

浅析生成式对抗网络发展的内在逻辑
电子说
描述
生成式对抗网络(Generative adversarial networks, GAN)是当前人工智能学界最为重要的研究热点之一。其突出的生成能力不仅可用于生成各类图像和自然语言数据,还启发和推动了各类半监督学习和无监督学习任务的发展。
本文概括了GAN的基本思想,并对近年来相关的理论与应用研究进行了梳理,总结了GAN常见的网络结构与训练方法,博弈形式,集成方法,并对一些应用场景进行了介绍。在此基础上,本文对GAN发展的内在逻辑进行了归纳总结。
近年来,人工智能领域,特别是机器学习方面的研究取得了长足的进步。得益于计算能力的提高,信息化工具的普及以及数据量的积累,人工智能研究的迫切性和可行性都大为提高。以Google等为代表的IT企业,利用其掌握的海量数据资源,结合新的硬件结构和人工智能算法,实现了一系列新突破和新应用,并获得了可观的收益。这些企业获得的成功进一步带动了机器学习的研究热度,使得人工智能的研究进入了一个新的高潮时期。
在此次的人工智能浪潮中,以统计机器学习,深度学习为代表的机器学习方法是主要的研究方向之一。相比符号主义的研究方法,基于机器学习的人工智能系统降低了对人类知识的依赖,转而使用统计的方法从数据中直接习得知识。机器学习理论是一次重要的范式革命,使人工智能领域的研究重点从算法设计转向了特征工程与优化方法。
一般而言,依据数据集是否有标记,机器学习任务可被分为有监督学习(又称预测性学习,数据集有标记)与无监督学习(又称描述性学习,数据集无标记)[1]。随着数据收集手段,算力与算法的不断发展,在诸多监督学习任务中,如图像识别[2-3],语音识别[4-5],机器翻译[6-7]等,机器学习方法,特别是深度学习方法都取得了目前最好的成绩。
然而,有监督学习需要人为给数据加入标签。这带来了两个问题:一是数据集采集后需要大量人力物力进行标注,大规模数据集的构建十分困难;二是对于许多学习任务,如数据生成,策略学习等,人为标注的方法较为困难甚至不可行。研究者普遍认为,如何让机器从未经处理的,无标签类别的数据中直接进行无监督学习,将是AI领域下一步要着重解决的问题。
在无监督学习的任务中,生成模型是最为关键的技术之一。生成模型是指一个可以通过观察已有的样本,学习其分布并生成类似样本的模型。深度学习的研究者在领域发展的早期就极为关注无监督学习的问题,基于神经网络的生成模型在神经网络的再次复兴中起到了极大的作用。在计算资源还未足够丰富前,研究者提出了深度信念网络(Deep belief network, DBN)[8],深度玻尔兹曼机(Deep Boltzmann machines, DBM)[9]等网络结构,这些网络将受限玻尔兹曼机(Restricted Boltzmann machine, RBM)[10],自编码机(Autoencoder, AE)[11]等生成模型作为一种特征学习器,通过逐层预训练的方式加速经网络的训练[12]。
然而,早期的生成模型往往不能很好地泛化生成结果。随着深度学习的进一步发展,研究者提出了一系列新的模型。生成式对抗网络(Generative adversarial networks, GAN)是生成式模型最新,也是目前最为成功的一项技术,由Goodfellow等在2014年第一次提出[13]。
GAN的主要思想是设置一个零和博弈,通过两个玩家的对抗实现学习。博弈中的一名玩家称为生成器,它的主要工作是生成样本,并尽量使得其看上去与训练样本一致。另外一名玩家称为判别器,它的目的是准确判断输入样本是否属于真实的训练样本。一个常见的比喻是将这两个网络想象成伪钞制造者与警察。GAN的训练过程类似于伪钞制造者尽可能提高伪钞制作水平以骗过警察,而警察则不断提高鉴别能力以识别伪钞。随着GAN的不断训练,伪钞制造者与警察的能力都会不断提高[14]。
GAN在生成逼真图像上的性能超过了其他的方法,一经提出便引起了极大的关注。尤为重要的是,GAN不仅可作为一种性能极佳的生成模型,其所启发的对抗学习思想更渗透进深度学习领域的方方面面,催生了一系列新的研究方向与应用[15]。
本文梳理了生成式对抗网络的最新研究进展,并对其发展趋势进行展望。第1节介绍了GAN的提出背景、基本思想与原始GAN存在的缺陷;第2节介绍了GAN在生成机制方面的改进;第3节介绍了GAN在判别机制方面的改进;第4节对GAN的应用发展进行了介绍;最后总结了GAN领域研究的内在逻辑与存在的问题,并对其下一步发展做出展望。
1. GAN的背景与提出
GAN是在深度生成模型的基础上发展而来,但又与以往的模型有显著区别。本节首先简要介绍深度学习与深度生成模型的基本思想与发展历史,然后介绍原始GAN的模型结构与训练方法,最后讨论原始GAN中存在的不足。
1.1 深度学习
深度学习是机器学习的一种实现方法。相比一般的机器学习方法,深度学习最主要的区别是不依赖人工进行特征工程。研究者认为,手工设计的特征描述子往往过早地丢失掉有用信息,直接从数据中学习到与任务相关的特征表示,比手工设计特征更加有效[16]。
深度学习使用多层神经网络(Multilayer neural network)[17]对数据进行表征学习。相比传统的神经网络方法,深度学习主要在四方面进行了突破:1)使用了卷积神经网络(Convolutional neural network, CNN)[18-19],递归神经网络(Recurrent/recursive neural network, RNN)[20-22]等特殊设计的网络结构,这些新的网络结构大大加强了神经网络的建模能力;2)使用了整流线性单元(Rectified linear unit, ReLU)[23]、Dropout[24]、Adam[25]等新的激活函数、正则方法与优化算法,这些新的训练技术有效提高了神经网络的收敛速度,使得大规模的神经网络训练成为可能;3)使用了图形处理器(Graphics processing unit, GPU)[2,26]、现场可编程逻辑门阵列(Field-programmable gate array, FPGA)[27]、应用定制威廉希尔官方网站 (Application-specific integrated circuit, ASIC)[28]以及分布式系统[29]等新的计算设备与计算系统,这些设备使得神经网络的训练时间大大缩短,从而具有被实际部署的可能性;4)形成了较为完善的开源社区,出现了Theano[30],Torch[31-32],Tensorflow[33]等被广泛使用的算法库,开源社区的发展降低了深度学习的应用门槛,提高了该领域新发现的可重复性,吸引了越来越多的研究者加入研究行列。
