

总结可微图像参数表示的最新进展
电子说
描述
编者按:Googel AI的Alexander Mordvintsev、Nicola Pezzotti和Google Brain的Ludwig Schubert、Chris Olah上个月在Distill发表论文,总结了可微图像参数表示的最新进展。
出人意料,为分类图像而训练的神经网络具有出色的生成图像的能力。DeepDream、风格迁移、特征可视化之类的技术将这一能力作为探索神经网络内部机制的强力工具,推动了一场基于神经网络的小型艺术运动。
这些技术的机制大致相同。用于计算机视觉的神经网络具有图像的丰富内在表示。我们可以使用这一表示来描述我们希望图像具有的性质(例如,风格),接着优化输入图像使其具备这些性质。这种优化之所以可行,是因为网络在其输入上可微:我们可以微调图像以更好地拟合所需性质,接着在梯度下降中迭代应用这些微调。
参数化输入图像的典型方法是将其表示为每个像素的RGB值,但这不是唯一的方式。只要参数到图像的映射是可微的,我们就可以通过梯度下降优化其他形式的参数表示。
橙色虚线表示反向传播
可微图像参数表示邀请我们提出了这样一个问题:“反向传播通过的是什么样的图像生成过程?”答案是相当多样的过程,其中一些奇异的可能性,可以创造多种多样的有趣效果,包括3D神经艺术,透明图像,对齐内插。之前一些使用不同寻常的图像参数表示的工作(arXiv:1412.1897、3D对抗样本、特征可视化)展示了激动人心的结果——我们觉得概览下这一领域的进展能够提示更具潜力的方法。
为什么参数表示很重要?
在保持实际进行优化的目标函数不变的情况下,改变优化问题的参数表示就能明显改变结果,这看起来比较惊人。参数表示的选择为什么具有显著的效应,我们认为有四个原因:
改良优化 —— 转换输入以降低优化问题的难度——这一技术称为预处理(preconditioning)——是优化的主要内容。
吸引盆 —— 通常有多种优化方案,对应不同的局部极小值。优化过程落入任一特定极小值的概率由其吸引盆控制(吸引盆为在极小值影响下的优化区域)。改变优化问题的参数表示,可以改变吸引盆的大小,从而影响结果。
额外限制 —— 有些参数表示仅仅覆盖可能输入的一个子集,而不是整个空间。在这样的参数表示上工作的优化器仍能找到最小化或最大化目标函数的解,但它们将置于参数表示的限制之下。
隐式优化其他目标 —— 一个参数表示可能内部使用和供优化的输出目标不同的目标。例如,尽管视觉网络的自然输入是RGB图像,我们可以将其参数化为3D物体的渲染,让反向传播通过其渲染过程。由于3D物体相比图像自由度更高,我们一般使用随机(stochastic)参数表示,该表示产生不同角度的渲染图像。
本文剩下的部分将给出具体的例子,体现这类方法的优势,以及它们如何导向惊奇、有趣的视觉效果。
对齐特征可视化内插
特征可视化最常用来可视化单个神经元,但它同样可以用来可视化神经元的组合,以研究它们是如何交互的。
当我们想要切实理解两个神经元之间的交互时,我们可以更进一步,创建多元可视化。某种意义上,这类似于GAN这样的生成式模型的潜空间内插。
不过我们还要应对一项小挑战:特征可视化是随机的。即时我们优化的目标完全一致,每次可视化的布局仍将不同。通常情形下这不会导致问题,但是确实影响解释性可视化,所得可视化会没对齐:像眼睛这样的视觉标记在每帧的不同位置出现。缺乏对齐使得比较略微不同的目标更加困难,因为布局上的差异最大、最明显,盖过了其他差异。
如何解决这一对齐问题,使得视觉标记不因帧的不同而移动。有一些可供尝试的方法,其中之一是使用共享参数表示(shared parameterization):每帧参数化为其自身唯一的参数表示和一个共享参数表示的组合。
通过部分共享帧间的参数表示,我们鼓励所得可视化自然对齐。从直觉上说,共享参数表示提供了视觉标记放置位置的共有参考,而唯一参数表示基于内插权重赋予每帧自身的视觉效果。这样的参数化并没有改变目标,但确实扩大了对齐可视化的吸引盆。
