

浅析循环神经网络的概念、变体及应用
电子说
描述
数据科学家James Le以语言建模为背景,介绍了RNN的概念、变体、应用。
介绍
我大三有一学期去丹麦的哥本哈根交流。我之前没去过欧洲,去丹麦交流,让我有机会浸入新文化,遇到新人群,去新地方旅行,以及最重要的,接触新语言。我为此极度兴奋。尽管英语不是我的母语(我的母语是越南语),但我很小的时候就开始学说英语了,它已经成为我的第二本能。而丹麦语则极为复杂,句法结构大不相同,语法也很不一样。我在出发前通过多邻国应用学了一点丹麦语;不过,我只掌握了一些简单的短语,像是你好(Hej)和早上好(God Morgen)。
到了丹麦之后,我需要去便利店买吃的。但是那里的标签都是丹麦文,我没法分辨。我花了大概半小时都没能分清哪个是全麦面包,哪个是白面包。这时我突然想起不久前我在手机上安装了谷歌翻译应用。我拿出手机,打开应用,将相机对准标签……哇,丹麦单词立刻翻译成了英文。我发现谷歌翻译可以翻译任何相机摄入的单词,不管是路牌,还是饭馆菜单,甚至手写数字。不用说了,在我交流学习期间,这个应用为我节省了大量时间。
谷歌翻译是谷歌的自然语言处理研究组开发的产品。这个小组专注于大规模应用的跨语言、跨领域算法。他们的工作包括传统的NLP任务,以及专门系统的通用语法和语义算法。
从更高的层面来看,NLP位于计算机科学、人工智能、语言学的交汇之处。NLP的目标是处理或“理解”自然语言,以便执行有用的任务,例如情绪分析、语言翻译、问题解答。完全理解和表示语言的含义是一项非常艰巨的目标;因此人们估计,完美理解自然语言需要AI完备系统。NLP的第一步是语言建模。
语言建模
语言建模的任务是预测下一个出现的单词是什么。例如,给定句子“I am writing a ……”(我正在写),下一个单词可能是“letter”(信)、“sentence”(句子)、“blog post”(博客文章)……更形式化地说,给定单词序列x1, x2, …, xt,语言模型计算下一个单词xt+1的概率分布。
最基础的语言模型是n元语法模型。n元语法是n个连续单词。例如,给定句子“I am writing a ……”,那么相应的n元语法是:
单元语法:“I”, “am”, “writing”, “a”
二元语法:“I am”, “am writing”, “writing a”
三元语法:“I am writing”, “am writing a”
四元语法:“I am writing a”
n元语法语言建模的基本思路是收集关于不同的n元语法使用频率的统计数据,并据此预测下一单词。然而,n元语法语言建模存在稀疏问题,我们无法在语料库中观测到足够的数据以精确建模语言(特别是当n增加时)。
神经概率语言模型的网络架构概览(来源:Synced)
不同于n元语法方法,我们可以尝试基于窗口的神经语言模型,例如前馈神经概率语言模型和循环神经网络语言模型。这一方法将单词表示为向量(词嵌入),将词嵌入作为神经语言模型的输入,从而解决了数据稀疏问题。参数在训练过程中学习。词嵌入通过神经语言模型得到,语义相近的单词在嵌入向量空间中更靠近。此外,循环神经语言模型也能捕捉句子层面、语料库层面、单词内部的上下文信息。
循环神经网络语言模型
RNN背后的想法是利用序列化信息。RNN一名中有循环(recurrent)这个单词,这是因为RNN在序列中的每个元素上执行相同的任务,其输出取决于之前的计算。理论上,RNN可以利用任意长度序列中的信息,但经验告诉我们,RNN只限于回顾若干步。这一能力使得RNN可以解决识别连写笔迹或语音之类的任务。