深度学习在模型、算法、硬件设施与开发社区四方面的突破改变了过往神经网络优化困难,应用受限,计算缓慢,认可度不高的问题,使得该技术的影响力不断扩大。目前,深度学习已成为人工智能研究中的一种主流方法。深度学习在监督学习任务,尤其是在图像识别[34]任务上的突破尤为令人瞩目。
1.2 深度生成模型
无监督学习具有重要的研究与应用价值。其一是有标记的数据较为稀缺,或是数据的标注与所希望研究的问题不直接相关,此时必须使用无监督或半监督学习的方法[35];其二是高层次的表征学习有助于其他任务的学习,可以帮助模型避免陷入局部最优点,或是添加一定的限制使得模型泛化能力提高[36];其三是在一些强化学习的场景下,我们无法得知未来任务的具体形式,而仅知道这些任务与环境有较为确定性的关系。无监督学习可提高代理(Agent)对环境的预测能力,从而有效提高代理的表现水平[37];最后,对于一些问题我们希望有多样化的回答而不仅仅是返回一个确定性的答案,有监督学习到的模型无法实现这一要求[14;36]。
生成模型是无监督学习的核心任务之一。虽然深度学习在早期研究中使用了自编码机,受限玻尔兹曼机等一系列生成模型,但这些模型往往会出现过拟合现象,不能很好地泛化以生成多样性样本。
为了解决这一问题,研究者提出了一种名为随机反向传播(Stochastic back-propagation)[38]的方法。通过加入额外的独立于模型的随机输入z,我们可以将确定性的神经网络f(x)转化为具有随机性的f(x;z),并使用反向传播的方法进行训练。这一方法可以提高生成模型输出样本的多样性。
以变分自编码机(Variational auto-encoder, VAE)[39]为例。如图1所示,VAE的一种简单实现是假设生成样本x为高斯分布,即

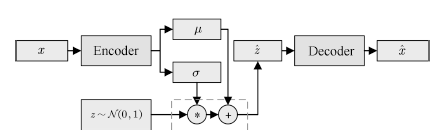
图1 变分自编码机
Fig.1 Variational auto-encoder
若将某一随机变量直接输入网络中,由于此时 与输入x的关系不唯一,网络可能出现优化困难的问题。我们可以通过设置随机变量z ~ N (0, 1),并构建编码器网络μ = g1 (x), σ = g2 (x), 原网络转化为
与输入x的关系不唯一,网络可能出现优化困难的问题。我们可以通过设置随机变量z ~ N (0, 1),并构建编码器网络μ = g1 (x), σ = g2 (x), 原网络转化为
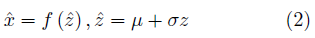
通过反向传播算法,网络可以获得更好的均值与标准差估计,不断提高生成模型的生成效果。在VAE的工作中,这一方法被称为重参数化技巧(Reparameterization trick)。
深度学习与随机反向传播方法的出现使得使用神经网络生成复杂随机样本成为可能,如何使得生成样本在具备多样性的同时保持原样本的模式特征成为了主要的研究问题。
1.3 生成式对抗网络
Goodfellow等提出了生成式对抗网络模型。GAN由一组对抗性的神经网络构成(分别称为生成器和判别器),生成器试图生成可被判别器误认为真实样本的生成样本。与其他生成模型相比,GAN的显著不同在于,该方法不直接以数据分布和模型分布的差异为目标函数,转而采用了对抗的方式,先通过判别器学习差异,再引导生成器去缩小这种差异。生成器G接受隐变量z作为输入,参数为θ。判别器D的输入为样本数据x或是生成样本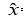 = G(z),参数为Φ。GAN的网络结构如图2所示:
= G(z),参数为Φ。GAN的网络结构如图2所示:
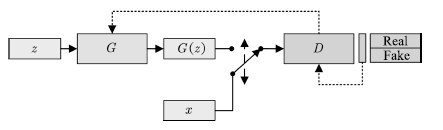
图 2 生成式对抗网络
Fig.2 Generative adversarial networks
GAN中的生成器与判别器可被视作博弈中的两个玩家。两个玩家有各自的损失函数J (G) (θ, φ) 与 J (D) (θ, φ),训练过程中生成器和判别器会更新各自的参数以极小化损失。GAN的训练实质是寻找零和博弈的一个纳什均衡解,即一对参数 (θ, φ) 使 得 θ 是 J (G)的一个极小值点, 同时 φ 是J (D 的一 个极小值点. 两个玩家的损失函数都依赖于对方的参数, 但是却不能更新对方的参数, 这与一般的优化 问题有很大的不同.
在 GAN 的原始论文中, Goodfellow 将判别器的损失函数定义为一个标准二分类问题的交叉熵. 真实样本对应的标签为 1, 生成样本对应的标签则为 0. J (D的形式为
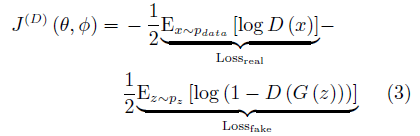
对于生成器的损失函数,根据博弈形式的不同有所区别。对于最简单的零和博弈,生成器的损失即为判别器所得:

在这一设定下,我们可以认为,GAN的关键在于优化一个关于判别器的值函数:
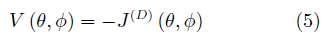
此时,GAN的训练可以看作一个min-max优化过程:
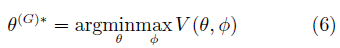
相比以往的生成模型,GAN模型具有以下几点明显的优势:一是数据生成的复杂度与维度线性相关,对于较大维度的样本生成,仅需增加神经网络的输出维度,不会像传统模型一样面临指数上升的计算量;二是对数据的分布不做显性的限制,从而避免了人工设计模型分布的需要;三是GAN生成的手写数字、人脸、CIFAR-10等样本较VAE、PixelCNN等生成模型更为清晰[14]。然而,原始GAN模型也存在许多问题。
1.4 GAN存在的问题
阻碍原始GAN发展的首要问题是不收敛问题。对于有明确目标函数的深度学习问题,一般可以使用基于梯度下降的优化算法加以训练。GAN的训练与这类问题不同,其目的是要找到一个纳什均衡点。由于一个玩家沿梯度下降的更新过程可能导致另一个玩家的误差上升,在二者行为可能彼此抵消的情况下,目前没有理论分析证明GAN总可以达到一个纳什均衡点。在实践中,生成式对抗网络通常会产生振荡,这意味着网络在生成各种模式的样本之间徘徊,从而无法达到某种均衡。一种常见的问题是GAN将若干不同的输入映射到相同的输出点,如生成器输出了包含相同颜色与纹理的多幅图片,这种非收敛情形被称为模式坍塌(Model collapse,又称the Helvetica scenario)。
