

60秒内对 Linux 的性能诊断的方法解析
描述
60,000 毫秒内对 Linux 的性能诊断
当你为了解决一个性能问题登录到一台 Linux 服务器:在第一分钟你应该检查些什么?
在 Netflix,我们有一个巨大的 EC2 Linux 云,以及大量的性能分析工具来监控和诊断其性能。其中包括用于云监控的 Atlas,以及用于按需实例分析的 Vector。虽然这些工具可以帮助我们解决大多数问题,但我们有时仍需要登录到一个服务器实例,并运行一些标准 Linux 性能工具。
在这篇文章中,Netflix Performance Engineering 团队将会向你讲解在命令行中进行一次最佳的性能分析的前 60 秒要做的事,使用的是你应该可以得到的标准 Linux 工具。
前六十秒:总览
通过运行下面十个命令,你就能在六十秒内粗略地了解系统正在运行的进程及资源使用情况。通过查看这些命令输出的错误信息和资源饱和度(它们都很容易看懂),你可以接下来对资源进行优化。饱和是指某个资源的负载超出了其能够处理的限度。一旦出现饱和,它通常会在请求队列的长度或等待时间上暴露出来。
uptime
dmesg | tail
vmstat 1
mpstat -P ALL 1
pidstat 1
iostat -xz 1
free -m
sar -n DEV 1
sar -n TCP,ETCP 1
top
其中某些命令需要预先安装 sysstat 软件包。这些命令展示出来的信息能够帮你实施 USE 方法(一种用于定位性能瓶颈的方法),比如检查各种资源(如 CPU、内存、磁盘等)的使用率、饱和度和错误信息。另外在定位问题的过程中,你可以通过使用这些命令来排除某些导致问题的可能性,帮助你缩小检查范围,为下一步检查指明方向。
下面的章节将以在一个生产环境上执行这些命令作为例子,简单介绍这些命令。若想详细了解这些工具的使用方法,请参考它们的 man 文档。
1. uptime

这是一种用来快速查看系统平均负载的方法,它表明了系统中有多少要运行的任务(进程)。在 Linux 系统中,这些数字包含了需要在 CPU 中运行的进程以及正在等待 I/O(通常是磁盘 I/O)的进程。它仅仅是对系统负载的一个粗略展示,稍微看下即可。你还需要其他工具来进一步了解具体情况。
这三个数字展示的是一分钟、五分钟和十五分钟内系统的负载总量平均值按照指数比例压缩得到的结果。从中我们可以看到系统的负载是如何随时间变化的。比方你在检查一个问题,然后看到 1 分钟对应的值远小于 15 分钟的值,那么可能说明这个问题已经过去了,你没能及时观察到。
在上面这个例子中,系统负载在随着时间增加,因为最近一分钟的负载值超过了 30,而 15 分钟的平均负载则只有 19。这样显著的差距包含了很多含义,比方 CPU 负载。若要进一步确认的话,则要运行 vmstat 或 mpstat 命令,这两个命令请参考后面的第 3 和第 4 章节。
2. dmesg | tail

这条命令显式了最近的 10 条系统消息,如果它们存在的话。查找能够导致性能问题的错误。上面的例子包含了 oom-killer,以及 TCP 丢弃一个请求。
