

了解迁移学习,哪种情况适合做迁移学习?
电子说
描述
▌一. 了解迁移学习
迁移学习(Transfer Learning)目标是将从一个环境中学到的知识用来帮助新环境中的学习任务。
> The ability of a system to recognize and apply knowledge and skills learned in previous tasks to novel tasks。
入门推荐一篇公认的比较好的 【Survey】: A Survey on Transfer Learning,Sinno JialinPan, Qiang Yang,IEEE Trans
http://www.cse.ust.hk/faculty/qyang/Docs/2009/tkde_transfer_learning.pdf
另外,戴文渊的硕士学位论文也可以看一下:基于实例和特征的迁移学习算法研究
https://download.csdn.net/download/linolzhang/9872535
Survey 作者归纳了 Transfer Learning 相关的知识域,有必要了解一下这些名词:
● Learning学习 - learning to learn
● 终身学习 - life-long learning
● 知识转移 - knowledge transfer
● 归纳迁移 - inductive transfer
● 多任务学习 - multi-task learning
● 知识的巩固 - knowledge consolidation
● 上下文相关学习 - context sensitive learning
● 基于知识的归纳偏差 - knowledge-based inductive bias
● 元学习 - meta learning
● 增量学习 - and incremental/cumulative learning
另外,进展及 Open Source Toolkit 可以参考:
http://www.cse.ust.hk/TL/index.html
▌二. 迁移学习分类
迁移学习(Transfer Learning)根据 领域 和 任务的相似性,可以这样划分:
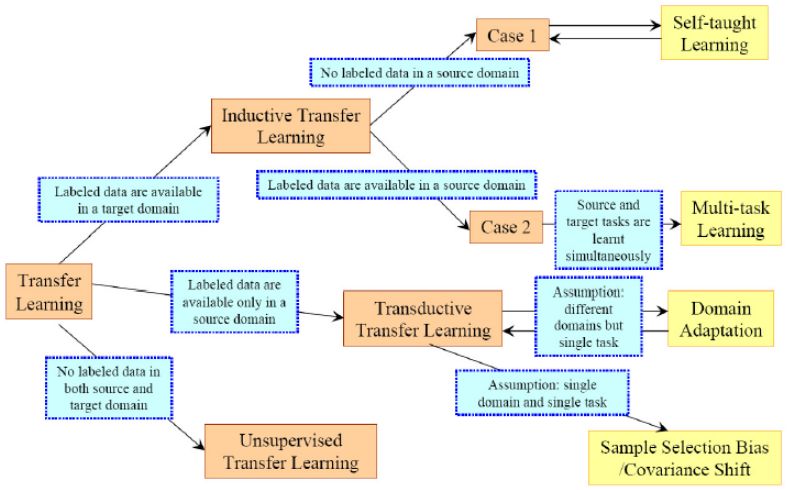
我们根据 源Domain和目前Domain 之间的关系,源Task 和 目标Task之间的关系,以及任务方法更详细的整理为下表:
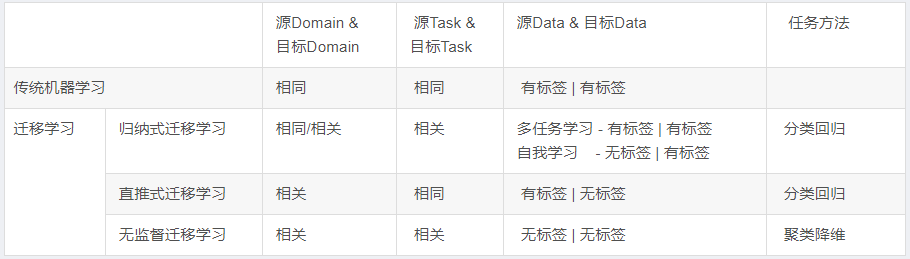
实际上,归纳式迁移学习 是应用最广泛的一种方法,从这点上看,迁移学习更适合 有标签的应用域。
根据技术方法,我们将迁移学习的方法划分为:

迁移学习方法虽然在学术有很多研究工作,实际上在应用领域并不算成熟,这本身就是一个很大的命题,关于迁移学习的条件 和 本质也并未形成一套正统的体系来引领研究方向,更多的也是在实验摸索。
迁移学习 目前面临如下几个问题:
1. 哪种情况适合做迁移学习? - What
这里先给个自己的理解:分类和回归问题是比较适合做迁移学习的场景,有标签的源数据是最好的辅助。
