

什么是Cortex,怎样驱动着智能合约和区块链的功能
区块链
描述
2009 年 1 月 3 日,比特币作为一种自持的 P2P 系统启动了创世区块,以巧妙的设计驱使参与者维持它的运转,并提供受限但极具颠覆性的金融功能至今。2015 年 6月 30 日,以太坊上线,为区块链增加了图灵完备的智能合约,可以对一些短小的程序的执行结果形成共识。相对于比特币,以太坊可以执行更复杂的计算,提供更丰富的响应,然而这些合约是不具备学习能力和自我进化规则的,是纯粹的基于简单规则(rule-based) 与递归调用的子程序的集合。参考 Conway 的生命游戏,基于 P2P 技术的虚拟货币网络可以被界定为生存在互联网上的生命,通过提供金融功能维持自身的存在,只要还有一个全节点在,网络的状态就可以得到保存,并且能够响应来自外界的交互。然而人类渴望的智能还没有出现,这些原始的网络生命只停留在简单规则的水平。
Cortex 在此基础上更进一步,为区块链增加了人工智能的共识推断,所有全节点共同运作,对一个要求人工智能的智能合约的执行达成共识,为系统赋予智能响应的能力。Cortex 作为一条兼容 EVM 智能合约的独立公链,可以运行现有的合约和带有人工智能推断的合约,在创世区块发布后,也将作为一个更加智能的网络生命永续存在下去。在 Cortex 中,由于开源和天然的竞争机制,最优秀的模型终将会存留下来,提升网络的智能水平。从机器学习研究者的角度来讲,Cortex 平台集合了各种基本智能应用的公开模型,并且是当前的世界级水准 (state of the art),这将大大加速他们的研究,并朝向 AI in All 的智能世界快速前进。这条公链同时使得模型在部署后的计算结果自动地得到全网公证。外星人存在与否我们尚不可知,但有人工智能的陪伴,人类不再孤独前行。
系统架构
1.扩充智能合约和区块链的功能
Cortex 智能推断框架
模型的贡献者将不限于 Cortex 团队,全球的机器学习从业人员都可以将训练好的相应数据模型上传到存储层,其他需要该数据模型的用户可以在其训练好的模型上进行推断,并且支付费用给模型上传者。每次推断的时候,全节点会从存储层将模型和数据同步到本地。通过 Cortex 特有的虚拟机 CVM (Cortex Virtual Machine) 进行一次推断,将结果同步到全节点,并返回结果。
将需要预测的数据进行代入计算到已知一个数据模型获得结果就是一次智能推断的过程。用户每发起一笔交易,执行带有数据模型的智能合约和进行推断都需要支付一定的 Endorphin,每次支付的 Endorphin 数量取决于模型运算难度和模型排名等。Endorphin和 Cortex Coin 会有一个动态的转换关系,Endorphin 的价格由市场决定,反映了Cortex 进行模型推断和执行智能合约的成本。这部分 Endorphin 对应的 Cortex Coin会分成两个部分,一部分支付给智能合约调用 Infer 的模型提交者,另一部分支付给矿工作为打包区块的费用。对于支付给模型提交者的比例,Cortex 会为这个比例设定一个上限。
ortex 在原有的智能合约中额外添加一个 Infer 指令,使得在智能合约中可以支持使用 Cortex 链上的模型。
下述伪代码表述了如何在智能合约里使用 Infer ,当用户调用智能合约的时候就会对这个模型进行一次推断:
模型提交框架
前面分析了链上训练的难处和不可行性,Cortex 提出了链下 (Offchain) 进行训练的提交接口,包括模型的指令解析虚拟机。这能够给算力提供方和模型提交者搭建交易和合作的桥梁。
