

 RoCE与IB对比分析(一):协议栈层级篇
RoCE与IB对比分析(一):协议栈层级篇
电子说
描述
在 AI 算力建设中, RDMA 技术是支持高吞吐、低延迟网络通信的关键。目前,RDMA技术主要通过两种方案实现:Infiniband和RoCE(基于RDMA的以太网技术,以下简称为RoCE)。
RoCE与IB网络架构概述
RoCE和InfiniBand均是InfiniBand Trade Association(IBTA)定义的网络协议栈,其中Infiniband是一种专为RDMA设计的高性能网络,它从硬件层面确保了数据传输的可靠性,为了进一步发挥RDMA的优势,IBTA在2010年定义了RoCE。RoCE则是Infiniband与以太网技术的融合,它在保持Infiniband核心优势的同时,实现了与现有以太网基础设施的兼容性。具体来说,RoCE在链路层和网络层与Infiniband有所不同,但在传输层和RDMA协议方面,RoCE继承了Infiniband的精髓。
从市场应用占比来看,2000年,IB架构规范的1.0版本正式发布,2015年,InfiniBand技术在TOP500榜单中的占比首次超过了50%,但据最新统计,在全球TOP500的超级计算机中,RoCE和IB的占比相当。以计算机数量计算,IB占比为47.8%,RoCE占比为39%;而以端口带宽总量计算,IB占比为39.2%,RoCE为48.5%。
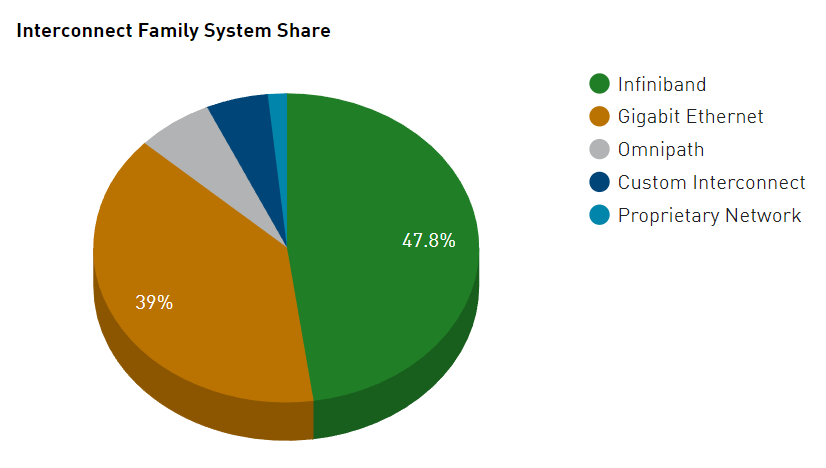
图1 超级计算机 500 强中 RoCE 和 InfiniBand 的利用率
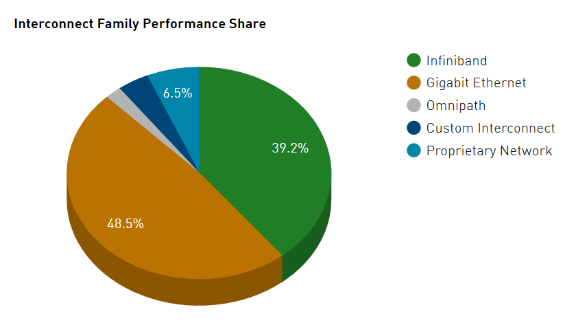
图2 超级计算机 500 强中 RoCE 和 InfiniBand 的利用率
RoCE与IB报文格式对比
- RoCE报文格式下图所示:
其中,RoCEv1使用了IB的全局路由头(Global Routing Header),IB BTH是IB的基本传输头(Base Transport Header),ICRC是对InfiniBand层不变字段进行校验的循环冗余校验码,FCS是以太网链路层的校验序列码。
RoCEv2中添加了IP Header和UDP Headrer,引入IP解决了扩展性问题。
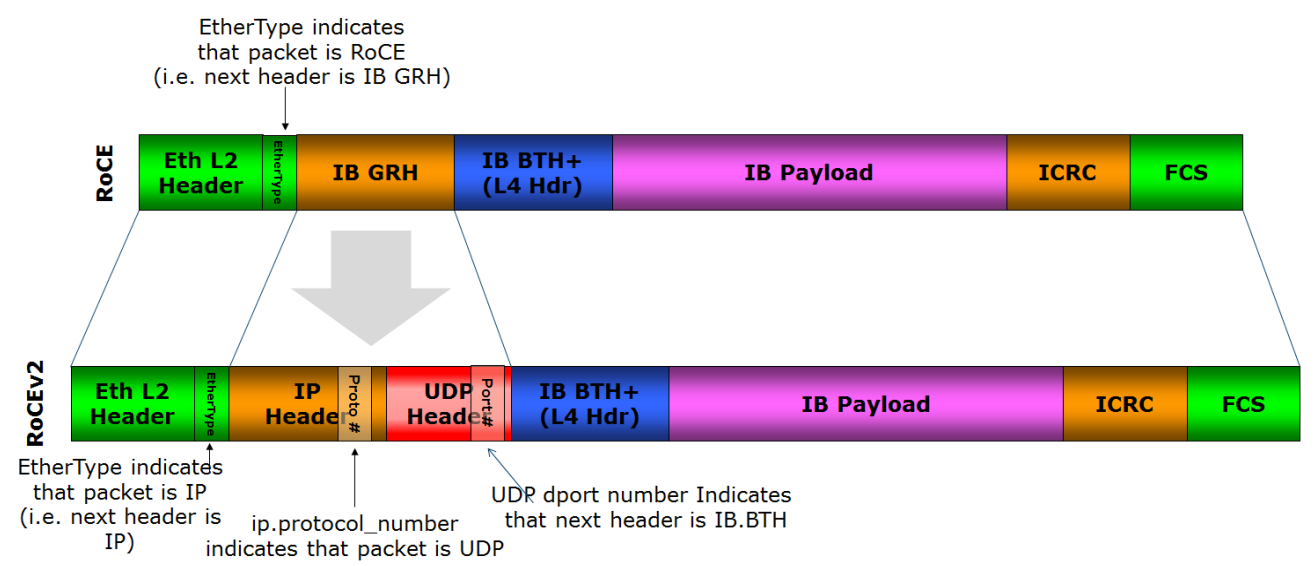
图3 RoCE数据包格式
- IB报文格式如下图所示:
在一个子网(Subnet)内部,只有Local Routing Header(LRH),对应OSI的链路层。在子网之间,还有一个Global Routing Header(GRH),对应OSI的网络层。在Routing Header之上,是Transport Header,提供端到端的传输服务,包括数据的分段、重组、确认和流量控制。接着就是报文的数据部分,包含应用层数据或上层协议信息。最后是不变字段和可变字段的循环冗余校验码(CRC),用于检测报文在传输过程中的错误。

