

关于Linux操作系统中LKM的优势与不足研究与应用浅析
嵌入式技术
描述
1. 引言
Linux系统开放源代码、系统漏洞少,在面对病毒和黑客入侵时能提供更好的安全性和稳定性,基于以上这些优点,近年来对Linux操作系统及其相关技术的应用和研究越来越多。对Linux操作系统扩充或裁剪功能需要在重新编译内核上花费大量的时间。LKM机制由于大大缩短了开发和测试的时间,在 Linux开发、研究的过程中起到了举足轻重的作用。
LKM主要包括内核模块在操作系统中的加载和卸载两部分功能,内核模块是一些在启动的操作系统内核需要时可以载入内核执行的代码块,不需要时由操作系统卸载。它们扩展了操作系统内核功能却不需要重新编译内核、启动系统。如果没有内核模块,就不得不反复编译生成操作系统的内核镜像来加入新功能,当附加的功能很多时,还会使内核变得臃肿。
2. LKM的编写和编译
2.1 内核模块的基本结构
一个内核模块至少包含两个函数,模块被加载时执行的初始化函数init_module()和模块
被卸载时执行的结束函数cleanup_module()。在最新内核稳定版本2.6中,两个函数可以起
任意的名字,通过宏module_init()和module_exit()实现。唯一需要注意的地方是函数必须在宏的使用前定义。例如:
static int __init hello_init(void){}
static void __exit hello_exit(void ){}
module_init(hello_init);
module_exit(hello_exit);
这里声明函数为static的目的是使函数在文件以外不可见,__init的作用是在完成初始化后收回该函数占用的内存,宏__exit用于模块被编译进内核时忽略结束函数。这两个宏只针对模块被编译进内核的情况,而对动态加载模块是无效的。这是因为编译进内核的模块是没有清理收尾工作的,而动态加载模块却需要自己完成这些工作。
2.2 内核模块的编译
编译时需要提供一个makefile来隐藏底层大量的复杂操作,使用户通过make命令就可以完成编译的任务。下面就是一个简单的编译hello.c的makefile文件:
obj-m += hello.ko
KDIR := /lib/modules/$(shell uname -r)/build
PWD := $(shell pwd)
default:
$(MAKE) -C $(KDIR) SUBDIRS=$(PWD) modules
编译后获得可加载的模块文件hello.ko。
内核版本2.6中使用.ko文件后缀代替了.o,这是为了与普通可执行文件相区别。
3. LKM的主要功能
3.1 模块的加载
模块的加载有两种方法,第一种是使用insmod命令加载,另一种是当内核发现需要加载某个模块时,请求内核后台进程kmod加载适当的模块。当内核需要加载模块时,kmod被唤醒并执行modprobe,同时传递需加载模块的名字作为参数。modprobe像insmod一样将模块加载进内核,不同的是在模块被加载时查看它是否涉及到当前没有定义在内核中的任何符号。如果有,在当前模块路径的其他模块中查找。如果找到,它们也会被加载到内核中。但在这种情况下使用insmod,会以“未解析符号”信息结束。
关于模块加载,可以用图3.1来简要描述:
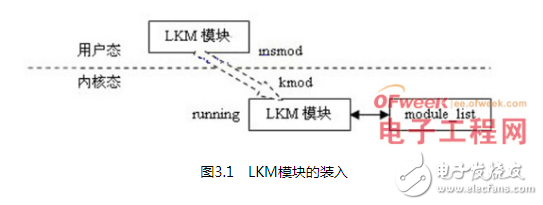
