

对于机器学习/数据科学初学者 应该掌握的七种回归分析方法
电子说
描述
对于机器学习/数据科学的初学者来说,线性回归,或者Logistic回归是许多人在建立预测模型时接触的第一/第二种方法。由于这两种算法适用性极广,有些人甚至在走出校门当上数据分析师后还固执地认为回归只有这两种形式,或者换句话说,至少线性回归和Logistic回归应该是其中最重要两个算法。那么事实真的是这样吗?
Sunil Ray是一位在印度保险行业拥有丰富经验的商业分析师和人工智能专家,针对这个问题,他指出其实回归有无数种形式,每种回归算法都有自己擅长的领域和各自的特色。在本文中,他将以最简单的形式介绍7种较为常见的回归形式,希望读者们在耐心阅读完毕后,可以在学习、工作中多做尝试,而不是无论遇到什么问题都直接上“万金油”的线性回归和Logistic回归。
目录
1. 什么是回归分析?
2. 为什么要用回归分析?
3. 几种常见的回归分析方法
线性回归
Logistic回归
多项式回归
逐步回归
岭回归
Lasso回归
ElasticNet回归
4. 如何挑选适合的回归模型?
什么是回归分析?
回归分析是一种预测建模技术,它可以被用来研究因变量(目标)和自变量(预测)之间的关系,常见于预测建模、时间序列建模和查找变量间关系等应用。举个例子,通过回归分析,我们能得出司机超速驾驶和发生交通事故次数之间的关系。
它是建模和分析数据的重要工具。回归分析在图像上表示为一条努力拟合所有数据点的曲线/线段,它的目标是使数据点和曲线间的距离最小化。
为什么要用回归分析?
如上所述,回归分析估计的是两个或两个以上变量间的关系。我们可以举这样一个例子来帮助理解:
假设A想根据公司当前的经济状况估算销售增长率,而最近一份数据表明,公司的销售额增长约为财务增长的2.5倍。在此基础上,A就能基于各项数据信息预测公司未来的销售情况。
使用回归分析有许多优点,其中最突出的主要是以下两个:
它能显示因变量和自变量之间的显著关系;
它能表现多个独立变量对因变量的不同影响程度。
除此之外,回归分析还能揭示同一个变量带来的不同影响,如价格变动幅度和促销活动多少。它为市场研究人员/数据分析师/数据科学家构建预测模型提供了评估所用的各种重要变量。
几种常见的回归分析方法
回归分析的方法有很多,但其中出名的没几个。综合来看,所有方法基本上都由这3个重要参数驱动:自变量的数量、因变量的类型和回归曲线的形状。
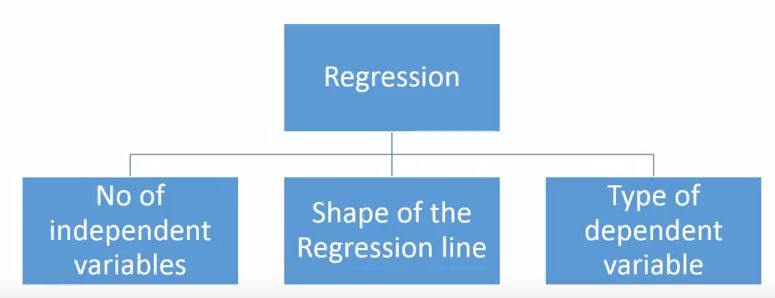
至于为什么是这三点,我们会在后文作出具体解释。当然,对于那些有创意、能独立设计参数的人,他们的模型大可不必局限于这些参数。这只是以前大多数人的做法。
1. 线性回归
线性回归是知名度最广的建模方法之一。每当提及建立一个预测模型,它总能占一个首选项名额。对于线性回归,它的因变量是连续的,自变量则可以是连续的或是离散的。它的回归线在本质上是线性的。
在一元问题中,如果我们要用线性回归建立因变量Y和和自变量X之间的关系,这时它的回归线是一条直线,如下图所示。
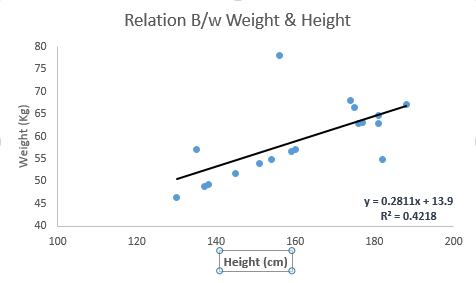
