

一种新的高效神经架构搜索方法,解决了当前网络变换方法的局限性
电子说
描述
利用机器学习技术代替人类专家来自动设计神经网络架构近期成为了一个热门研究话题。上海交大和MIT的研究团队提出一种新的高效神经架构搜索方法,解决了当前网络变换方法的局限性,且在十分有限的GPU算力下,达到了谷歌AutoML搜索神经网络架构的效果。
最近,利用机器学习技术代替人类专家自动设计神经网络架构(即神经架构搜索)成为一个热门话题。但是,目前的资源密集型的方法实际上并不适用于大公司之外的一般研究团队。
来自上海交大APEX数据与知识管理实验室和MIT韩松老师在今年ICML 2018上发表的新研究“Path-Level Network Transformation for Efficient Architecture Search”表明,利用现有的成功的人工设计的架构来设计高效的网络架构会容易得多。通过将现有成功的人工设计的架构与神经架构搜索方法在设计有效的路径拓扑方面的强大能力相结合,可以在有限的计算资源下获得更好的结果。
研究人员表示,他们的方法用更少的GPU达到了谷歌AutoML自动搜索神经网络结构的效果。
对于这一系列工作,上海交通大学APEX实验室和约翰霍普克罗夫特中心的张伟楠助理教授表示:“在当今大型科技公司凭借超高算力持续做出AutoML领域的高质量工作的大背景下,高校团队可以将注意力集中在如何在低成本低算力的限制下巧妙设计AutoML新方法,这样的解决方法其实更加亲民,从而带来更大的影响力和更广泛的使用场景。”
麻省理工大学HAN Lab的韩松助理教授表示,“算力换算法”是当今AutoML系列工作的热点话题。传统AutoML需要上千块GPU的大量算力,然而硬件算力是深度学习的宝贵资源。本文通过提出路径级别的网络变换、树形的架构搜索空间和树形的元控制器,可以在同样性能的情况下将AutoML的硬件算力节省240倍(48,000 GPU-hours v.s. 200 GPU-hours)。在摩尔定律放缓、而数据集却在不断变大的时代,深度学习研究者值得关注算法性能和算力资源的协同优化。
结论和贡献
本研究的贡献包括:
提出路径级变换(path-level transformation),以在神经网络中实现路径拓扑修改;
提出了树形结构的RL元控制器来探索树形结构的架构空间;
在计算资源显著更少的情况下,在CIFAR-10和ImageNet(移动设置)上获得了更好的结果。
从人工设计到自动架构搜索
在应用深度学习技术时,神经网络架构往往是我们需要优化的一个非常重要的部分。传统上,这项工作是由人类专家完成的,但这十分缓慢并且往往是次优的。因此,随着计算资源的增加,研究人员开始使用机器学习工具,例如强化学习和神经网络进化(neuro-evolution)来自动化架构设计的过程,这就是“神经架构搜索”(neural architecture search)。
从头开始进行神经架构搜索
当前的大多数神经架构搜索方法都遵循一种类似的模式,即在验证信号(validation signals)的指导下,从零开始探索给定的架构空间。
一个典型的例子(Google Brain在ICLR 2017发表的“Neural Architecture Search with Reinforcement Learning”)是使用一个随机初始化的自回归递归神经网络(Auto-regressive RNN)来生成与特定网络架构相对应的整个字符串。并通过策略梯度算法来训练这个递归神经网络,以最大化预期验证性能。
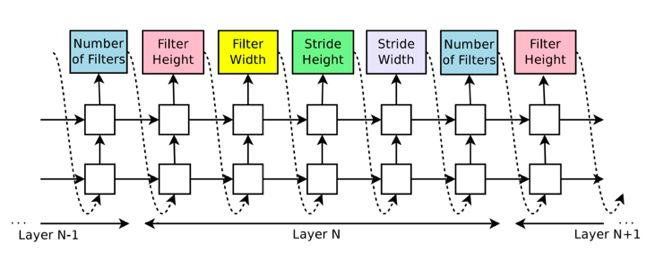
谷歌大脑提出的NAS上的Auto-regressive RNN
该模式具有如下优点:
首先,这是一个灵活的框架(可应用于自动化设计神经网络架构、神经优化器、设备配置、数据增强策略等)。
其次,这种方法在CIFAR和ImageNet等基准数据集上取得了当时最佳的结果。
缺点:
首先,这一模式通常依赖于大量的计算资源来取得好的结果(例如,NASNet使用了48000 GPU-hours)。
其次,遵循这一模式的许多方法仍然无法击败人工设计的最佳架构,尤其在计算资源受限的情况下。
基于网络变换( Network Transformation)的神经结构搜索
在这种情况下,一个想法便是:既然我们已经有许多成功的人工设计的架构,现有的神经架构搜索方法都无法轻易超越它们,那么为什么不利用它们呢?
