

如何在Raspberry Pi 3上构建机器学习应用程序
描述
希望评估机器学习方法的开发人员发现了越来越多的专业硬件和开发平台,这些平台通常针对特定类别的机器学习架构和应用程序进行调整。虽然这些专业平台对于许多机器学习应用程序至关重要,但很少有新的机器学习人员可以做出有关选择理想平台的明智决策。
开发人员需要一个更易于访问的平台来获得机器开发经验学习应用程序并更深入地了解资源需求和最终的功能。
如Digi-Key文章“使用随时可用的硬件和软件开始机器学习”中所述,开发任何用于监督机器学习的模型包括三个关键步骤:
准备培训模型的数据
模型实施
模型培训
数据准备将熟悉的数据采集方法与标记特定数据实例所需的额外步骤相结合,以便在培训过程中使用。对于最后两个步骤,机器学习模型专家直到最近才需要使用相对较低级别的数学库来实现模型算法中涉及的详细计算。机器学习框架的可用性大大降低了模型实施和培训的复杂性。
今天,任何熟悉Python或其他支持语言的开发人员都可以使用这些框架快速开发能够运行的机器学习模型。各种各样的平台。本文将介绍如何在Raspberry Pi 3上开发机器学习应用程序之前的机器学习堆栈和培训过程。
机器学习堆栈
为了支持模型开发,机器学习框架提供了一整套资源(图1)。在典型堆栈的顶部,培训和推理库提供定义,培训和运行模型的服务。这些模型反过来建立在内核函数的优化实现上,例如卷积和激活函数,如ReLU,以及矩阵乘法等。这些优化的数学函数适用于较低级别的驱动程序,这些驱动程序提供抽象层以与通用CPU连接,或者在可用时充分利用专用硬件(如图形处理单元(GPU))。
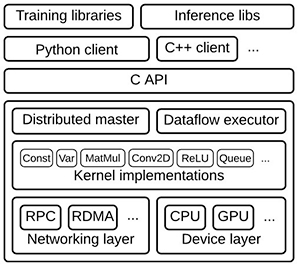
图1:在典型的机器学习堆栈中,更高级别的库提供了实现神经网络和其他机器学习算法的功能,借鉴了专业的数学库实现针对底层硬件层中的CPU和GPU优化的内核函数。 (图片来源:Google)
随着提供这些堆栈的TensorFlow等机器学习框架的可用性,无论硬件目标如何,在应用程序中实现机器学习的开发过程大致相同。在不同硬件平台上利用TensorFlow的能力允许开发人员开始在相对适度的硬件平台上探索模型开发,然后利用这些经验在更强大的硬件上开发机器学习应用程序。
预计专业的高性能人工智能(AI)芯片最终将为开发人员提供实现复杂机器学习算法的能力。在此之前,开发人员可以开始评估机器学习并使用通用平台创建真正的机器学习应用程序,包括Raspberry Pi Foundation的Raspberry Pi 3,或任何基于通用处理器(如Arm ®)的现成开发板。 Cortex ® -A系列MCU或Arm Cortex-M系列MCU。
Raspberry Pi 3作为机器学习应用程序的开发平台提供了一些直接的优势。其Arm Cortex-A53四核处理器提供了显着的性能,而核心的NEON单指令,多数据(SIMD)扩展能够执行一定程度的多媒体和机器学习类型处理。但是,开发人员可以使用任意数量的兼容硬件附件轻松扩展基础Raspberry Pi 3硬件平台。
例如,要创建下面描述的机器学习图像识别系统,开发人员可以添加相机,如800万像素Raspberry Pi相机模块v2或其低光Pi NoIR相机(图2)。
图2:低 - 诸如Raspberry Pi 3之类的成本板为机器学习开发提供了一个有用的平台,支持诸如用于开发图像分类应用程序的相机模块之类的附加组件。 (图片来源:Raspberry Pi Foundation)
在软件方面,Raspberry Pi社区创建了一个同样丰富的生态系统,开发人员可以在其中找到包含完整的预编译二进制轮文件的分发版,以便在Raspberry上安装TensorFlow皮。 TensorFlow在Raspberry Pi车轮存储库piwheels.org上为Python 3.4和3.5提供了这些车轮文件。或者,由于Docker现在正式支持Arm架构,开发人员可以使用dockerhub.com中的合适容器。
实现机器学习模型
使用这种软件,Raspberry Pi 3和相机模块的组合,开发人员可以使用Arm的示例代码构建一个简单的机器学习手势识别应用程序。此应用程序仅用于检测用户何时做出特定手势:在这种情况下,以一种庆祝手势向空中举手。
首先,使用Python脚本(记录。 py)记录几次执行相同手势的人的短视频片段。由于此应用程序应尽可能简单,因此下一步将使用TensorFlow中嵌入的Keras机器学习应用程序编程接口(API)开始培训。在此示例中,训练过程在另一个Python脚本(train.py)中定义,该脚本包括Keras模型定义和训练序列(清单1)。
