

介绍了主要的生成模型和代表性的应用
电子说
描述
本文是IJCAI 2018的深度生成模型tutorial,作者是斯坦福大学PH.D Aditya Grover,长达115页的slides非常详尽地介绍了主要的生成模型和代表性的应用,希望对大家的学习有所帮助。
生成模型是图模型和概率编程语言中概率推理的关键模型。最近,使用神经网络对这些模型进行参数化,以及使用基于梯度的技术进行随机优化的最新进展,使得可以跨多种模态和应用程序对高维数据进行可扩展建模。
本教程的前半部分将提供对深度生成模型的主要家庭成员的整体回顾,包括生成对抗网络、变分自编码器和自回归模型。对于每个模型,我们都将深入讨论概率公式、学习算法以及与其他模型的关系。
本教程的后半部分将演示如何在一组具有代表性的推理任务中使用深度生成模型:半监督学习、模仿学习、对抗样本防御,以及压缩感知。
最后,我们将讨论当前该领域面临的挑战,并展望未来的研究方向。
目录
第一部分:
生成建模的动机,以及与判别模型的对比
生成模型的定义和特征:估计密度、模拟数据、学习表示
传统的生成建模方法,以及深度神经网络在有效参数化中的作用
基于学习算法的生成模型的分类:likelihood-based的学习和likelihood-free的学习
Likelihood-based学习实例:
自回归模型(定向,完全观察)
变分自编码器(定向,潜变量)
第二部分:
Likelihood-based学习实例(续):
规范化流模型
likelihood-free学习实例化:
生成对抗网络
深度生成模型的应用
半监督学习
模仿学习
对抗样本
压缩感知
生成模型未来研究的主要挑战和展望
生成建模概述、与判别模型的对比

生成模型应用领域:
计算机视觉
计算语音
自然语言处理
计算机视觉/机器人学
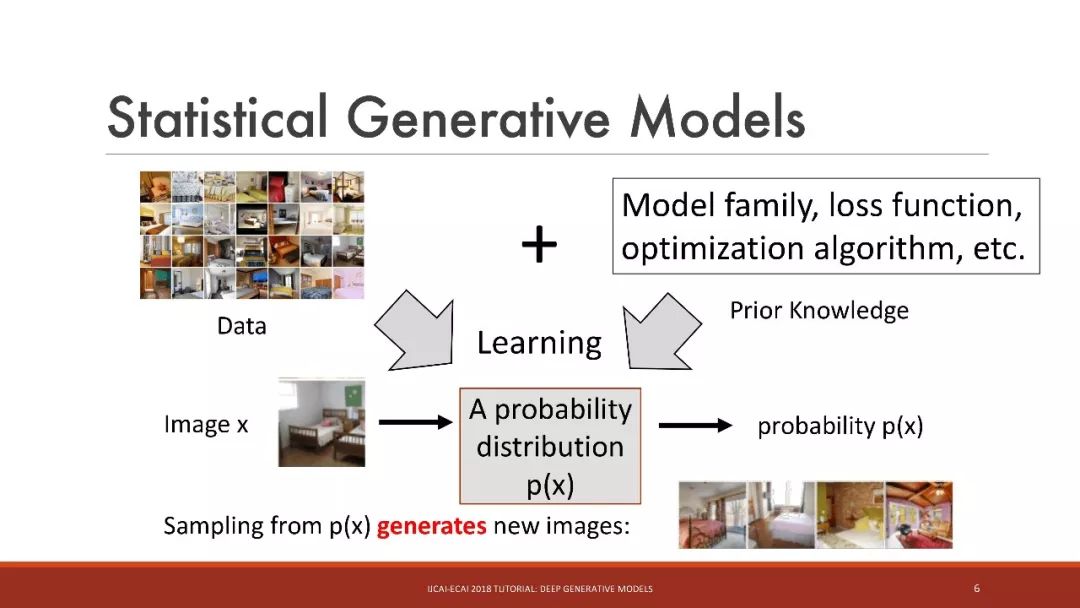
统计生成模型


判别 vs. 生成

生成模型中的学习
给定:来自数据分布和模型家族的样本
目标是:尽可能地接近数据分布
挑战:如何评价和优化数据分布和模型分布之间的接近性(closeness)?