为了实现这点,上交大团队在AAAI 2018大会上发表的工作EAS(“Efficient Architecture Search by Network Transformation”)中提出:可以不从头开始进行神经架构搜索,而是使用现有的网络作为起点,通过网络变换(Network Transformation)的方式来探索架构空间。具体的,他们使用了Net2Net操作(一类 function-preserving的网络变换操作)来探索架构空间。
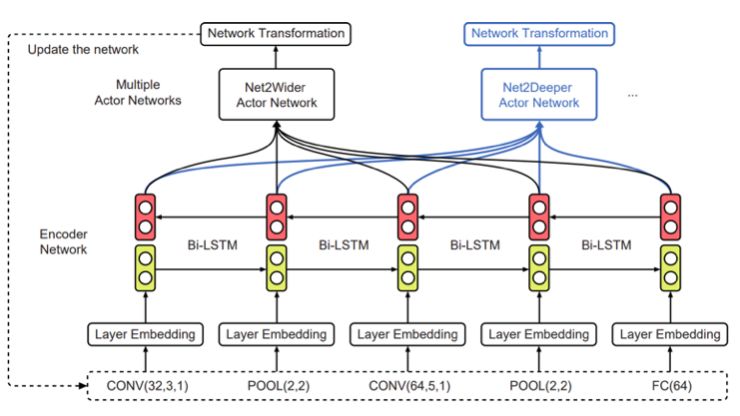
EAS的Meta-controller
而在之后的ICLR 2018上,来自CMU的研究人员提出了“N2N Learning: Network to Network Compression via Policy Gradient Reinforcement Learning”,即利用网络压缩操作来自动化地压缩一个训练好的网络。
当前网络变换方法的局限性
Net2Net和网络压缩操作的局限性在于他们都是layer-level的操作,例如添加(修剪)过滤器和插入(删除)层。通过应用这些layer-level的操作仅能改变网络的深度和宽度,而不能修改网络的拓扑结构。这意味着在给定一个链式结构的起点时,它们总是会导致链式结构网络。
然而,考虑到当前最先进的人工设计的架构(例如Inception模型、ResNets和DenseNets等)已经超越了简单的链式结构布局,并且显示出精心定制的路径拓扑(path topology)的好处,因此对于这些基于变换的方法来说,这将是一个关键的需要解决的问题。
上交大和MIT的研究人员在ICML 2018发表的“Path-Level Network Transformation for Efficient Architecture Search”的主要目的便是解决这个问题。
路径级网络变换
研究人员提出将网络变换从层级(layer-level)扩展到路径级(path-level)。
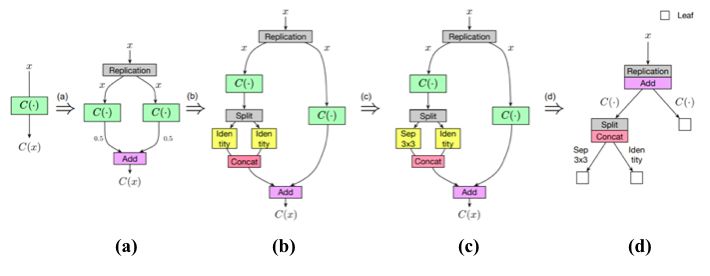
解决方案是从一些简单的观察开始。考虑一个卷积层,如果我们把多分支结构( multi-branch structure)中的每一个分支都设为该层的复制,那么给定相同的输入,每个分支必然会产生相同的输出,这些输出的平均值也等于卷积层的输出。
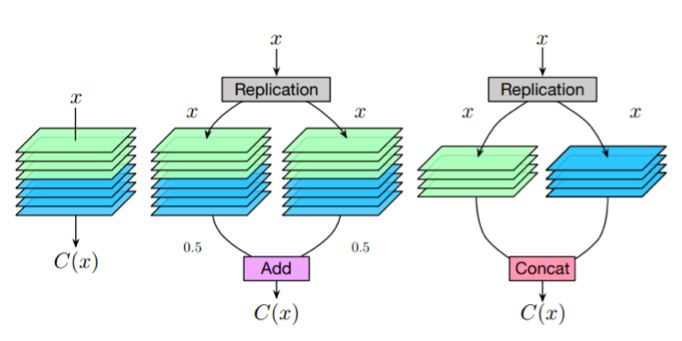
卷积层和等价的multi-branch结构