图4 IB数据包格式
RoCE与IB网络层级对比
IB与RoCE协议栈在传输层以上是相同的,在链路层与网络层有所区别:
RoCEv1中,以太网替代了IB的链路层(交换机需要支持PFC等流控技术,在物理层保证可靠传输),然而,由于RoCEv1中使用的是L2 Ethernet网络,依赖于以太网的MAC地址和VLAN标签进行通信,而不涉及网络层(IP层,即OSI模型的第三层)的路由功能,因此,RoCE v1数据包不能实现跨不同的IP子网传输,只能在同一广播域或L2子网内进行传输。
RoCEv2在RoCEv1的基础上,融合以太网网络层,IP又替代了IB的网络层,因此也称为IP routable RoCE,使得RoCE v2协议数据包可以在第3层进行路由,可扩展性更优。
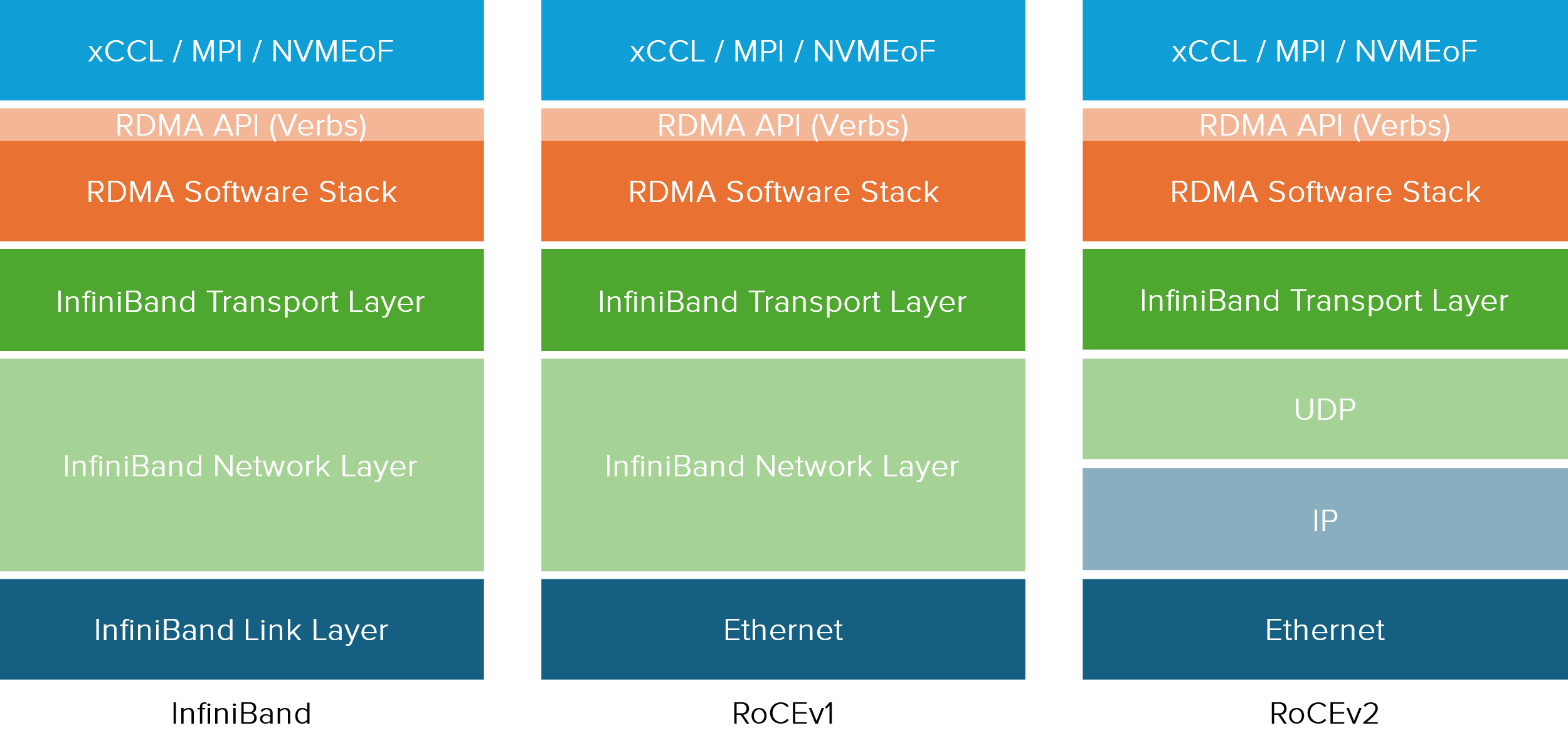
图5 RoCE和IB协议栈对比
物理层
- RoCE的物理层基于标准以太网,使用PAM4 (Pulse Amplitude Modulation 4)编码方式和64/66b编码。支持铜缆和光纤,接口有 SFP+、QSFP+ 、OSFP等。支持速率从 10GbE到800GbE。
- IB的物理层则是专有的,采用更传统的NRZ(Non-Return-to-Zero)调制技术和64/66b编码。支持铜缆和光纤,接口通常为 QSFP、OSFP,支持速率从 10Gbps 到 400Gbps,并可以通过多通道的组合实现更高的总带宽(如 800Gbps)。
对比来看,IB采用的NRZ每个符号只有两个电平,而RoCE采用的PAM4使用 4个不同的电压电平来表示数据,也就是说RZ信号中,每个周期传输1bit的逻辑信息,PAM4每个周期可以传输2bit的信息,因此在相同的波特率下,PAM4的数据传输速率是NRZ的两倍,具有更高的带宽效率,在支持更高速率(如1.6T,3.2T)时具有潜在的优势。目前,六进制(PAM6)和八进制(PAM8)调制技术正处于实验和测试阶段,而InfiniBand(IB)也在逐渐从传统的NRZ(非归零)调制技术转型至PAM4,例如,400G光模块现已能够同时支持IB和以太网标准。相比之下,以太网在调制技术的应用上展现出更为迅速的发展势头。
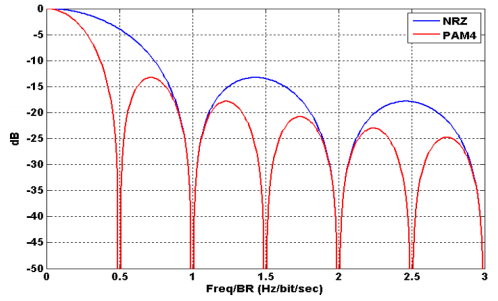
图6 频域中 PAM4 与 NRZ 信号的频率内容
链路层
- RoCE的链路层是标准以太网,为了在传统以太网上实现无损传输,引入了 PFC (Priority-based Flow Control),由IEEE 802.1Qbb标准定义,当交换机的某个优先级队列的缓冲区接近满载时,会发送 PFC帧给上游设备,通知其暂停发送该优先级的流量,防止缓冲区溢出,避免数据包在链路层被丢弃。