千万不要错过这一步!dmesg 命令永远值得一试。
3. vmstat 1
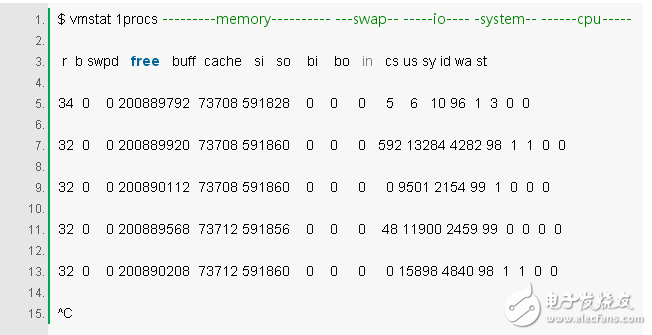
vmstat(8) 是虚拟内存统计的简称,其是一个常用工具(几十年前为了 BSD 所创建)。其在每行打印一条关键的服务器的统计摘要。
vmstat 命令指定一个参数 1 运行,来打印每一秒的统计摘要。(这个版本的 vmstat)输出的第一行的那些列,显式的是开机以来的平均值,而不是前一秒的值。现在,我们跳过第一行,除非你想要了解并记住每一列。
检查这些列:
r:CPU 中正在运行和等待运行的进程的数量。其提供了一个比平均负载更好的信号来确定 CPU 是否饱和,因为其不包含 I/O。解释:“r”的值大于了 CPU 的数量就表示已经饱和了。
free:以 kb 为单位显式的空闲内存。如果数字位数很多,说明你有足够的空闲内存。“free -m” 命令,是下面的第七个命令,其可以更好的说明空闲内存的状态。
si, so:Swap-ins 和 swap-outs。如果它们不是零,则代表你的内存不足了。
us, sy, id, wa, st:这些都是平均了所有 CPU 的 CPU 分解时间。它们分别是用户时间(user)、系统时间(内核)(system)、空闲(idle)、等待 I/O(wait)、以及占用时间(stolen)(被其他访客,或使用 Xen,访客自己独立的驱动域)。
CPU 分解时间将会通过用户时间加系统时间确认 CPU 是否为忙碌状态。等待 I/O 的时间一直不变则表明了一个磁盘瓶颈;这就是 CPU 的闲置,因为任务都阻塞在等待挂起磁盘 I/O 上了。你可以把等待 I/O 当成是 CPU 闲置的另一种形式,其给出了为什么 CPU 闲置的一个线索。
对于 I/O 处理来说,系统时间是很重要的。一个高于 20% 的平均系统时间,可以值得进一步的探讨:也许内核在处理 I/O 时效率太低了。
在上面的例子中,CPU 时间几乎完全花在了用户级,表明应用程序占用了太多 CPU 时间。而 CPU 的平均使用率也在 90% 以上。这不一定是一个问题;检查一下“r”列中的饱和度。
4. mpstat -P ALL 1
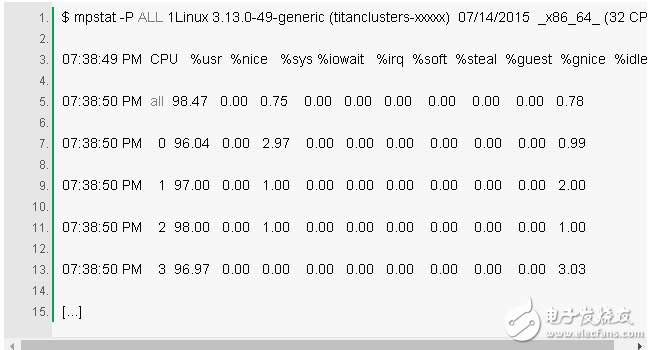
这个命令打印每个 CPU 的 CPU 分解时间,其可用于对一个不均衡的使用情况进行检查。一个单独 CPU 很忙碌则代表了正在运行一个单线程的应用程序。
5. pidstat 1
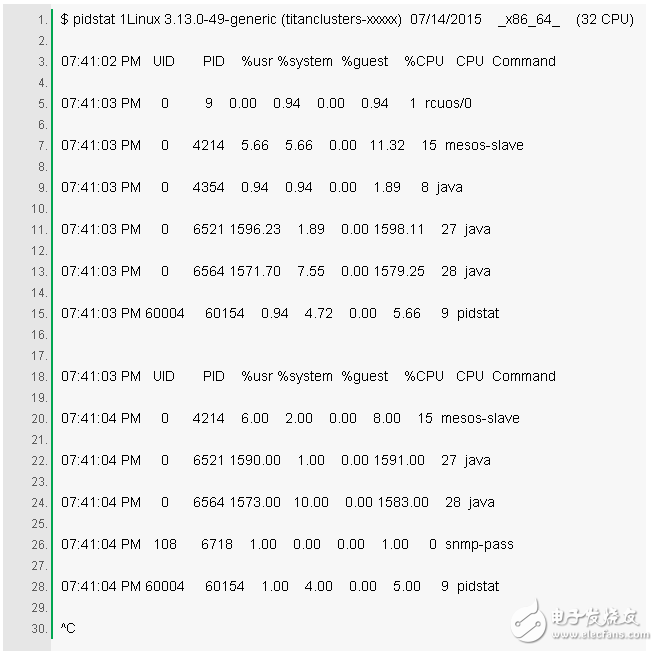
pidstat 命令有点像 top 命令对每个进程的统计摘要,但循环打印一个滚动的统计摘要来代替 top 的刷屏。其可用于实时查看,同时也可将你所看到的东西(复制粘贴)到你的调查记录中。
上面的例子表明两个 Java 进程正在消耗 CPU。%CPU 这列是所有 CPU 合计的;1591% 表示这个 Java 进程消耗了将近 16 个 CPU。
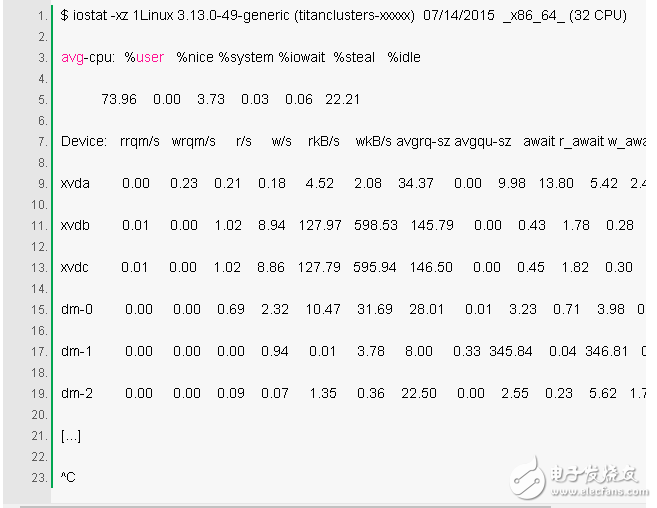