它的相应表达式为:Y = a + b × X + e。其中a是y轴截距,b是回归线斜率,e是误差项。
但有时我们可能拥有不止一个自变量X,即多元问题,这时多元线性回归的回归方程就是一个平面或是一个超平面。
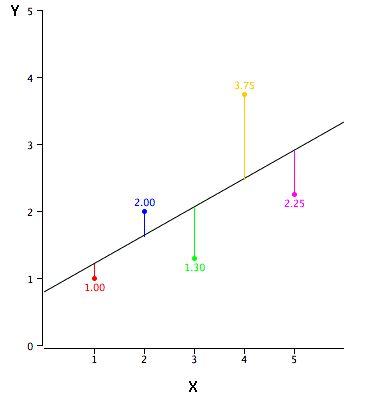
既然有了一条线,那我们如何确定拟合得最好的那条回归线呢(a和b的值)?对于这个问题,最常规的方法是最小二乘法——最小化每个点到回归线的欧氏距离平方和。由于做了平方,距离不存在正负差别影响。
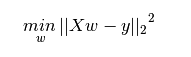
线性回归重点:
自变量和因变量之间必须存在线性关系;
多元回归受多重共线性、自相关和异方差影响;
线性回归对异常值非常敏感。它会严重影响回归线,并最终影响预测值。
多重共线性会使参数估计值的方差增大,可能会过度地影响最小二乘估计值,从而造成消极影响。
在存在多个自变量的情况下,我们可以用前进法、后退法和逐步法选择最显著的自变量。
2. Logistic回归
Logistic回归一般用于判断事件成功/失败的概率,如果因变量是一个二分类(0/1,真/假,是/否),这时我们就应该用Logistic回归。它的Y是一个值域为[0, 1]的值,可以用下方等式表示:
odds = p/ (1-p) = 事件发生概率 / 事件未发生概率 ln(odds) = ln(p/(1-p)) logit(p) = ln(p/(1-p)) = b0+b1×1+b2×2+b3×3....+bk×k
在上式中,p是目标特征的概率。不同于计算平方和的最小值,这里我们用的是极大似然估计,即找到一组参数θ,使得在这组参数下,样本数据的似然度(概率)最大。考虑到对数损失函数与极大似然估计的对数似然函数在本质上是等价的,所以Logistic回归使用了对数函数求解参数。
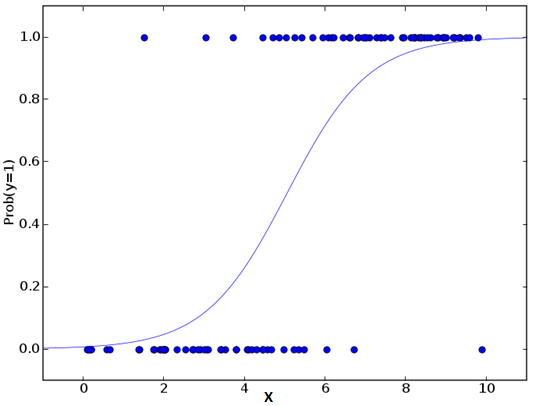
Logistic回归重点:
Logistic回归被广泛用于分类问题。
Logistic回归无需依赖自变量和因变量之间的线性关系,而是用非线性对数计算用于预测的比值比,因此可以处理各种类型的问题。
为了避免过拟合和欠拟合,Logistic回归需要包含所有重要变量,然后用逐步回归方法去估计逻辑回归。
Logistic回归对样本大小有较高要求,因为对于过小的数据集,最大似然估计不如普通最小二乘法。
各自变量间不存在多重共线性。
如果因变量的值是序数,那么它就该被称为序数Logistic回归。
如果因变量是多个类别,那么它就该被称为多项Logistic回归。
3. 多项式回归
多项式回归是对线性回归的补充。线性回归假设自变量和因变量之间存在线性关系,但这个假设并不总是成立的,所以我们需要扩展至非线性模型。Logistic回归采取的方法是用非线性的对数函数,而多项式回归则是把一次特征转换成高次特征的线性组合多项式。
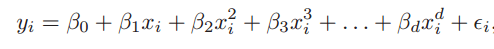
一元多项式回归