让我们尝试类比一下。假设你看了最近的《复仇者联盟3:无限战争》(顺便提一下,这是一部现象级电影)。其中有许多超级英雄,有多条故事线,缺乏漫威电影宇宙的先验知识的观众可能感到迷惑。然而,如果你按顺序看过之前的漫威系列(钢铁侠、雷神、美国队长、银河护卫队),那你就有了上下文可以正确地将所有情节联系起来。这意味着你记住你看过的东西以理解《无限战争》中的混沌。
无限战争(图片来源:digitalspy.com)
类似地,RNN记得一切。其他神经网络中,所有输入都是彼此独立的。但在RNN中,所有的输入都彼此相关。比方说你需要预测给定句子的下一个单词,所以之前单词之间的关系有助于预测更好的输出。换句话说,RNN在训练自身时记住一切关系。
RNN通过简单的循环记住从之前的输入中学到的东西。该循环接受上一时刻的信息,并将它附加到当前时刻的输入上。下图显示了基本的RNN结构。在某一具体时步t,Xt是网络的输入,ht是网络的输出。A是一个RNN单元,其中包含类似前馈网络的神经网络。
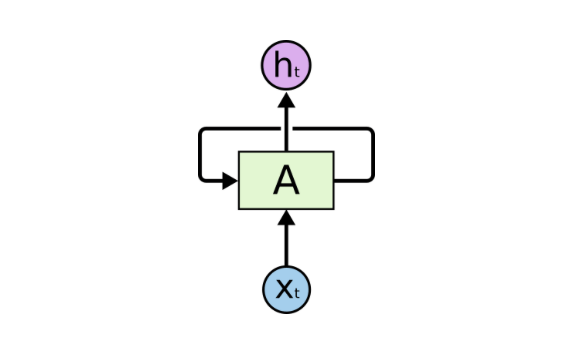
图片来源:colah.github.io
这一循环结构让神经网络可以接受输入序列。下面的展开图有助于你更好地理解RNN:
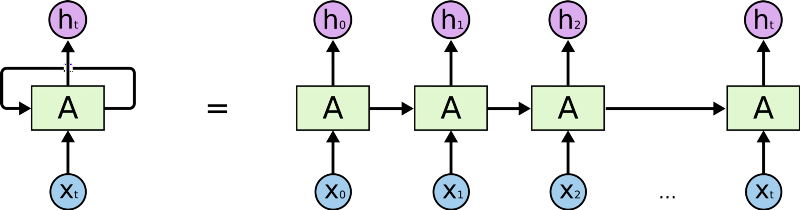
图片来源:colah.github.io
首先,RNN接受输入序列中的X0,接着输出h0,h0和X1一起作为下一步的输入。接着,下一步得到的h1和X2一起作为再下一步的输入,以此类推。这样,RNN在训练时得以保留上下文的记忆。
如果你偏爱数学,许多RNN使用下面的等式定义隐藏单元的值:
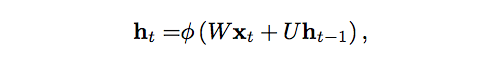
图片来源:lingvo-masino
其中,ht是t时刻的隐藏状态,∅是激活函数(Tanh或Sigmoid),W是输入到t时刻的隐藏层的权重矩阵,U是t-1时刻的隐藏层到t时刻的隐藏层的权重矩阵,ht-1是t时刻的隐藏状态。
RNN在训练阶段通过反向传播学习U和W。这些权重决定了之前时刻的隐藏状态和当前输入的重要性。基本上,它们决定了生成当前输出时,隐藏状态和当前输入所起到的作用。激活函数∅给RNN加上了非线性,从而简化了进行反向传播时的梯度计算。
RNN的劣势
RNN不是完美的。它有一个重大缺陷,称为梯度消失问题,阻止它取得高精确度。随着上下文长度的增加,展开的RNN中的网络层也增加了。因此,随着网络的加深,反向传播中由后往前传播的梯度变得越来越小。学习率变得很低,期望这样的模型学习到语言的长期依赖不太现实。换句话说,RNN在记忆序列中很久之前出现的单词上遇到了困难,只能基于最近的一些单词做出预测。
图片来源:anishsingh20
RNN的扩展
这些年来,研究人员研发了更复杂的RNN变体,以应对标准RNN模型的不足。让我们简短地总结以下其中最重要的一些变体:
双向RNN不过是堆叠组合了2个RNN。双向RNN的输出基于2个RNN的隐藏状态得出。背后的直觉是输出可能不仅取决于序列中之前的元素,还取决于未来的元素。
长短时记忆网络(LSTM)现在相当流行。LSTM继承了标准RNN的架构,在隐藏状态上做了改动。LSTM的记忆(称为单元)接受之前的状态和当前输入作为输入。在LSTM内部,这些单元决定哪些信息保留在记忆中,哪些信息从记忆移除。接着,LSTM组合之前状态、当前记忆和输入。这一过程有效解决了梯度消失问题。
门控循环单元网络(GRU)扩展了LSTM,通过门控网络生成信号以控制当前输入和之前记忆如何工作以更新当前激活,以及当前网络状态。阀门自身的权重根据算法选择更新。