这是用于查看块设备(磁盘)情况的一个很棒的工具,无论是对工作负载还是性能表现来说。查看个列:
r/s, w/s, rkB/s, wkB/s:这些分别代表该设备每秒的读次数、写次数、读取 kb 数,和写入 kb 数。这些用于描述工作负载。性能问题可能仅仅是由于施加了过大的负载。
await:以毫秒为单位的 I/O 平均消耗时间。这是应用程序消耗的实际时间,因为它包括了排队时间和处理时间。比预期更大的平均时间可能意味着设备的饱和,或设备出了问题。
avgqu-sz:向设备发出的请求的平均数量。值大于 1 说明已经饱和了(虽说设备可以并行处理请求,尤其是由多个磁盘组成的虚拟设备。)
%util:设备利用率。这个值是一个显示出该设备在工作时每秒处于忙碌状态的百分比。若值大于 60%,通常表明性能不佳(可以从 await 中看出),虽然它取决于设备本身。值接近 100% 通常意味着已饱和。
如果该存储设备是一个面向很多后端磁盘的逻辑磁盘设备,则 100% 利用率可能只是意味着当前正在处理某些 I/O 占用,然而,后端磁盘可能远未饱和,并且可能能够处理更多的工作。
请记住,磁盘 I/O 性能较差不一定是程序的问题。许多技术通常是异步 I/O,使应用程序不会被阻塞并遭受延迟(例如,预读,以及写缓冲)。
7. free -m
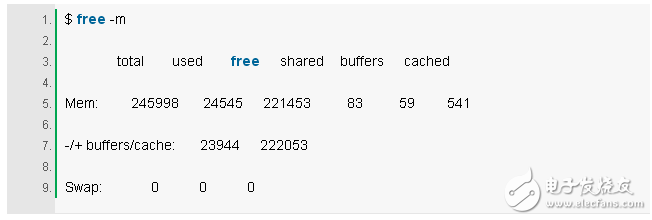
右边的两列显式:
buffers:用于块设备 I/O 的缓冲区缓存。
cached:用于文件系统的页面缓存。
我们只是想要检查这些不接近零的大小,其可能会导致更高磁盘 I/O(使用 iostat 确认),和更糟糕的性能。上面的例子看起来还不错,每一列均有很多 M 个大小。
比起第一行,-/+ buffers/cache 提供的内存使用量会更加准确些。Linux 会把暂时用不上的内存用作缓存,一旦应用需要的时候就立刻重新分配给它。所以部分被用作缓存的内存其实也算是空闲的内存。为了解释这一点, 甚至有人专门建了个网站: linuxatemyram。
如果你在 Linux 上安装了 ZFS,这一点会变得更加困惑,因为 ZFS 它自己的文件系统缓存不算入free -m。有时候发现系统已经没有多少空闲内存可用了,其实内存却都待在 ZFS 的缓存里。
8. sar -n DEV 1
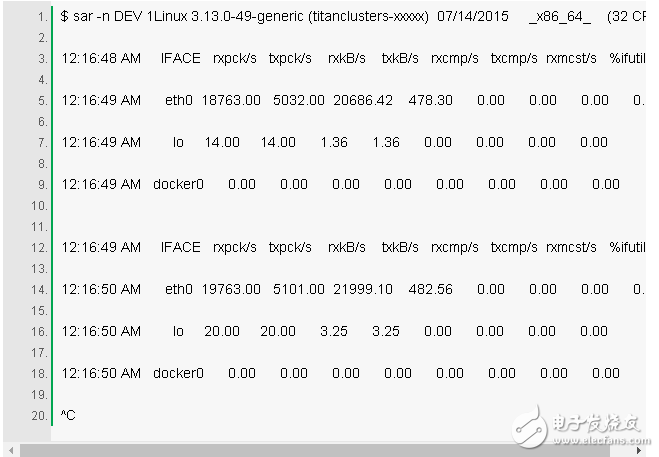
这个工具可以被用来检查网络接口的吞吐量:rxkB/s 和 txkB/s,以及是否达到限额。上面的例子中,eth0 接收的流量达到 22Mbytes/s,也即 176Mbits/sec(限额是 1Gbit/sec)
我们用的版本中还提供了 %ifutil 作为设备使用率(接收和发送的最大值)的指标。我们也可以用 Brendan 的 nicstat 工具计量这个值。一如 nicstat,sar 显示的这个值是很难精确取得的,在这个例子里面,它就没在正常的工作(0.00)。
9. sar -n TCP,ETCP 1
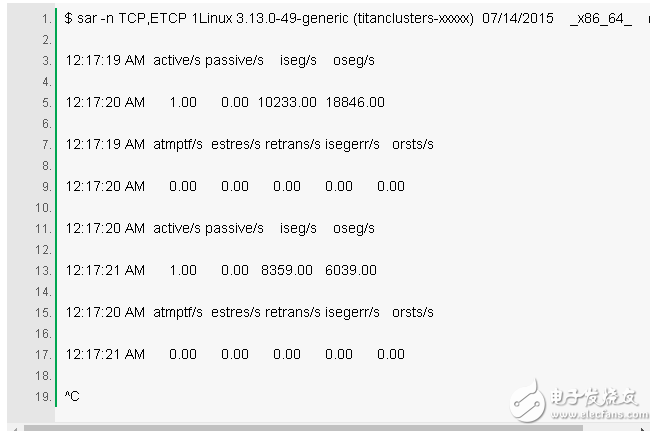
