

深度强化学习是什么?有什么优点?
人工智能
描述
深度强化学习(DRL)是人工智能研究领域的一个令人兴奋的领域,具有潜在的问题领域的适用性。有些人认为DRL是人工智能的一种途径,因为它通过探索和接收来自环境的反馈来反映人类的学习。最近DRL代理的成功打败了人类的视频游戏玩家,广为人知的围棋大师被人工智能AlphaGo击败,以及在模拟中学习行走的两足球员的演示,都让人们对这个领域产生了普遍的热情。
与监督机器学习不同,在强化学习中,研究人员通过让一个代理与环境交互来训练模型。当代理的行为产生期望的结果时,它得到正反馈。例如,代理人获得一个点数或赢得一场比赛的奖励。简单地说,研究人员加强了代理人的良好行为。
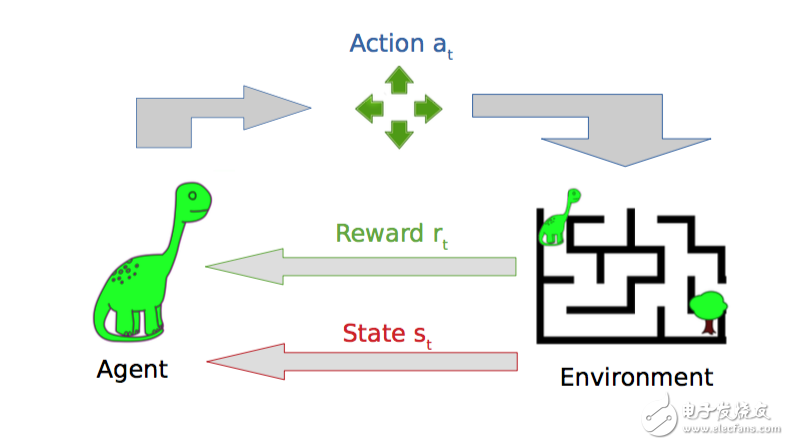
将DRL应用于非平凡问题的关键挑战之一是构建一个奖励功能,它鼓励人们期望的行为而不会产生不良的副作用。当你犯错时,会发生各种各样的坏事,包括欺骗行为。(想想奖励一个机器人服务员,在一些视觉上测量房间的清洁程度,只是教机器人打扫家具下面的污垢。)
值得注意的是,深度强化学习——“deep”指的是底层模型是一个深层的神经网络——仍然是一个相对较新的领域,强化学习从20世纪70年代或更早的时候就开始了,这取决于你如何计算。正如Andrej Karpathy在他2016年的博客文章中所指出的,关键的DRL研究,如AlphaGo论文和Atari Deep Q-Learning paper都是基于已经存在了一段时间的算法,但是用深度学习代替了其他方法来近似函数。他们对深度学习的使用,当然是在过去20多年里我们看到的廉价计算能力的爆发。
DRL的承诺,以及谷歌在2014年以5亿美元收购DeepMind的承诺,影响了一些希望利用这项技术的初创公司。本周,我采访了Bonsai的创始人Mark Hammondfor。该公司提供了一个开发平台,用于将深度强化学习应用于各种工业用例。我还与加州大学伯克利分校的Pieter Abbeelon讨论了这个话题。从那以后,他创立了“实体智能”公司,这是一家依然隐秘的初创公司,打算将VR和DRL应用于机器人技术。
由杨致远(Jerry Yang)、彼得?蒂尔(Peter Thiel)、肖恩?帕克(Sean Parker)以及其他知名投资者支持的Osaro,也希望在工业领域应用DRL。与此同时,人工智能正在寻找最佳的传统对冲基金,并将其应用于算法交易,而DeepVu正在应对管理复杂企业供应链的挑战。
由于对DRL的兴趣增加,我们也看到了新的开源工具包和用于培训DRL代理的环境。这些框架中的大多数本质上都是专用的仿真工具或接口。这些是目前AI中比较流行的工具:
OpenAI Gym
OpenAI gym是一个流行的开发和比较增强学习模型的工具箱。它的模拟器界面支持多种环境,包括经典的Atari游戏,以及像MuJoCo和darpa资助的Gazebo这样的机器人和物理模拟器。和其他DRL工具包一样,它提供了api来反馈意见和回报给代理。
DeepMind Lab
DeepMind Labis是一个基于Quake III第一人称射击游戏的3D学习环境,为学习代理提供导航和解谜任务。DeepMind最近添加了dmlab30,一个新级别的集合,并介绍了它的newImpaladistributed agent培训体系结构。
