

瑞萨电子RA8E1和RA8E2 MCU新品解读
描述
Arm Cortex-M85 RA8系列于2024年11月推出RA8E1和RA8E2两款新产品。这两款新产品已正式量产上市,将高算力的RA8系列扩展到入门级领域的应用,降低BOM成本,扩大RA8高性能产品线。
● RA8E1:面向高性能入门级通用型应用。360MHz Arm Cortex-M85内核,集成Helium、TrustZone及优化的外设接口。
● RA8E2:面向高性能入门级图形显示应用。480MHz Arm Cortex-M85内核,集成Helium、TrustZone及TFT-LCD显示控制单元,2D绘图引擎等图形功能模块。
RA产品阵容

Helium
Helium技术是Arm公司为Cortex-M系列处理器引入的向量扩展,正式名称是Armv8.1-M M-Profile Vector Extension(MVE)向量扩展。Helium技术适用于需要高效数据处理的嵌入式设备,特别是物联网、可穿戴设备、音频处理、图像处理、边缘AI等领域。目的是提升它们的数字信号处理(DSP)和机器学习(ML)任务的性能,同时保持低功耗。通过Helium,Cortex-M处理器可以在保持低功耗的同时执行高效的计算任务,拓宽了嵌入式系统的应用场景。
Helium和Cortex-A内核MPU中的Neon有很多相似之处。Neon和Helium都使用FPU中的寄存器作为矢量寄存器。两者都使用128位向量,并且许多向量处理指令对于两种体系结构都是通用的。然而,Helium是一种全新的设计,可在小型处理器中实现高效的信号处理性能。它为嵌入式用例提供了许多新的架构功能,因为它针对面积(成本)和功耗进行了优化,为M-Profile架构带来了类似Neon的功能(Cortex-A的SIMD注指令)。Helium经过优化,可有效利用较小Cortex-M内核中的所有可用硬件。下表详细的给出了Helium和Neon之间的对比信息。
Helium与Neon对比表
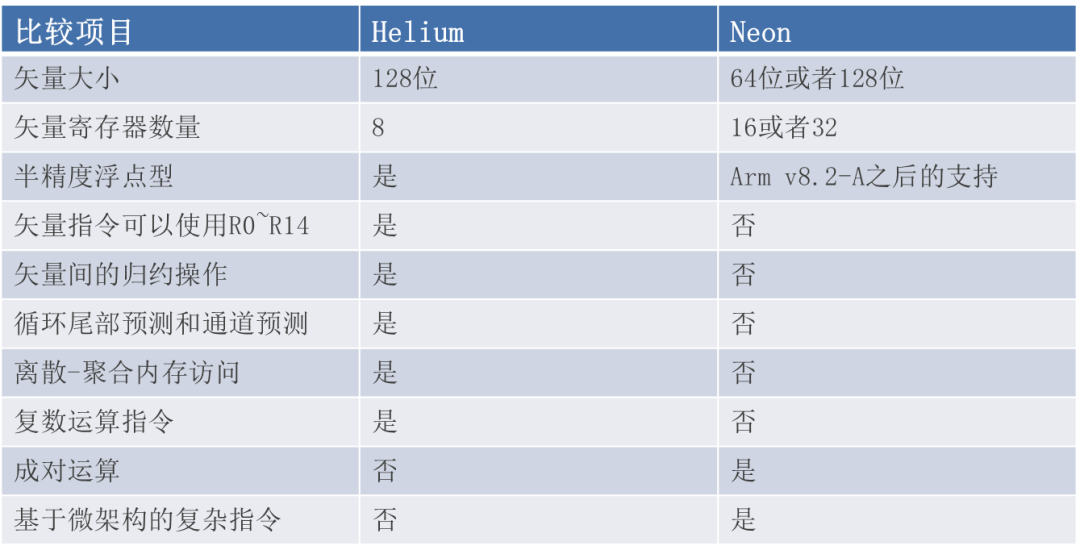
注:SIMD(Single Instruction Multiple Data)即单指令多数据,表示在该硬件中的多个处理单元中可以同时对多个数据项执行相同的操作,也就是说,CPU可以同时执行并行计算,但只有一个指令正在执行。这是数据级的并行。