因此,我们可以构造一个等效的多分支结构(multi-branch structure),并通过add操作合并卷积层。类似地,为了构造一个通过串联合并的等效多分支结构,可以将卷积层沿着输出通道维度分割为几个部分,并将每个部分分配给相应的分支。这样,它们输出的串联就等于卷积层的输出。
对于其他类型的层,例如 identity 层和深度可分离卷积层(depth-wise separable convolution layer,),可以类似地进行这种等价的替换。
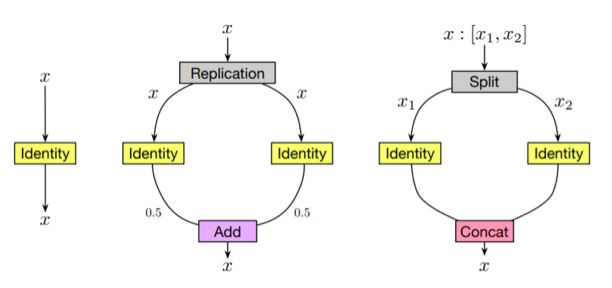
identity层和等价的multi-branch结构
更进一步,通过将这些等价替换与Net2Net操作相结合,就可以任意修改神经网络的路径拓扑。
树形结构的架构空间
在路径级网络变换的基础上,研究人员探索了一个树形的结构空间(即多分支结构的一个简单的扩展)。
形式上,树形结构单元由节点和边组成。在每个节点,定义有一个分配方案,用于确定如何为每个分支分配输入特性映射(feature map);还有一个合并方案,用于确定如何合并分支的输出。节点通过边(edge)连接到每个子节点,而边被定义为一个单元操作(例如卷积、池化、 identity等)。
给定输入特性映射x,节点的输出将基于其子节点的输出递归地定义。首先将输入特性映射分配给每个分支。然后在每个分支上,分配的特征映射由相应的边和子节点处理。最后,合并它们以产生输出。
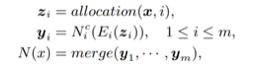
树形结构的强化学习元控制器(RL Meta-Controller)
为了探索树形结构空间,研究人员使用了一个强化学习元控制器。这里的策略网络包括一个编码器网络,用于将输入架构编码成一个低维向量,以及各种softmax分类器,用于生成相应的网络变换操作。
此外,由于输入架构现在具有树形结构,无法简单用一个字符串序列来表示,因此这里使用了树形结构编码器网络( tree-structured encoder network)。
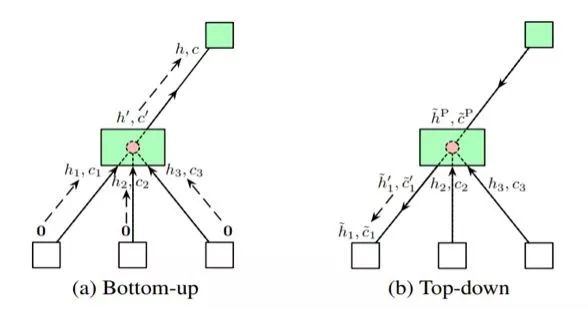
树形结构的编码器网络
具体来说,除了用于在边上执行隐藏状态变换的普通LSTM单元之外,还引入了两个额外的树结构LSTM单元,以在节点上执行隐藏状态转换。如上图所示,使用这3个LSTM单元,整个过程以自下而上和自上而下的方式进行,使每个节点中的隐藏状态包含架构的所有信息,类似于双向LSTM。
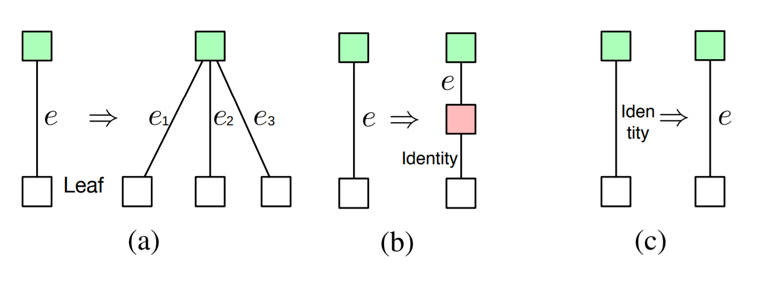
三种不同类型的决策