最大似然估计
解决方案1: = KL 散度
统计学上有效
需要可跟踪地评估或优化似然性

最大似然估计
易处理似然性(Tractable likelihoods):有向模型,如自回归模型
难处理似然性:无向模型,如受限玻尔兹曼机(RBM);有向模型,如变分自编码器(VAE)
intractable likelihoods的替代选择:
- 使用MCMC或变分推理进行近似推理
- 利用对抗训练进行 Likelihood-free的推理
基于似然性的生成模型

提供一个对数似然的解析表达式,即 log N
学习涉及(近似)评估模型对数似然相对于参数的梯度
关键设计选择
有向(Directed)和无向(undirected)
完全观察 vs. 潜在变量

有向、完全观察的图模型
这里的关键想法是:将联合分布分解为易处理条件的乘积

学习和推理
学习最大化数据集上的模型对数似然
易处理条件允许精确的似然评估
训练期间并行的条件评估
有向模型允许ancestral采样,每次一个变量

基于神经网络的参数化

基于MLP的参数化

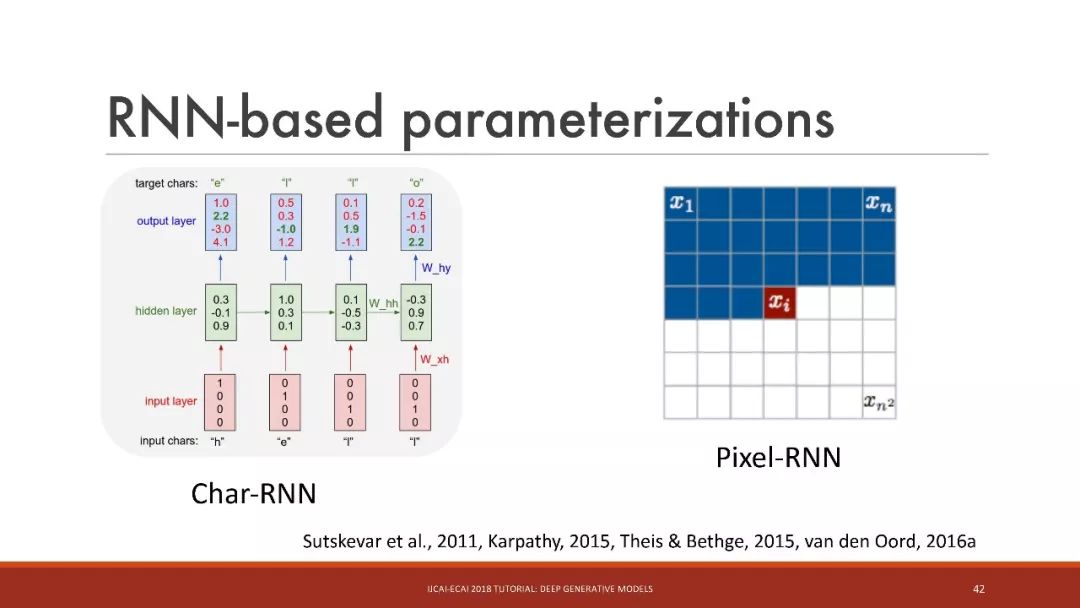
基于RNN的参数化
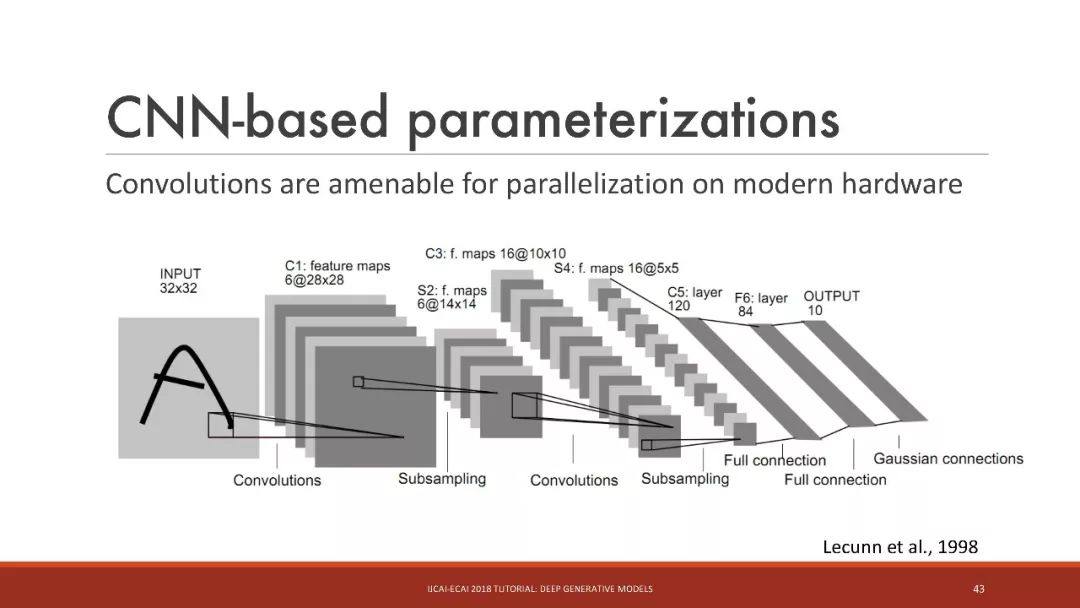
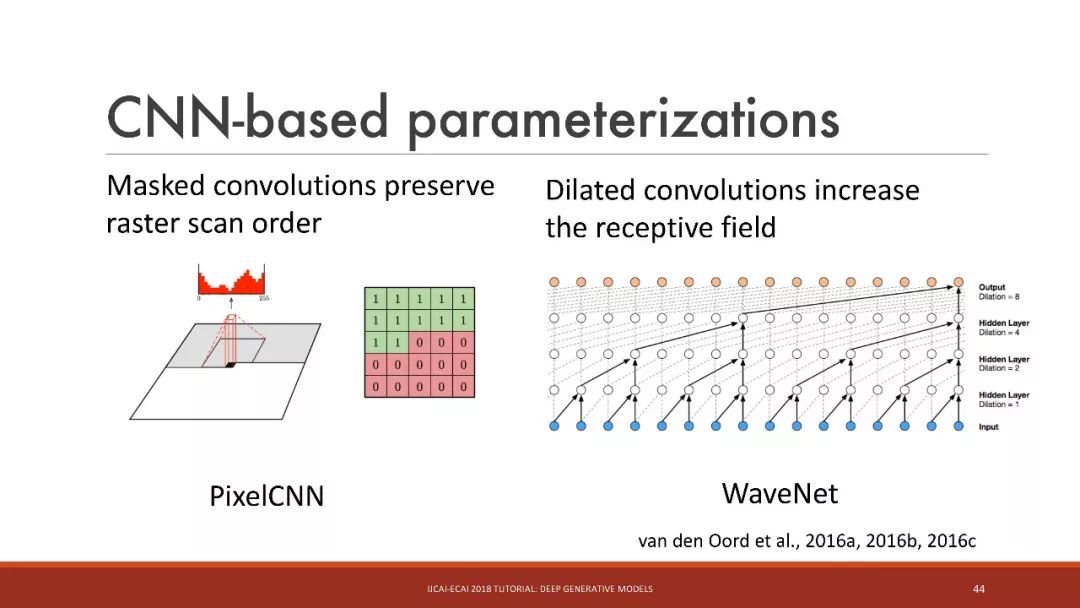
基于CNN的参数化
likelihood-free的生成模型

