

简单好上手的图像分类教程!
电子说
描述
今天,Google AI再次放出大招,推出一个专注于机器学习实践的“交互式课程”,第一门是图像分类机器学习实践,已有超过10000名谷歌员工使用这个教程构建了自己的图像分类器。内容简明易上手,不妨来试。
几个月前,Google AI教育项目放出大福利,将内部机器学习速成课程(MLCC)免费开放给所有人,以帮助更多开发人员学习和使用机器学习。
今天,Google AI再次放出大招,推出一个专注于机器学习实践的“交互式课程”。公开的第一门课程是谷歌AI团队与图像模型方面的专家合作开发的图像分类机器学习实践。
这个动手实践课程包含视频、文档和交互式编程练习,分步讲解谷歌最先进的图像分类模型是如何开发出来的。这一图像分类模型已经在Google相册的搜索功能中应用。迄今为止,已经有超过10000名谷歌员工使用这个实践指南来训练自己的图像分类器,识别照片上的猫和狗。
在这个交互式课程中,首先,你将了解图像分类是如何工作的,学习卷积神经网络的构建模块。然后,你将从头开始构建一个CNN,了解如何防止过拟合,并利用预训练的模型进行特征提取和微调。
机器学习实践:图像分类
学习本课程,你将了解谷歌state-of-the-art的图像分类模型是如何开发出来的,该模型被用于在Google Photos中进行搜索。这是一个关于卷积神经网络(CNN)的速成课程,在学习过程中,你将自己构建一个图像分类器来区分猫的照片和狗的照片。
预计完成时间:90~120 分钟
先修要求
已学完谷歌机器学习速成课程,或有机器学习基本原理相关的经验。
精通编程基础知识,并有一些Python编程的经验
在2013年5月,谷歌发布了对个人照片进行搜索的功能,用户能够根据照片中的对象在自己的相册中检索相应的照片。
在相册中搜索包含暹逻猫的照片
这一功能后来在2015年被Google Photos中,被广泛认为具有颠覆性的影响。这证明了计算机视觉软件可以按照人类的标准对图像进行分类,其价值包括:
用户不再需要用“beach”之类的标签手工地对照片内容进行分类,当需要管理几千张图片时,这一任务会变得非常繁琐。
用户可以用新的方式来探索他们的相册,使用搜索词来定位他们可能从未标记过的对象的照片。例如,他们可以搜索“棕榈树”,将所有背景中有棕榈树的度假照片放在一起。
软件可能会“看到”用户自己可能无法察觉的分类差别(例如,区分暹罗猫和阿比西尼亚猫),有效地增加了用户的专业知识。
图像分类是如何工作的
图像分类是一个有监督的学习问题:定义一组目标类(即图像中需要识别的对象),并使用已标记的示例照片来训练一个模型来识别目标。早期的计算机视觉模型依赖于原始的像素数据作为模型的输入。
然而,如下图所示,仅原始的像素数据并不能提供足够稳定的表示,以包含图像中捕获的无数个对象的细微变化。对象的位置、对象背后的背景、周围的光线、相机的角度和相机的焦点在原始像素数据中都可能产生波动;这些差异是非常重要的,它们不能通过对像素RGB值的加权平均来校正。
左:不同姿势、不同背景和光照条件的照片中,猫都可以被识别出来;右:用平均像素数据来解释这种变化无法产生任何有意义的信息