用户将模型通过 Cortex 的 CVM 解析成模型字符串以及参数,打包上传到存储层,并发布通用接口,让智能合约编写用户进行调用。模型提交者需要支付一定的存储费用得以保证模型能在存储层持续保存。对智能合约中调用过此模型进行 Infer 所收取的费用会有一部分交付给模型提交者。提交者也可以根据需要进行撤回和更新等操作。对于撤回的情况,为了保证调用此模型的智能合约可以正常运作,Cortex 会根据模型的使用情况进行托管,并且保持调用此模型收取的费用和存储维护费用相当。Cortex 同时会提供一个接口将模型上传到存储层并获得模型哈希。之后提交者发起一笔交易,执行智能合约将模型哈希写入存储中。这样所有用户就可以知道这个模型的输入输出状态。
智能 AI 合约
Cortex 允许用户在 Cortex 链上进行和机器学习相关的编程,并且提交一些依赖其他合约的交互,这将变得十分有趣。比如以太坊上运行的电子宠物 Cryptokitties ,宠物之间的交互可以是动态的、智能的、进化的。通过用户上传的增强学习模型,赋予智能合约结合人工智能,可以很方便的实现类似带有人工智能的各种应用。
同时 Cortex 为其他链提供 AI 调用接口。比如在比特币现金和以太坊上,Cortex 提供基于人工智能的合约钱包地址上分析的调用结果。那些分析地址的模型将将不仅有助于监管科技 (RegTech),也能给一般用户提供转账目标地址的动态风险评估。
2.模型和数据存储
Cortex 链并不实际存储模型和数据,只存储模型和数据的 Hash 值,真正的模型和数据存储在链外的 key-value 存储系统中。新模型和新数据在节点上有足够多的副本之后将可以在链上可用。
3.Cortex 共识推断标准
当用户发起一笔交易到某个合约之后,全节点需要执行该智能合约的代码。Cortex 和普通智能合约不同的地方在于其智能合约中可能涉及推断指令,需要全节点对于这个推断指令的结果进行共识。整个全节点的执行流程是:
1. 全节点通过查询模型索引找到模型在存储层的位置,并下载该模型的模型字符串和对应的参数数据。
2. 通过 Cortex 模型表示工具将模型字符串转换成可执行代码。
3. 通过 Cortex 提供的虚拟机 CVM ,执行可执行代码,得到结果后进行全节点广播共识。
Cortex 模型表示工具的作用可以分为两部分:
1. 模型提交者需要将自己编写的模型代码通过模型表示工具转化为模型字符串之后才可以提交到存储层。
2. 全节点下载模型字符串之后通过模型表示工具提供的转换器转换成可执行代码后,在 Cortex 虚拟机中执行推断操作。
Cortex 虚拟机的作用在于全节点的每次推断执行都是确定的。
4.如何挑选优秀的模型
Cortex 链不会对模型进行限制,用户可以依靠模型 infer 的调用次数作为相对客观的模型评价标准。当模型使用者对模型有不计计算代价的高精度需求时,Cortex 支持保留
原有模型参数使用浮点数来表示。从而,官方或者第三方机构可以通过自行定义对模型的排序机制(召回率,准确率,计算速度,基准排序数据集等),达成模型的甄选工作,并展示在第三方的网站或者应用中。
5 共识机制:PoW 挖矿
一直以来,一机一票的加密数字货币社区设想并未实现。原因是 ASIC 的特殊设计使得计算加速比得到大幅提升。社区和学术界探索了很多内存瓶颈算法来对显卡和 CPU 挖矿更加友好,而无需花费大量资金购买专业挖矿设备。近年来社区实践的结果显示,以太坊的 Dagger-Hashimoto和 Zcash 的 Equihash是比较成功的显卡优先原则的算法实践。
Cortex 链将进一步秉承一机一票优先,采用 Cuckoo Cycle 的 PoW 进一步缩小 CPU和显卡之间加速比的差距。同时 Cortex 链将充分发掘智能手机显卡的效能,使得手机和桌面电脑的显卡差距符合通用硬件平台测评工具(如 GFXBench )的差距比例:比如,最好的消费级别显卡是最好的手机显卡算力的 10-15 倍。考虑到手机计算的功耗比更低,使得大规模用户在夜间充电时间利用手机挖矿将变得更加可行。