其次,原始GAN只能用于生成连续数据,无法生成离散数据(如自然语言)。从直观上理解,由于生成器每次更新后的输出是之前的输出加判别器回传的梯度,其输出必须是连续可微的。更进一步地,有研究者指出,是由于原始GAN论文中使用了Jensen-Shannon(JS)散度JSD(Pr||Pg)作为衡量生成样本的度量标准[40],即使使用词的分布或embedding等连续的表示方法也无法实现很好的离散数据生成。
最后,相比其他的生成模型,GAN的评价问题更加困难。与VAE不同,GAN的输入仅有随机数据,无法使用MAE等重构指标进行衡量。一般而言,除了通过人类测试员对生成样本进行评价外,研究者还使用Inception score(IS)[41],Frechet inception distance(FID)[42-43]等方法评价生成图像,使用BLEU分数评判机器翻译质量[44]。由于这种方式可以自动进行大规模的评估与展示,研究者往往将在这些自动化评价指标上的提升作为主要的贡献。
然而,有研究指出,在评价分数上的提升更可能来自计算资源与调参技巧上的改进,而非算法上的突破[45]。此外,对于图像生成任务而言,基于概率估计的评价方法与视觉评价方法相互独立,一个具有更高评价分数的模型并不能必然地产出更高质量的样本[46]。在实际中,研究者需要根据具体目的去选择合适的评价指标。
2. GAN生成机制的发展
面对原始GAN的种种不足,研究者从多个方面尝试加以解决。在生成机制方面,研究者主要利用了深度学习在有监督学习任务上取得的成果对GAN加以改进。主要包括了使用新的网络结构、添加正则约束、集成多种模型、改变优化算法等改进。需要说明的是,这四类方法往往会同时出现在一个工作中,本文根据它们的主要贡献作为分类依据。
2.1 网络结构
DCGAN[47]是GAN发展早期比较典型的一类改进。卷积神经网络(Convolutional neural network, CNN)是图像处理任务中常用的一种网络结构,被认为可以自动提取图像的特征[36]。DCGAN将生成器中的全连接层用反卷积(Deconvolution)层[48]代替,在图像生成的任务中取得了很好的效果,其参数设置如图3所示。此后,使用GAN进行图像生成任务时,默认的网络结构一般都与DCGAN类似的设置。目前,GAN在网络结构方面的改进主要通过添加额外信息或是对隐变量进行特殊处理来实现。研究人员发现使用半监督的方式,如添加图像分类标签的方法会极大地提高GAN生成样本的质量[41]。这可能是由于添加了图像标签等信息后,GAN会更关注对于阐释样本相关的统计特征,并忽略不太相关的局部特征。

图3 DCGAN的拓扑结构[47]
Fig.3 Schematic of DCGAN architecture[47]
基于这种猜想,条件生成式对抗网络(Conditional GAN,CGAN)[49]提出了一种带条件约束的GAN,在生成模型G和判别模型D的建模中均引入条件变量c,使用额外信息对模型增加条件,以指导数据的生成过程。CGAN结构如图4所示。
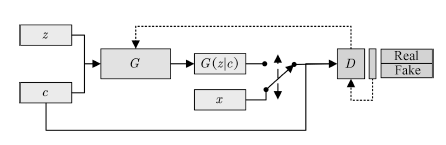
图4 CGAN的拓扑结构
Fig.4 Schematic of CGAN architecture
CGAN中的条件变量c一般为含有特定语义信息的已知条件,如样本的标签。生成器接受噪声z与条件变量c,生成样本G(z|c)与相同条件变量c控制下的真实样本一起用于训练判别器。相应的,CGAN的目标函数为:
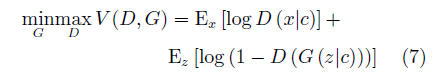
ACGAN[50]是CGAN作者的后续工作。它在判别器D的真实数据x也加入了类别c的信息,进一步告诉G网络该类的样本结构如何,从而生成更好的类别模拟。
InfoGAN[51]发展了这种思想。通过引入互信息量,InfoGAN不仅免去了使用标注数据的必要性,还使得GAN的行为具有了一定的可解释性。InfoGAN的结构如图5所示。
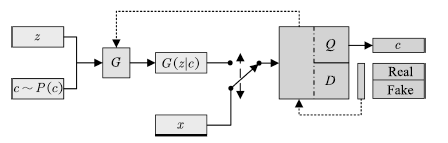
图5 InfoGAN的拓扑结构
Fig.5 Schematic of InfoGAN architecture
InfoGAN的生成器与CGAN类似,同时接受噪声z与服从特定分布的隐变量c作为输入。与CGAN不同的是,InfoGAN接受的隐变量并非已知信息,其含义需要在训练过程中去发现。判别器会输出与原始GAN类似的判断,同时InfoGAN还有一个额外的解码器Q,用于输出解码后的条件变量Q(c|x)。InfoGAN的目标函数为原始GAN的目标函数加上条件变量与生成样本间的互信息,即:
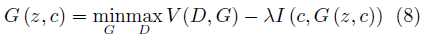
其中第二项为互信息量约束:
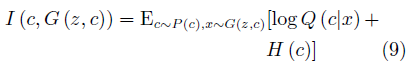
λ是该约束项的超参数。互信息量约束使得输入的隐变量c对生成数据的解释性越来越强。
除了有助于提高GAN的生成质量,该类网络还可实现生成指定类随机样本的功能。CGAN通过直接在网络输入中加入条件信息c以达到输出特定类别样本的目的。InfoGAN可以通过调整隐变量实现改变生成数字的倾斜角度,对人脸的三维模型进行旋转等操作。
除了在目标函数中对隐变量添加约束外,部分工作利用自编码机可学习隐变量表示的性质对GAN进行了改进。以VAE-GAN[52]为例,该模型将变分自编码机与GAN结合,其结构如图6所示。
该类模型同时训练GAN与VAE模型,其目标函数由三部分组成:
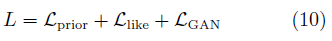

图6 VAE/GAN的拓扑结构
Fig.6 Schematic of VAE/GAN architecture
其中, 为GAN模型的目标函数,
为GAN模型的目标函数,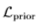 为VAE的先验约束
为VAE的先验约束
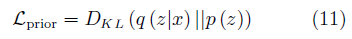
p(z)为隐变量z的先验分布,q(z|x)为编码器Encoder(x)的输出分布。
 为VAE的重构损失函数,根据具体的目的往往有不同形式。通过AE+GAN的设计模式,该类方法可以提供具有更丰富信息的隐变量以提高生成质量。通过设计不同的自编码机目标函数,研究者还提出了Denoise-GAN[53]、Plug&Play GAN[54]、α-GAN[55]等模型变体。该类模型可以获得较高清晰度的生成图像,并在3D模型的生成工作中得到较好应用[56]。