此外,以太网引入了ETS(Enhanced Transmission Selection) ,它是DCB (Data Center Bridging)标准的一部分,由 IEEE 802.1Qaz 规范定义。ETS 将流量分配到不同的队列,为每个队列分配一个权重,控制每个流量队列能够使用的带宽百分比,保证高优先级的流量,如RDMA等,获得足够的带宽资源。
- IB的链路层是专有的,包头称为Local Routing Header,如图所示。

其中,VL是虚拟通道 (Virtual Lanes),SL是服务等级 (Service Level),Source/Destination Local Identifier则是链路层地址。
它内建了对无损传输的支持,这是因为它实现了基于信用的流量控制( Credit -based Flow Control)。接收方在每个链路上提供一个信用值,表示其缓冲区能够接收的数据量。发送方根据此信用值发送数据,确保不会超过接收方的处理能力,从而避免缓冲区溢出和 数据丢失 。
IB链路层结合SL和VL实现QoS,SL共有16个业务等级,用于标识流量优先级,每个数据包可以根据业务需求被分配到不同的服务等级,通过SL-VL映射,将不同优先级的流量分配到不同的VL上,从而确保高优先级流量(如RDMA)不会因低优先级流量的拥塞而受到影响。
对比而言,IB的链路层由专用硬件实现,效率较高,具有超低时延的特点,而RoCE基于标准以太网硬件,时延稍长。但由于两者都达到了100ns级别,而根据UEC的最新定义,在传输RDMA时,端到端性能要求通常为10μs左右,它们的差别不大。
网络层
- RoCE的网络层使用IP,可以是IPv4或IPv6。它采用成熟的BGP/OSPF等路由协议,适应任何网络拓扑并具有快速自愈能力;支持ECN(EXPLICIT CONGESTION NOTIFICATION ),用于端到端的拥塞控制;支持DSCP,替代IB的TRAFFIC CLASS,用于实现QoS。
- IB的网络层借鉴了IPv6。Global Routing Header的格式与IPv6完全相同,具有128bit地址,只是字段命名不同。但它没有定义路由协议,而是采用子网管理器(Subnet Manager)来处理路由问题,这是一种集中式的[服务器] ,每个网卡端口和交换芯片都通过由SM分配的唯一[身份标识] (Local ID,LID)进行识别,不具备互操作性,因此很难快速响应网络的变化。
显然,IB网络层是专有的、集中管理的,而RoCE的网络层基于标准以太网和UDP,在互联网数以十亿计算的设备上使用,技术成熟,并在持续发展中;引入SRv6等技术后,IP进一步增强了流量工程、业务链、灵活性和可扩展性等能力,非常适合组建超大规模可自愈的RDMA网络。
