

在NVIDIA TensorRT-LLM中启用ReDrafter的一些变化
描述
Recurrent Drafting (简称 ReDrafter) 是苹果公司为大语言模型 (LLM) 推理开发并开源的一种新型推测解码技术,该技术现在可与 NVIDIA TensorRT-LLM 一起使用。ReDrafter 帮助开发者大幅提升了 NVIDIA GPU 上的 LLM 工作负载性能。NVIDIA TensorRT-LLM 是一个 LLM 推理优化库,提供了一个易于使用的 Python API 来定义 LLM 和构建 NVIDIA TensorRT 引擎,这些引擎具有顶尖的优化功能,可在 GPU 上高效执行推理。优化功能包括自定义 Attention Kernel、Inflight Batching、Paged KV Caching、量化技术 (FP8、INT4 AWQ、INT8 SmoothQuant) 等。
推测解码 (Speculative decoding) 是一种通过并行生成多个 token 来加速 LLM 推理的技术。它使用较小的“draft”模块预测未来的 token,然后由主模型进行验证。该方法通过更好地利用可用资源实现低延迟推理,在保持输出质量的同时大大缩短了响应时间,尤其是在低流量时段。
ReDrafter 运用基于循环神经网络 (RNN) 的采样 (称为 Drafting) 并结合之前在 Medusa 等其他技术中使用的树状注意力,预测和验证来自多个可能路径的 draft token 以提高准确性,并在解码器的每次迭代中接受一个以上 token。NVIDIA 与苹果公司合作,在 TensorRT-LLM 中添加了对该技术的支持,使更加广泛的开发者社区能够使用该技术。
ReDrafter 与 TensorRT-LLM 的集成扩大了该技术的覆盖范围,解锁了新的优化潜力,并改进了 Medusa 等先前的方法。Medusa 的路径接受和 token 采样发生在 TensorRT-LLM 运行时,需要在接受路径未知的情况下处理所有可能的未来路径,而且其中大部分路径最终都会被丢弃,这就给引擎内部带来了一些开销。为了减少这种开销,ReDrafter 要求在 drafting 下一次迭代的未来 token 之前,先验证 token 并接受最佳路径。
为了进一步减少开销,TensorRT-LLM 更新后在单个引擎中整合了 drafting 和验证逻辑,不再依赖运行时或单独的引擎。这种方法为 TensorRT-LLM 内核选择和调度提供了更大的自由度,通过优化网络实现了性能的最大化。
为了更好地说明 ReDrafter 的改进,图 1 展示了 TensorRT-LLM 中 ReDrafter 实现与 Medusa 实现的主要区别。大多数与推测解码相关的组件都在 ReDrafter 的引擎内完成,这大大简化了 ReDrafter 所需的运行时更改。
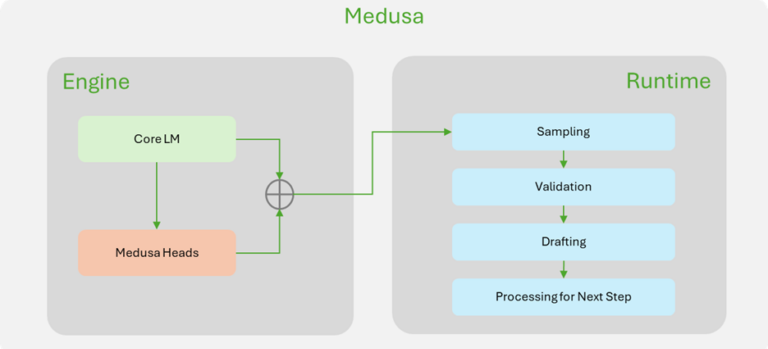
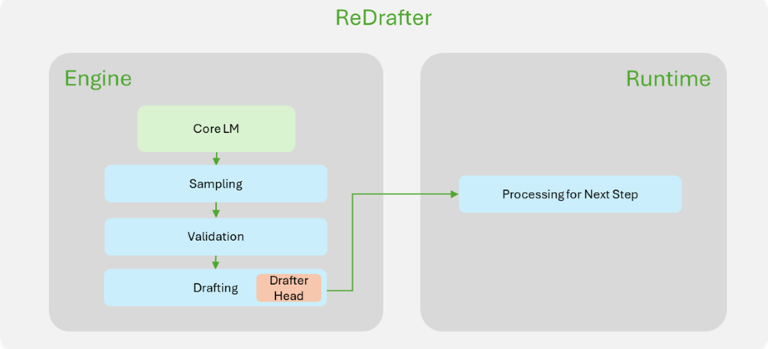
图 1. NVIDIA TensorRT-LLM 中
Medusa(左)和 ReDrafter(右)实现的比较
下面将深入探讨有助于在 TensorRT-LLM 中启用 ReDrafter 的一些变化。
兼容 Inflight-batching
批处理的引擎
Inflight-batching (IFB) 是一种通过批量处理上下文阶段和生成阶段请求,来显著提高吞吐量的策略。鉴于上下文阶段请求与生成阶段请求的处理方式不同(生成阶段请求需要 draft token 验证),因此结合 IFB 的推测解码会给管线带来更大的复杂性。ReDrafter 将验证逻辑移至模型定义内部,因此引擎在验证过程中也需要该逻辑。与注意力插件类似,该批处理被分成两个较小的批处理:一个用于上下文请求,另一个用于生成请求。然后,每个较小的批处理进入计算工作流,最后再合并成一个批处理进行 drafting 流程。
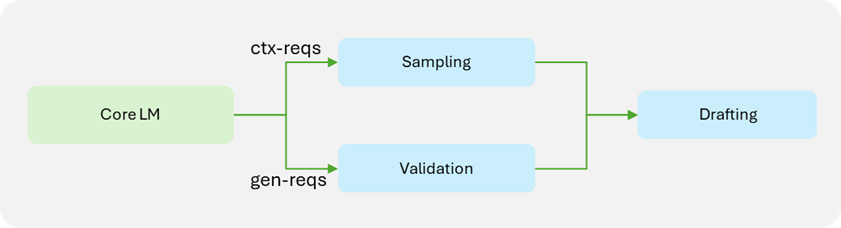
图 2. ReDrafter 兼容 TensorRT-LLM 引擎的
Inflight-batching 批处理计算工作流
请注意,这种方法要求任一路径上的所有运算符都支持空张量。如果一个批处理由所有上下文请求或所有生成请求组成,就可能出现空张量。该功能增加了 TensorRT-LLM API 的灵活性,使未来定义更复杂的模型成为可能。
实现引擎内验证和 Drafting
为了在引擎内进行验证和 draft,TensorRT-LLM 更新时加入了对许多新操作的支持,这样 PyTorch 代码就可以轻松地转化成一个 TensorRT-LLM 模型的定义。
以下 PyTorch 代码摘录是苹果公司的 PyTorch 实现的 ReDrafter。TensorRT-LLM 实现几乎就是 PyTorch 版本的直接逐行映射。
PyTorch
