

SSL方法是否适用于“现实世界”的环境?
电子说
描述
半监督学习(Semi-supervised learning,SSL)提供了一个强大的框架,可以在标记有限或昂贵的情况下利用无标记数据。近期,基于深度神经网络的SSL算法已被证明在标准基准任务上是成功的。然而,我们认为,这些基准无法解决这些算法在实际应用程序中遇到的许多问题。在对各种广泛使用的SSL技术进行了统一重新实现(unified reimplemention)之后,我们在一组旨在解决这些问题的实验中对它们进行了测试。我们发现:不使用无标记数据的简单基线的性能经常被低估;SSL方法对标记数据和无标记数据数量的敏感性不同;当无标记数据集包含类外的样本时,其性能会大幅降低。为了帮助指导SSL研究在现实世界的实际应用,我们开源了我们的统一重新实现和评估平台。
深度神经网络已经一再被表明,可以通过利用大量标记数据,在某些监督学习问题上达到人类水平或超越人类水平的性能。然而,这些成功有着不同的代价;也就是说,创建这些大型数据集通常需要大量的人力(以手工对样本增添标记)、痛苦或风险(对于涉及侵入性测试的医疗数据集)或财务费用(用于雇佣标记标注者或构建在特定领域收集数据所需的基础设施)。对于许多实际问题和应用程序来说,没有足够的资源来创建足够大的标记数据集,这限制了深度学习技术的广泛采用。
有一个具有吸引力的方法可以缓解这个问题,就是半监督学习(semi-supervised learning,SSL)框架。与需要所有样本都有标记的监督学习(supervised learning)算法相反,SSL算法可以通过使用无标记样本来提高其性能。SSL算法通常提供一种从无标记样本中学习数据结构的方法,这可以减轻对标记的需求。最近的一些研究结果表明,在某些情况下,SSL能够接近纯粹监督学习的性能,即使在给定的数据集中有很大一部分的标记被丢弃。
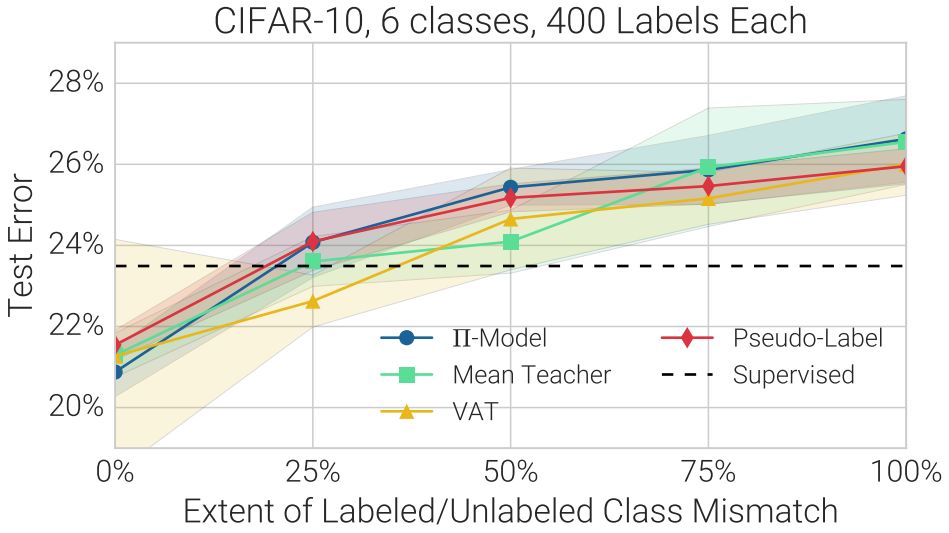
每种SSL技术在CIFAR-10(六类动物)上的测试误差,其中,在标记数据与无标记数据之间,存在不同程度的重叠。例如,“25%”是指来自不同类的4种无标记数据之一,而非来自标记数据的6类。“监督”是指不使用无标记数据。阴影区域表示5次试验的标准偏差。
这些最近的成功引出了一个自然的问题:SSL方法是否适用于“现实世界”的环境?在本文中,我们认为,当前评估SSL技术的实际方法并不能以令人满意的方式解决这个问题。具体而言,采用大型标记数据集并丢弃许多标记的标准评估程序没有考虑到SSL应用程序的各种常见特征。我们的目标是通过提出一种新的实验方法来更直接地解决这个问题,我们认为该方法能够更好地测量对现实世界问题的适应性。我们的一些发现包括:
•当给予调优超参数(hyperparameter)相同预算时,使用SSL和使用标记数据之间的性能差距比通常记录的差距要小。
•此外,使用无标记数据的大型、高度正则化的分类器的强大性能证明了在同一个基础模型上评估不同SSL算法的重要性。
•在不同的标记数据集上对分类器进行预先训练,然后仅在利益相关数据集中的标记数据上进行再训练,这可以胜过所有我们研究过的SSL算法。
•当无标记数据包含与标记数据不同的类分布时,SSL技术的性能可能会急剧下降。
•不同的方法对标记数据和无标记数据数量的敏感度有很大不同。
•实际的小型验证集(validation set)会妨碍对不同方法、模型和超参数设置进行可靠的比较。
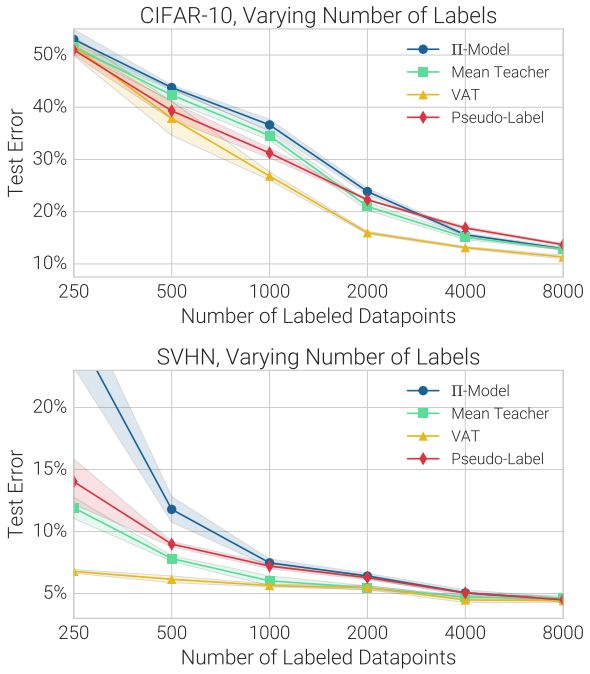