部分共享的参数表示扩大了对齐处的吸引盆
配套colab页面:
https://colab.research.google.com/github/tensorflow/lucid/blob/master/notebooks/differentiable-parameterizations/aligned_interpolation.ipynb
基于非VGG架构的风格迁移
神经风格迁移有一个不解之谜:尽管使用神经网络进行风格迁移非常成功,但几乎所有的风格迁移都基于VGG架构的变体。这并不是因为没人对使用其他架构进行风格迁移感兴趣,而是因为在其他架构上的尝试表现一直不好。
人们提出了一些假说,解释VGG为何比其他模型的表现好这么多。其中一种解释是VGG的大尺寸使其捕捉了其他模型丢弃的信息。这些无助于分类的额外信息,使得这一模型在风格迁移上表现更好。另一种替代假说是其他模型比VGG更激进的下采样导致空间信息的损失。我们怀疑可能有其他因素:大多数现代的视觉模型,其梯度中都有棋盘效应(checkerboard artifacts),这可能加大了优化风格图像的难度。
在之前的工作中,我们发现,去相关性的参数表示可以显著改善优化。我们发现这一方法同样可以改善风格迁移,让我们可以使用原本无法产生有视觉吸引力的风格迁移结果的模型:
左上为风格图像(梵高的《星空》),右上为内容图像(Andyindia拍摄的照片)。下为模型生成的风格迁移图像(最终优化结果)。生成图像的左半部分为去相关性空间(Decorrelated Space)优化结果,右半部分为像素空间(Pixel Space)优化结果,两部分的优化目标完全一样,仅仅参数表示不同。
下面我们稍稍介绍一些细节。风格迁移涉及三张图像:内容图像,风格图像,优化图像。这些图像都传给CNN,风格迁移目标则基于这些图像如何激活CNN的差异。我们唯一进行的改动是参数化优化图像的方法。从基于像素参数化(相邻像素高度相关)转为基于尺度傅立叶变换参数化。
我们同时使用了部分风格迁移实现没有使用的转换鲁棒性。具体实现见配套的colab页面:
https://colab.research.google.com/github/tensorflow/lucid/blob/master/notebooks/differentiable-parameterizations/style_transfer_2d.ipynb
复合模式生成网络
到目前为止,我们探索的图像参数表示,相对接近我们通常对图像的认知,像素或傅立叶成分。本节将探索使用不同的参数表示给优化过程施加额外限制的可能性。更具体地说,我们将图像参数化为神经网络——复合模式生成网络(Compositional Pattern Producing Network,CPPN)。
CPPN是将(x, y)位置映射到图像色彩的神经网络:

CPPN可以生成任意分辨率的图像。CPPN网络的参数——权重和偏置——决定生成什么样的图像。取决于CPPN的架构,所得图像中的像素,在一定程度上受到共享相邻像素颜色的限制。
随机参数可以产生美学上有趣的图像,然而,通过学习CPPN的参数,我们能生成更有趣的图像。学习CPPN参数经常通过演化达成(例如,K. Sims、K.O. Stanley、A.M. Nguyen等的工作);这里我们探索了通过反向传播某个目标函数(例如特征可视化目标)学习CPPN参数的可能性。这不难做到,因为CPPN网络是可微的(和卷积神经网络一样)。这就是说,CPPN是一种可微图像参数表示——在任何神经艺术或可视化任务中,CPPN是一个参数化图像的通用工具。
使用基于CPPN的图像参数表示,可以给神经艺术加上有趣的艺术性,隐约让人联想起光绘(light-paintings,运用彩色光束、棱镜、平面镜创造图像)。