这是一些关键的 TCP 指标的汇总视图。这些包括:
active/s:每秒本地发起 TCP 连接数(例如,通过 connect())。
passive/s:每秒远程发起的 TCP 连接数(例如,通过 accept())。
retrans/s:每秒重传 TCP 次数。
active 和 passive 的连接数往往对于描述一个粗略衡量服务器负载是非常有用的:新接受的连接数(passive),下行连接数(active)。可以理解为 active 连接是对外的,而 passive 连接是对内的,虽然严格来说并不完全正确(例如,一个 localhost 到 localhost 的连接)。
重传是出现一个网络和服务器问题的一个征兆。其可能是由于一个不可靠的网络(例如,公网)造成的,或许也有可能是由于服务器过载并丢包。上面的例子显示了每秒只有一个新的 TCP 连接。
10. top

top 命令包含了很多我们之前已经检查过的指标。可以方便的执行它来查看相比于之前的命令输出的结果有很大不同,这表明负载是可变的。
top 的一个缺点是,很难看到数据随时间变动的趋势。vmstat 和 pidstat 提供的滚动输出会更清楚一些。如果你不以足够快的速度暂停输出(Ctrl-S 暂停,Ctrl-Q 继续),一些间歇性问题的线索也可能由于被清屏而丢失。
后续的分析
还有更多命令和方法可以用于更深入的分析。查看 Brendan 在 Velocity 2015 大会上的 Linux 性能工具教程,其中包含了超过 40 个命令,涵盖了可观测性、标杆管理、调优、静态性能调优、分析,和跟踪等方面。
-
怎样记录10秒内的数据2012-04-20 0
-
如何设计5秒内没声音发出警示的威廉希尔官方网站2015-10-14 0
-
怎么用已用时间函数设置程序在前三秒内亮布尔一,当三秒时间过后亮布尔二2017-12-18 0
-
为什么33521上的对数扫描会在超过20秒的时间内以对数方式扫描在最后一秒内进入停止频率2019-03-27 0
-
为什么我不能在PIC16F883第一秒内开始任何交流?2019-08-06 0
-
如何让键盘10秒内无操作进入休眠状态2022-01-13 0
-
CH573主从握手速度能做到1秒内完成吗?2022-08-05 0
-
夏普 PM2.5小型检测传感器 10秒内检测PM2.5浓度2018-04-20 5898
-
戴尔易安信携手中医行业将中医治疗数字化,在80秒内就可破解人体经络的密码2018-08-18 3907
-
02:采取什么措施来提高启动性能,在一秒内启动系统2019-01-10 2639
-
AI可识别语音情感模型 在1.2秒内判断你的愤怒2019-02-12 3324
-
替代Windows有望 国产UOS系统30秒内开机办公体验流畅2020-03-17 2171
-
UV LED 30秒内成功杀死99.9%的新型冠状病毒 首尔伟傲世表示即将提供解决方案2020-04-03 1271
-
EMS的诊断技巧与案例解析综述2021-08-27 797
全部0条评论

快来发表一下你的评论吧 !
