

一种金字塔注意力网络,用于处理图像语义分割问题
电子说
描述

近日,北京理工大学、旷视科技、北京大学联手,发表了一篇名为 Pyramid Attention Network for Semantic Segmentation 的论文。在这篇论文中,四位研究者提出了一种金字塔注意力网络 (Pyramid Attention Network,PAN),利用图像全局的上下文信息来解决语义分割问题。
与大多数现有研究利用复杂的扩张卷积 (dilated convolution) 并人为地设计解码器网络不同的是,论文作者将注意力机制和空间金字塔(spatial pyramid)相结合,来提取准确而密集的特征并获取像素标签。
具体来说,他们引入了一个特征金字塔注意力模块 (Feature Pyramid Attention module),在高层的输出上施加空间金字塔注意力结构,并结合全局池化策略来学习更好的特征表征。此外,利用每个解码器层中的全局注意力上采样模块 (Global Attention Upsample module) 得到的全局上下文特征信息,作为低级别特征的指导,以此来筛选不同类别的定位细节。
论文作者表示,他们提出的方法在 PASCAL VOC 2012 数据集上实现了当前最佳的性能。而且无需经过 COCO 数据集的预训练过程,他们的模型在 PASCAL VOC 2012 和 Cityscapes 基准测试中能够实现了 84.0% mIoU。
▌引言
随着卷积神经网络 (CNN) 的发展,层次特征的丰富性及端到端的训练框架可用性,逐像素(pixel-wise)的语义分割问题的研究取得了显著的进步。但是,现有的研究对于高维度特征表征的编码效果仍不理想,导致原始场景中上下文像素的空间分辨率遭受损失。
如图1所示,全卷积神经网络 (Full Convolutional Network,FCN) 缺乏对场景中小部件的预测能力,图中第一排自行车的手柄消失了,而第二排中的羊被误认为牛。这对语义分割任务提出了挑战。首先是多尺度目标的存在会加大语义分割任务中类别分类的困难。为了解决这个问题,PSPNet 或 DeepLab 系统提出空间金字塔结构,旨在不同的网格尺度或扩张率下 (称之为空间金字塔池化,ASPP),融合多尺度的特征信息。在 ASPP 模块中,扩张卷积是一种稀疏计算,这可能会导致产生网格伪像 (grid artifacts)。而 PSPNet 中提出的金字塔池化模块则可能会丢失像素级别的定位信息。受 SENet 和 Parsenet 的启发,我们尝试从 CNN 的高层次特征中提取出准确的像素级注意力特征。图1展示了我们提出的特征金字塔注意力模块 (Feature Pyramid Attention,FPA)的能力,它能够扩大感受野的范围并有效地实现小目标的分类。

图1:VOC 数据集的可视化结果
上图中,正如我们所看到的,FCN 模型难以对小目标和细节进行预测。在第一排中自行车的手柄在预测中丢失了,而第二排中出现了错误的动物类别预测。我们的特征金字塔注意力模块 (FPA) 和全局注意力上采样 (GAU) 模块旨在扩大目标感受野并有效地恢复像素的定位细节。