传输层
RoCE
RoCE采用了IB的传输层。RoCEv2协议栈虽然包含UDP,但它仅借用了UDP的封装格式,传输层的连接、重传、拥塞控制等功能由IB传输层完成。UDP层的目的端口固定分配给RDMA协议,源端口则是动态分配的,但在一个连接过程中保持固定。这样可以让网络设备通过源端口区分不同的RDMA 数据流 。
InfiniBand
IB的传输层采用了模块化的灵活设计,通常包含一个基本传输头 BTH(Base Transport Header) 和若干个(0到多个)扩展的传输头(Extended Transport Header)。
BTH(Base Transport Header) 是InfiniBand传输层头部的一部分。它是InfiniBand网络协议中L4传输层的基本头部,用于描述数据包传输的控制信息。格式如下,

关键信息有:
- OpCode , 操作码 。由8个bit组成。前3个bit代表传输服务类型,如可靠连接/不可靠连接/可靠数据报/不可靠数据报/RAW数据报等。后5个bit代表操作类型,如SEND/READ/WRITE/ACK等。
- Destination QP,目的QP号 (Queue Pair Number)。与TCP端口号类似,代表了RDMA连接(称为Channel)的目的端。但与TCP端口不同的是,QP由Send/Recv两个队列组成,但用同一个号码标识。
- Packet Sequence Number,包序列号 ,简称PSN。与TCP序列号类似,用于检查数据包的传输顺序。
- Partition Key,分区键。 可以将一个RDMA网络分为多个逻辑分区。在RoCE中可采用新一代的VxLAN等技术替代。
- ECN,显示拥塞通知。 用于拥塞控制,包含Forward和Backward两个bit,分别表示在发送和返回路径上遇到了拥塞,在RoCE中被IP头部的ECN替代。
BTH帮助接收方理解该包属于哪个连接以及如何处理接收到的包,包括验证包的顺序、识别操作类型等。
在BTH之后,还有 RDMA Extended Transport Header ,它包含远端的虚拟地址、密钥和数据长度等信息。格式如下,

其中:
- VirtualAddress ,虚拟地址,代表目的端内存地址。
- DMA Length ,直接内存访问长度,是要读写的数据长度,以字节为单位。
- Remote Key ,用于访问远端内存的密钥。
IB传输层通常由RDMA网卡硬件实现,在IB中称为Channel Adapter(CA),在RoCE中称为RoCE网卡,从而提升RDMA传输的性能。在一些高级的RoCE交换机中,还可以感知IB传输层信息并对RDMA数据流做加速处理。