def unpack( packed_tensor: torch.Tensor, unpacker: torch.Tensor, ) -> torch.Tensor: assert len(packed_tensor.shape) == 3 last_dim_size = packed_tensor.shape[2] batch_size, beam_width, beam_length = unpacker.shape unpacked_data_indices = unpacker.view( batch_size, beam_width * beam_length, 1).expand( -1, -1, last_dim_size ) unpacked_tensor = torch.gather( packed_tensor, 1, unpacked_data_indices).reshape( batch_size, beam_width, beam_length, -1 ) return unpacked_tensor
TensorRT-LLM
def _unpack_beams( x: Tensor, indices: Tensor, num_beams: int, beam_length: int ) -> Tensor: assert x.rank() == 3 d0 = shape(x, 0, INT_DTYPE_STR) dl = shape(x, -1, INT_DTYPE_STR) indices = view( indices, [-1, num_beams * beam_length, 1], False) res_shape = concat([d0, num_beams, beam_length, dl]) res = view(gather_nd(x, indices), res_shape, False) return res
当然,这只是一个非常简单的例子。如要了解更复杂的示例,请参见束搜索实现。借助为 ReDrafter 添加的新功能,就可以改进 TensorRT-LLM 中的 Medusa 实现,从而进一步提高其性能。
ReDrafter
在 TensorRT-LLM 中的性能
根据苹果公司的基准测试,在采用 TP8 的 NVIDIA GPU 上使用 TensorRT-LLM 的 ReDrafter 最多可将吞吐量提高至基础 LLM 的 2.7 倍。
请注意,任何推测解码技术的性能提升幅度都会受到诸多因素的大幅影响,包括:
GPU 利用率:推测解码通常用于低流量场景,由于批量较小,GPU 资源的利用率通常较低。
平均接受率:由于推测解码必须执行额外的计算,而其中很大一部分计算最终会在验证后被浪费,因此每个解码步骤的延迟都会增加。所以要想通过推测解码获得任何性能上的优势,平均接受率必须高到足以弥补增加的延迟。这受到束数量、束长度和束搜索本身质量(受训练数据影响)的影响。
任务:在某些任务(例如代码完成)中预测未来的 token 更容易,使得接受率更高,性能也会因此而提升。
总结
NVIDIA 与苹果公司的合作让 TensorRT-LLM 变得更加强大和灵活,使 LLM 社区能够创造出更加复杂的模型并通过 TensorRT-LLM 轻松部署,从而在 NVIDIA GPU 上实现无与伦比的性能。这些新特性带来了令人兴奋的可能性,我们热切期待着社区使用 TensorRT-LLM 功能开发出新一代先进模型,进一步改进 LLM 工作负载。
-
如何在 NVIDIA TensorRT-LLM 中支持 Qwen 模型2023-12-04 957
-
如何利用LLM做一些多模态任务2023-05-17 868
-
NVIDIA TensorRT与Apache Beam SDK的集成2023-07-05 452
-
学习资源 | NVIDIA TensorRT 全新教程上线2023-08-04 835
-
阿里云 & NVIDIA TensorRT Hackathon 2023 决赛圆满收官,26 支 AI 团队崭露头角2023-10-17 503
-
周四研讨会预告 | 注册报名 NVIDIA AI Inference Day - 大模型推理线上研讨会2023-10-26 354
-
现已公开发布!欢迎使用 NVIDIA TensorRT-LLM 优化大语言模型推理2023-10-27 977
-
TensorRT-LLM初探(一)运行llama2023-11-16 1237
-
点亮未来:TensorRT-LLM 更新加速 AI 推理性能,支持在 RTX 驱动的 Windows PC 上运行新模型2023-11-16 674
-
NVIDIA加速微软最新的Phi-3 Mini开源语言模型2024-04-28 559
-
魔搭社区借助NVIDIA TensorRT-LLM提升LLM推理效率2024-08-23 442
-
NVIDIA Nemotron-4 340B模型帮助开发者生成合成训练数据2024-09-06 310
-
TensorRT-LLM低精度推理优化2024-11-19 295
-
NVIDIA TensorRT-LLM Roadmap现已在GitHub上公开发布2024-11-28 267
-
解锁NVIDIA TensorRT-LLM的卓越性能2024-12-17 143
全部0条评论

快来发表一下你的评论吧 !