2. 该选择哪种方法? - Which
简单而行之有效的方法是首选,领域在快速发展,也不必拘泥算法本身,改善结果才是硬道理。
3. 如何避免负迁移? - How
迁移学习的目标是改善目标域的 Task效果,这里面 负迁移(Negative Transfer)是很多研究者面临的一个问题,如何得到行之有效的改进,避免负迁移是需要大家去评估和权衡的。
▌三. 经典算法 TrAdaBoost
TrAdaBoost 算法是基于 样本迁移的 开山之作,由 戴文渊 提出,有着足够的影响力放在第一位来进行讲解。
论文下载:Boosting for Transfer Learning
http://home.cse.ust.hk/~qyang/Docs/2007/tradaboost.pdf
算法的基本思想是 从源 Domain 数据中筛选有效数据,过滤掉与目标 Domain 不match的数据,通过 Boosting方法建立一种权重调整机制,增加有效数据权重,降低无效数据权重,下图是 TrAdaBoost 算法的示意图(截图来自于 庄福振 - 迁移学习研究进展):
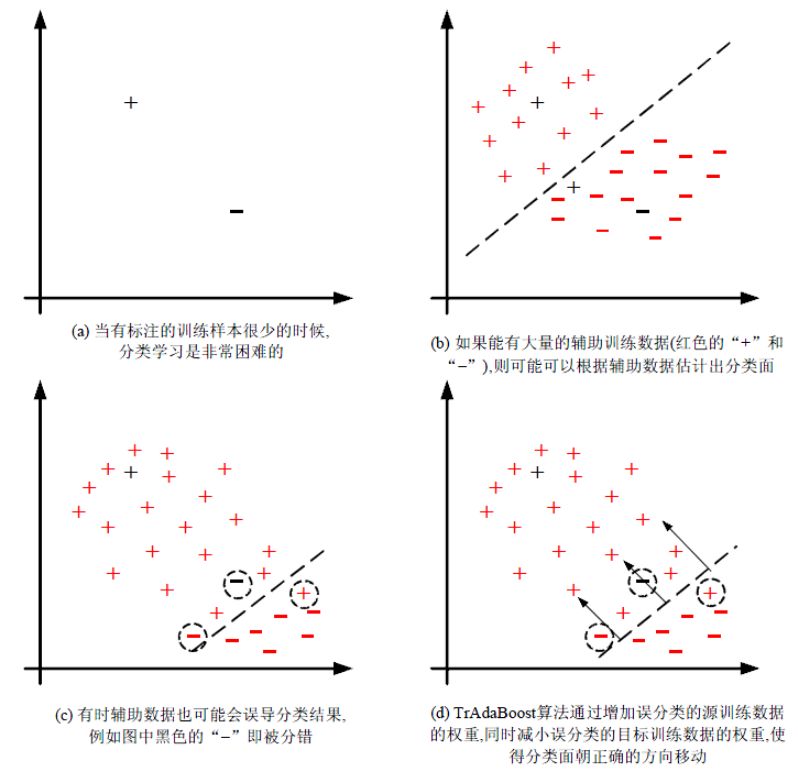
TrAdaBoost 算法比较简单,用一句话概括就是 从过期数据里面 找出和目标数据最接近的样本数据。
来看 TrAdaBoost 的算法步骤:

这里需要说明的一点就是 权重的更新方式,对于辅助样本来讲,预测值和标签越接近,权重越大;而对于目标数据则是相反,预测值和标签差异越大,权重越大。这种策略狠容易理解,我们想找到辅助样本中 和 目标数据分布最接近的样本,同时放大目标样本Loss的影响,那么理想的结果就是:
目标样本预测值与标签尽量匹配(不放过一个没匹配好的数据),辅助样本在前面的基础上筛选出最 match(权重大的) 的部分。
作者在后面给出了理论证明,这里有两个公式(来证明算法收敛):
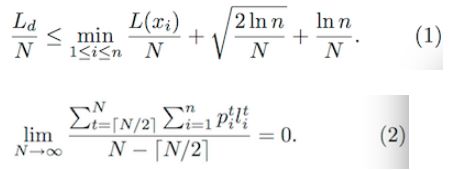
因篇幅问题,这里就不再展开了(和作者说的一样),有兴趣可以参考原Paper,看下实验结果:
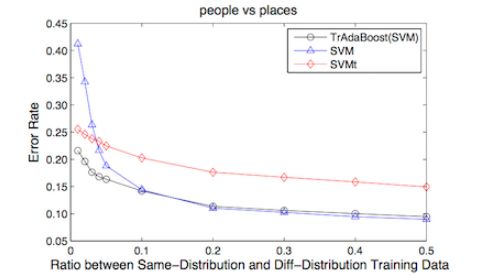
实验发现,当 同分布数据(目标数据)占比当低于0.1时,算法效果明显,当比例超过 0.1时,TrBoost 退化为 SVM 的效果。
这又是一个显而易见的结论,我们认为大于0.1时,仅仅依靠 目前数据就足够完成样本训练,这种情况下,辅助样本的贡献可以忽略。
另外,当 目标数据 和 辅助数据 差别比较大时,该方法是不 Work的,印证了最初的假设,这里不再展开证明。
最后,给出网友提供的C代码:【下载地址】
https://download.csdn.net/download/linolzhang/9880438
▌四. 多任务学习
多任务学习(Multi-Task Learning, MTL)是一种同时学习多个任务的机器学习方法,该方法由来已久,和深度学习没什么关系。
如果非要把它 和深度学习加上一个 link,我们可以这样来表示:
