

革命性的图形分析: NVIDIA cuGraph 加速的下一代架构
描述
在我们的 先前的图分析探索 中,我们使用 NVIDIA cuGraph 揭示了 GPU-CPU 融合的变革力量。基于这些见解,我们现在引入了一种革命性的新架构,它重新定义了图处理的边界。
图形处理的发展
在我们早期涉足图形分析的过程中,我们在使用的架构方面面临着各种挑战。这种体系结构虽然有效,但也造成了阻碍设置和性能的障碍。
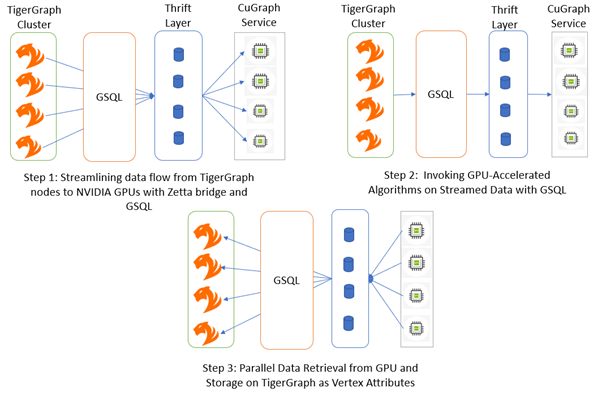
图 1.(以前的体系结构)使用 TigerGraph、cuGraph 和 GSQL 进行高性能图形分析的过程
以前体系结构的挑战
对磁盘的依赖关系:我们在 TigerGraph 和 cuGraph 之间使用基于磁盘的数据传输,这会对可扩展性和性能造成限制。组件之间的数据传输依赖于临时磁盘,从而引入延迟和潜在的性能瓶颈。
Python 依赖项:使用 Python 运行 cuGraph 将引入开销和复杂性,从而影响性能,特别是在图形处理等计算密集型任务中。
节俭层:节俭的通信会增加复杂性和开销,从而可能影响系统的可靠性。
对设置和性能的影响
这些依赖关系不仅使设置过程复杂化,而且对实现最佳性能也提出了挑战。对共享磁盘基础设施的需求,加上基于 Python 的服务和 Thrift 通信,造成了一个难以有效配置和扩展的系统。
在我们寻求加速图形分析的过程中,很明显,范式转变是必要的。进入下一代架构,这是一种革命性的方法,旨在克服前代架构的局限性,开启图形处理的新领域。让我们详细探讨一下这一突破性的体系结构。
介绍下一代架构
在我们寻求彻底改变图形分析的过程中,我们精心打造了代表图形处理范式转变的下一代架构。该体系结构完全构建在 C++中,利用尖端技术实现了前所未有的性能和可扩展性。
理解 TigerGraph 中的 GSQL 查询执行过程
在深入研究我们新体系结构的复杂性之前,了解 GSQL 查询传统上是如何在 TigerGraph 集群中执行的至关重要:
步骤 1:编译
GSQL 查询将经编译,然后转换为 C++ 代码。随后,编译这些代码,并将其与专有的 TigerGraph 库进行链接,以便执行准备。
第 2 步:执行
编译后,将使用图形处理引擎(GPE)在 TigerGraph 集群上执行查询。GPE 负责管理集群通信,并协调分布式环境中算法的执行。
升级下一代体系结构
在我们的下一代体系结构中,我们对编译和执行阶段进行了重大升级,利用 GPU 加速的力量并简化了处理流程:
步骤 1:增强加速的查询编译
我们通过将 cuGraph CUDA 库直接集成到 TigerGraph 中,实现了对 GPU 加速图形处理功能的无缝访问。基于 cuGraph 库,我们开发了 ZettaAccel,这是一个自定义的 C++ 库,它公开了在 GSQL 查询中可用作用户定义函数(UDF)的函数。现在,在查询编译过程中,GSQL 查询被编译并与 TigerGraph、CUDA cuGraph 和 ZettaAccel 库链接,从而解锁其核心的加速图处理能力。
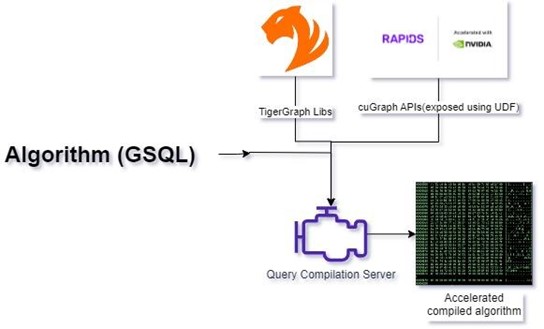
图 2:加速 GSQL 编译
步骤 2:通过 GPU 资源管理优化执行
在执行时,我们的体系结构使用 RAPID 生态系统库动态分配 GPU 资源,以确保可用硬件的最佳利用率。图形数据通过 ZettaAccel 库从 TigerGraph 高效地传输到 GPU 内存,其中它被无缝转换为可供处理的图形结构。然后,算法直接在 GPU 上执行,利用其并行处理能力获得无与伦比的性能提升。最后,生成的数据被无缝地传输回 CPU 和 TigerGraph,以进行进一步的分析和集成。
