

融合计算是如何提出来的
描述
融合计算是微观和宏观视角算力提升策略的总结,是三个维度融合(异构融合x软硬件融合x云边端融合)的统称,那么融合计算是如何提出来的?为什么融合计算有且仅有三个维度的融合?
性能和算力
1.1 性能的计算公式

定性的分析,一个芯片的性能由三个维度组成:
维度一,指令复杂度。理论上,指令复杂度越高,性能越好。但实际上,需要考虑系统的通用性,以及目标工作任务的灵活性特征,来选择合适的处理器引擎。
维度二,运行频率。运行频率提升,主要是先进工艺,以及更复杂的流水线设计。
维度三,并行度。提高并行度比较好理解,并行也主要有同构并行、(两个处理器的)异构并行和(三个以上)更多异构融合的并行。
1.2 算力的计算公式
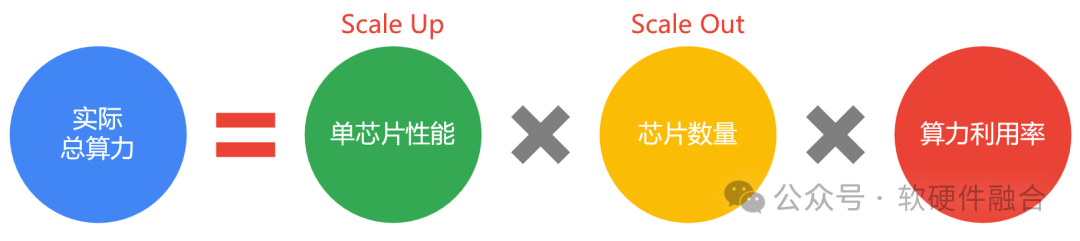
算力和性能的区别在哪里?性能是微观的算力,算力是宏观的性能。那么算力和性能之间的联系是什么? 如上图所示,我们定性分析,可以在性能和算力之间构建一个关联的公式。从上述公式可以看到,宏观的总算力,由三个维度的参数组成:
维度一,单芯片性能。通过提升单芯片性能的方式,也就是Scale Up的方式提升整体算力。
维度二,芯片的数量。通过增加计算芯片(计算节点)的数量,也就是Scale Out的方式,通过提升规模来提升整体算力。
维度三,算力利用率。如果仅有标称算力,而无法达到很好的利用率,那也是徒劳。随着AI的发展,集群规模越来越扩大,算力利用率越来越成为评价一个算力系统能力的关键指标。
从微观到宏观
2.1 微观视角的算力提升
2.1.1 如何提升单芯片性能 融合提升单芯片的性能:
一方面是底层采用更先进的工艺,以及通过Chiplet封装支撑,从而实现更大的计算规模;
另一方面,则是系统架构和微架构方面的创新,来实现单芯片层次更高的性能,这也是算力提升最本质的做法。
计算架构的创新则最主要的就是:
从第一代基于CPU的同构通用计算;
以及第二代基于CPU+GPU的异构通用计算;
逐步的走向第三代基于CPUxGPUxDSAs的异构融合通用计算。
2.1.2 如何提升芯片的数量和落地规模 芯片的落地,不是简单的复制。国产算力芯片已经有好多家了,甚至一些公司的芯片都已经有三到四代了,但仍然销售不是很顺利。底层的原因在于:
生态的问题。国产芯片(相比NVIDIA CUDA)生态不够好。但生态问题如何解决,不在于微观的一家公司的一个架构和相应的私有生态如何构建和繁荣,而在于宏观的很多公司很多架构如何整合(将在加下来的宏观视角部分介绍)。
芯片需要足够多的通用性,需要能够覆盖更多的业务场景和更多的业务迭代。
此外,芯片需要有非常高的I/O能力,确保在更大的规模下仍能有非常高的东西向通信效率(不耽误计算,不影响计算效率),能够支持更大规模的集群计算。
2.1.3 如何提升芯片的算力利用率 要想提升算力芯片的利用率,那么:
一方面,芯片需要有很好的扩展性能力,支持资源切分、池化、和重组;
另一方面,开放架构,减少多元异构算力的架构数量,从而使得更多的算力能够汇集到统一的算力资源池,从而实现更大范围的算力共享,进而提升整体的算力利用率。
2.2 宏观视角的算力提升
2.2.1 如何提升单个节点的性能 从宏观角度,单节点的性能提升,则主要是如何把更多异构融合架构的计算能力充分的用起来:
首先,是需要一个更加综合的异构融合计算框架,既包括CPU的工具链,也有GPU、AI,以及其他如网络、存储、视频、安全等领域的加速计算框架,还需要这个异构融合计算框架,支持异构协同和跨异构应用迁移。
第二,则是更复杂的计算架构和算力调度。在通算时代,一个物理的计算机,通常具有四类资源:CPU、内存、网络和存储;在异构计算时代,则是CPU、内存、网络、存储和加速器。而在异构融合时代,则是CPU、内存、网络、存储,以及更多种不同领域的加速器。那么,如此复杂的计算架构模型,如何资源切分、池化和重组,以及如何同架构调度,以及实现跨架构调度,都是需要深入考虑的事情。
2.2.2 如何提升芯片的数量和落地的规模 宏观视角下,芯片的数量提升,主要是如下几个层次:
最基础的就是集群规模的扩大,这需要高性能网络,更高的带宽,更低的延迟。
接下来,就是跨集群管理和跨集群调度,这就需要更复杂的网络和更高层次的算力调度。
再接下来,就是要实现跨数据中心的算力整合,这也就是目前火热的算力网络关注的范畴,有非常大的技术挑战和商业上的挑战。
再接下俩,那就是要跨云边端,实现云边端融合计算,挑战会更大。
2.2.3 如何提升算力利用率 宏观视角看算力利用率提升,主要是两块,承上启下:
启下。承载计算的芯片类型越来越多,多元异构问题凸显,这是目前算力整合不得不面对的现实困难。芯片(或引擎)的类型有很多,每一张类型还有很多不同的架构,这些不同类型不同架构的芯片是一个个孤岛,如何把这些孤岛连成一体,是一个非常重要的事情。未来,开放计算架构会是一个不得不走的选项,逐渐的从目前各家芯片公司各自为政私有架构的模式,过渡到开放架构的模式,让芯片的架构逐渐收敛。
承上。相比芯片侧的问题,计算芯片所支撑的上层业务软件侧的问题相对较少。行业存在开源软件生态,这是目前绝大部分业务客户的共识,这也减少了很多底层硬件的适配难度。但这几年,这个问题有所恶化:随着AI发展,NVIDIA GPU和CUDA一家独大,大家不得不在NVIDIA的封闭体系下工作。这不利于行业的竞争,也不利于算力成本的下降。理想的情况是:行业形成开源开放的计算软硬件生态,开源软件定义开放硬件;算力中心,不对任何硬件平台有依赖,不需要为生态溢价付费,仅需要为功能和性能付费即可。
需要注意的是,宏观和微观,以及算力提升的三个维度,是彼此交叉关联的。这里的很多策略,可能会同时影响两个甚至三个维度,甚至“按下葫芦浮起瓢”也是有可能的。实际的算力优化工作,需要仔细分析应对。
融合计算
随着AI大模型以及AI+场景对算力的需求猛增,算力中心建设成本也水涨船高,算力网络(实现算力共享)逐渐流行。同时许多AI+终端的场景,算力需求猛增,从云端和边缘端“借”算力的云边端融合计算模式,成为了终端算力提升的一个重要方式。 算力系统相当复杂,算力提升成为了一个庞大的系统工程。立足于最核心的芯片硬件和相关软件,从微观到宏观,基于上面分析的算力提升的背景知识,提出了“融合计算”的概念。希望通过“融合计算”的全方位的整合优化,来实现算力最优的性能和成本。
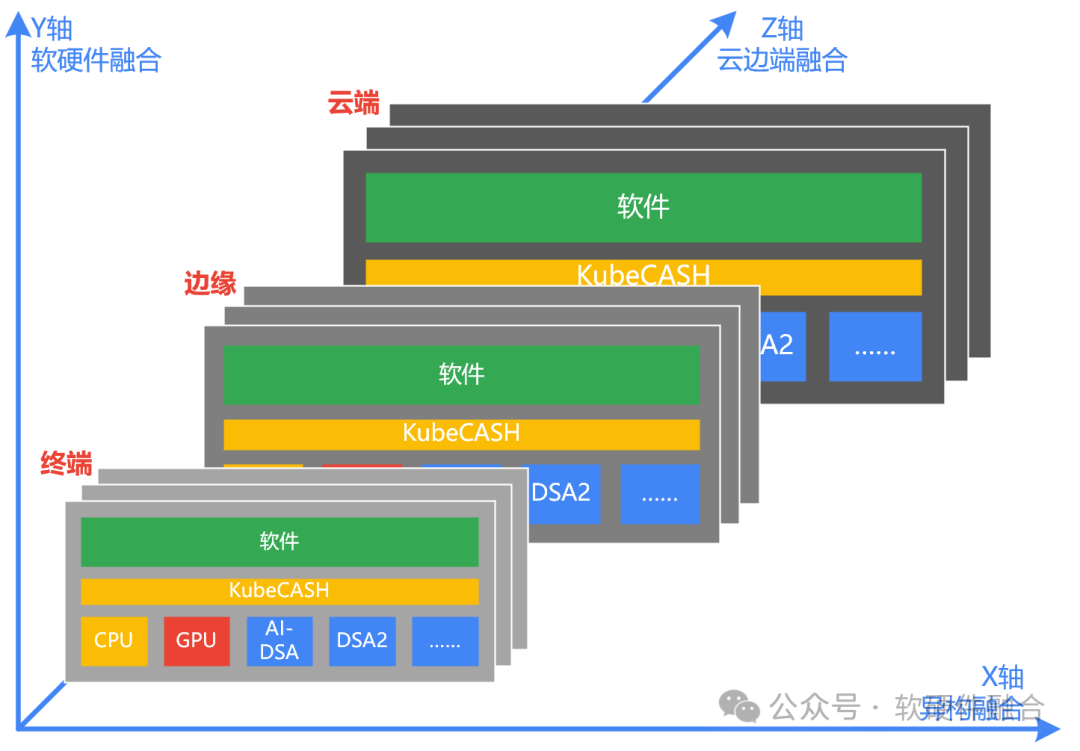
融合计算,其实就是微观和宏观视角算力提升策略的总结,是三个维度融合(异构融合x软硬件融合x云边端融合)的统称:
X轴,芯片维度,异构融合,Scale Up,提升单芯片性能。通过异构融合计算,把各类异构算力的价值发挥到极致。