为VAE的重构损失函数,根据具体的目的往往有不同形式。通过AE+GAN的设计模式,该类方法可以提供具有更丰富信息的隐变量以提高生成质量。通过设计不同的自编码机目标函数,研究者还提出了Denoise-GAN[53]、Plug&Play GAN[54]、α-GAN[55]等模型变体。该类模型可以获得较高清晰度的生成图像,并在3D模型的生成工作中得到较好应用[56]。
2.2 正则方法
对原始GAN的另一项重要改进是使用新提出的一系列正则方法。批量规范化(Batch normalization, BN)[57]是深度学习中常用的一种正则方法。其基本思想是每次更新权值时对相应的输入做规范化操作,使得mini-batch输出结果的均值为0,方差为1。具体而言,给定一批某中间层网络的输入U = {u1, · · · , um},在使用激活函数对其进行非线性转换前,首先做如下转换:
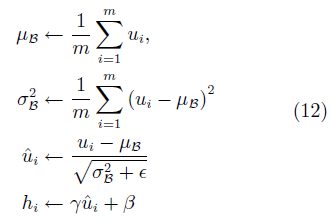
其中,γ、β为待学习的参数,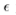 为一极小常数。正则化后,网络使用转换过的hi进行下一步操作。BN可以极大地提高神经网络有监督学习的速度。DCGAN首先将这一技术引入GAN的训练中,并取得了很好的效果。
为一极小常数。正则化后,网络使用转换过的hi进行下一步操作。BN可以极大地提高神经网络有监督学习的速度。DCGAN首先将这一技术引入GAN的训练中,并取得了很好的效果。
权值规范化(Weight normalization, WN)[58]是在有监督学习中常用的另一种正则化技术。与BN不同的是,WN主要针对神经网络的权值进行归一化,常用的方法是将网络权值除以其范数。在GAN中,常见的形式是
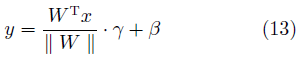
其中,W是网络的权值,γ、β为待学习的参数。实验表明,在GAN网络中使用WN可以取得比BN更好的效果[59]。
除了在有监督学习中常用的BN、WN等方法,有研究者还针对GAN提出了谱规范化(Spectral normalization,SN)[43]。该方法对判别器的各层施加操作
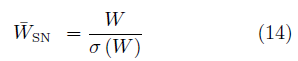
其中,σ (W )是权值的谱范数,其值等于矩阵的最大奇异值。SN可以极大地提高GAN的生成效果,SN-GANs是少数几种可以使用单一网络生成ImageNet全部1000类物体的GAN结构。
除此以外,研究者还使用了Minibatch discrimination[41]的方法,通过对批量生成样本(区别于原始GAN对单个生成样本)施加多样性约束以克服模式崩溃问题。
2.3 集成学习
集成学习(Ensemble learning)是通过构建并结合多个学习器来完成学习任务的一种方法[60-61],一般分为两类。一类是提升(Boosting)方法,通过调整样本权重,级联网络等方法将弱学习器提升为强学习器,另一类则是使用多个同类学习器对数据的不同子集进行学习后,再将学习结果通过某种方式整合(Bagging)起来。
基于Boosting思想的集成方法可以大致分为两类。一类工作为同构网络合并。此类的典型工作是AdaGAN[62]。该方法通过与AdaBoost类似的算法依次训练T个生成器模型。在第t步训练过程中,前一次未能成功生成的模式会被加大权重。每次训练后输出的模型为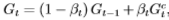 ,为一给定的超参数。 训练结束后得到一系列生成模型 G1, G2, · · · , GT及其相应权重 α1 , α2, · · · , aT ,
,为一给定的超参数。 训练结束后得到一系列生成模型 G1, G2, · · · , GT及其相应权重 α1 , α2, · · · , aT ,  。 最终的生成模型为
。 最终的生成模型为
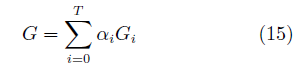
图7 StackGAN的拓扑结构
Fig.7 Schematic of stackGAN architecture
另一类工作的主要方法为网络叠加。该类方法的主要模式是串联多个GAN,将上层生成器的输出作为隐变量输入下层生成器。Stack GAN[63]是其中较为典型的工作。如图7所示,该模型的生成器由多个子模型串联构成,每级生成器Gi 接受上一级生 成器的输出 hˆi+1 及一个随机变量 zi 作为输入. 在训练时, 该方法同步训练一个编码器 Ei, 并使用其中间层的输出 hi 和生成器的中间输出一起训练.
该类工作的另一种常见方式则通过叠加不同分辨率的生成器网络来实现。以LAP-GAN[64]为例。
如图8 所示, 该模型中上一层生成器的输出Ii+1 在放大后 (记为 li ) 与随机变量 zi 一同输入下一层网络, 下一层的输出 h˜i 与 li 合并为 I˜i , I˜i 经过放大后作为再下一层的输入。
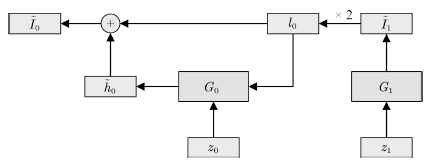
图8 LAP-GAN的拓扑结构
Fig.8 Schematic of LAP-GAN architecture
后继的PG-GAN(Progress growing of GANs)[65]通过不断加深网络层数的方法改进了这一模式。在训练过程中首先训练可输出低分辨率图像的浅层网络,再在浅层网络上增加层数。该方法可生成目前最高清晰度的图像。
基于Bagging思想的集成方法主要针对模式坍塌(Mode collapse)这一GAN训练中最常见的不收敛情况,通过使用多个网络,每个网络针对不同的模式进行训练,之后再将这些网络的输出进行整合。
这类模型中较为典型的是CoGAN[66]与MAD-GAN[67]。两者均通过集成多个共享部分权值的生成器以实现生成多样性样本的目的。两者的区别主要在于,CoGAN使用了与生成器同样数量的判别器,而MAD-GAN使用了多输出的单判别器,通过判别目标函数和基于相似性的竞争性目标函数来引导生成器。
相较于基于Boosting的集成方法,基于Bagging的GAN集成方法并没有在一般性的任务中取得显著效果。但由于Bagging方法较为直接,在个性化任务中能以较小的代价获得较大的提升。
2.4 优化算法
GAN 的优化算法是另一个重要的改进方向. GAN 使用同步梯度下降 (Simultaneous gradient ascent) 的方法优化网络,一般可以定义两个效用函 数 f (φ, θ) 与 g (φ, θ), 其中 (φ, θ) ∈ Ω1 × Ω2. 玩家 1 的目标是最大化效用函数 f , 玩家 2 的目标则是最大化效用函数 g. Ωi (i = 1, 2) 为对应玩家的可能行动空间,在GAN中,它们对应着生成器与判别器的参数取值空间。GAN博弈的相关梯度向量场(Associated gradient vector field)为