为了更灵活地对对象进行建模,经典的计算机视觉模型添加了来自像素数据的新特性,比如颜色直方图、纹理和形状。但这种方法的缺点是使特性工程变成了一种负担,因为需要调整的输入太多了。比如对于一个猫的分类器,哪种颜色最重要?形状的定义灵活度应该多大?由于特征需要非常精确地调整,构建一个稳定的模型非常具有挑战性,而且模型精度也会受到影响。
卷积神经网络
构建图像分类模型的一个突破是发现卷积神经网络(CNN)可以用来逐步地提取图像内容的更高层的表示。CNN不是预先处理数据以获得纹理、形状等特征,而是将图像的原始像素数据作为输入,并“学习”如何提取这些特征,最终推断它们构成的对象。
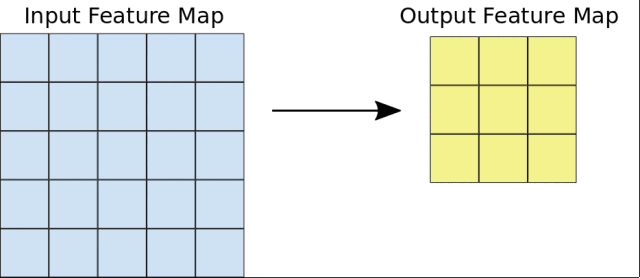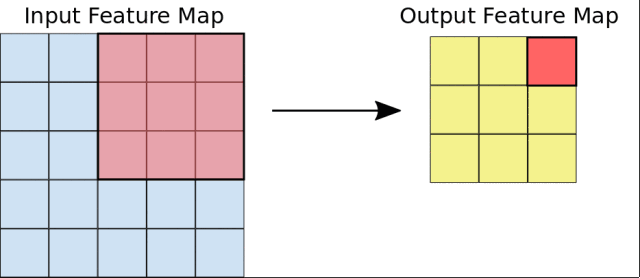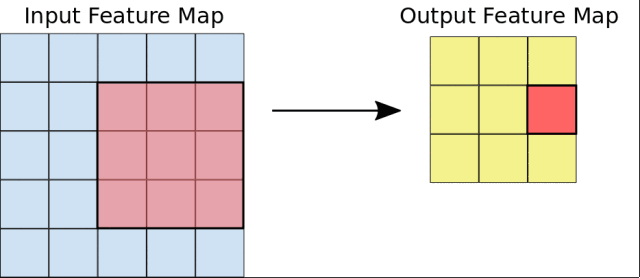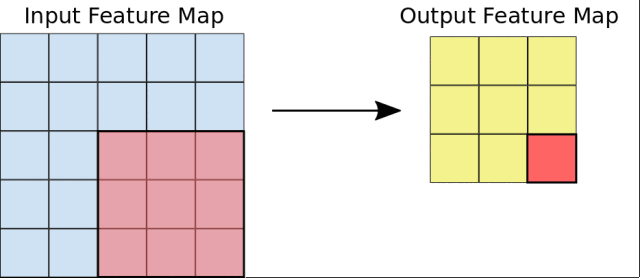
首先,CNN接受到一个输入特征图:一个三维矩阵,其中前两个维度的大小对应于像素图像的长度和宽度。第三个维度的大小为3(对应于彩色图像的3个通道:红、绿和蓝)。CNN包含许多个模块,每个模块执行三个操作。
CNN部分接下来分别讲解卷积、ReLU、Pooling和全连接层。接下来两节是“防止过拟合”和“利用预训练的模型”,并提供三个练习:
练习1:为猫-狗分类(Cat-vs-Dog Classification)建立一个卷积神经网络
在这个练习中,你将得到动手建一个卷积神经网络的实战经验,从头开始建立一个图像分类器来区分猫的照片和狗的照片。
练习2:防止过拟合
在这个练习中,你将进一步改进练习1中构建的猫狗分类CNN模型,运用数据增强和dropout 正则化。
练习3:特征提取和微调
在这个练习中,你将对谷歌的初始 Inception v3 模型进行特征提取和fine-tuning,以使你的猫狗分类模型达到更高精度。
-
基于多通道分类合成的SAR图像分类研究2010-04-23 0
-
区分图像的分类方法是什么2020-05-07 0
-
Edge Impulse的分类模型浅析2021-12-20 0
-
分享一下单片机和PLC哪个更好上手2022-02-16 0
-
一种新的图像定位和分类系统实现方案2009-07-30 691
-
基于Brushlet和RBF网络的SAR图像分类2009-12-18 609
-
图像分类的方法之深度学习与传统机器学习2017-09-28 1481
-
基于显著性检测的图像分类算法2018-01-04 581
-
Google图像分类速成ML实战课程2018-06-01 3646
-
相机图像质量的分类及应用2022-07-06 2301
-
图像分类任务的各种tricks2022-09-14 1165
-
如何区分图像分类和目标检测技术2023-07-11 521
-
TinyML变得简单:图像分类2023-07-13 703
-
CNN图像分类策略2023-12-25 293
-
计算机视觉怎么给图像分类2024-07-08 664
全部0条评论

快来发表一下你的评论吧 !