神经图灵机通过结合外部记忆资源扩展了标准RNN的能力,模型可以通过注意力过程与外部记忆资源交互。就像阿兰·图灵的图灵机,有限状态机和无限存储纸带。
使用RNN语言模型生成文本的有趣例子
好了,现在让我们来看一些使用循环神经网络生成文本的有趣例子:
Obama-RNN(机器生成的政治演说):这里作者使用RNN生成了模仿奥巴马的政治演说。模型使用奥巴马演讲稿(4.3 MB / 730895单词)作为输入,生成了多个版本的演说,主题广泛,包括就业、反恐战争、民主、中国……极其滑稽!
Harry Potter(AI撰写的《哈利波特》):在《哈利波特》的前4部上训练LSTM循环神经网络,然后根据所学生成一个新章节。去看看吧。我打赌即使JK罗琳也会对此印象深刻的。
Seinfeld Scripts(计算机版本的《宋飞正传》):使用第3季的剧本作为输入,生成了关于主角的3页剧本。生成的剧本风格奇特,提问浮夸,充斥各种术语——和《宋飞正传》的风格相匹配。
RNN的真实世界应用
RNN的美妙之处在于应用的多样性。我们使用RNN的时候,可以处理多种多样的输入和输出。让我们重新回顾下开头提到的谷歌翻译的例子。这是神经机器翻译的一个例子,通过一个巨大的循环神经网络建模语言翻译。这类似语言建模,输入是源语言的单词序列,输出是目标语言的单词序列。
图片来源:sdl.com
标准的神经机器翻译是一个端到端的神经网络,其中源语言的句子由一个RNN编码(称为编码器),另一个RNN预测目标单词(称为解码器)。RNN编码器逐符号地读取源语言的句子,并在最后的隐藏状态中总结整个句子。RNN解码器通过反向传播学习这一总结,并返回翻译好的版本。
机器翻译方面的一些论文:
A Recursive Recurrent Neural Network for Statistical Machine Translation(用于统计机器翻译的递归循环神经网络,微软亚研院和中科大联合研究)
Sequence to Sequence Learning with Neural Networks(神经网络的序列到序列学习,谷歌)
Joint Language and Translation Modeling with Recurrent Neural Networks(循环神经网络的语言、翻译联合建模,微软研究院)
除了之前讨论的语言建模和机器翻译,RNN在其他一些自然语言处理任务中也取得了巨大的成功:
1 情感分析 一个简单的例子是分类推特上的推文(积极、消极)。
情感分析方面的论文:
Benchmarking Multimodal Sentiment Analysis(多模态情感分析评测,新加坡NTU、印度NIT、英国斯特林大学联合研究)
2 图像说明
搭配卷积神经网络,RNN可以用于为没有标注的图像生成描述的模型。给定需要文本描述的图像,输出是单词组成的序列或句子。输入的尺寸也许是固定的,但输出长度是可变的。
关于图像说明的论文:
Explain Images with Multimodal Recurrent Neural Networks(使用多模态循环神经网络解释图像,百度研究院、UCLA联合研究)
Long-Term Recurrent Convolutional Networks for Visual Recognition and Description(用于视觉识别和描述的长期循环卷积网络,伯克利)
Show and Tell: A Neural Image Caption Generator(看图说话:神经图像说明生成器,谷歌)
Deep Visual-Semantic Alignments for Generating Image Descriptions(用于生成图像说明的深度视觉-语义对齐,斯坦福)