RDMA操作
借助RDMA扩展头,RoCE和IB的传输层对远程主机的地址进行直接的读写操作(Operation)。
- RDMA写操作 (RDMA Write)
在 QP(Queue Pair) 建立后可以直接进行,允许发送方直接写入接收方的内存,不需要接收方的CPU参与,并且无需请求。这种操作方式是 RDMA 高性能和低延迟的核心特性之一。
RDMA Write 是一种单向操作。写入方在写入数据后不需要等待接收方的响应,这种操作与常规的 Send/Receive 模式不同,不需要接收方预先准备接收队列。
- RDMA读操作 (RDMA Read)
允许发送方从接收方的内存中读取数据,不需要接收方CPU参与。目标地址和数据大小在发送方指定。如下图所示,在一次请求后,可以通过多次响应返回数据,提高了数据传输效率。
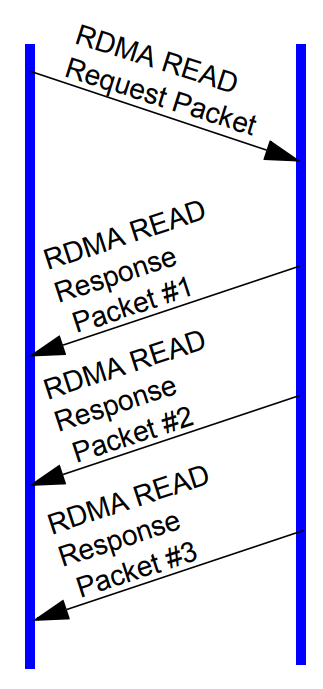
图7 RDMA 读操作
- 发送/接收操作 (Send/Receive)
这是传统的消息传递操作,数据从发送方传递到接收方的接收队列中,需要接收方预先准备接收队列。
在RoCE中,RDMA跳过操作系统的TCP/IP协议栈,直接与RoCE网卡上的传输层连接,借助DMA机制,直接访问本地和远端内存,实现了零拷贝传输,大幅度提升了性能。

同样,IB网卡在硬件上实现RDMA操作,零拷贝传输,两者的性能相当。
当然,无论在RoCE还是IB中,RDMA 连接的初始化、资源分配、队列对 (QP) 管理、以及一些控制路径上的操作(如连接建立、内存注册等)仍然依赖于软件栈。
应用层
RDMA在 数据中心 、HPC集群、超级计算机中获得了广泛的应用,用于承载AI训练、推理、[分布式存储] 等数据中心内部的关键业务。
例如,在AI训练/推理时, xCCL或者MPI使用RDMA实现点对点和集合通信;在分布式存储时,NVMEoF, Ceph使用RDMA对网络存储器进行读写操作。
网络层级对比小结
- 在物理层,RoCE和IB都支持800G,但PAM4相比NRZ具有更强的升级潜力,以太网成本也低于IB,RoCE更胜一筹。
- 在链路层,两者均实现了无损传输,RoCE的ETS能够为不同优先的流量提供带宽保证,且RoCE和IB的时延均达到了100ns级别,在实际应用中差不大。
- 在网络层,RoCE借助IP的成熟的持续发展,更能适应大规模网络。
- 传输层及以上,RoCE和IB使用同样的协议,没有区别。
RoCE与IB的较量,究竟谁更胜一筹
总的来说,RoCE和InfiniBand都由IBTA定义,没有本质的不同。RoCE实际上是将成熟的IB传输层和RDMA移植到了同样成熟的以太网和IP网络上,是一种强强联合,在保持高性能的同时,降低了RDMA网络的成本,能够适应更大规模的网络。