特别值得注意的一点是,出块加密的共识算法和链上的智能推断合约的计算并没有直接联系,PoW 保障参与挖矿的矿工们硬件上更加公平,而智能计算合约则自动提供公众推理的可验证性。
6.防作弊以及模型筛选
由于模型是完全公开的,所以可能会有模型被复制或抄袭等现象发生。在一般情况下,如果是一个非常优秀的模型,往往上线之后就会有很高的使用量,而针对这些模型进行抄袭并没有很大优势,但是,在一些特殊情况下,对一些很明显的抄袭或者完全复制的行为,Cortex 会进行介入并且仲裁,并通过链上 Oracle 的方式公示。
软件方案
1.CVM:EVM + Inference
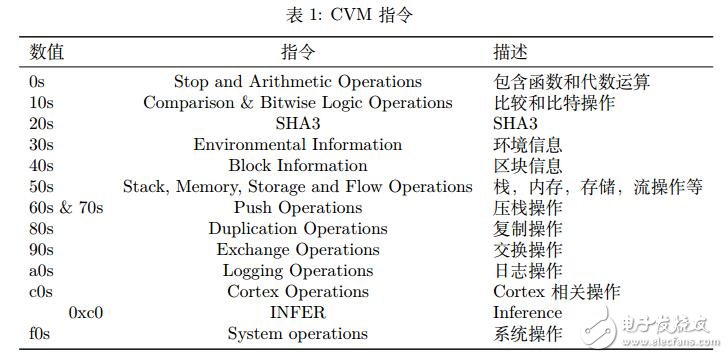
Cortex 拥有自己的虚拟机,称为 Cortex Virtual Machine(CVM)。CVM 指令集完全兼容 EVM,此外,CVM 还提供对于推断指令的支持。Cortex 将在 0xc0 加入一个新的 INFER 指令。这条指令的输入是推断代码,输出是推断结果。CVM 使用的虚拟机指令包含的内容在表 1中说明。
2.Cortex 核心指令集与框架标准
人工智能的典型应用——图像问题,语音/语义/文本问题,与强化学习问题无一例外的需要以下张量操作。Cortex 以张量操作的代价作为 Endorphin 计费的一种潜在锚定手段,剖析机器学习以及深度学习的核心指令集。在不同计算框架中,这一术语往往被称为网络层 (network layer) 或者操作符 (operator)。
• 张量的计算操作,包括:
– 张量的数值四则运算:输入张量,数值与四则运算符
– 张量之间的按位四则运算:输入两个张量与四则运算符
– 张量的按位函数运算:输入张量与乘方函数、三角函数、幂与对数函数、大小判断函数、随机数生成函数、取整函数等。
– 张量的降维运算:输入张量与满足结合律、交换律的操作符。
– 张量之间的广播运算:输入张量,用维度低张量补齐维度后进行按位操作。
– 张量之间的乘法操作:以 NCHW/NHWC 张量存储模式为例,包含张量与矩阵、矩阵与向量等张量乘法/矩阵乘法操作。
• 张量的重构操作,包括:
– 维度交换,维度扩张与维度压缩
– 按维度排序
– 值补充
– 按通道拼接
– 沿图像平面拼接/剪裁
• 神经网络特定操作
– 全连接
– 神经网络激发函数主要依赖张量的按位函数运算的操作
– 1 维/2 维/3 维卷积(包括不同尺度卷积核、带孔、分组等选项)
– 通过上采样实现的 1 维/2 维/3 维反卷积操作与线性插值操作
– 通用辅助运算(如对一阶/二阶信息的统计 BatchNorm)
– 图像类辅助计算(如可形变卷积网络的形变参数模块)
– 特定任务辅助计算(如 ROIPooling, ROIAlign 模块)
Cortex 的核心指令集已覆盖主流的人工智能计算框架操作。受制于不同平台上 BLAS的实现,Cortex 把拥有浮点数 (Float32, Float16) 参数的 Cortex 模型通过 DevKit 转化为定点数(INT8, INT6)参数模型 (Wu et al. [9]Han et al. [10]),从而支持跨平台的推断共识。
3.Cortex 模型表示工具
Cortex 模型表示工具创建了一个开放,灵活的标准,使深度学习框架和工具能够互操作。它使用户能够在框架之间迁移深度学习模型,使其更容易投入生产。Cortex 模型表示工具作为一个开放式生态系统,使人工智能更容易获得,对不同的使用者都有价值:人工智能开发人员可以根据不同任务选择正确的框架,框架开发人员可以专注于创新与更新,硬件供应商可以针对性的优化。例如,人工智能开发人员可以使用 PyTorch等框架训练复杂的计算机视觉模型,并使用 CNTK 、Apache MXNet 或者 TensorFlow进行推断。