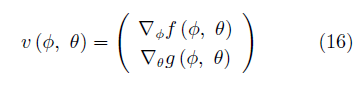
对于零和博弈, 有 f (φ, θ) = −g (θ, φ). 在一些情况下, 如 v (φ, θ) = φ · θ 时, 使用同步梯度下降方法的参数轨迹为
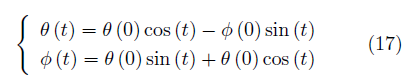
该式对应一个圆轨迹,具有无穷小学习速率的梯度下降将在恒定半径处环绕轨道运行,使用更大的学习率则轨迹有可能沿螺旋线发散。在这种情况下,同步梯度下降无法接近均衡点θ=Φ=0。
解决这一问题可以使用共识优化(Consensus optimization)[68]的方法。定义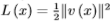 ,有修正的效用函数
,有修正的效用函数
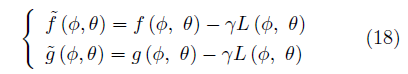
正则化因子L(Φ,θ)鼓励玩家间达成“共识”,这种方法较同步梯度下降方法具有更好的收敛性。
除了从优化方法的角度,研究者还通过改变优化的形式对GAN加以改进。最为常见的方法是使用强化学习中的策略梯度方法[69-70]以实现生成离散变量的目的。
GAN与强化学习领域的Actor-critic模型[70]的关系引起了许多研究者的注意[71]。强化学习(Reinforcement learning)[72]研究的问题是如何将状态映射为行动,以最大化执行者的长期回报。Actor-critic模型是强化学习中常用的建模方法,在这一模型中,存在行动者(Actor)与批评家(Critic)两个子模型,其中,行动者根据系统状态做出决策,评价者对行动者做出的行为给出估计。如图9所示。
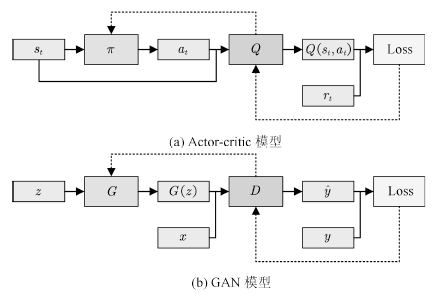
图9 GAN与Actor-critic模型
Fig.9 GAN and actor-critic models
可以看出,GAN模型与Actor-critic具有结构上的相似性,两者均包含了一个由随机变量到另一空间的映射,以及一个可学习的评价模型。两者均通过迭代寻求均衡点的方式求解。Goodfellow甚至认为GAN实质是一种使用RL技巧解决生成模型问题的方法,两者的区别主要在于GAN中回报是策略的已知函数且可对行动求导[73]。
Actor-critic的优化方法主要是基于REIN-FORCE算法[74]改进的策略梯度方法。该方法的主要思想是:行动者为一参数化的函数 π (s; θ), 每次行动的动作为 at = π (st|θ). 若一个动作可以获 得较大的长期回报 Q (st, at) 则提高该行动的出现几率, 否则降低该行动的出现几率. 长期回报一般由批评家给出. 每次行动后更新策略函数的参数:
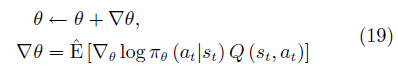
其中,∇θ被称为策略梯度。
在原始GAN中,生成器的学习依赖判别器回传的梯度。由于离散取值的操作不可微,原始GAN无法解决离散数据的生成问题。通过借鉴Actor-critic模型的思想,研究者提出了一系列基于策略梯度优化的GAN变体以解决这一问题。
SeqGAN[75]是这一系列工作中较早出现的模型之一。它的生成器结构及更新方式与用于图像生成的GAN类似。其模型结构如图10所示:
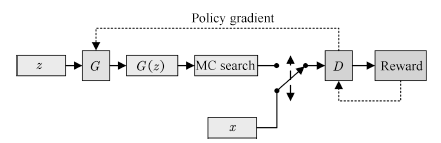
图10 SeqGAN的拓扑结构
Fig.10 Schematic of SeqGAN architecture
SeqGAN将序列生成问题视为序列决策问题进行处理,使用RNN作为生成网络。以已生成的语素(Tokens)Y1:t−1 作为当前状态, 生成器输出的下一个词汇 yt 为行为, 生成器网络为策略 π, 行为的回 报 rt 为判别器 D 对生成 Tokens 的置信概率。为了提高对整句输出的判别准确度,SeqGAN在每次生成一个Token后,使用蒙特卡洛搜索(Monte Carlo search, MC search)的方法对句子进行补齐,再将补齐后的句子输入判别器D. SeqGAN的值函数见式(20),每次更新的策略梯度见式(21):

通过这一方式,SeqGAN克服了原始GAN无法生成离散数据序列的问题。
后续工作通过改进网络结构,结合更丰富的数据类型等方法进一步强化了GAN的离散数据生成能力。如MaskGAN[76]使用Seq2Seq[7]作为生成网络,使得GAN具备了填词能力。SPIRAL[77]使用艺术生成的序列数据作为样本,可控制机械臂生成艺术图像。
3. GAN判别机制的发展
如何合理选择目标函数是深度学习中至关重要的一个问题。一个好的目标函数需要在刻画任务本质的同时,提供良好的数值优化特性。在GAN的训练过程中,目标函数设计的主要目标是有效地定义可区分性,并使得博弈过程可解[78-79]。
原始GAN使用分类误差作为真实分布与生成分布相近度的度量。当判别器为最优判别器时,生成器的损失函数等价于真实分布与生成分布之间的JS散度。然而,已被证明,当真实分布与生成分布的重叠区域可忽略时,JS散度为一常数,此时生成器的获得梯度为0,无法进一步学习[40]。
有研究者认为,这一问题的根源在于原始GAN假设了判别网络具有无限建模能力,可以对于任意的样本分布进行判别。然而对于一般的分布而言,真实分布与生成分布不重叠的概率无限趋于1[80]。为了克服这一问题,研究者提出对样本分布进行限制的方法,通过假设样本服从某类特殊的函数族以避免梯度消失的问题。
3.1 Lipschitz密度
一类较有代表性的限制是假设样本分布服从Lipschitz连续,即其概率密度分布f(x)服从

使不等式成立的最小K值被称为Lipschitz常数。
这类方法的典型代表是Wasserstein GAN(WGAN)[81]。WGAN使用Wasserstein-1距离(又称Earth-Mover(EM)距离)作为真实分布与生成分布相近度的度量。定义如下:
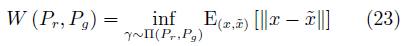
其中, 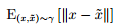 相当于在真实与生成样本 的联合分布 γ 的条件下, 将真实分布变换为生成分布所需要 “消耗” 的步骤. W (Pr , Pg ) 是这一 “消 耗” 的最小值.