Stephen Knapp的光绘作品
在偏理论的层面,它们可以看成是对图像的组分复杂性(compositional complexity)的限制。优化特征可视化目标时,CPPN可以生成独具特色的图像:
选择的CPPN架构对生成图像的视觉质量影响很大。这里CPPN架构不仅包括网络的形状(网络层和过滤器的数量),也包括激活函数和归一化。例如,相比较浅的网络,较深的网络生成细节上更精细的图像。我们鼓励读者通过修改CPPN的架构生成不同的图像。这并不难,只需改动配套的colab页面中的代码:
https://colab.research.google.com/github/tensorflow/lucid/blob/master/notebooks/differentiable-parameterizations/xy2rgb.ipynb
CPPN生成模式的演化自身就是艺术品。回到光绘的比喻上来,优化过程对应光束方向和形状的迭代调整。相比像素参数表示之类的其他参数表示,CPPN的迭代变动更具全局效应,因此在优化刚开始的时候,只能看到主要的模式。随着迭代调整权重的进行(我们想象中的光束变换位置),出现了精细的细节。
继续这一比喻,我们可以创造一种新的动画,从上面的一幅图像渐变为另一幅。直观地讲,我们从其中一幅光绘开始,然后移动光束以创作另一幅不同的光绘。事实上,这是通过内插两种模式的CPPN表示权重做到的。给定经内插替换的CPPN表示,可以生成一组中间帧。像之前一样,改动参数具有全局效应,能够生成具有视觉吸引力的中间帧。
这一节展示了一种不同于标准图像表示的参数表示。神经网络(这里的CPPN),可以用来参数化为给定目标函数优化的图像。更具体地说,我们结合了特征可视化目标函数和CPPN参数表示,以创建视觉风格独特的无穷分辨率图像。
生成半透明模式
本文介绍的神经网络都接受二维RGB图像作为输入。有没有可能使用同样的网络合成超出这一范围的图像?为了做到这一点,我们可以让可微参数表示定义一系列图像而不是单张图像,接着在每个优化步骤中从图像序列中取样一张图像或多张图像。这很重要,因为我们即将探索的许多优化目标比传入网络的图像的自由度更高。
让我们来看一个具体的例子,半透明图像。这些图像在RGB通道之外,还有一个编码透明度的Alpha通道。为了将这样的图像传入在RGB图像上训练的神经网络,我们需要通过某种方法塌缩Alpha通道。达成这一点的一种方法是将RGBA图像覆盖在一张背景图像BG之上,这可以应用标准的Alpha混合公式:
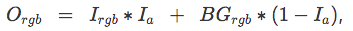
其中,Ia为图像I的Alpha通道。
如果我们使用固定的背景图像,例如全黑图,透明度将仅仅指示背景直接贡献优化目标的像素位置。事实上,这等价于优化一张RGB图像,使其在颜色与背景相同的区域透明!直觉上,我们想要透明区域对应于“这一区域的内容可能是任意的”之类的东西。基于这一直觉,我们在每一个优化步骤使用了不同的随机背景。(实际上,我们同时尝试了从真实图像取样以及应用不同种类的噪声。我们发现,只要充分随机化,不同的分布并不会影响最终的优化结果。所以,出于简单性,我们使用了平滑2D高斯噪声。)
默认配置下,优化半透明图像将导致图像变得完全不透明,这样网络总能得到最优输入。为了避免这一问题,我们需要修改目标,采用一个鼓励部分透明的目标函数。我们发现,对原目标函数进行如下替换很有效:
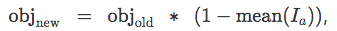
这一新目标函数自动在原目标函数objold和降低透明度均值间寻找平衡。如果图像变得很透明,它将专注于原本的目标。如果图像变得很不透明,它会暂时停止关注原目标,专注于降低平均透明度。
半透明图像优化的例子
