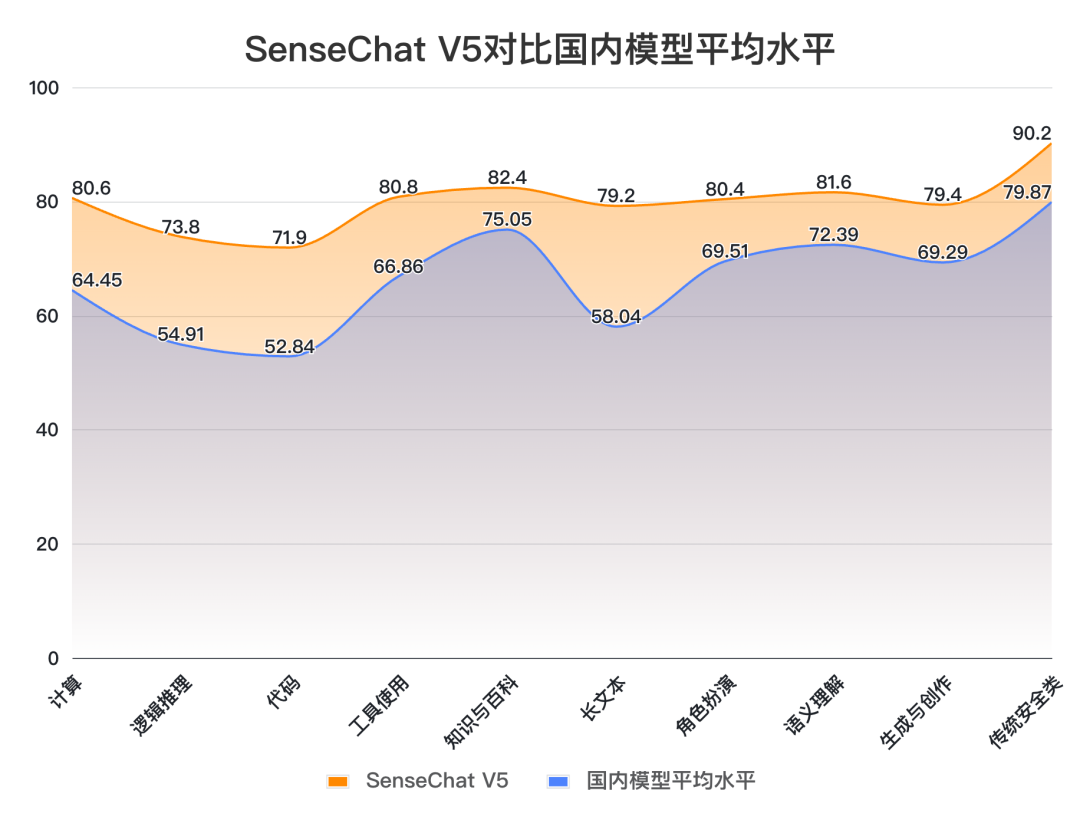
对比数据来源:SuperCLUE, 2024年4月30日 将SenseChat V5与国内大模型平均得分对比,我们可以发现,SenseChat V5在所有能力上均高于平均线,展现出较均衡的综合能力。尤其在计算(+16.15)、逻辑推理(+18.89)、代码(+19.06)、长文本(+21.16)能力上远高出平均线15分以上。
SenseChat V5与国外代表模型对比
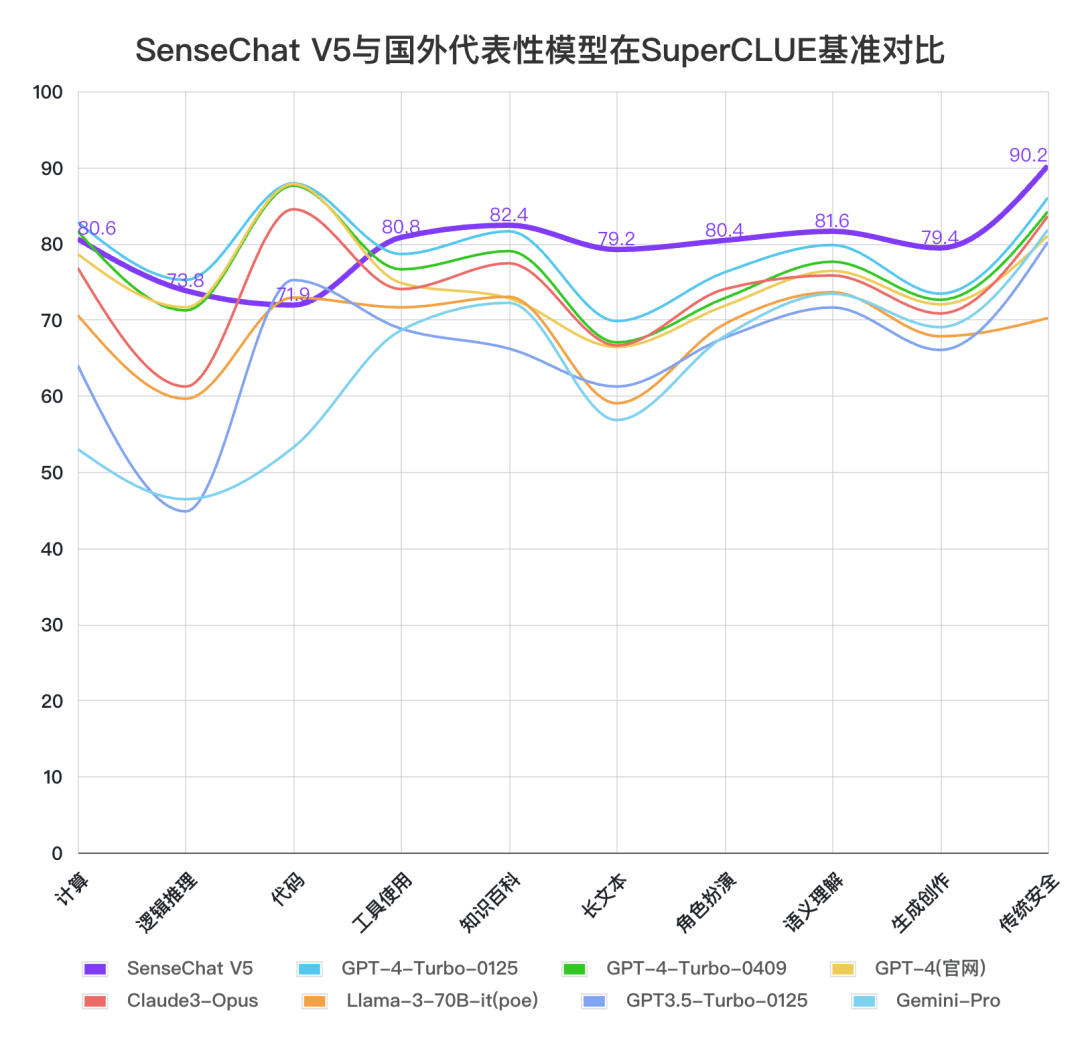
将SenseChat V5与国外代表大模型对比,SenseChat V5在文科类中文任务上好于国外大模型,尤其在长文本、生成创作能力较为领先。在理科如计算、逻辑推理、代码能力上与GPT-4-Turbo-0125还有一定提升空间。
小结:
从评测结果我们发现,SenseChat V5综合能力上表现不俗,在总分上刷新了国内外最好成绩,其中文科任务上有超过GPT-4 Turbo的表现,理科任务上刷新国内最好成绩,与GPT-4 Turbo还有一定距离。 2 定性分析
通过一些典型示例,对比定性分析SenseChat V5的特点。
示例1:长文本