目前有许多系统将Cortex-M处理器和专用可编程的DSP处理器结合来使用。Helium允许这样的系统只用一个处理器来实现。这样做有如下优点:
● 从软件开发的角度来看,它允许使用单个工具链,而不是分别对CPU和DSP使用各自的编译器和调试器。这就意味着程序员只需要熟悉一种架构。
● 消除了对处理器间通信的需求,这点可能非常重要,因为要对实时交互的两个正在运行的处理器中的不同软件进行调试,既困难也耗时。
● Cortex-M系列的CPU相比专用DSP而言,更易于编程。
在硬件设计层面,使用一个处理器(而不是两个处理器)可以简化系统,从而减少芯片面积和成本,并缩短开发周期。
Helium寄存器是128位的,一共有8个,寄存器数量不可修改。它和浮点单元(FPU)共用硬件物理单元。在FPU中使用S0~S31来访问32个单精度(32位)寄存器,同样的硬件寄存器也可看做16个双精度(64位)寄存器D0~D15。D0和S0、S1共用64位相同的硬件寄存器。在Helium架构中,Helium使用8个矢量寄存器Q0~Q7。这就意味着,Helium寄存器Q0和浮点寄存器S0~S3,D0~D1使用相同的物理寄存器,Q1和浮点寄存器S4~S7,D2~D3使用相同的物理寄存器,其他Helium寄存器以此类推。因为Helium寄存器重用了标量FPU寄存器,所以当发生异常时无须使用额外的资源去保存和恢复这些寄存器(同样不影响中断延迟)。
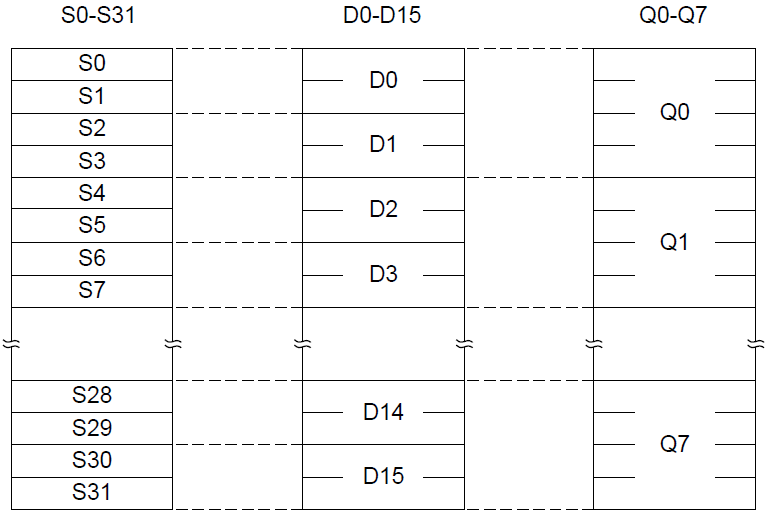
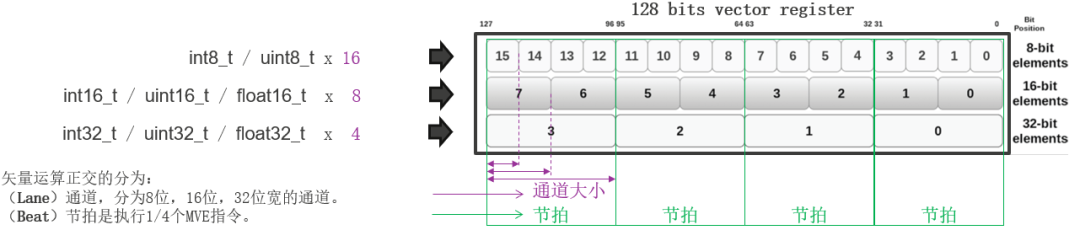
每个Helium寄存器都可以划分为8位,16位,32位宽的通道。每个通道可以被一条指令看作:
● 整型数值(8/16/32位宽)
● 定点饱和值(Q7/Q15/Q31)
● 浮点数值(半精度FP16/单精度FP32)
下图是一个矢量寄存器相加的示例。Helium寄存器q5和q0都是8个int16的元素数据(8个通道),将他们相加的结果存在q0中。
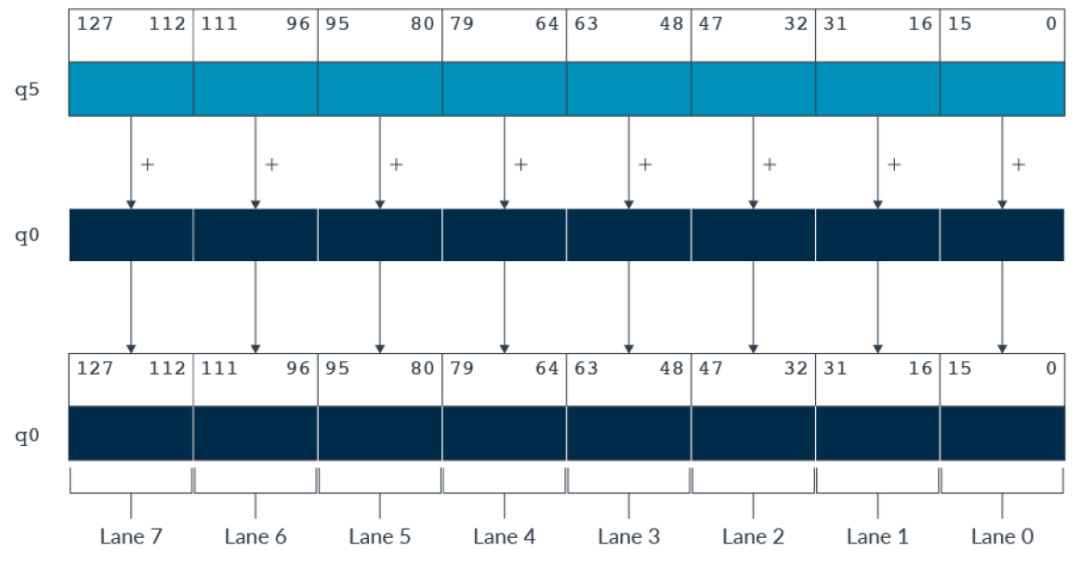
矢量寄存器相加示例
Helium允许矢量中的每个通道有条件地执行,这称作通道预测。矢量预测状态和控制寄存器(VPR)保存每个通道的条件值。某些矢量指令(比如矢量比较VCMP)可以改变VPR中的条件值,当这些条件值被设置好以后,接下来就可以使用VPT(矢量条件预测)指令,以每个通道为基础在矢量预测中实现条件执行。