根据亚马逊的高级首席工程师Brian Barrett,AWS之所以放弃IB方案,主要是因为:“云数据中心很多时候是要满足资源调度和共享等一系列弹性部署的需求,专用的IB网络构建的集群如同在汪洋大海中的孤岛”。
出于AI算力建设对于成本和开放性的考量,越来越多的公司已经在使用以太网交换机用于大规模AI算力中心,例如当前全球最大的AI超级集群(xAI Colossus,造价数亿美元、配备十万片NVIDIA H100 GPU),便是采用64 x 800G,51.2T以太网方案构建集群网络。
参考文献
https://mp.weixin.qq.com/s/PZ_Q5rS5a5YJlczao9SMXw
https://support.huawei.com/enterprise/zh/doc/EDOC1100203347
https://community.fs.com/cn/article/roce-technology-in-high-performance-computing.html
https://ascentoptics.com/blog/cn/understanding-infiniband-a-comprehensive-guide/
https://blog.csdn.net/jkh920184196/article/details/141461235
https://www.servethehome.com/inside-100000-nvidia-gpu-xai-colossus-cluster-supermicro-helped-build-for-elon-musk/
审核编辑 黄宇
-
步进电机与伺服电机对比分析2021-02-05 0
-
LTE与WiMAX对比分析哪个好?2021-05-31 0
-
CPLD与FPGA对比分析哪个好?2021-06-21 0
-
协议是什么 协议栈又是什么2021-08-05 0
-
STM32和Arduino对比分析哪个好?2021-11-04 0
-
ARM/DSP/FPGA的区别是什么?对比分析哪个好?2021-11-05 0
-
ARM与单片机对比分析哪个好?2021-11-05 0
-
CPLD与FPGA的对比分析哪个好?2021-11-05 0
-
异步通信与同步通信对比分析哪个好?2021-12-16 0
-
DRAM和SRAM对比分析哪个好?2022-01-20 0
-
SPWM调制方法对比分析2009-07-06 13393
-
WLAN与WPAN的QoS机制对比分析2009-08-04 830
-
小型PLC对比分析2012-04-27 871
-
RoCE技术在HPC中的应用分析2022-09-05 1566
-
RoCE与IB对比分析(二):功能应用篇2024-11-15 270
全部0条评论

快来发表一下你的评论吧 !