相当于在真实与生成样本 的联合分布 γ 的条件下, 将真实分布变换为生成分布所需要 “消耗” 的步骤. W (Pr , Pg ) 是这一 “消 耗” 的最小值.
由于取下界的操作无法直接求解,根据Kantorovich-Rubinstein对偶性[82],EM距离被转化为如下的形式:
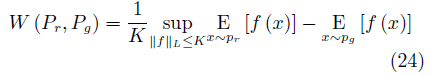
其 中, f (·) 是 一 个 满 足 Lipschitz 连 续 条 件 的 函数. 我们可以使用神经网络对 f (·) 进行拟合,因此WGAN的目标函数为:

其中评价函数C需要满足Lipschitz连续条件,一般采用权值裁剪或软约束的方式保证。在WGAN中,判别器(称为评价网络C)的目的是逼近Pr与Pg的EM距离,生成器的目的则是最小化两者的EM距离。WGAN的网络结构如图11所示。
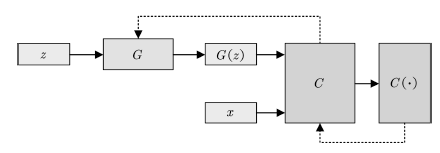
图11 WGAN的拓扑结构
Fig.11 Schematic of WGAN architecture
WGAN的可收敛性远强于原始GAN,一经提出就引起了极大的关注。后继的改进版本WGAN-GP通过添加梯度惩罚的方式[83],进一步提高了网络的稳定性,在多种网络结构上都可实现收敛,是目前性能最佳,使用最广泛的GAN变种之一。
3.2 能量函数
除了使用Lipschitz连续假设对样本分布进行约束,还可以使用非概率形式作为度量的GAN结构,较为典型的是基于能量的GAN(Energy-based GAN,EBGAN)[84]。EBGAN将判别器D视为一个能量函数,该函数得赋予真实样本较低的能量,而赋予生成样本较高的能量。其网络结构如图12所示。
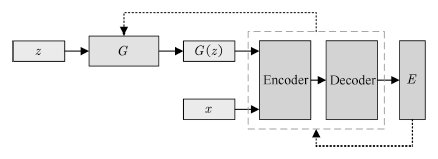
图12 EBGAN的拓扑结
Fig.12 Schematic of EBGAN architecture
在论文中,EBGAN使用了一个自动编码机作为判别网络,并将自动编码机的重构误差作为样本的能量,即:
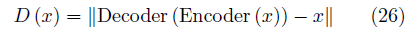
相应的损失函数为

其 中 [·]+= max (0,·), m是一个预定义的边界(Margin), 主要作用在于避免判别器过强导致生成器无法获得有用的信息, 该参数也可以通过自适应的方式学习[85]。
为了使得生成的样本具有更好的多样性,EBGAN还提出了一种约束方法,称为Pullingaway term(PT),其形式为
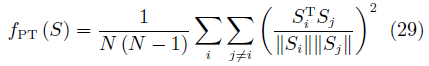
其中,S为判别器中编码层的输出。通过增大PT值,EBGAN可以有效地提升生成样本的多样性。EBGAN为理解GAN提供了一种全新的视角。
4. GAN的应用
GAN在生成逼真图像上的性能远超以往,一经提出便引起了极大的关注。随着研究的深入,研究者逐渐认识到其作为一种表征学习方式的潜力,并进一步地发展了其对抗的思想,将GAN的结构设计用于模仿学习与图像翻译等新兴领域。
一般而言,GAN的应用遵循这样的设计模式:首先定义一个模型用于将某一空间中的数据映射至另一空间,再定义一个模型用于评估这一映射的质量。通过迭代训练两模型得到理想的映射模型或评价模型。本文将GAN的应用依据其映射的性质分为三类:数据生成与增强,广义翻译模型,以及广义生成模型。
4.1 数据生成与增强
作为生成模型,GAN最为直接的作用是对训练数据进行增强。根据增强后的数据性质,这一类应用可以分为数据集内增强与数据集外增强两类。前者是对训练集内数据进行填补,清晰化,变换等操作,主要目的是增强数据集质量。后者则主要是结合外部知识或无标签数据对数据集进行调整和猜测,使其具备原数据集不具备的信息。
在有监督的深度学习训练中,研究者常常要对原始数据进行平移、缩放、旋转等操作。这些数据增强操作一方面扩大了数据集的样本量,另一方面也有助于神经网络学到轮廓,纹理等特征,以收敛到更好的(局部)最优解[2]。
数据集内提升是对这一工作的扩展。典型的应用包括缺失数据填补[86-87]、超分辨率图像生成[88]、视频预测[89-90]、图像清晰化[91]等。该类工作的主要模式是将有缺陷的数据或历史数据输入生成器,通过使用GAN的训练方式替代均方根误差(Mean square error,MSE)等人工设计的损失函数,从而实现更好的修复或预测效果。
以缺失数据填补为例。给定一个信息有缺失的数据,如部分像素丢失的图像,我们希望根据同类别的其他图像训练一个模型,该模型可将丢失的信息补全。如图13所示,相比传统方法(Image melding)[92],基于GAN的数据填补可以更好地考虑图像的语义信息,并填充符合当前场景的内容。
图13 GAN[86]与传统方法[92]的数据填补效果
Fig.13 Image completion by GAN[86] and traditional method[92]
许多计算机视觉任务都可以通过GAN增强图像以提高性能。除了图像分类,目标检测等常用任务,GAN也被用于对抗样本[93-94]的生成[95]与抵抗任务,如APE-GAN[96]通过将对抗样本转化为可被目标模型正确识别的样本,Generative adversarial trainer[97]使用GAN生成对抗性扰动(Adversarial perturbation)后将经过污染的样本与标记样本一起学习,等等。
GAN在数据集外扩展方面的工作,主要集中在使用仿真数据扩大真实数据相关的工作。在许多问题中,真实数据的收集十分困难或缓慢,但在仿真数据上训练的模型又无法很好地泛化以用于现实任务[98]。研究者提出了PixelDA[99]、SimGAN[100]、GraspGAN[101]等模型以解决该问题。该类模型的基本想法是通过使用GAN中的生成器作为精炼器(Refiner),对仿真数据进行修饰后,使其与真实数据相接近。该类方法使得以往需要大量样本的任务,如人眼识别、自动驾驶、机械臂控制等,现在通过少量真实样本与仿真环境即可完成训练[102-104]。
GAN还可以用于提升开放集分类(Opencategory classification,OCC,即将与训练集内数据类型不一致的样本区分为单独一类)问题的性能[105]。通过生成接近集内数据但被判别器认为是集外数据的样本,GAN可以较大地提升分类器在开放集分类问题上的性能。