另一个问题是,高层次的特征在对类别进行准确分类时非常有效,但在重组原始分辨率的二类预测问题方面比较薄弱。一些 U 型网络,如 SegNet,Refinenet 以及 Large Kernel Matters 能够在复杂的解码器模块中使用低层次信息来帮助高层次特征恢复图像细节。但是,这些方法都很耗时,运行效率不高。解决这个问题,我们提出了一种称为 Global Attention Upsample (GAU) 方法,这是一个有效的解码器模块,在不需要耗费过多计算资源的情况下,它可以提取高层次特征的全局上下文信息,作为低层次特征的加权计算的指导。
总的来说,我们的工作主要有以下三个贡献:
1. 我们提出一个特征金字塔注意模块,可以在基于 FCN 的像素预测框架中嵌入不同尺度的上下文特征信息。
2. 我们开发了一个高效的解码器模块 Global Attention Upsample,用于处理图像的语义分割问题。
3. 结合特征金字塔注意力模块和全局注意力上采样模块,我们的金字塔注意力网络在 VOC2012 和 cityscapes 的测试基准中取得了当前最佳的性能。
▌模型方法
特征金字塔注意力模块 FPA
基于以上观察,我们提出了特征金字塔注意力模块 (FPA),该模块能够融合来自 U 型网络 (如特征金字塔网络 FPN) 所提取的三种不同尺度的金字塔特征。为了更好地提取不同尺度下金字塔特征的上下文信息,我们分别在金字塔结构中使用 3×3, 5×5, 7×7 的卷积核。由于高层次特征图的分辨率较小,因此我们使用较大的内核并不会带来太多的计算负担。随后,金字塔结构逐步集成不同尺度下的特征信息,这样可以更准确地结合相邻尺度的上下文特征。然后,经过 1×1 卷积处理后,由 CNN 所提取的原始特征通过金字塔注意力特征进行逐像素相乘。此外,我们还引入了全局池化分支来联结输出的特征,这将进一步提高 FPA 模块的性能。整体的模块结构如下图 2 所示。得益于空间金字塔结构,FPA 模块可以融合不同尺度的上下文信息,同时还能为高层次的特征图提供更好的像素级注意力。
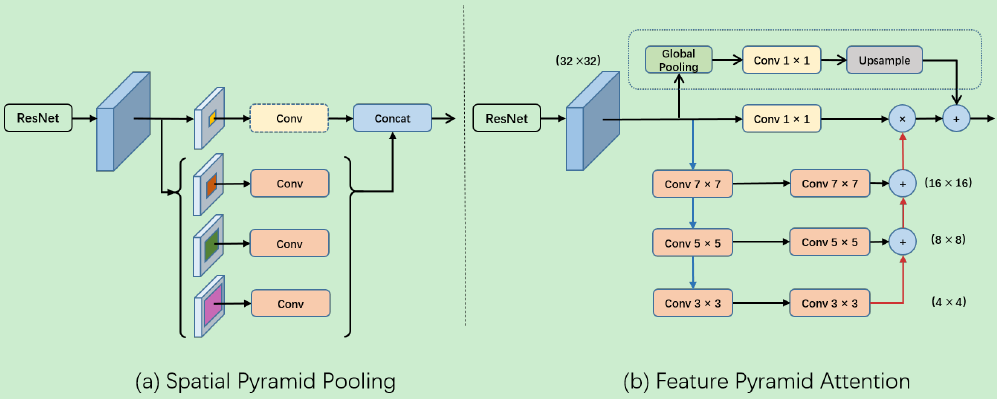
图2:特征金字塔注意力模块结构
上图中,(a) 空间金字塔池结构。(b) 特征金字塔注意力模块。 '4×4,8×8,16×16,32×32' 分别代表特征映射的不同分辨率。虚线框表示全局池化分支。蓝色和红色的线条分别代表下采样和上采样运算符。
全局注意力上采样模块 GAU
我们提出的全局注意力上采样模块 (Global Attention Upsample,GAU),通过全局池化过程将全局上下文信息作为低层特征的指导,来选择类别的定位细节。具体地说,我们对低层次特征执行 3×3 的卷积操作,以减少 CNN 特征图的通道数。从高层次特征生成的全局上下文信息依次经过 1×1 卷积、批量归一化 (batch normalization) 和非线性变换操作 (nonlinearity),然后再与低层次特征相乘。最后,高层次特征与加权后的低层次特征相加并进行逐步的上采样过程。我们的 GAU 模块不仅能够更有效地适应不同尺度下的特征映射,还能以简单的方式为低层次的特征映射提供指导信息。模块的结构示意图如下图3所示。
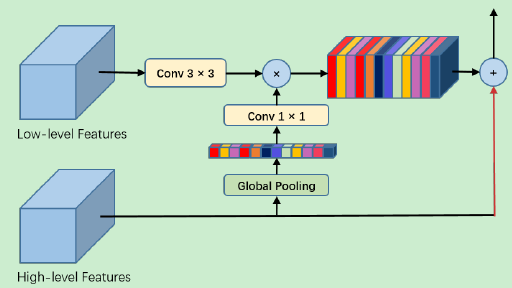
图3:全局注意力上采样模块
金字塔注意力网络 PAN