复制 def main():. 。 。 model_file = argv [1] recording_files = argv [2:] feature_extractor = PiNet()。 。 。 for i,filename in enumerate(recording_files):stdout.write('%s'%filename)stdout.flush()with open(filename,'rb')as f:x = load(f)features = [feature_extractor.features (f)对于f in x] label = np.zeros((len(recording_files),))label [i] = 1.#在该列的文件栏中创建一个带有1的标签xs + = features#添加从此文件加载的帧的功能ys + = [label] * len(x)#为文件中的每个帧添加标签class_count [i] = len(x)print(“创建网络以对%s进行分类“%','。join(recording_files))classifier = make_classifier(xs [0] .shape,len(recording_files))print(”训练网络将高级功能映射到%d类别“%len(recording_files)) classifier.fit([np.array(xs)],[np.array(ys)],epochs = 20,shuffle = True)print(“现在我们保存这个模型,以便我们可以随时部署它”)分类器。 save(model_file)def make_classifier(input_shape,num_classes):“”“制作一个非常简单的分类器图层:GaussianNoise:添加随机噪声到pre发泄我们的分类器记住具体的例子。展平:输入可能来自具有形状(x,y,深度)的层;将其压平至1D。密集:每个类提供一个输出,按比例缩放为1(softmax)“”##定义一个简单的神经网络net_input = keras.layers.Input(input_shape)noise = keras.layers.GaussianNoise(0.3)(net_input)flat = keras .layers.Flatten()(noise)net_output = keras.layers.Dense(num_classes,activation ='softmax')(flat)net = keras.models.Model([net_input],[net_output])#在使用前编译模型损失应该与输出激活函数匹配,例如#binary_crossentropy用于sigmoid,categorical_crossentropy用于softmax,mse用于线性。#Adam是一个可靠的默认优化器,我们可以将学习速率保留为默认值.net.compile(optimizer = keras。 optimizers.Adam(),loss ='categorical_crossentropy',metrics = ['accuracy'])return net
清单1:在Arm示例应用程序库的这个片段中,培训过程结合了一个预先训练好的模型,该应用程序需要简单的分类器。(代码来源:Arm)
尽管这个模型很简单,它实际上非常复杂,使用了一种称为转移学习的技术。转移学习使用经过验证的模型,该模型使用一个数据集作为培训针对不同但相关问题集的模型的起点。在这种情况下,该应用程序使用来自Google的MobileNet模型集的优化卷积神经网络(CNN)模型。
由Google开发的MobileNet模型是CNN在标记的事实标准ImageNet数据集的子集上进行训练图片。 MobileNet模型的显着特点是它们被配置为支持移动设备或通用板(如Raspberry Pi)所需的减少的资源需求。这种资源减少的成本降低了准确性。虽然这些模型提供的精确度远远低于关键任务应用程序的要求,但MobileNet模型可以证明对于更宽松的要求和转移学习中的基本模型非常有用。
对于此应用程序,train.py脚本使用MobileNet模型创建一个特征提取器,其中最终分类层已被删除:
feature_extractor = PiNet()
PiNet函数只读取代码库中包含的修改后的MobileNet模型。
然后,应用程序使用该修改后的模型为此训练数据集创建要素集(要素):
features = [feature_extractor.features(f)for f in x]
其中x是一个数组,包含在初始数据收集步骤中由record.py生成的帧。
最后,train.py脚本使用Keras fit方法训练模型和save方法以保存最终模型以供推理使用:
classifier.fit ([np.array(xs)],[np.array(ys)],epochs = 20,shuffle = True)