数据生成与增强的工作往往与半监督学习相联系,其目的在于提高后续的监督学习或强化学习性能。一部分半监督学习方面工作还使用了GAN本身的结构特性。如后文IRGAN对判别式信息检索(Information retrieval,IR)模型的提升,使用CGAN模型中的判别器作为图像分类器[106],Professor forcing[107]方法中使用GAN提高RNN的训练质量,等等。由于这部分研究尚不丰富,限于篇幅本文不做详细介绍。
4.2 广义数据翻译
不同领域的数据往往具有各自不同的特征和作用。如自然语言数据具有易获取,具有较为明确的意义,但缺乏细节信息的特点。图像数据具有细节丰富,但难以分析语义的特点。同类数据间如何翻译,不同类型的数据间如何转化,不仅具有相当的实用价值,而且对于提高神经网络的可解释性具有重要的意义。GAN已被用于一些常见的数据翻译工作中,如从语义图生成图像[108]、图文翻译[109]等。本节主要介绍一些GAN所特有或表现显著优于传统方法的应用。
根据用户修改自动对照片进行编辑和生成是一个极具挑战的任务。研究人员提出了iGAN模型,通过类似InfoGAN等模型调整隐变量改变输出样本的方法,将用户输入作为隐变量,实现了图像的自动修改与生成[110-111]。效果如图14所示。受该工作启发,研究者提出了“图对图翻译”的新问题[112]。
图14 iGAN的生成样例[110]
Fig.14 Images generated by iGAN[110]
如图15所示,许多常见的图像处理任务都可以看作是将一张图片“翻译”为另一张图片,如将卫星图像转换为对应的路网图,将手绘稿转换为照片,将黑白图像转换为彩色图片等。Isola等提出了一种名为Pix2Pix[112]的方法,利用GAN实现了这种翻译,模型结构如图16所示。
图15 图对图翻译举例[112]
Fig.15 Examples of image to image translation[112]
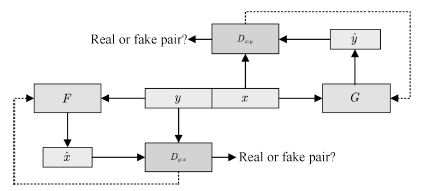
图16 Pix2Pix的拓扑结构
Fig.16 Chematic of Pix2Pix architecture
图 16 中 F 与 G 均为翻译器. Pix2Pix 需要成 对的数据集 (x, y), 例如在卫星图像转换的任务中, x 是卫星图像, y 是对应的路网图像. 在 x 向 y 转换 的过程中, 翻译器接受 x 的样本, 生成对应的样本 yˆ, 判别器 Dx:y 判别 x 与 yˆ 是否配对, 并将梯度回传给翻译器. y 向 x 的转换也照此进行。
Pix2Pix取得了非常惊艳的效果,后续的Pix2PixHD[113]等工作进一步提高了其生成样本的分辨率和清晰度。不过,该模型的训练必须有标注好的成对数据,这限制了它的应用场景。为了解决这一问题,结合对偶学习[114],研究者提出了CycleGAN[115],使得无须建立训练数据间一对一的映射,也可以在源域和目标域之间实现转换。CycleGAN的结构如图17所示。
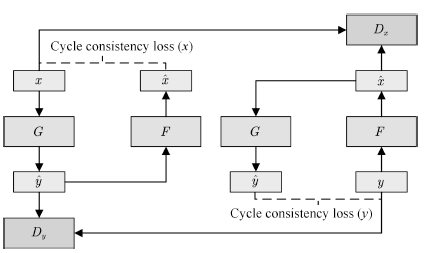
图17 CycleGAN的拓扑结构
Fig.17 Schematic of CycleGAN architecture
为了使用非配对数据进行训练,CycleGAN会首先将源域样本映射到目标域,然后再映射回源域得到二次生成图像,从而消除了在目标域中图像配对的要求。为了保证经过“翻译”的图像是我们所期望的内容,CycleGAN还引入了循环一致性的约束条件。
以x向y的转换为例,翻译器G接受x的样本,生成对应的样本 yˆ, 翻译器 F 再将 yˆ 翻译为 xˆ.判别器 Dy 接受样本 y 与 yˆ, 并试图判别其中的生成样本。 xˆ 应与 x 相似, 以保证中间映射有意义。 为此, 文中将循环一致性约束定义为
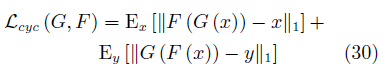
在训练GAN的同时保证循环一致性约束最小化,CycleGAN就可以通过非配对数据实现较好的映射效果。该方法生成的图像与Pix2Pix十分接近。除了用于数据增强任务外,该模型也被广泛用于神经风格转换(Neural style transfer)[116]等艺术性工作中。
4.3 广义生成模型
以上讨论的工作主要关于图像,自然语言等具体数据。实际上,我们可以考虑更为广义的数据,如状态、行动、图网络等。
该类研究的典型工作之一为生成式模仿学习(Generative adversarial imitation learning, GAIL)[117]。模仿学习(Imitation learning)是强化学习中的一个重要课题,其目的是解决如何从示教数据中学习专家策略的问题。由于状态对行动的映射具有不确定性,直接使用示教数据进行监督训练得到的策略模型往往不能很好地泛化。研究者一般使用反向强化学习(Inverse reinforcement learning, IRL)[118]来解决这一问题。通过学习一个代理回报函数(Surrogate reward function)R˜ (s),并期望该函数能最好地解释观察到的行为,再由此从数据中习得类似的策略。IRL成功解决了一系列的问题,如预测出租车司机行为[119],规划四足机器人的足迹[120]等。
然而,IRL算法的运算代价高昂,且方法过于间接。对于模仿学习而言,真正的目的是使得Agent可以习得专家的策略,内在的代价函数并非必要。研究者从GAN的思想中得到启发,提出了生成式模仿学习(Generative adversarial imitation learning, GAIL)[117]的方法。GAIL的一般结构如图18所示。
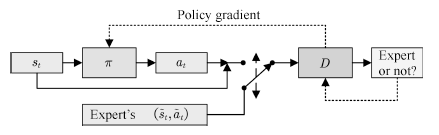
图18 生成式模仿学习
Fig.18 Generative adversarial imitation learnin
与GAN 类似, GAIL的目的是训练一个策略网络 πθ , 其输出的状态– 行为对Xθ ={(s1, a1) , · · · , (sT , aT )} 可以欺骗判别器 Dφ, 使其无法区分 Xθ 与由专家策略 πE 输出的 XE . GAIL的目标函数为
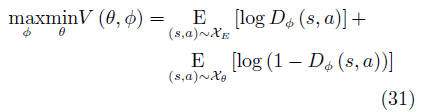
策略的代理回报函数为
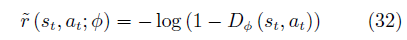
使用策略梯度方法更新行动者π(生成器),最终使得行动者的决策与专家的决策一致。该方法被用于模仿驾驶员[121],机械臂控制[122]等任务中,取得了较好的效果。