在SVHN和CIFAR-10中,每种SSL技术的测试误差都随标记数据量的变化而变化。阴影区域表示5次实验的标准偏差。X轴采用对数形式表示
此外,与机器学习中的许多领域一样,对超参数、模型结构及训练的微小调整,都会对方法的直接比较构成混淆,并对结果产生重大影响。为了改善这一问题,我们提出了关于各种SSL方法的统一的、模块化的重新实现,这些方法也使得我们的评估技术成为现实。
结论与建议
我们的实验提供了有力的证据,证明SSL的标准评估实践是不现实的。为了更好地反应在现实世界中的应用,我们应该对评估进行哪些改进呢?我们对SSL算法的评估有以下建议:
•在比较不同的SSL方法时,使用完全相同的基础模型。因为模型结构或实现细节的差异会对结果产生很大影响。
•报告需认真评估对完全监督精确度和迁移学习性能的要求,以将其作为基准。SSL的目标应该定为,显著优于完全监督环境下的综合表现。
•对类分布失协情况的系统性变化的结果进行报告。 我们表明,当采用是不同类的无标记数据,而非标记数据时,我们对SSL技术的研究受到了影响。据我们了解,这一现实问题被严重忽略了。
•在评估性能时,应调整标记数据和无标记数据的数量。理想的SSL算法即使在标记数据很少的情况下也是非常有效的,并且它还可以从额外的无标记数据中受益。具体而言,我们建议将SVHN和SVHN-extract相结合,来测试大型无标记数据机制的性能。
•注意,不要在非真实的大型验证集上过度调节超参数。如果验证集非常小,那么为了获得理想的性能而在每个模型或每个任务基础上,对超参数进行重大调整的SSL方法将不可用。
我们的研究还表明,面对以下情况时,SSL或许是研究人员最正确的选择:
•当没有来自类似域的高质量标记数据集用于微调时。
•当标记数据是通过独立同分布(i.i.d)采样,从无标记数据集中采集得到,而不是从不同分布中收集得来时。
•当标记的数据集足够大,能够准确计算验证精确度时(这是进行模型选择和超参数调优所必须的条件)。
近来,SSL收获了巨大的成功。我们希望我们的研究成果,以及公开可用的统一实现,能够让成功之花在现实世界中遍地绽放。
-
是否有适用于CYBT-343026-01的SPICE型号?2024-03-01 0
-
LMP91051是否适用于Pyreos的双通道?2024-08-19 0
-
适用于高性能运算的处理器2016-03-14 0
-
FMC是否适用于ML507?2020-06-12 0
-
适用于所有atmega328p项目的通用板2022-08-29 0
-
STM32L073RZ是否适用于近地轨道运行环境?2023-02-07 0
-
是否有适用于LPC4078的SVD文件?2023-03-29 0
-
是否有适用于LPC4357的替代屏幕?2023-06-02 0
-
是否有适用于LS1046ARDB上的Secure JTAG的任何应用说明?2023-06-08 0
-
泰科电子推出适用于LED印刷威廉希尔官方网站 板上全新的IDC SSL连接2010-04-20 650
-
基于一种适用于SSL产品的LED控制威廉希尔官方网站 设计2019-11-27 1177
-
适用于恶劣环境的产品2021-05-27 658
-
工业加固三防平板适用于哪些环境2021-07-12 834
-
UltraFAST设计方法指南(适用于Vivado Design Suite)2023-09-13 336
-
UltraFAST设计方法指南(适用于Vivado Design Suite)2023-09-15 297
全部0条评论

快来发表一下你的评论吧 !