示例2:生成创作

示例3:逻辑推理

模型技术特点
据官方介绍,SenseChat V5模型能力显著提升,其背后是训练数据的全面升级与训练方法的有效提升。
在数据方面,SenseChat V5采用了新一代数据生产管线,生产了10T tokens的高质量训练数据。通过多个模型进行数据的过滤和提炼,显著提升了预料质量和信息密度;基于精细聚类的均衡采样确保对世界知识覆盖的完整性。同时,SenseChat V5还大规模采用了思维型的合成数据(数千亿tokens量级),这对于模型在逻辑推理、数学和编程等方面的能力提升起到了关键作用。
SenseChat V5采用了自研的多阶段训练链路,包括三阶段预训练、双阶段SFT和在线RLHF。通过在每个阶段设定更加清晰聚焦的目标,实现更敏捷的调优,也避免了不同目标之间的相互干扰。其中在预训练阶段,分阶段培养模型的基础语言和知识能力、长文建模能力、以及复杂逻辑推理能力(规模化采用合成数据);在 SFT 阶段,把任务指令遵循和对话体验优化分解到双阶段进行;在 RLHF 阶段,采用统一的多维度奖励模型和动态系统提示词对多维度偏好进行打分,从而更好地实现模型在多个维度和人类期望对齐。
审核编辑:刘清
-
“商汤日日新”重磅升级点燃WAIC 2023,产业应用百花齐放2023-07-07 670
-
商汤日日新大模型全面升级,SenseCore可支持20个千亿参数量大模型同时训练2023-07-13 2928
-
商汤科技发布新版日日新·商量大语言模型2024-02-04 961
-
商汤日日新SensNova 4.0发布2024-02-05 914
-
商汤科技新升级大模型,对标GPT-4 Turbo2024-04-24 689
-
商汤科技发布日新5.0大模型,对标GPT-4 Turbo,预计2024年落地端侧2024-04-25 573
-
商汤科技发布“日日新SenseNova 5.0”大模型2024-05-07 560
-
商汤将发布日日新大模型5.0粤语版本2024-05-08 496
-
商汤科技即将推出日日新大模型5.0粤语版本2024-05-13 589
-
商汤发布日日新大模型5.0粤语版2024-05-30 627
-
商汤科技发布日日新5.5大模型体系2024-07-08 563
-
商汤“日日新”大模型全面赋能2024 WAIC2024-07-08 624
-
商汤日日新大模型中标上海电信订单2024-07-29 540
-
商汤日日新·商量大模型位列国内大模型第一梯队2024-11-08 321
-
商汤日日新多模态大模型权威评测第一2024-12-20 170
全部0条评论

快来发表一下你的评论吧 !