与GAIL相类似,IRGAN[123]使用对抗方式提高信息检索(Information retrieval,IR)模型质量。一般而言,IR模型可分为两类。一类为生成式模型,其目标是学习一个查询(Query)到文档(Document)的关联度分布,利用该分布对每个查询返回相关的检索结果。另一类为判别式模型,该模型可以区分有关联的查询对 (queryr , docr ) 与无关联的查询对 (queryf , docf ). 对于给定的查询对对于给定的查询对,该模型可返回该查询对内元素的关联程度[124]。由于这两类模型的对抗性质,IRGAN将两个或多个生成式IR模型与判别式IR模型整合为一个GAN模型,再通过策略梯度优化的方式提升两类模型的检索质量。
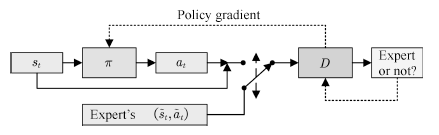
图18 生成式模仿学习
Fig. 18 Generative adversarial imitation learnin
此外,GAN还被用于专业领域数据的生成任务。如用于生成恶意软件的MalGAN[125]模型,用于生成DNA序列的FBGAN[126],用于学习图嵌入表示(Graph embedding)[127]的GraphGAN等。限于篇幅,本文不再详细介绍。
5. 总结与展望
自2014年提出以来,生成式对抗网络获得了极大的关注与发展。GAN的相关工作越来越多地出现在机器学习的各类会议和期刊上,LeCun甚至将其称为“过去十年间机器学习领域中最让人激动的点子”。
本文综述了GAN在理论与应用方面的成果,总体来看可分为两个大的方向。
第一个研究方向集中在生成机制方面,主要的问题是如何设计一个有效的结构,以学习一个从隐变量到目标空间的映射。在理论上主要包括了如何设计更好的网络结构和相应的优化方法以提高生成数据质量,如何集成多模型以提高生成效率。在应用上主要是考虑半监督学习问题以及复杂数据间的映射问题。
第二个研究方向集中在判别机制方面,主要的问题是如何更好地将生成问题转化为一个较易学习的判别问题。在理论上主要包括了如何设计博弈形式以提高学习效率,在应用上主要是如何利用GAN中的判别模型辅助下游任务,以及如何设计整体结构,将其他问题转化为一个可判别的生成问题。
GAN在数据生成,半监督学习,强化学习等多方面任务中起到了重要作用。但也应看到,该领域的发展仍处于早期阶段,许多问题仍在制约GAN的发展。最为突出的是GAN的评价与复现问题,目前尚未有关于如何科学评价GAN的共识。其次,GAN的博弈与收敛机制背后的数学分析仍有待建立,现有的研究主要是利用深度学习在有监督任务中积累的经验进行扩展。最后,大部分GAN的工作仍然缺乏实用价值,仅可在特定的数据集上使用。如何建立类似ImageNet等标准化任务以评价GAN方法;如何建立和分析GAN的数学机制,并在此基础上进一步实现GAN特有的,与有监督学习任务不同的深度学习构件;如何拓展GAN的应用范围;这些问题仍有待研究者进一步探索。
从更高的角度看,GAN的成功实质反映了人工智能的研究进入深水区,研究的重点从视觉、听觉等感知问题向解决决策、生成等认知问题转移。与机器感知问题相比,这些新的问题往往人类也无法很好解决,对这类问题的解决必须依赖新的研究方法。
这两类问题的区别可以使用强化学习中的“探索与利用两难(Explore and exploit dilemma)”问题进行类比,如图19所示。对于感知问题,我们有一个足够明确的目标以及目标临近域的数据,所需要的是足够高效的利用方法。然而,对于认知问题,我们只能通过比较局部目标的方法来定义问题,且数据往往过于稀疏或处于局部最优点附近。如在围棋AI的研究中发现,使用人类数据训练的智能体会收敛到局部最优值,反而无法胜过不学习人类经验的智能体[128]。此时,需要寻找一种方法充分探索可能性空间,以更好地确定实际需要学习的目标。
图19 探索与利用
Fig.19 Explore and exploit
实现这种探索的一个方式是将真实世界的互动机制引入模型。GAN可以看作是这样的一个系统,通过在生成模型上添加判别模型,GAN模仿了现实世界中人类判断图片的机制,进而将难以定义的样本差异转化为一个博弈问题。与之类似的是AlphaZero,通过自我对弈的形式积累大量数据,再从中探索出一个更优的策略。在这一新的研究范式中,模型从分析的工具变为了数据的“工厂”[129]。
这类方法的思路与国内学者提出的平行思想有很多相似之处。平行思想是指,通过将真实系统与人工系统融合,在两个平行的系统中迭代实现对另一系统的描述、预测与引导[129]。有研究者结合平行思想与机器学习提出了平行学习的概念[130]。通过在平行系统中综合描述学习、预测学习与引导学习,可以更好地提高机器学习方法的样本效率,扩大学习的探索空间,实现一条从小数据产生大数据,再由大数据炼成“小定律”的精准知识之路,从而更好地分析和解决决策、生成等难以明确定义优化目标的问题。目前,平行学习己在自动驾驶中得到了成功的应用[131-132]。
GAN可被视为一个最简单且无引导学习功能的平行学习系统,它用判别器逼近真实系统,利用生成器逼近人工系统,为虚实一体的智能“平行机”构造提供了一个例子[133]。GAN为平行学习中的博弈提供了一个初步示例,更为人工智能的下一步发展提供了一种全新的思路。
-
图像生成对抗生成网络gan_GAN生成汽车图像 精选资料推荐2021-08-31 0
-
图像生成对抗生成网络2021-09-15 0
-
生成式对抗网络基础知识直观解读2018-05-14 4414
-
生成对抗网络在计算机视觉领域有什么应用2018-12-06 1418
-
如何使用生成对抗网络进行信息隐藏方案资料说明2018-12-12 1064
-
新型生成对抗式分层网络表示学习算法2021-03-11 734
-
一种利用生成式对抗网络的超分辨率重建算法2021-03-22 781
-
基于生成式对抗网络的深度文本生成模型2021-04-12 601
-
基于条件生成式对抗网络的面部表情迁移模型2021-05-13 759
-
基于生成式对抗网络的图像补全方法2021-05-19 776
-
生成式对抗网络应用及研究综述2021-06-09 698
-
基于像素级生成对抗网络的图像彩色化模型2021-06-27 574
-
「自行科技」一文了解生成式对抗网络GAN2022-09-16 4113
-
PyTorch教程20.2之深度卷积生成对抗网络2023-06-05 404
-
生成对抗网络(GANs)的原理与应用案例2024-07-09 1020
全部0条评论

快来发表一下你的评论吧 !