结合特征金字塔注意力模块 (FPA) 和全局注意力上采样模块 (GAU),我们提出金字塔注意力网络 (PAN),其结构示意图如下图 4 所示。我们使用在 ImageNet 数据集上预训练好的 ResNet-101 模型,辅以扩张卷积策略来提取特征图。具体地说,我们在 res5b 模块上应用扩张率为 2 的扩张卷积,以便 ResNet 输出的特征图大小为原输入图像的1/16,这与 DeepLabv3+ 模型中的设置是一致的。正如 PSPNet 和 DUC 模型那样,我们用三个 3×3 卷积层来取代原 ResNet-101 模型中的 7×7 卷积。此外,我们使用 FPA 模块来收集 ResNet 的输出中密集的像素级注意力信息。结合全局的上下文信息,经 GAU 模块后,生成最终的预测图。
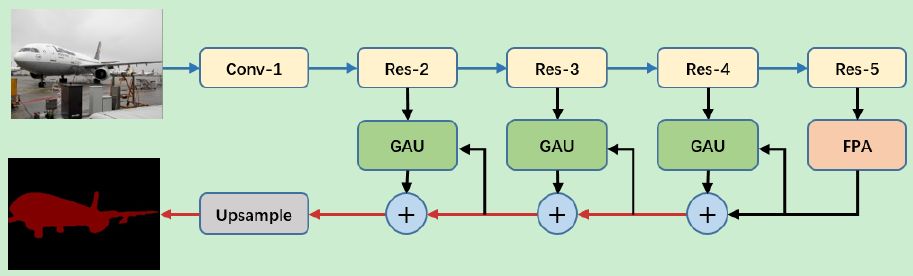
图4:金字塔注意力网络结构
上图中,我们使用 ResNet-101 模型来提取密集的特征。然后,我们分别执行 FPA 模块和 GAU 模块进行准确的像素预测并获取目标定位的细节。蓝线和红线分别代表下采样和上采样运算符。
我们将 FPA 模块视为编码器和解码器结构之间的中心模块。即使没有全局注意上采样模块,FPA 模块也能够进行足够准确的像素级预测和类别分类。在实现 FPA 模块后,我们将 GAU 模块视为一种快速有效的解码器结构,它使用高层次的特征来指导低层次的信息,并将二者结合起来。
▌实验结果
我们在 PASCAL VOC2012 和 cityscapes 数据集上分别评估了我们的方法。
Ablation Experiments
FPA 模块
我们分别对池化类型、金字塔结构、卷积核大小、全局池化四种设置进行了 Ablation Experiments 分析,结果如下:其中 AVE 表示平均池化策略,MAX 表示最大池化,C333 代表全部使用 3×3 的卷积核,C357 表示所使用的卷积核分别为 3×3、5×5 和 7×7,GP 代表全局池化分支,SE 表示使用 SENet 注意力模块。
池化类型:在这项工作中,我们发现 AVE 的性能要优于 MAX:对于 3×3 的卷积核设置,AVE 的性能能达到 77.54%,优于 MAX 所取得的77.13%。
金字塔结构:我们的模型在验证集上能取得 72.60% 的 mIoU。此外,我们使用 C333 和 AVE 时,模型的性能能够从 72.6% 提升至 77.54%。我们还使用 SENet 注意力模块来取代金字塔结构,进一步对比评估二者的性能。实验结果如下表1所示,与 SENet 注意力模块相比,C333 和 AVE 设置能将性能提高了近1.8%。
卷积核大小:对于使用平均池化的金字塔结构,我们使用 C357 取代 C333 卷积核设置,金字塔结构中特征映射的分辨率为 16×16,8×8,4×4。实验结果表明,模型性能能够从 77.54% 提高至 78.19%。
全局池化:我们进一步在金字塔结构中添加全局池化分支以提高模型性能。实验结果表明,在最佳设置下模型能够取得 78.37 的 mIoU 和 95.03% 的 Pixel Acc。
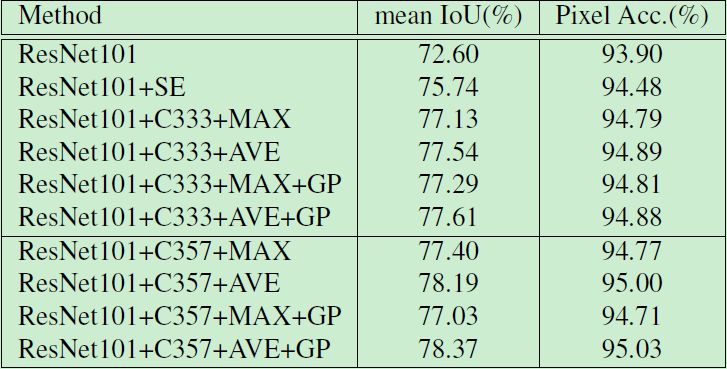
表1:不同设置下 FPA 模块的性能
GAU 模块
首先,我们评估 ResNet101+GAU 模型,然后我们将 FPA 和 GAU 模块结合并在 VOC 2012 验证集中评估我们的模型。 我们分别在三种不同的解码器设置下评估模型:(1) 仅使用跳跃连接的低级特征而没有全局上下文注意力分支。(2) 使用 1×1 卷积来减少 GAU 模块中的低层次特征的通道数。(3) 用 3×3 卷积代替 1×1 卷积减少通道数。实验结果如表2所示。