Psychlab
另一个DeepMind工具包,今年早些时候开放源代码,心理实验室扩展DeepMind实验室,以支持认知心理学实验,如搜索特定目标的一系列项目或检测一系列项目中的变化。然后,研究人员可以比较人类和人工智能在这些任务上的表现。
House3D
加州大学伯克利分校和Facebook人工智能研究人员之间的合作,在45000个模拟室内场景中模拟室内场景和家具布局。本文介绍的主要任务是“概念驱动的导航”,比如训练一个代理导航到一所房子的房间,只提供一个高级的描述符,比如“餐厅”。
Unity Machine Learning Agents
在AI和MLDanny Lange副总裁的领导下,游戏引擎开发者Unity正在努力将尖端的人工智能技术融入其平台。Unity Machine Learning Agents,于2017年9月发布,是一个开源Unity插件,可以在平台上运行游戏和模拟,作为训练智能代理的环境。
Ray
虽然这里列出的其他工具集中于DRL培训环境,但Ray更关注DRL的基础结构。Ray是在Berkeley RISELab开发的byIon Stoicaand他的团队,它是高效运行集群和大型多核机器上的Python代码的框架,具体目标是为增强学习提供一个低延迟的分布式执行框架。
所有这些工具和平台的出现将使DRL更易于开发人员和研究人员使用。但是,他们需要所有的帮助,因为深度强化学习在实践中是很有挑战性的。谷歌工程师亚历克斯·伊尔潘最近发表了一篇颇具煽动性的文章,题为“深度强化学习还不起作用”。Irpan引用了DRL所需要的大量数据,事实上,DRL的大多数方法都没有利用之前关于系统和环境的知识,以及前面提到的困难,在其他问题中也有一个有效的奖励功能。
我希望在未来的一段时间内,从研究和应用的角度来看,深度强化学习将继续成为人工智能领域的热门话题。它在处理复杂、多面和顺序的决策问题方面表现出了极大的希望,这使得它不仅对工业系统和游戏有用,而且对市场、广告、金融、教育、甚至数据科学本身也有很大的用处。
-
反向强化学习的思路2019-04-03 0
-
深度强化学习实战2021-01-10 0
-
将深度学习和强化学习相结合的深度强化学习DRL2018-06-29 28022
-
萨顿科普了强化学习、深度强化学习,并谈到了这项技术的潜力和发展方向2017-12-27 11261
-
如何深度强化学习 人工智能和深度学习的进阶2018-03-03 4214
-
深度强化学习是否已经到达尽头?2019-05-10 2534
-
深度强化学习的笔记资料免费下载2020-03-10 744
-
深度强化学习的概念和工作原理的详细资料说明2020-05-16 3489
-
深度强化学习到底是什么?它的工作原理是怎么样的2020-06-13 6065
-
模型化深度强化学习应用研究综述2021-04-12 907
-
基于深度强化学习仿真集成的压边力控制模型2021-05-27 729
-
基于深度强化学习的无人机控制律设计方法2021-06-23 986
-
《自动化学报》—多Agent深度强化学习综述2022-01-18 1621
-
ESP32上的深度强化学习2022-12-27 687
-
什么是深度强化学习?深度强化学习算法应用分析2023-07-01 1454
全部0条评论

快来发表一下你的评论吧 !