insmod程序必须找到要求加载的内核模块,这些内核模块是已链接的目标文件,与其他文件不同的是,它们被链接成可重定位映象即映象没有被链接到特定地址上。insmod将执行一个特权级系统调用来查找内核的输出符号,这些符号都以符号名和数值形式如地址值成对保存。内核输出符号表被保存在内核维护的模块链表的第一个module结构中。只有特殊符号才被添加,它们在内核编译与链接时确定。insmod将模块读入虚拟内存并通过使用内核输出符号来修改其未解析的内核函数和资源的引用地址。这些工作采取由insmod程序直接将符号的地址写入模块中相应地址来进行。
当insmod修改完模块对内核输出符号的引用后,它将再次使用特权级系统调用申请足够的空间容纳新模块。内核将为其分配一个新的module结构以及足够的内核内存来保存新模块,并将其插入到内核模块链表的尾部,最后将新模块标志为UNINITIALIZED。insmod将模块拷贝到已分配空间中,如果为它分配的内核内存已用完,将再次申请,但模块被多次加载必然处于不同的地址。另外此重定位工作包括使用适当地址来修改模块映象。如果新模块也希望将其符号输出到系统中,insmod将为其构造输出符号映象表。每个内核模块必须包含模块初始化和结束函数,所以为了避免冲突它们的符号被设计成不输出,但是insmod必须知道这些地址,这样可以将它们传递给内核。在所有这些工作完成以后,insmod将调用初始化代码并执行一个特权级系统调用将模块的初始化和结束函数地址传递给内核。当将一个新模块加载到内核中时,内核必须更新其符号表并修改那些被新模块使用的老模块。那些依赖于其他模块的模块必须在其符号表尾部维护一个引用链表并在其module数据结构中指向它。内核调用模块的初始化函数,如果成功将安装此模块。模块的结束函数地址被存储在其module结构中,将在模块卸载时由内核调用,模块的状态最后被设置成RUNNING。
3.2 模块的卸载
模块可以使用rmmod命令删除,但是请求加载模块在其使用计数为0时,自动被系统删除。kmod在其每次idle定时器到期时都执行一个系统调用,将系统中所有不再使用的请求加载模块删除。
关于模块卸载,可以用图3.2来描述:
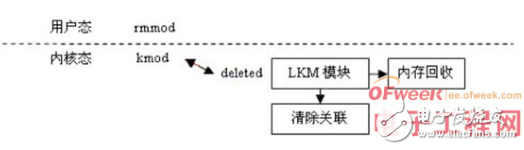
内核中其他部分还在使用的模块不能被卸载。例如系统中安装了多个VFAT文件系统则不能卸载VFAT模块。执行lsmod将看到每个模块的引用计数。模块的引用计数被保存在其映象的第一个常字中,这个字还包含autoclean和visited标志。如果模块被标记成autoclean,则内核知道此模块可以自动卸载。visited标志表示此模块正被一个或多个文件系统部分使用,只要有其他部分使用此模块则这个标志被置位。每次系统要将没有被使用的请求加载模块删除时,内核将在所有模块中扫描,但是一般只查看那些被标志为autoclean并处于running状态的模块。如果某模块的 visited标记被清除则它将被删除。其他依赖于它的模块将修改各自的引用域,表示它们间的依赖关系不复存在。此模块占有的内核内存将被回收。
4. LKM的应用
零拷贝基本思想是:数据分组从网络设备到用户程序空间传递的过程中,减少数据拷贝次数,减少系统调用,实现CPU的零参与,彻底消除CPU在这方面的负载。零拷贝的实现分为实现DMA数据传输和地址映射两个部分。其中DMA数据传输与本文关系不大,就不详细叙述了,这里主要介绍应用LKM机制实现的地址映射。
地址映射的基本原理是在内核空间申请内存,通过proc文件系统和mmap函数将其映射到用户空间来允许应用程序访问,这样就消除了内核空间到应用程序空间的数据拷贝。地址映射部分的实现主要分为以下三步:
第一,建立LKM的基本结构,包括编写初始化和结束函数等。
第二,声明完成映射功能所需要的函数,主要有分配和初始化内核内存函数init_mem(),释放内核内存函数del_mem(),向内核内存输入内容的函数put_mem()等。