简而言之,如果自变量的幂大于1,那么该回归方程是多项式回归方程,即Y = A + B × X2。在这种回归方法中,它的回归线不是一条直线,而是一条力争拟合所有数据点的曲线。
多项式回归重点:
尽管更高阶的多项式回归可以获得更低的误差,但它导致过拟合的可能性也更高。
要注意曲线的方向,观察它的形状和趋势是否有意义,在此基础上在逐步提高幂。
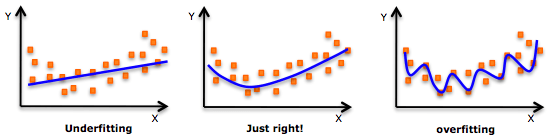
过拟合
4. 逐步回归
截至目前,上述方法都需要针对因变量Y选择一个目标自变量X,再用线性的、非线性的方法建立“最优”回归方程,以便对因变量进行预测或分类。那么当我们在处理多个自变量时,有没有一种回归方法能按照对Y的影响大小,自动筛选出那些重要的自变量呢?
这种方法就是本节要介绍的逐步回归,它利用观察统计值(如R方,t-stats和AIC度量)来辨别重要变量。作为一种回归分析方法,它使用的方法是基于给定的水平指标F一次一个地添加/丢弃变量,以下是几种常用的做法:
标准的逐步回归只做两件事:根据每个步骤添加/删除变量。
前进法:基于模型中最重要的变量,一次一个添加剩下的变量中最重要的变量。
后退法:基于模型中所有变量,一次一个删除最不重要的变量。
这种建模方法的目的是用尽可能小的变量预测次数来最大化预测能力,它是处理更高维数据集的方法之一。
5. 岭回归
在谈及线性回归重点时,我们曾提到多重共线性会使参数估计值的方差增大,并过度地影响最小二乘估计值,从而降低预测精度。因此方差和偏差是导致输出值偏离真值的罪魁祸首之一。
我们先来回顾一下线性回归方程:Y = a + b × X + e。
如果涉及多个自变量,那它是:Y = a + Y = a + b1X1 + b2X2 + … + e
上式表现了偏差和误差对最终预测值的明显影响。为了找到方差和偏差的折中,一种可行的做法是在平方误差的基础上增加一个正则项λ,来解决多重共线性问题。请看以下公式:
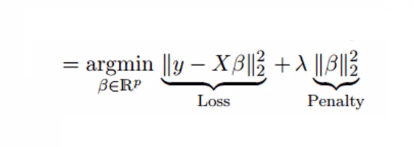
这个代价函数可以被分为两部分,第一部分是一个最小二乘项,第二部分则是系数β的平方和,再乘以一个调节参数λ作为惩罚项,它能有效控制方差和偏差的变化:随着λ的增大,模型方差减小而偏差增大。
岭回归重点:
岭回归的假设与最小二乘法回归的假设相同,除了假设正态性。
岭回归可以缩小系数的值,但因为λ不可能为无穷大,所以它不会等于0。
这实际上是一种正则化方法,使用了l2范数。
6. Lasso回归
同样是解决多重共线性问题,岭回归是在平方误差的基础上增加一个正则项λ,那么Lasso回归则把二次项改成了一次绝对值。它可以降低异常值对模型的影响,并提高整体准确度。
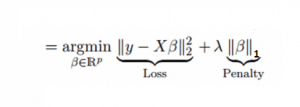
一次项求导可以抹去变量本身,因此Lasso回归的系数可以为0。这样可以起来真正的特征筛选效果。
Lasso回归重点:
Lasso回归的假设与最小二乘法回归的假设相同,除了假设正态性。
Lasso回归的系数可以为0。
这实际上是一种正则化方法,使用了l1范数。
如果一组变量高度相关,Lasso回归会选择其中的一个变量,然后把其他的都变为0。