我们发现,半透明图像在特征可视化上很有用。特征可视化的目标是,通过创建能够最大化神经元激活程度的图像,理解视觉模型中的神经元在找什么。不幸的是,这些可视化无法区分图像的哪些区域对某个神经元的激活影响很大,哪些区域的影响甚少。
理想情况下,我们想要找到一种方法,让可视化可以区分重要性——一种自然的方式,是将不重要的部分透明化。因此,如果我们优化一张带Alpha通道的图像,并鼓励整张图像变得透明,那么在特征可视化目标看来不重要的图像区域应该变得透明。
配套colab页面:
https://colab.research.google.com/github/tensorflow/lucid/blob/master/notebooks/differentiable-parameterizations/transparency.ipynb
基于3D渲染的高效纹理优化
前一节使用针对RGB图像的神经网络创建半透明RGBA图像。可不可以更进一步?这一节将探索为特征可视化目标优化3D物体。我们使用3D渲染过程转换出2D RGB图像,传入神经网络,然后反向传播渲染过程以优化3D物体的纹理。
我们的技术类似Athalye等用来创建真实世界对抗样本的方法,依赖反向传播目标函数至随机取样的3D模型视图。和现有的艺术纹理生成方法(arXiv:1711.07566)不同,我们并不在反向传播过程中修改物体的几何性质。通过拆分纹理生成和顶点定位,我们可以为复杂物体创建细节丰富的纹理。
在描述我们的方法之前,首先需要了解3D物体是如何储存,如何在屏幕上渲染的。物体的几何性质通常保存为一组相连的三角形,这称为三角网格(triangle mesh),简称网格。之后在网格上绘制纹理(texture)以渲染逼真的模型。纹理保存为一张图像,通过UV映射(UV-mapping)应用于模型。网格中的每个顶点ci关联纹理图像中的一个坐标(ui, vi)。渲染模型(即在屏幕上绘制)时,给每个三角形贴上由顶点坐标(u, v)界定的图像区域。
一个简单粗暴的创建3D物体纹理的方法是照常优化图像,并将其作为纹理贴到物体上。然而,这一方法生成的纹理没有考虑UV映射,因此会在渲染好的物体上造成多种视觉效应,包括接缝(seams)、随机朝向、缩放不一致。
左:直接优化;右:基于渲染过程优化
从上图可以看到,左面的图像出现了接缝、朝向错误的问题。
将上图展开为二维纹理表示,能够更清楚地看到两者的差别。
我们没有直接优化纹理,而是优化3D物体渲染过程中的纹理:
我们首先基于傅立叶参数表示随机初始化纹理。每个训练迭代取样一个随机拍摄位置(朝向物体包围盒的中心),然后渲染贴上纹理的物体为图像。接着我们反向传播所需目标函数(神经网络感兴趣的特征)的梯度至渲染图像。
不过,更新渲染图像并不对应纹理(我们的优化目标)的更新。因此,我们需要进一步传播变动至物体纹理。应用逆向UV映射,这很容易实现。
朝向正确,接缝几不可见
此外,由于优化函数从物体的几何性质中分离出来,纹理可以使用任意大的分辨率。在下一节中,我们将看到,如何复用这一框架,进行物体纹理的艺术风格迁移。
配套colab页面:
https://colab.research.google.com/github/tensorflow/lucid/blob/master/notebooks/differentiable-parameterizations/texture_synth_3d.ipynb
基于3D渲染的纹理风格迁移
既然我们已经有了一个高效地反向传播UV映射纹理的框架,我们可以基于该框架将现有的风格迁移技术应用于3D物体。和2D情形类似,我们的目标是依据用户提供的图像风格重绘原物体的纹理。
和前一节一样,我们从随机初始化的纹理开始。在每一次迭代中,我们取样一个随机视角(同样朝向物体包围盒的中心),并渲染两张图像:内容图像(content image)(原纹理)和学习图像(learned image)(正优化的纹理)。