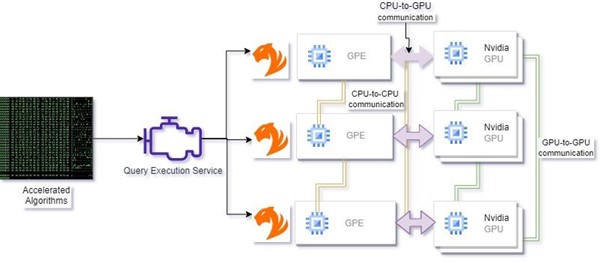
图 3。加速 GSQL 执行
下一代架构的优势
下一代架构代表了图形处理效率和可扩展性的巨大飞跃:
前所未有的性能:通过充分利用 GPU 加速和精简处理管道,我们的架构提供了无与伦比的性能提升,从而能够快速执行复杂的图形算法。
简化的设置:通过将 cuGraph 和 ZettaAccel 集成到 TigerGraph 中,我们简化了设置过程,消除了对复杂依赖关系的需求,并减少了配置开销。
可扩展性和灵活性:借助动态 GPU 资源管理和高效的数据传输机制,我们的架构可以轻松扩展,以处理大规模的图形数据集和多样化的处理工作负载。
利用加速的 GSQL 构造进行图形处理
为了利用加速的 GSQL 构造的力量进行高效的图形处理,用户可以遵循分为三个阶段的结构化方法:流式图形构造、算法执行和结果检索。
让我们以 pagerank 为例来看看所有三个阶段:-
1.流图构建:
在这个阶段,用户通过指定数据处理所需的关系和累加器来定义流图。
|
SELECT s FROM Start:s -(friend:f)- :t ACCUM int graph_obj=@@graph_per_server.get(server_id) udf_stream_edges(graph_obj,getvid(s),getvid(t),store_transposed); |
在这里,用户可以建立初始的图结构,并积累相关信息,如图对象和自定义流功能。这个udf_stream_edges 函数能够有效地处理边缘流并更新图形结构。
2.执行算法:
一旦构建了流图,用户就可以使用 GSQL 结构高效地执行他们想要的算法。
|
V = SELECT s FROM vertex_per_server:s ACCUM udf_prank_execute(@@graph_per_server.get(s.@server_id),@@vertices_per_server.get(s.@server_id)); |
在这个阶段,用户使用加速的 GSQL 构造来执行像 PageRank 这样的算法。这个udf_prank_execute函数可以有效地计算分布在服务器上的顶点的 PageRank 分数,从而优化算法执行时间。
3.检索结果:
在执行算法之后,用户从图中取回计算结果,用于进一步分析或可视化。
|
V = SELECT s FROM Start:s ACCUM s.@score=udf_pagerank_score(@@graph_per_server.get(server_id),getvid(s)); |
在这里,用户检索在算法执行期间计算的 PageRank 分数,并将其存储为顶点属性,用于后续分析或可视化。
通过遵循这三个阶段,用户可以有效地利用加速的 GSQL 构造来简化图形处理任务,优化算法执行,并高效地从图形数据中检索有价值的见解。
绩效基准和结果
图形算法性能比较
该基准测试在 2 节点集群上进行,每个节点都具有 4x NVIDIA A100 40GB GPU、AMD EPYC 7713 64 核处理器和 512GB RAM。
基准数据集
Graphalytics 是由链接数据基准委员会(LDBC)开发的综合基准套件,旨在评估图形数据库管理系统(GDBMS)和图形处理框架的性能。它提供了真实世界的数据集、不同的工作负载和一系列图形算法,以帮助研究人员和组织评估系统的效率和可扩展性。欲了解更多信息,请参阅 LDBC 图形分析基准。