7. ElasticNet回归
ElasticNet是Lasso和Ridge回归技术的结合。它使用L1和L2范数作为惩罚项,既能用于权重非零的稀疏模型,又保持了正则化属性。简单来说,就是当有多个相关特征时,Lasso回归只会选择其中的一个变量,但ElasticNet回归会选择两个。
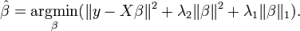
在Lasso和Ridge之间进行权衡的一个实际优势是,它允许Elastic-Net继承岭回归的一些稳定性。
ElasticNet回归重点:
它鼓励在高度相关变量的情况下的群体效应。
在选择变量的数量上没有限制。
受双重收缩影响。
除了这7中常用的回归分析方法外,贝叶斯回归、生态学回归和鲁棒回归也是出镜率很高的一些选择。
如何挑选适合的回归模型?
当你只知道一种或两种方法时,生活通常很简单。相信不少读者都听到过这种论调:如果结果是连续的,用线性回归;如果是个二分类,就用Logistic回归。然而随着现在我们的选择越来越多,许多人不免要深受选择恐惧症影响,无法做出满意的决定。
那么面对这么多的回归分析方法,我们该怎么选择呢?以下是一些可以考虑的关键因素:
数据探索是构建预测模型不可或缺的一部,因此在选择正确的模型前,我们可以先分析数据,找到变量间的关系。
为了比较不同方法的拟合成都,我们可以分析统计显著性参数、R方、调整R方、最小信息标准、BIC和误差准则等统计值,或者是Mallow‘s Cp准则。将模型与所有可能的子模型进行比较来检查模型中可能存在的偏差。
交叉验证是评估预测模型最好的方法没有之一。
如果你的数据集中有多个奇怪变量,你最好手动添加而不要用自动的方法。
杀鸡焉用牛刀。根据你的任务选择强大/不强大的模型。
岭回归、Lasso回归和ElasticNet回归在高维度、多重共线性情况下有较好的表现。
-
DSP5509A这个芯片,对于初学者应该从哪里开始学习啊???2013-08-14 0
-
初学者如何快速掌握2014-04-22 0
-
初学者之路—硬件学习经验2011-12-29 14558
-
HDL初学者谨记:学习HDL前必知2012-10-15 2748
-
cad初学者应该注意的问题2012-10-18 1666
-
verilog初学者学习ppt2016-03-25 591
-
电子学习资料[适初学者]2017-02-08 1411
-
九张机器学习和深度学习代码速查表分享_初学者必备2018-06-30 4079
-
机器学习的初学者必看指南2017-11-15 6996
-
最适合初学者的机器人有哪些2020-02-05 4035
-
学习机器学习的方法及如何运用Python2020-08-07 927
-
fpga开发板推荐初学者2020-11-10 18933
-
给Linux初学者的一些经验与建议与学习方法及其学习方向2021-03-19 2935
-
FPGA初学者必读文档2021-08-04 919
-
PLC初学者必须掌握的梯形图2023-05-25 990
全部0条评论

快来发表一下你的评论吧 !