表2:不同解码器设置下的模型性能
此外,我们还比较了ResNet101+GAU 模型、Global Convolution Network 和 Discriminate Feature Network,实验结果如表3所示。

表3:我们模型与其他模型的比较结果
PASVAL VOC 2012 数据集
结合 FPA 模块和 GAU 模块的最佳设置,我们在 PASVAL VOC 2012 数据集上评估了我们的金字塔注意力网络 (PAN)。实验结果如表4、表5所示。可以看到,PAN 取得了84.0% mIoU,超过现有的所有方法。
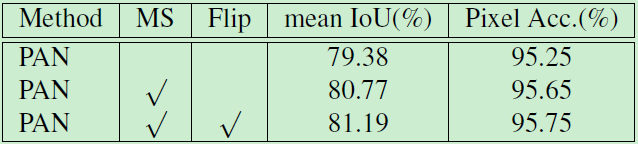
表4:在 VOC 2012 数据集上模型的性能
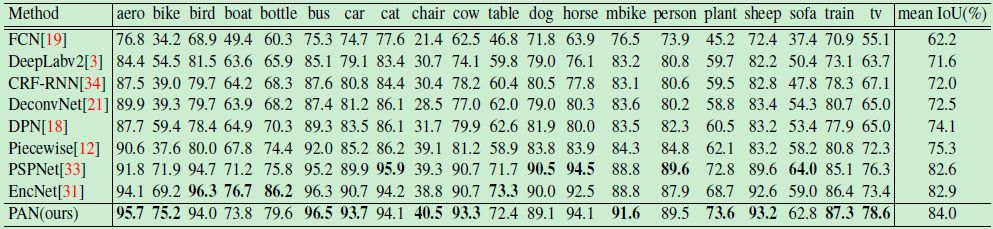
表5:在 PASVAL VOC 2012 测试集上单类别的实验结果
Cityscapes 数据集
Cityscapes 数据集包含 30 个类别,其中 19 个用于我们的模型训练和评估。整个数据集 5000 个带细粒度标注的图像和 19998 个带粗粒度标注的图像。具体地说,我们将细粒度图像分为训练集、验证集和测试集,分别有 2979、500 和 1525 张图像。在训练期间,我们没有使用带粗粒度标注的数据集,所使用的图像尺寸为 768×768。同样地,我们以 ResNet101 作为基础模型,实验结果如表6列出。
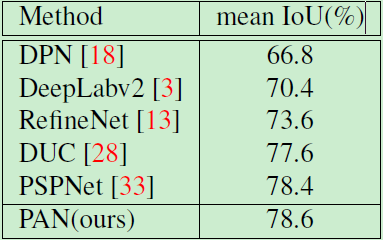
表6:Cityscapes 测试集上模型的性能
▌结论
在本文中,我们提出了一种金字塔注意力网络,用于处理图像语义分割问题。我们设计了特征金字塔注意力模块 (FPA) 和全局注意力上采样模块 (GAU)。FPA 模块能够提供像素级注意力信息并通过金字塔结构来扩大感受野的范围。GAU 模块能够利用高层次特征图来指导低层次特征恢复图像像素的定位。实验结果表明,我们所提出的方法在 PASCAL VOC 2012 语义分割任务实现了当前最佳的性能。
-
PCB工程师金字塔分级标准2012-08-06 0
-
自制for循环打印金字塔2016-09-18 0
-
van-自然和医学图像的深度语义分割:网络结构2021-12-28 0
-
基于金字塔模型的地形网格裂缝消除算法2009-12-30 660
-
图像金字塔和resize综合示例_《OpenCV3编程入门》书本配套源代码2016-06-06 568
-
绘制金字塔程序实现2017-11-27 823
-
可控特性的金字塔变换2017-12-14 897
-
基于梯度方向直方图与高斯金字塔的车牌模糊汉字识别方法2017-12-25 1340
-
卷积神经网络的岩心FIB-SEM图像分割算法2021-03-11 945
-
一种全新的遥感图像描述生成方法2021-04-20 927
-
基于密集注意力网络的图像自动分割算法2021-05-24 592
-
基于密集层和注意力机制的快速场景语义分割方法2021-05-24 666
-
基于金字塔的激光雷达和摄像头深度融合网络2022-10-09 2439
-
普通视觉Transformer(ViT)用于语义分割的能力2022-10-31 5114
全部0条评论

快来发表一下你的评论吧 !