模型表示的基础是关于人工智能计算的 Cortex 核心指令集的规范化。随着人工智能领域研究成果、软件框架、指令集、硬件驱动、硬件形式的日益丰富,工具链碎片化问题逐渐突显。很多新的论文站在前人的工作基础上进行微创新;理论过硬的科研成果得到的模型、数据、结论并不是站在过去最佳成果之上进行进一步发展,为精度的提高带来天花板效应;工程师为了解决特定问题而设计的硬编码更加无法适应爆发式增长的数据。
Cortex 模型表示工具被设计为
• 表征:将字符串映射为主流神经网络模型、概率图模型所支持的最细粒度的指令集
• 组织:将指令集映射为主流神经网络框架的代码
• 迁移:提供同构检测工具,使得不同机器学习/神经网络框架中相同模型可以互相迁移
4.存储层
Cortex 可以使用任何 key-value 存储系统来存储模型,可行的选择是 IPFS 和 libtorrent。Cortex 的数据存储抽象层并不依赖于任何具体的分布式存储解决方案,分布式哈希表或者 IPFS 都可以用来解决存储问题,对于不同设备,Cortex 采取不同策略:
• 全节点常年存储公链数据模型
• 手机节点采取类似比特币轻钱包模式,只存储小规模的全模型
Cortex 只负责共识推断,不存储任何训练集。为了帮助合约作者筛选模型,避免过拟合的数据模型难题,合约作者可以提交测试集到 Cortex 披露模型结果。
一条进入合约级别的调用,会在内存池 (Mempool) 中排队,出块后,将打包进入区块确认交易。缓存期间数据会广播到包括矿池的全节点。Cortex 当前的存储能力,能够支持目前图片、语音、文字、短视频等绝大部分典型应用,足以覆盖绝大多数人工智能问题。对于超出当前存储限制的模型和数据,比如医疗全息扫描数据,一条就可能几十个 GB ,将在未来 Cortex 提升存储限制后加入支持。
对于 Cortex 的全节点,需要比现有比特币和以太坊更大的存储空间来存储缓存的数据测试集和数据模型。考虑到摩尔定律 (Moore’s Law),存储设备价格将不断下降,因此不会构成障碍。对于每个数据模型,Metadata 内将建立标注信息,用来进行链上调用的检索。Metadata 的格式在表 2中表述。

5.模型索引
Cortex 存储了所有的模型,在全节点中,对于每笔需要验证的交易,如果智能合约涉及共识推断,则需要从内存快速检索出对应的模型进行推断。Cortex 的全节点内存将为本地存储的模型建立索引,根据智能合约存储的模型地址去检索。
6.模型缓存
Cortex 的全节点存储能力有限,无法存下全网所有模型。Cortex 引入了缓存来解决这个问题,在全节点中维护一个 Model Cache 。Model Cache 数据模型的替换策略,有最近最常使用(LRU)、先进先出(FIFO)等,也可以使用任何其他方案来提高命中率。
7.全节点实验
针对全节点执行推断指令的吞吐情况,本章描述了一些在单机上实验的结果。测试平台配置为:
• CPU: E5-2683 v3
• GPU: 8x1080Ti
• 内存: 64 GB
• 硬盘: SSD 960 EVO 250 GB
实验中使用的测试代码基于 python 2.7 和 MXNet ,其中主要包含以下模型:
• CaffeNet
• Network in Network
• SqueezeNet
• VGG16
• VGG19
• Inception v3 / BatchNorm
• ResNet-152
• ResNet101-64x4d