第三,在初始化函数中应用第二步建立的函数分配一块内存空间、输入内容、建立proc文件系统入口。在结束函数中释放已分配的内核内存,删除proc文件系统入口。
编写应用程序测试该LKM,发现已经达到了映射内核内存到应用程序空间的目的。在实现零拷贝的过程中采用LKM机制不但便于调试而且大大减少了开发时间。
5. LKM与普通应用程序的比较
LKM与普通应用程序之间的区别主要体现在四个方面。
第一,也是最重要的区别,普通应用程序运行在用户空间,而LKM运行在内核空间。通过区分不同的运行空间,操作系统能够安全地保护操作系统中一些重要数据结构的内容不被普通应用程序所修改,达到保证操作系统正常运转的目的。
第二,普通应用程序的目标很明确,它们从头至尾都是为了完成某一项特定任务。而LKM是在内核中注册并为后续应用程序的请求提供服务的。
第三,普通应用程序可以调用并没有在其中定义的函数,但一个LKM是链接到内核上的,它所能调用的函数只有内核导出来的那些函数。
第四,普通应用程序和LKM处理错误的方式不同。当应用程序中出现错误时并不会给系统造成很大的伤害。LKM则不然,在其中出现的错误对子系统来说通常是致命的,至少对于当前正在运行的进程而言。LKM中的一个错误常常会导致整个系统崩溃。
6. 编写LKM需要注意的问题
LKM运行在内核空间,它们拥有对整个系统所有资源的访问权限,因此,编写LKM首先要注意就是安全问题,而且还应该避免将可能导致出现安全问题的代码带到LKM中。
LKM加载后是作为操作系统内核的一部分运行的,因此,在设计、编写操作系统内核过程中应该注意的问题在LKM中也应该引起足够的重视。在这里,主要指的是并发问题和指针引用问题。并发是指在同一时间有多个进程在操作系统内核中同时运行。并发结合共享资源最终会导致竞态条件,在这种情况下应该对各个并发进程访问共享资源进行严格的控制。如果在LKM中出现指针引用错误,内核将没有办法将内存的虚拟地址映射到物理地址,从而导致出现内核中的意外,如内存访问冲突、除0以及非法操作等。
7. LKM的不足之处
LKM虽然在设备驱动程序的编写和扩充内核功能中扮演着非常重要的角色,但它仍有许多不足的地方。
第一,LKM对于内核版本的依赖性过强,每一个LKM都是靠内核提供的函数和数据结构组织起来的。当这些内核函数和数据结构因为内核版本变化而发生变动时,原先的LKM不经过修改就可能不能正常运行。
第二,虽然现在有针对内核编程调试的工具kgdb,但是在LKM编写过程中调试仍非常麻烦,而且在调试过程中,系统所能提供的出错信息极为晦涩。
创新点:针对Linux内核,利用LKM,在实现了数据的零拷贝(Zero-copy)的过程中,将LKM与普通应用程序进行比较,提出了LKM的优势和不足。
-
机器人操作系统浅析2016-09-28 0
-
嵌入式Linux系统中内核抽象的动态扩展技术2018-10-26 0
-
关于Trampoline操作系统有哪些研究?2021-04-27 0
-
Linux系统与其它操作系统相比有什么优势?2021-10-28 0
-
Linux作为嵌入式操作系统具有哪些优势2021-11-04 0
-
浅析Linux操作系统的显著优势2021-11-04 0
-
分享一款Linux操作系统2021-11-04 0
-
Linux操作系统2009-04-10 682
-
Linux操作系统原理及应用2009-04-28 556
-
嵌入式Linux操作系统实时性研究2009-06-15 411
-
什么是Linux操作系统2009-12-26 1406
-
II、eCos、FreeRTOS和djyos操作系统的特点及不足2018-09-21 2575
-
Linux嵌入式操作系统有哪些优势2020-07-10 5121
全部0条评论

快来发表一下你的评论吧 !
