

基于目标图像的视觉强化学习算法,让机器人可以同时学习多个任务
电子说
描述
目前的深度强化学习需要人为地为每一个任务设计奖励函数,当涉及复杂系统时需要很多的人力成本和复杂的工作。如果需要完成更大范围内的更多工作,就需要对每一个新任务进行重复的训练。为了提高学习的效率,伯克利的研究者们提出了一种可以同时对多个不同任务进行学习的算法,无需人工干预。
这一算法可以自动从图像中抽取目标并学习如何达到目标,并实现推物体、抓握和开门等一系列特殊的任务。机器人可以学会自己表示目标、学习如何达到目标,而一切的输入仅仅是来自相机的RGB图像。
· 目标条件下的强化学习
如何描述真实世界的状态和期望的目标是我们需要考虑的首要问题,但对于机器人来说枚举出所有需要注意的物体是不现实的,现实世界中的物体及其数量变化多端、如果要检测他们就需要额外的视觉检测工作。
那么该如何解决这一问题呢?研究人员提出了一种直接利用传感器信息来操作的方法,利用机器人相机的输出来表达世界的状态,同时利用期望状态的图像作为目标输入到机器人中。对于新的任务,只需要为模型提供新的目标图像即可。这种方法同时能拓展到多种复杂的任务,例如可以通过语言和描述来表达状态/目标。(或者可以利用先前提出的方法来优化目标:传送门>>UC Berkeley提出新的时域差分模型策略:从无模型到基于模型的深度强化学习)
强化学习是一种训练主体最大化奖励的学习机制,对于目标条件下的强化学习来说可以将奖励函数设为当前状态与目标状态之间距离的反比函数,那么最大化奖励就对应着最小化与目标函数的距离。
我们可以通过一个基于目标条件下的Q函数来训练策略实现最大化奖励。基于目标条件的Q函数Q(s,a,g)描述的是在当前状态和目标下,当前的行为将产生对主体怎样的结果(奖励)?也就是说在给定状态s、目标g的前提下,我们可以通过优化行为a来实现奖励最大化:
π(s,g) = maxaQ(s,a,g)
基于Q函数来选择最优的行为,可以得到最大化奖励和的策略(在这个例子中便是达到各种不同的目标)。
Q学习得以广泛应用的原因在于它可以不基于策略而仅仅只依赖与s,a,g。那么意味着训练任意策略所收集的数据都可以用来在多个任务上进行训练。基于目标条件的Q学习算法如简图所示:
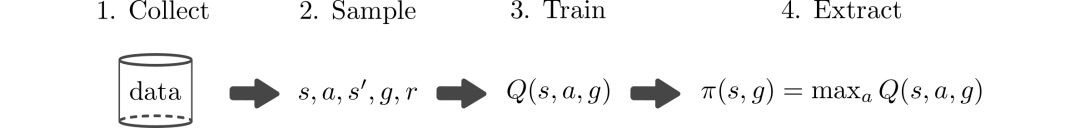
但上述方法的主要局限在于数据收集。如果能人工生成数据,理论上就可以学习解决不同的任务而无需与真实世界进行交互。但遗憾的是在真实世界中学习精确的模型十分困难,所以通常依赖于采样来获取状态s--行为a--下一个状态s'的训练数据。
但我们换个角度来看,如果可以表达出奖励函数r(s,g), 有一种可以生成目标并计算奖励的机制,我们就可以可回溯的重新标记目标,重新计算奖励。这样的话就可以利用(s,a,s') 数据生成大量的人工数据,这一个过程如下图所示:

最美妙的事情在于可以同时生成多个目标和奖励函数,这就意味着可以学习达到多个目标而无需采集额外的数据,这一简单的改进极大的加速了学习过程。
上面的方法主要基于两个假设:1).知道奖励函数的表达并可以进行操作;2).可以得到目标的采样分布p(g).基于前人的工作,可以方便的设计出目标分布p(g)和奖励函数。
但对于基于视觉的任务来说会出现两个问题:1).由于基于像素的距离可能没有实际意义,模型不知道该使用哪一个奖励函数;2).由于任务的目标是图像的形式,需要知道目标图像的分布p(g),但人工设计目标图像的分布是一个很复杂的任务。那么研究人员们期望最好的情况就是,主体可以自动地想象出它的目标,并学习出如何达到这一目标。
·基于假想目标的强化学习
为了解决这一问题,研究人员通过学习出图像的表示并利用这些表示来实现条件Q学习,而不是直接利用图像本身来进行强化学习。那么这时候关键的问题就被转换为:这一从图像中学习的表达应该满足什么样的特点?为了计算出语义的奖励,需要一种可以捕捉图像中变量潜在因素的表达,同时这种表达需要很便捷地生成新的目标。
试验中研究人员通过变分自编码器(VAE)来从图像中获取满足这些条件地表示。这种生成模型可以将高维空间中图像转换到低维度地隐空间中去(或者进行相反地变换)。得到的模型可以将图像转换到隐空间中并抽取其中的变量特征,这与人类在真实世界中描述目标的抽象过程很类似。在给定当前图像x和目标图像xg后,模型可将他们转换为隐空间中对应的隐变量z和zg,此时就可以利用隐变量来为强化学习算法描述系统状态和期望目标了。在低维的隐空间中学习Q函数和策略比直接使用图像进行训练要快很多。
将当前图像和目标图像编码到隐空间中,并利用其中的距离来计算奖励。
这同时解决了如何计算强化学习中计算奖励的问题。相较于利用像素误差,可以使用隐空间中与目标的距离来训练主体。在最大化抵达目标概率的同时这一方法可以给出更有效的学习信号。
这一模型的重要性在于主体可以容易的在隐空间中生成目标。(这一生成模型使得隐空间中的采样是可以回溯的:仅仅从VAE的先验中采样)其原因在于:为主体提供了可以设置自身目标的机制,主体从生成模型的隐变量中采样并尝试抵达隐空间中的目标;同时为重采样机制也可用于前述的重标记过程。由于训练的生成模型可以将真实图像编码为先验,从先验的隐变量采样也对应着有意义的隐目标。
主体可以通过模型生成自己的目标,用于探索和目标重标记。
综上所述,对于输入图像的隐空间表示1).捕捉了场景中的隐含因素;2).为优化提供了有效的距离度量;3).提供了有效的目标采样机制,使得这一方法可以直接利用像素输入来实现基于假想的强化学习算法( Reinforcement Learning with imagined Goals ,RIG)
· 实验
下面研究人员将通过实验来证明这一方法是能简单高效地在合理的时间内在真实世界中训练出机器人策略。实验分为两个任务,分别是基于目标图像直到机械臂运动到人为指定地位置和将目标推到期望的位置。实验中仅仅通过84*84的RGB图像来训练,而没有关节角度和位置信息。
机器人首先学习到如何在隐含空间内学习出自己的目标,这一阶段可以利用解码器来可视化机器人为自己假想出来的目标。下图上半部分显示了机器人“想象”出的目标位置,而下面图则是实际运行状况。
通过设置自身的目标,机器人就可以在没有人类的干预下自动的训练尝试以抵达目标。需要执行特定的任务时,才需要人为的给定目标图像。由于机器人以及多次练习过如何抵达目标,在下面的图中我们可以看到它已经不需要额外的训练便可以抵达新的目标。
下图是第二个任务,利用RIG来训练机械臂将物体推到指定位置。其中左边是实验装置、右上是目标图像、右下是机器人推动的过程。
通过图像训练策略使得机器人推物体的任务变得容易多了。只需要在上一个任务的基础上加上一张桌子、一个物体、稍微调整相机就可以开始训练了。虽然模型的输入是图像,但这一算法只需要一个小时的时间就可以训练完成抵达特定位置的任务、4.5小时就可以实现将物体推到特定位置的任务(需要与环境交互),同时达到了比较好的精度。
很多实际使用的强化学习算法需要目标位置的基准状态,然而这却需要引入额外的传感器或训练目标检测算法来实现 。与之相比,这里提出的算法仅仅依赖于RGB相机,并可以直接输入图像完成训练过程。
· 未来研究方向
通过前文描述的方法,可以利用直接输入的图片训练出真实世界的机器人策略,简单高效地实现不同的任务。基于这一结果,可以开启很多令人激动地研究领域。这一研究不仅限于利用图像作为强化学习的目标,同时还可以广泛应用于语言和描述等不同的目标表达中。同时,可以探索如何利用更本质的方式来选择目标以实现更好的自动学习。如果使用内在动机的概念与上文提出的策略结合,可以引导策略进行更快的学习。
另一个可能方向是训练模型能够处理动力学的情况。对环境动力学进行编码可以使得隐含空间更加适合强化学习,加速学习的过程。最后,有很多机器人任务的状态很难被传感器所捕捉,但利用基于假想目标的学习就可以处理诸如形变物体的抓取、目标数量变化这样复杂的问题。
-
机器人视觉系统组成及定位算法分析2019-06-08 0
-
基于深度学习技术的智能机器人2018-05-31 0
-
机器人视觉与机器视觉有什么不一样?2020-08-28 0
-
深度强化学习实战2021-01-10 0
-
四足机器人的机构设计2021-09-15 0
-
基于LCS和LS-SVM的多机器人强化学习2018-01-09 832
-
【重磅】DeepMind发布通用强化学习新范式,自主机器人可学会任何任务2018-03-19 1901
-
基于强化学习的MADDPG算法原理及实现2018-11-02 21699
-
一文详谈机器学习的强化学习2020-11-06 1749
-
一种基于多智能体协同强化学习的多目标追踪方法2021-03-17 1405
-
机器学习中的无模型强化学习算法及研究综述2021-04-08 900
-
当机器人遇见强化学习,会碰出怎样的火花?2021-04-13 2443
-
基于深度学习的机器人目标识别和跟踪2022-08-02 1660
-
什么是深度强化学习?深度强化学习算法应用分析2023-07-01 1450
-
基于强化学习的目标检测算法案例2023-07-19 476
全部0条评论

快来发表一下你的评论吧 !