所有模型都可以在 MXNet 的文档 1 中找到。实验分别在 CPU 和 GPU 中测试这些模型在平台上的推断速度,这些测试不考虑读取模型的速度,所有模型会提前加载到内存或者显存中。
测试结果如表 3,括号中是 Batch Size(即一次计算所传入的数据样本量),所有 GPU测试结果都是在单卡上的测试。
以上是单机测试的结果。为了模拟真实的情况,试验平台上设置 10 万张的图片不断进行推断,每次推断选择随机的模型来进行并且 Batch Siz e 为 1,图片发放到 8 张带有负载均衡的显卡上。对于两种情况:
1. 所有模型都已经读取完毕并存放到显存中,其单张图片推断的平均速度为 3.16ms。
2. 每次重新读取数据(包括模型和输入数据)而不是提前加载进显存,但是进行缓存,其单张图片推断的平均速度为 113.3 ms。
结论 全节点在模型已经预读到显存之后,支持负载均衡,并且将同一模型进行显卡间并行推断,测试结果大约每秒能执行接近 300 次的单一推断。如果在极端情况下不进行显存预读,而只是进行缓存,每次重新读取模型和输入数据,大约每秒能进行 9 次左右的单一推断。以上实验都是在没有优化的情况下进行的计算,Cortex 的目标之一是致力于不断优化提高推断性能。
硬件方案
1.CUDA and RoCM 方案
Cortex 的硬件方案大量采用了 NVidia 公司的 CUDA 驱动与 CUDNN 库作为显卡计算的开发框架。同时,AMD OpenMI 软件项目采用了 RoCM 驱动与 HIP/HCC 库人工智能研发计划, 并计划在 2018 年底推出后支持的开发框架。
2.FPGA 方案
FPGA 产品的特性是低位定点运算 (INT8 甚至 INT6 运算),延时较低,但是计算功耗较高,灵活性较差;在自动驾驶领域、云服务领域已经有较好的深度学习部署方案。Cortex 计划对 Xilinx 与 Altera 系列产品提供 Infer 支持。
3.全节点的硬件配置需求 - 多显卡和回归传统的 USB 挖矿
不同于传统的比特币和以太坊全节点,Cortex 对全节点的硬件配置需求较高。需要比较大的硬盘存储空间和多显卡桌面主机来达到最佳确认速度的性能,然而这并不是必需的。在比特币领域 USB 曾经是一种即插即用的比特币小型 ASIC 矿机,在大规模矿厂形成之前,这种去中心化的挖矿模式,曾经风靡一时,Cortex 全节点在缺少显卡算力的情况下可以配置类似的神经网络计算芯片或计算棒,这些设备已经在市场上逐渐成熟。与 USB 挖矿不同的是,计算芯片是做全节点验证的硬件补足,并非计算挖矿具体过程中需要的设备。
4.现有显卡矿厂需要的硬件改装措施
对于一个现有显卡算力的矿厂,特别是有高端显卡的矿厂,Cortex 提供改造咨询服务和整体技术解决方案,使得矿厂具有和世界一流 AI 公司同等水平的智能计算中心,硬件性价比将远远超过现有商用 GPU 云,多中心化的矿厂有机会出售算力给算法提供者,或者以合作的方式生成数据模型,和世界一流的互联网、AI 公司同场竞技。具体的改造策略有:
• 主板和 CPU 的定制策略,满足多路 PCI-E 深度学习的数据传输带宽
• 万兆交换机和网卡的硬件解决方案
• 存储硬件和带宽解决方案
• 相关软件在挖 Cortex 主链、挖其他竞争显卡币和链下深度学习训练之间自动切换
• 相关的手机端监控收益、手动切换等管理软件
5. 手机设备和物联网设备挖矿和计算
平衡异构计算芯片 (CPU)、显示芯片 (GPU)、FPGA 与 ASIC 计算模块的算力收益比例,从而更加去中心的进行工作量证明挖矿,一直是主链设计的难点,特别是能够让算力相对弱小的设备,比如手机和 IoT 设备参与其中。同时,由于目前市场上的手机设备已经出现了支持 AI 计算的芯片或者计算库、基于手机 AI 芯片的计算框架也可以参与智能推断,只不过全节点的数据模型相对较大,移动端需要定制对可执行数据模型的规模做筛选。Cortex 主链将发布 Android 和 iOS 客户端 App:
• 闲置中具有显卡算力的设备能通过 SoC 、ARM 架构的 CPU/GPU 参与挖矿,比如市场中,电视盒子的显卡性能其实已经很不错了,而 90% 时间基本都在闲置
• 用户手机在上班充电和睡觉充电中都可以参与挖矿,只要算法上让手机的显卡得到公平的收益竞争力
• 手机或其他配有 AI 芯片的设备,能够自动在主链出块和执行智能推断之间切换
手机端的推断能力可能会受到芯片供应商的软件技术限制,不同软件供应商正在封装不同的计算协议,Cortex 将负责抽象层接口的编写和轻智能客户端的筛选。
代币模型
1.Cortex Coin (CTXC)
模型提交者的奖励收益
传统的区块链对于每个打包区块的奖励是直接支付给矿工的,Cortex 为了激励开发者提交更加丰富和优秀的模型,调用合约需要支付的 Endorphin 不仅仅会分配给帮助区块打包的节点矿工,还会支付给模型的提供者。费用的收取比例采用市场博弈价格,类似以太坊中 Gas 的机制。
模型提交者成本支出
为了防止模型提交者进行过度的提交和存储攻击 - 比如,随意提交几乎不可用的模型以及频繁提交相同模型从而占用存储资源 - 每个模型提交者必须支付存储费用。这样可以促使模型提交者提交更加优秀的模型。这样调用者更多,模型提交者收益更大。
模型复杂度和 Endorphin 的耗费
Endorphin 用来衡量在推断过程中将数据模型带入合约时,计算所耗费的虚拟机级别硬件计算资源,Endorphin 的耗费正比于模型大小,同时 Cortex 也为模型的参数大小设置了 8GB 的上限,对应最多约 20 亿个 Float32 的参数。
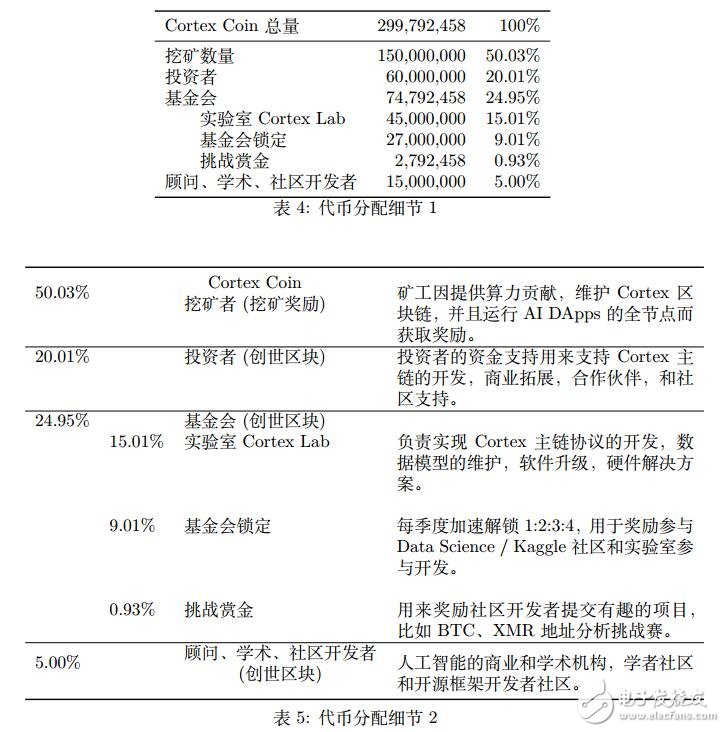
2.代币分配
Cortex Coin (CTXC) 数量总共为 299,792,4582个。其中 60,000,000 (20.01%) 分配给早期投资者。
3 代币发行曲线
Cortex Coin 发行总量为 299,792,458 个,其中 150,000,000 的 Cortex Coin 可以通过挖矿获得。
第一个 4 年 75,000,000
第二个 4 年 37,500,000
第三个 4 年 18,750,000
第四个 4 年 9,375,000
第五个 4 年 4,687,500
…
依此类推,发行量按每四年减半。
-
#硬声创作季 #区块链 区块链技术与应用-22-ETH-智能合约-9水管工 2022-10-09
-
区块链如何改变AI2018-02-27 0
-
什么是区块链 区块链有什么用2018-03-26 0
-
区块链在商业方面的应用如何2018-07-14 0
-
区块链行业发展,金融领域应用方向?2018-08-06 0
-
DENC底层架构的智能合约层与应用API2018-09-03 0
-
区块链热度不止,参考架构9个部分解密2018-09-06 0
-
什么是区块链?区块链都有哪些应用?2021-06-28 0
-
什么是智能合约?区块链智能合约漏洞又是怎么回事?2018-06-02 5095
-
区块链智能合约技术解析2018-10-10 3655
-
以太坊的智能合约在区块链中的作用是什么2018-11-12 4503
-
智能合约Oracle如何与区块链外部环境链接2018-12-20 1311
-
区块链智能合约技术特点全面分析2019-01-17 3702
-
区块链智能合约有哪些常见的漏洞2019-11-04 3474
-
区块链智能合约的原理_区块链智能合约技术的发展前景2020-07-21 6000
全部0条评论

快来发表一下你的评论吧 !