TCM
TCM(Tightly Coupled Memory,紧耦合内存)是一种用于嵌入式系统中的高性能内存结构,主要用于存储关键的数据或代码,减少访问延迟。TCM通常与处理器内核紧密连接,能够实现快速访问,与主存(如SRAM)相比,它具有更低的延迟和更高的带宽。
TCM的关键特性
1. 低延迟高带宽
TCM直接连接到CPU核心(通过高带宽、低延迟的路径),允许处理器以更高的速度访问数据,适合实时性要求高的应用,如电机控制算法,数字电源,通信,视频/音频信号处理等。

2. 可预测性
TCM是一种确定性内存,与缓存不同,它没有不确定的替换策略或不确定的访问延迟。这种特性对于实时系统非常重要,可以确保系统的响应时间。
3. 代码和数据分离
TCM通常分为ITCM(指令紧耦合内存)和DTCM(数据紧耦合内存),分别用于存储代码和数据。这种分离可以有效避免代码和数据访问之间的资源争用,进一步提高性能。
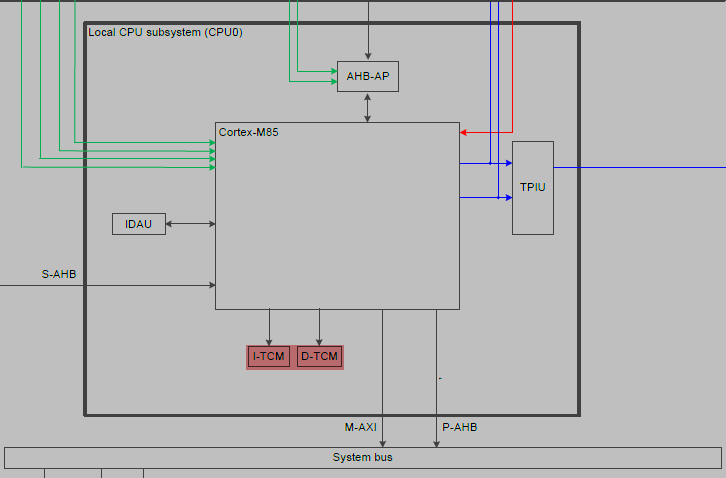
CPU框图
2D Drawing Engine(RA8E2特有)
2D Drawing Engine(二维绘图引擎,DRW)是一种专门设计的硬件模块,用于加速图形界面的绘制任务,尤其是在嵌入式系统、工业控制、家电显示屏等图形密集型应用中。这种引擎能够显著提高图形处理的效率,同时减轻MCU的运算负担。
2D Drawing Engine的关键功能
1. 基本图形绘制加速
2D绘图引擎通常可以加速基本的图形绘制操作,比如线条、矩形、圆形、多边形等。通过硬件加速,这些图形能够快速呈现在屏幕上,而不必依赖软件逐点绘制。
2. 图像和纹理的拷贝与缩放
2D绘图引擎能够对图像或纹理进行高效的拷贝、缩放、旋转等操作。比如在用户界面上实现图标缩放、背景图的平滑移动等效果。
3. 位块传输(BitBLT)
用于将图像数据从一个区域快速复制到另一个区域。这对UI界面更新非常重要,可以加速图形元素的刷新和移动,减少闪烁感。
4. 颜色填充和渐变填充
可以快速填充颜色或实现颜色渐变填充。渐变填充可以帮助设计更丰富的UI界面,比如背景的渐变效果和按钮的渐变光泽。
5. 抗锯齿和锐化
2D绘图引擎支持抗锯齿技术,确保图形边缘更加平滑,提升视觉效果。
绘图对象示例
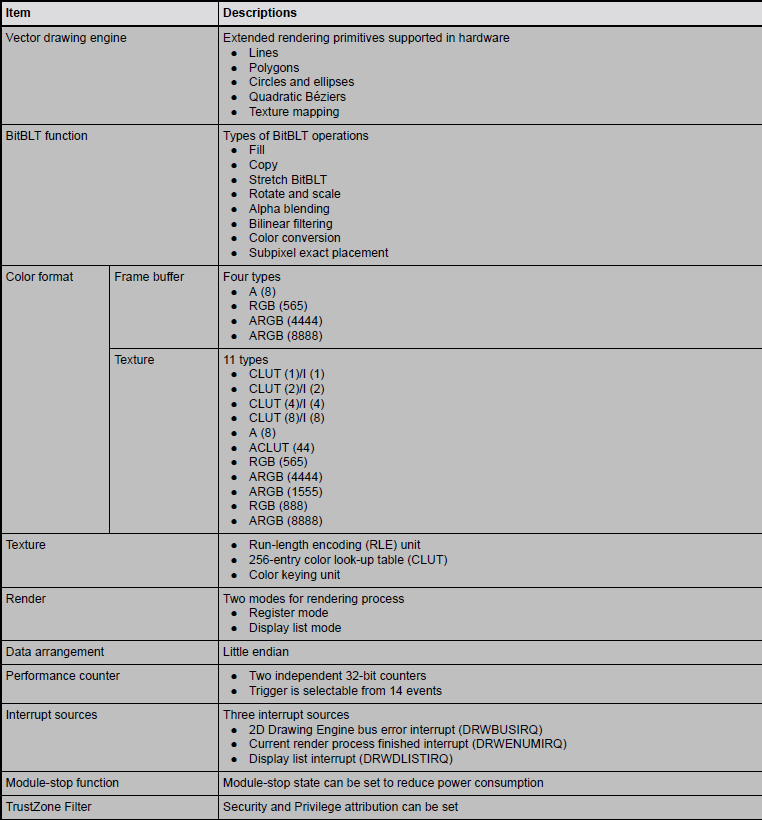
2D绘图引擎规格
典型应用场景
1. 用户界面