| 图表 | 顶点 | 边缘 | TigerGraph 群集(秒) | cuGraph+TigerGraph(python)(秒) | cuGraph+TigerGraph(本机)(秒) |
| 图 22 | 239 万 | 6400 万 | 311.162 | 12.14(25 倍) | 6.91(45 倍) |
| 图 23 | 460 万 | 1.29 亿 | 617.82 | 14.44(42X) | 9.04(68 倍) |
| 图 24 | 887 万 | 260 米 | 1205.34 | 24.63(48 倍) | 14.69(82 倍) |
| 图表 25 | 1706 万 | 5.23 亿 | 2888.74 | 42.5(67 倍) | 21.09(137 倍) |
| 图 26 | 3280 万 | 10.5 亿 | 4842.4 | 73.84(65 倍) | 41.01(118 倍) |
表 1。与 cuGraph 加速(Python 和 Native)集成方法相比,基于 TigerGraph CPU 的解决方案
优化图形处理:在 TigerGraph 中集成 cuGraph 的成本分析
在追求增强图形处理能力的过程中,cuGraph 与 TigerGraph 的集成已被证明是游戏规则的改变者。通过在 TigerGraph 框架内利用 cuGraph 的 GPU 加速功能,我们不仅实现了显著的速度提高,还显著降低了总体成本。
机器信息:以下是机器的详细信息:
实例名称:m7a.32xlarge
节点总数:2 个
按需时薪:7.41888 美元
vCPU 数量:128
内存大小:512 GiB
实例名称:p4d.24xlarge
节点总数:1 个
按需时薪:$32.77
vCPU 数量:96
内存大小:1152 GiB
GPU 信息:
规格: NVIDIA A100 GPU
计数:8
内存:320 GB HBM2
| 图表 | TigerGraph 群集(秒) | cuGraph+TigerGraph(本机)(秒) | CPU 成本 | GPU 成本 | 收益(X) |
| 图 22 | 311.162 | 6.91(45 倍) | $1.28 | $0.06 | 20 |
| 图 23 | 617.82 | 9.04(68 倍) | $2.55 | $0.08 | 31 |
| 图 24 | 1205.34 | 14.69(82 倍) | $4.97 | $0.13 | 37 |
| 图表 25 | 2888.74 | 21.09(137 倍) | $11.91 | $0.19 | 62 |
| 图 26 | 4842.4 | 41.01(118 倍) | $19.96 | $0.37 | 53 |
表 2。与我们的基准机器相似的 AWS 机器的成本分析
这些结果表明,当将 cuGraph 与 TigerGraph 集成时,图形处理的速度显著提高了 100 倍。同时,成本分析显示,总体成本大幅降低了 50 倍,显示了这种集成的效率和成本效益。这种优化不仅确保了卓越的性能,而且为图形分析工作负载提供了更经济的解决方案。
总结
在对图形分析的全面探索中,我们开始了一段彻底改变处理和分析复杂图形数据方式的旅程。从传统架构的挑战到我们下一代解决方案的推出,本文涵盖了一系列主题,展示了先进技术和创新方法的变革力量。
图形处理技术的发展:
我们首先剖析了传统图形处理架构的局限性,强调了对共享磁盘基础设施、Python 和 Thrift 通信层的依赖性。这些挑战凸显了对图形分析新方法的需求,这种方法可以释放新的性能、可扩展性和效率水平。
