

一种可以编辑图像或重建已损坏图像的深度学习方法
电子说
描述
英伟达的研究人员发布了一种可以编辑图像或重建已损坏图像的深度学习方法,实现了一键P图,而且“毫无ps痕迹”。通过使用“部分卷积”层,该方法优于其他方法。
在计算机视觉研究领域,NVIDIA常常让人眼前一亮。
比如“用Progressive Growing的方式训练 GAN,生成超逼真高清图像”,“用条件 GAN 进行 2048x1024 分辨率的图像合成和处理”的pix2pixHD项目,或者脑洞大开的让晴天下大雨、小猫变狮子、黑夜转白天的“无监督图像翻译网络”(Unsupervised Image-to-Image Translation Networks)。
近日,NVIDIA在arXiv放出一篇今年ICLR的论文,同样很厉害。论文题为“Image Inpainting for Irregular Holes Using Partial Convolutions”,即使用“Partial Convolutions”进行图像修复。
在视频中左侧的操作界面,只需用工具将图像中不需要的内容简单涂抹掉,哪怕形状很不规则,NVIDIA的模型能够将图像“复原”,用非常逼真的画面填补被涂抹的空白。可谓是一键P图,而且“毫无ps痕迹”。
该研究来自Nvidia的Guilin Liu等人的团队,他们发布了一种可以编辑图像或重建已损坏图像的深度学习方法,即使图像穿了个洞或丢失了像素。这是目前state-of-the-art的方法。

该方法还可以通过移除图像中的某些内容,并填补移除内容后造成的空白,从而实现编辑图像。
这个过程叫做“image inpainting”,可以在图片编辑软件中实现去除不需要的内容,同时用计算机生成的逼真的替代方式填补空白。
图:被遮盖的图像,及使用基于部分卷积的网络得到的修复结果
“我们的模型可以很好地处理任何形状、大小、位置或距离图像边界任何距离的空白。以前的深度学习方法主要集中在位于图像中心附近的矩形区域,并且通常需要依赖成本很高的后期处理。“英伟达的研究人员在他们的研究报告中写道,“此外,我们的模型能够很好地处理越来越大的空白区域。”
为了训练神经网络,研究团队首先生成了55116个随机色条、形状和大小任意的masks,用于训练。他们还生成了25000个图像用于测试。为了提高重建图像的精度,研究人员根据相对于输入图像的大小,将这些训练图像进一步分为6类。
图:一些用于测试的masks
使用NVIDIA Tesla V100 GPU和cuDNN加速的PyTorch深度学习框架,该团队通过将生成的mask应用在ImageNet数据集Places2和CelebA-HQ两个数据集的图像,训练其神经网络。
图:ImageNet上的测试结果对比
图:Place2数据集上的测试结果对比
在训练阶段,将空白或缺失的部分引入上述数据集的完整训练图像中,以使网络能够学习重建缺失的像素。
在测试阶段,另一批没有在训练期间使用的空白或缺失部分被引入数据集里的测试图像,以对重建的图像的精度进行无偏验证。
图:基于典型卷积层的结果(Conv)和“部分卷积”层的结果(PConv)对比
研究人员表示,现有的基于深度学习的图像修复方法不够好,因为丢失像素的输出必然取决于输入的值,而这些输入必须提供给神经网络,以找出丢失的像素。这就导致图像中出现诸如颜色差异或模糊之类的artifacts。
为了解决这个问题,NVIDIA团队开发了一种方法,确保丢失像素的输出不依赖于为这些像素提供的输入的值。这种方法使用一个“部分卷积”层,根据其对相应的接受域(receptive field)的有效性,对每个输出进行重新归一化(renormalization)。这种重新归一化可以确保输出值与每个接受域中缺失像素的值无关。
该模型是利用这些部分卷积实现的UNet架构构建的。使用一组损失函数,匹配VGG模型的特征损失以及风格损失,进而训练模型以产生逼真的输出。
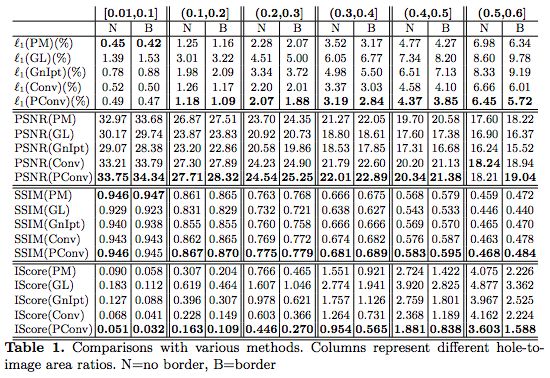
表:各种不同方法的结果对比
研究团队称,该模型优于以前的方法。
“据我们所知,我们是第一个在不规则形状的孔洞上展示深度学习图像修复模型效果的人,”NVIDIA的研究人员说。
研究人员还在论文中提及,相同的框架也可以用来处理图像超分辨率任务。
-
基于深度图像重建Matlab代码2017-09-15 972
-
讨论纹理分析在图像分类中的重要性及其在深度学习中使用纹理分析2022-10-26 0
-
单帧图像重建方法2018-02-02 881
-
基于邻域特征学习的单幅图像超分辨重建2018-02-07 760
-
一种新型分割图像中人物的方法,基于人物动作辨认2018-04-10 5657
-
NVIDIA一种先进的深度学习方法可用于对图像进行编辑2018-05-09 4708
-
到底谁可以产生更好的图像修复结果?什么是图像修补?2018-10-18 12144
-
使用多孔卷积神经网络解决机器学习的图像深度不准确的方法说明2019-10-30 873
-
深度学习中图像分割的方法和应用2020-11-27 3177
-
详解深度学习之图像分割2021-01-06 3688
-
图像分割的方法,包括传统方法和深度学习方法2021-01-08 9317
-
一种多粒度融合的模糊规则系统图像特征学习算法2021-03-31 745
-
一种改进的基于LRC-SNN的图像重建与识别算法2021-04-01 977
-
通过深度学习的图像三维物体重建研究方案2023-02-13 767
-
一种无需训练的深度电阻抗图像重建方法2023-02-21 1078
全部0条评论

快来发表一下你的评论吧 !