likelihood-free的生成模型
最佳生成模型:最佳样本和最高的对数似然
对于不完美的模型,对数似然和样本是不相关的
Likelihood-free的学习考虑的目标不直接依赖于似然函数


生成对抗网络
这里的关键想法是:generator(生成器)和discriminator(判别器)两者的博弈
判别器区分真实数据集样本和来自生成器的假样本
生成器生成可以欺骗判别器的样本

对于一个固定的生成器,判别器最大化负交叉熵
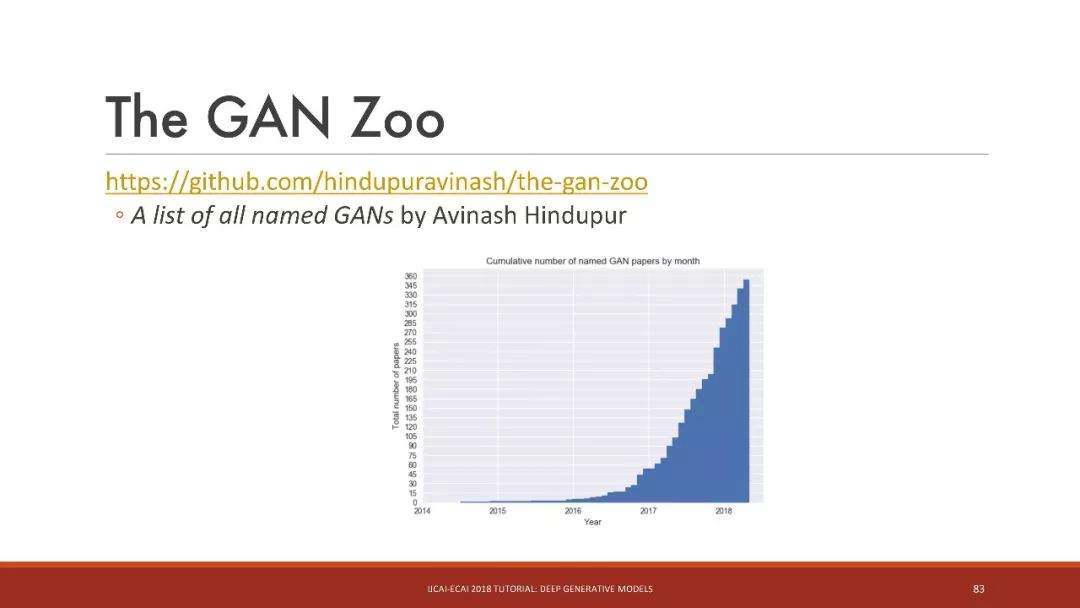
GAN动物园
深度生成模型的应用:半监督学习、模仿学习、对抗样本、压缩感知

半监督学习
在这个例子中,我们可以如何利用这些未标记的数据呢?