Y轴,计算堆栈维度,软硬件融合,提升算力利用率。通过核心的算力调度系统中间件,实现承上启下,向上对接开源软件,向下对接多元异构算力,实现多元异构算力的协同和融合,从而最大化算力资源的利用率。
Z轴,集群扩展维度,云边端融合,Scale Out,提升芯片数量。通过增加集群规模,同时实现跨算力中心、跨不同云运营商、跨云边端融合的计算。
融合计算和多算融合的关系
融合计算,是从宏观和微观的角度,实现更底层更本质的提升性能和降低成本。而通算、智算和超算,则要更上层一些,是计算面向不同业务要求所做的定向性能和成本的调整。
随着智算中心的发展,目前行业中出现了通算,智算和超算的融合的发展趋势。但实际的做法,有待商榷。把CPU通算集群、GPU智算集群,以及存储集群,以及超算集群,放置到一个算力中心里,就是多算融合吗?显然不是。

多算融合,必然是需要一套体系,能够统一通算、智算和超算,有统一的资源切分重组,有统一的资源池,有统一的算力调度,有统一的上层算力服务,才能称之为多算融合:
首先,是要构建统一的计算机模型。通算一般是CPU+标准网卡,而智算是CPU+GPU+高性能网卡,而超算则是CPU+GPU+高性能网卡+内存一致性加速,存储则是CPU+更多的存储I/O。不管咋样,可以通过我们前面讲到的计算模型来统一,不管是哪种计算,都是CPU+加速卡+内存+网络+存储的统一的计算模型。
然后是资源的池化。通过云计算的虚拟化和容器的机制,实现资源的切分、池化和重组,可以组合出符合要求的不同类型的计算实例。
目前,计算集群已经成为主流的计算方式。通过VPC,可以在公共算力服务的多租户场景为用户构建专属的通算的、智算的或超算的计算集群。
融合计算,是更底层更本地算力优化问题,它存在于软硬件协同层次,通过全方位的各种融合,实现算力的最佳效果:同算力条件下,成本更优;同成本下,算力更高。
融合计算,是云计算未来发展最大的创新方向,通过融合计算,夯实算力底座,支撑云计算继续往前发展。再以云计算为基,构建出面向通算、智算和超算等不同场景的算力服务。
-
哈佛结构是谁提出来的?居然找不到答案2012-11-06 0
-
大神们,帮我看看这图画得怎么样啊,有哪里不好的尽管提出来2015-06-10 0
-
如何将圆圈内的图片单独提出来2017-09-06 0
-
基于TCP的多路通讯的服务器,客户端可以去网站上下一个TCP调试助手来模拟,有什么问题可以提出来?2018-12-21 0
-
函数ROLLUP怎么计算合计2019-08-05 0
-
基于Cotherm的自动化热流耦合计算和热设计优化2021-01-07 0
-
为啥nwell上面的金属提出来20fF对sub的电容?2021-06-25 0
-
摩尔定律是什么_摩尔定律提出者及含义2018-03-09 30459
-
量子计算是什么2018-11-04 27239
-
基于AR与物联网融合技术在智能交通领域的应用是怎样2019-06-17 1958
-
带你了解超级计算机2019-07-24 3111
-
边缘计算是AI重要的承载体,是三者融合发展的爆发点2020-12-14 1632
-
元宇宙是什么时候提出来的2021-11-09 9883
-
安谋科技刘澍:高性能融合计算IP平台,赋能智能汽车芯片创新2022-12-26 499
-
黑芝麻智能推出基于武当C1296芯片多域融合计算平台方案2024-04-30 1783
全部0条评论

快来发表一下你的评论吧 !