在智能家电、工业仪表、汽车信息娱乐系统等需要GUI界面的设备上,2D绘图引擎可以加速图形元素的绘制,使得界面更加流畅。
2. 图像渲染
2D绘图引擎可以用于小型图像渲染任务,比如显示简单的动画或图形效果。
2D绘图引擎通过硬件加速图形处理,大幅提升绘图速度,降低CPU负载,适合资源受限的嵌入式环境。
总的来说,MCU的2D绘图引擎提供了高效的图形处理能力,适用于需要快速绘制的图形界面应用。它在嵌入式系统中起到了平衡性能和功耗的关键作用。
综上所述,RA8E1和RA8E2作为新质生产力在嵌入式系统领域的杰出代表,以其高算力、高性能、高性价比以及丰富的功能和安全性特点,成为安全控制、工业HMI、智能家电、建筑自动化和医疗监护仪等应用领域的理想选择。
-
留言有奖 | 瑞萨最新RA入门级系列RA4E2&RA6E2新品解读【高性能,小封装,低成本】2023-03-29 1231
-
使用RA2E1 MCU和FSP实现超低设计2022-04-25 2089
-
入门级RA系列RA2E1 MCU组用于低功耗和空间受限应用2022-04-29 2419
-
瑞萨RA入门级产品RA4E2&RA6E2外设简介(上)2023-03-31 1349
-
直播预告 | 6月8日 RA6T2电机板新品发布会&RA MCU创意氛围赛说明2023-06-08 844
-
基于瑞萨RA系列R7FA2E1A52DFJ MCU的无叶风扇控制方案2023-09-26 842
-
瑞萨电子宣布推出RA8D1微控制器(MCU)产品群2023-12-15 1009
-
使用瑞萨e² studio FSP基于RA2E1定时器配置PWM输出2023-08-01 719
-
瑞萨电子RA家族推出RA8系列高算力通用MCU2024-04-02 1430
-
瑞萨电子RA产品家族新增RA0E1 MCU产品组2024-04-11 904
-
瑞萨RA0E1开发分享之一2024-05-10 903
-
试用活动 | 100套!!瑞萨RA6E2/RA4E2开发板评测活动2024-09-10 595
-
瑞萨推出全新RA8入门级MCU产品群, 提供极具性价比的高性能Arm Cortex-M85处理器2024-11-07 468
-
瑞萨电子推出RA8E1和RA8E2微控制器产品群2024-11-09 517
-
瑞萨电子全新RA8系列MCU产品介绍2024-11-09 408
全部0条评论

快来发表一下你的评论吧 !