步骤1:学习标记数据和未标记数据的潜在变量生成模型
步骤2:使用z作为特征,训练分类器(例如SVM),仅使用有标记的部分


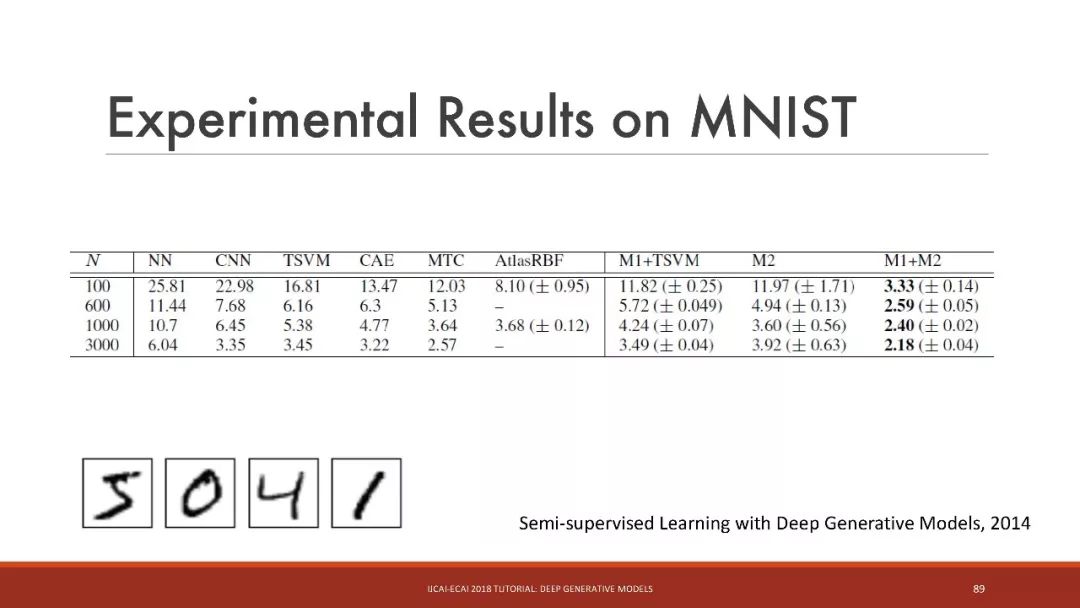

半监督学习的结果


模仿学习
有几个现有的方法:
行为克隆(Behavioral cloning)
逆向强化学习
学徒学习(Apprenticeship learning)
我们的方法是:生成式的潜变量模型

对抗样本
添加微小的噪声,最先进的分类器都有可能被欺骗!

检测对抗样本

迁移压缩感知
从源、数据丰富的域迁移到目标、数据饥渴的域

总结
1. 生成模型的杀手级应用是什么?
基于模型的RL?
2. 什么是正确的评估指标?
从根本上说,它是无监督学习。评估指标定义不明确。
3. 在推理中是否存在基本的权衡?
采样
评估
潜在特征
-
基于模型的设计(MBD)的深入讨论2016-06-14 0
-
运算放大器的代表性参数2019-05-27 0
-
DC大功率LED驱动IC有哪些代表性的分类?2021-04-07 0
-
常见的几种代表性的HDL语言2021-04-28 0
-
白菜白光起源、发展及代表性威廉希尔官方网站 图资料下载2018-02-03 5559
-
9款具有代表性的系统解决方案2018-12-19 4479
-
在情感分析中使用知识的一些代表性工作2020-11-02 2698
-
具有代表性的科学产品2020-11-04 2464
-
一文详解云存储结构的模型2020-12-25 4292
-
运算放大器的代表性参数详解2021-09-24 4609
-
新华三入选 “代表性中国数据库厂商”2022-04-14 1308
-
浪潮存储入选分布式存储代表性厂商2022-08-09 903
-
晶振封装代表性的网红型号有哪些?2022-10-08 1179
-
解读可穿戴设备代表性产品核心技术原理2023-10-31 262
-
全国5G新基建智慧灯杆建设十大代表性案例2024-11-07 598
全部0条评论

快来发表一下你的评论吧 !