介绍下一代架构:下一代架构的引入。
进入我们的下一代架构——图形处理中改变游戏规则的范式转变。我们的体系结构完全构建在 C++中,利用一系列尖端技术,包括 cuGraph、Raft、NCCL 和 ZettaAccel,将图形分析加速到前所未有的高度。
关键进展和创新:
通过我们的新体系结构,我们彻底改变了图形处理的编译和执行阶段。通过将 cuGraph 和 ZettaAccel 直接集成到 TigerGraph 中,我们简化了编译过程,消除了复杂的依赖关系,并解锁了 GPU 加速的图形处理的核心。我们的体系结构的动态 GPU 资源管理和精简的数据传输机制确保了各种图形处理任务的最佳性能和可扩展性。
前所未有的性能和可扩展性:无与伦比的计算能力和灵活的架构设计。
结果不言自明——我们的下一代架构提供了无与伦比的性能提升,实现了复杂图形算法的快速执行和处理大规模数据集的无缝可扩展性。通过利用 GPU 加速和创新 C++技术的力量,我们重新定义了图形分析的边界,使组织能够释放新的见解,推动不同领域的创新。
未来的发展方向和机遇:
当我们展望未来时,可能性是无限的。随着 GPU 技术、算法优化以及与新兴框架的集成的不断进步,我们的体系结构将继续发展,突破图形分析的极限。
开始使用
如果你渴望利用加速图形处理的力量,以下是你如何开始你的旅程:
检查您的要求:确保您的 TigerGraph 版本 3.9.X 和 NVIDIA GPU 配备了 RAPID 支持。这些先决条件对于释放加速图形处理的潜力至关重要。
表达您的兴趣:如果您对探索加速图形处理感兴趣,请联系 TigerGraph 或Zettabolt。无论您是经验丰富的数据科学家还是图形分析的新手,他们的团队都会随时为您提供帮助。
指导和支持:一旦您表达了兴趣,TigerGraph 或 Zettabolt 的专家将指导您完成最初的步骤,为您提供所有必要的信息,以启动您的加速图形处理之旅。从设置基础架构到微调性能,他们的支持确保了实施的顺利和成功。
审核编辑 黄宇
-
人工智能成下一代技术革命2019-01-07 4152
-
NVIDIA火热招聘GPU高性能计算架构师2017-09-01 0
-
为什么说射频前端的一体化设计决定下一代移动设备?2019-08-01 0
-
下一代SONET SDH设备2019-09-05 0
-
Nvidia发布首款Kepler架构GPU,提高图形处理性能2012-03-23 922
-
下一代网络核心技术概览2016-01-14 693
-
Imagination推出全新一代PowerVR Furian GPU架构 满足下一代消费类设备图形运算需求2017-03-10 886
-
在英特尔架构上启用下一代分析2020-05-31 2712
-
NVIDIA下一代7nm GPU效率比Turing高两倍2020-01-06 5145
-
RDNA 2架构全面改进,AMD展示革命性光线追踪技术2020-03-07 1813
-
NVIDIA下一代GPU曝光2020-12-22 2311
-
使用Memgraph和NVIDIA cuGraph算法运行大规模图形分析2022-10-10 1419
-
革命性的小芯片 GPU 设计时代开启2023-01-06 512
-
NVIDIA推动中国下一代车辆发展2023-08-01 895
-
使用NVIDIA Holoscan for Media构建下一代直播媒体应用2024-04-16 669
全部0条评论

快来发表一下你的评论吧 !