然后,给定每个节点的隐藏状态,做出三种不同类型的决策。第一种类型是确定是否要将一个节点转换为多个子节点。合并方案和分支数量都是预测的。第二种类型是确定是否插入新节点。第三种类型是用从一组可能的原始操作中选择的层来替换 identity 映射。
实验和结果
以下是论文中提供的受限的计算资源下(大约200 GPU-hours)找到的最好的树形单元(TreeCell-A):
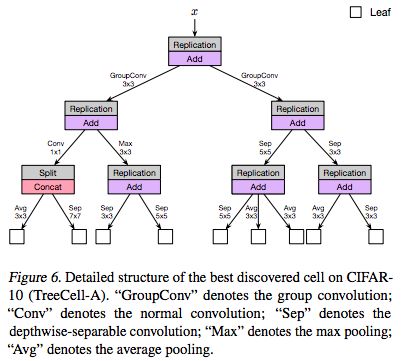
我们可以将这样的树形单元嵌入到已有的人类设计的网络架构(例如DenseNet,PyramidNet)当中,而在CIFAR-10上的结果如下表所示
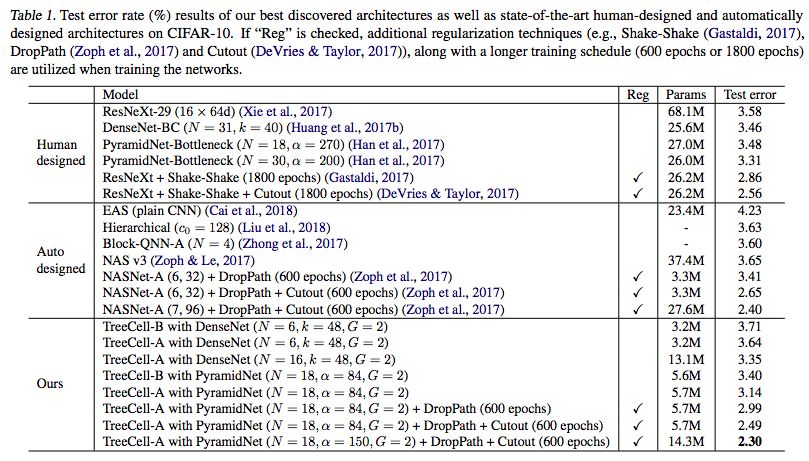
与原始的DenseNet和PyramidNet相比,树形单元显著提高了参数效率和测试误差结果。与其他从头开始的神经架构搜索方法(NASNet),TreeCell-A可以在大约一半参数的情况下实现更低的测试错误率(2.30% test error with 14.3M parameters versus 2.40% test error with 27.6M parameters)。更重要的是,其所使用的计算资源要比NASNet少得多。
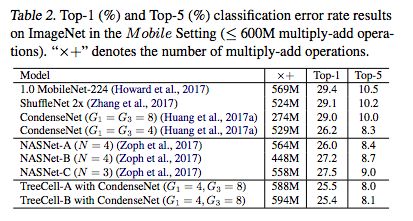
当迁移到ImageNet(移动设置)时,与NASNets相比,树形单元仍然可以获得稍好的结果。
-
34063的局限性2011-06-12 0
-
一种基于经优化算法优化过的神经网络设计FIR滤波器的方法介绍2019-07-08 0
-
无线网络有什么局限性?2019-08-23 0
-
运算放大器的精度局限性是什么2021-03-11 0
-
基于FPGA的神经网络的性能评估及局限性2021-04-30 0
-
一种基于高效采样算法的时序图神经网络系统介绍2022-09-28 0
-
一种基于BP网络的信号动态检测方法2009-08-06 550
-
一种基于神经网络汉语声韵母可视化方法2017-10-31 618
-
一种利用强化学习来设计mobile CNN模型的自动神经结构搜索方法2018-08-07 3834
-
自动神经结构搜索方法实现高效率卷积神经网络设计2018-08-07 5260
-
一种改进的深度神经网络结构搜索方法2021-03-16 811
-
以进化算法为搜索策略实现神经架构搜索的方法2021-03-22 1132
-
WSN中LEACH协议局限性的分析与改进2021-09-15 597
-
千兆光模块存在哪些局限性?2023-10-16 577
-
WDM技术的缺点和局限性2024-08-09 768
全部0条评论

快来发表一下你的评论吧 !