input1 -> Hidden1-> H1-> Out1 input1 -> Out1 input2 -> Hidden2-> H2-> Out2 ==> input2 -> Hidden123 -> H123 -> Out2 input3 -> Hidden3-> H3-> Out3 input3 -> Out3
也比较好理解,相当于把多个 Task网络进行合并,同时训练多个任务,这种情况并不鲜见,比如以下2个方向:
1)目标检测 - 复合多任务
目标检测是 分类问题+回归问题的组合,这是一个典型的 Multi-Task,比如:
Detection=Classification+Location
Mask RCNN = Classification+Location+Segmentation
检测问题前面描述的比较多了,这里就不再贴图了。
2)特征提取
多任务特征提取,多个输出,这一类问题代表就是 数据结构化,特征识别。
下图是香港中文大学汤晓鸥组发表的TCDCN(Facial Landmark Detection by Deep Multi-task Learning),很多讲 Multi-Task的软文都拿出来说,我们也借用一下。
在这里 Multi-Task 被同时用作 人脸关键点定位、姿态估计和属性预测(比如性别、年龄、人种、微笑?戴眼镜?)
多任务学习适用于这样的情况:
1)多个任务之间存在关联,比如行人和车辆检测,对于深度网络也可以理解为有部分共同的网络结构;
2)每个独立任务的训练数据比较少,单独训练无法有效收敛;
3)多个任务之间存在相关性信息,单独训练时无法有效挖掘;
可以看一下这篇 Tutorial:
www.public.asu.edu/~jye02/Software/MALSAR/MTL-SDM12.pdf
关于多任务学习的应用,比如分类任务下的二级分类、人脸识别等,大家可以更进一步了解。
-
迁移学习的基本概念和实现方法2024-07-04 1629
-
视觉深度学习迁移学习训练框架Torchvision介绍2023-09-22 899
-
使用哪种运放比较适合做衰减用,且不会失真很严重?2024-09-10 0
-
迁移学习训练网络2019-09-09 0
-
【木棉花】学习笔记--分布式迁移2021-09-05 0
-
迁移学习2022-04-21 0
-
基于局部分类精度的多源在线迁移学习算法2017-12-25 728
-
迁移学习的原理,基于Keras实现迁移学习2018-05-09 14908
-
什么是迁移学习?迁移学习的实现方法与工具分析2018-05-11 12360
-
机器学习方法迁移学习的发展和研究资料说明2020-07-17 820
-
基于脉冲神经网络的迁移学习算法2021-05-24 736
-
基于WordNet模型的迁移学习文本特征对齐算法2021-06-27 583
-
基于迁移深度学习的雷达信号分选识别2022-03-02 1498
-
一文详解迁移学习2023-08-11 6323
-
预训练和迁移学习的区别和联系2024-07-11 1035
全部0条评论

快来发表一下你的评论吧 !