Translating Videos to Natural Language Using Deep Recurrent Neural Networks(基于深度循环神经网络翻译视频至自然语言,德州大学、麻省大学洛威尔分校、伯克利联合研究)
YouTube自动生成的字幕;图片来源:filmora.wondershare.com/vlogger
3 语音识别
比如SoundHound和Shazam这样的听音识曲应用。
语音识别方面的论文:
Sequence Transduction with Recurrent Neural Networks(基于循环神经网络的序列转换,多伦多大学)
Long Short-Term Memory Recurrent Neural Network Architectures for Large-Scale Acoustic Modeling(用于大规模声学建模的长短期记忆循环网络架构,谷歌)
Towards End-to-End Speech Recognition with Recurrent Neural Networks(通向端到端语音识别的循环神经网络,DeepMind、多伦多大学联合研究)
Shazam应用
结语
复习一下本文的关键点:
语言建模是一个预测下一个单词的系统。它是一个可以帮助我们衡量我们在语言理解领域的进展的基准任务,同时也是其他自然语言处理系统(比如机器翻译、文本总结、语音识别)的子部件。
循环神经网络接受任意长度的序列化输入,在每一步应用相同的权重,并且可以在每步生成输出(可选)。总体上来说,RNN是一个构建语言模型的出色方法。
此外,RNN还可以用于句子分类、词性标记、问题回答……
顺便提一下,你看了今年的Google I/O大会吗?谷歌基本上已经成了一家AI优先的公司。谷歌引入的出类拔萃的AI系统之一是Duplex,一个可以通过电话完成真实世界任务的系统。接收完成特定任务的指示(例如安排预约)后,Duplex可以和电话另一头的人自然地对话。
Duplex的核心是基于TFX构建的RNN,在匿名化的电话交谈数据语料库上训练,以达到高准确率。RNN利用了谷歌的自动语音识别技术的输出、音频的特征、谈话的历史、谈话的参数等信息。而TFX的超参数优化进一步改善了模型。
很好,AI对话的未来已经取得了第一个重大突破。这一切都要感谢语言建模的发电厂,循环神经网络。
-
循环神经网络(RNN)和(LSTM)初学者指南2019-02-05 944
-
循环神经网络是如何工作的2019-07-05 1158
-
PyTorch教程之循环神经网络2023-06-05 321
-
什么是RNN (循环神经网络)?2024-02-29 4033
-
卷积神经网络与循环神经网络的区别2024-07-03 3251
-
循环神经网络和递归神经网络的区别2024-07-04 907
-
循环神经网络和卷积神经网络的区别2024-07-04 1289
-
循环神经网络的基本原理是什么2024-07-04 641
-
循环神经网络的基本概念2024-07-04 680
-
循环神经网络处理什么数据2024-07-04 474
-
循环神经网络算法原理及特点2024-07-04 653
-
递归神经网络是循环神经网络吗2024-07-04 753
-
递归神经网络与循环神经网络一样吗2024-07-05 849
-
rnn是什么神经网络模型2024-07-05 607
-
rnn是递归神经网络还是循环神经网络2024-07-05 576
全部0条评论

快来发表一下你的评论吧 !