渲染内容图像和学习图像后,我们基于Gatys等提出的风格迁移的目标函数(arXiv:1508.06576)进行优化,并像前一节一样将参数表示映射回UV映射纹理。迭代此过程,直到混合内容和风格的目标纹理符合要求。
Martín Jario的3D模型骷髅头骨,风格迁移为梵高《星空》
每个视角独立优化,迫使优化在每个迭代中尝试加上所有风格元素。例如,如果我们的风格图像是梵高的《星空》,那么每个视角都会加上星辰。我们发现,通过引入之前视角的风格作为某种“记忆”,能够得到更满意的结果。我们通过这种方式维护了最近取样的视图的平均风格表示格拉姆矩阵。在每个优化迭代中,我们基于这些平均矩阵(而不是特定视角的矩阵)计算风格损失。
所得纹理在保持原纹理特性的同时,结合了所需风格的元素。以应用梵高《星空》风格至Greg Turk和Marc Levoy的Stanford Bunny模型为例:
所得纹理包含了梵高的作品特有的富于韵律和活力的笔触。然而,尽管风格图像以冷色调为主,最终得到的纹理却保留了原纹理的暖色(皮毛的底色为橙色)。更有趣的地方,是不同风格迁移下,如何保留兔眼的形态。例如,当风格取自梵高的作品时,兔眼转换为类似星辰的漩涡。如果使用的是康丁斯基的作品,兔眼则变为类似眼睛的抽象模式。
风格图像为康丁斯基的《白色之上第二号》
生成的纹理模型易于在流行的3D建模软件和游戏引擎中使用。作为演示,我们3D打印了其中一项设计:
风格图像为Fernand Leger的The large one parades on red bottom
配套colab页面:
https://colab.research.google.com/github/tensorflow/lucid/blob/master/notebooks/differentiable-parameterizations/style_transfer_3d.ipynb
结语
对富于创意的艺术家和研究者而言,参数化优化图像的方法是一个巨大的空间。这一切并不局限于静态图像,还可以用于生成动画的3D物体!本文探索的可能性仅仅触及了表面。例如,可以探索扩展3D物体纹理优化至材质和反射率的优化——甚至进一步优化网格顶点的位置,正如Kato等所做的(arXiv:1711.07566)那样。
本文关注的是可微图像参数表示,因为它们易于优化,并且覆盖了广阔范围的可能应用。不过,基于强化学习和演化策略(jmlr/v15/wierstra14a、arXiv:1703.03864),优化不可微或部分可微的图像参数表示当然是可行的。使用不可微的参数表示可以为图像生成和场景生成提供许多激动人心的可能性。
-
国内外变体机翼技术最新进展2023-01-03 1861
-
风光互补技术及应用新进展2009-10-22 0
-
风光互补技术原理及最新进展2009-10-26 0
-
DIY怀表设计正式启动,请关注最新进展。2012-01-13 0
-
车联网技术的最新进展2018-09-21 0
-
介绍IXIAIP测试平台和所提供测试方案的最新进展2021-05-26 0
-
ITU-T FG IPTV标准化最新进展如何?2021-05-27 0
-
CMOS图像传感器最新进展及发展趋势是什么?2021-06-08 0
-
VisionFive 2 AOSP最新进展即将发布!2023-10-08 0
-
中国龙芯CPU及产品最新进展2011-12-07 27806
-
UWB通信技术最新进展及发展趋势2017-02-07 965
-
Topic医疗开发平台的最新进展2018-11-22 3307
-
工业机器人市场的最新进展浅析2018-12-14 1122
-
ASML***的最新进展2023-07-30 2327
-
5G最新进展深度解析.zip2023-01-13 343
全部0条评论

快来发表一下你的评论吧 !