classifier.save(model_file)
要使用生成的模型文件进行推理,请调用另一个脚本run.py.此脚本中的关键设计模式是无限循环,它采用每个帧,计算要素(extractor.features),使用相同的分类器进行推理(classifier.predict),并生成标签的预测(np.argmax)。预测只是目标手势是否已经发生(清单2)。
复制 而True:raw_frame = camera.next_frame()#使用MobileNet获取此帧的功能z = extractor.features(raw_frame)#使用这些功能,我们可以预测a 'normal'/'yeah'class(0或1)#Keras期望一组输入并产生一个输出数组classes = classifier.predict(np.array([z]))[0]#smooth the outputs - this添加延迟但减少中断平滑=平滑* SMOOTH_FACTOR +类*(1.0 - SMOOTH_FACTOR)选择= np.argmax(平滑)#所选类是概率最高的类#显示类概率和选定的类摘要='类%d [%s]'%(已选中,''。join('%02.0f %%'%(99 * p)为平滑的p))stderr.write(' r'+ summary)
清单2:Arm示例run.py脚本中的这个片段演示了推理的基本设计模式,使用相同的预训练模型提取特征和相同的分类器来执行推理。 (代码源:Arm)
多分类模型
开发一个应用程序来检测一类输入,例如单个手势,这在机器学习开发中是值得的,但机器学习应用程序通常用于多类分类。另一个Arm示例应用程序演示了执行此操作所需的步骤,并提供了完成多分类模型开发通常所需步骤的更完整示例。例如,除了捕获期望的手势之外,单个手势应用程序不需要重要的数据准备。相比之下,多分类应用程序涉及大量数据捕获和相关的开发步骤,以使用Arm提供的Python脚本使用目标类(手势)标记捕获的视频。在这种情况下,开发者捕获不同动作的短视频剪辑,例如进入或离开房间,指向灯(打开或关闭),以及制作不同的手势以开始或停止音乐播放。使用classify.py脚本,查看图像并输入相应的标签(与每个操作对应的整数)。标记完成后,保留约10%的标记数据,用于测试模型,如下所述。
使用训练数据和保留的测试集,下一步是创建模型本身。与在单个手势应用程序中大量使用预训练模型不同,此应用程序构建完整的CNN模型。在这种情况下,使用一系列Keras语句,使用构建2D卷积层(Conv2D)的Keras函数逐层构建模型,添加激活层(激活),池化层(MaxPooling2D)等(列表) 3)。
复制 def main():如果len(argv)!= 3或argv [1] ==' - help':print(“ “”用法:train.py TRAIN_DIR VAL_DIR ...训练一个转换网后保存TRAIN_DIR/model.h5以区分其子目录中的图像。“”“)exit(1)train_data_dir = argv [1] val_data_dir = argv [2 ] nb_train_samples = len(glob('%s/*/* .png'%train_data_dir))nb_classes = len(glob('%s/*/'%train_data_dir))batch_size = 100 model = Sequential()model.add( Conv2D(32,(3,3),input_shape =(128,128,3)))model.add(Activation('elu'))model.add(MaxPooling2D(pool_size =(2,2)))model.add (Conv2D(32,(3,3)))model.add(Activation('elu'))model.add(MaxPooling2D(pool_size =(2,2)))model.add(Conv2D(64,(3,3) )))model.add(Activation('elu'))model.add(MaxPooling2D(pool_size =(2,2))) model.add(Flatten())model.add(Dense(64))model.add(Activation('elu'))model.add(Dropout(0.5))model.add(Dense(nb_classes))model.add(激活('softmax'))model.compile(loss ='categorical_crossentropy',optimizer ='adam',metrics = ['accuracy'])
清单3:Arm多分类示例应用程序说明了使用Keras函数逐层构建卷积神经网络。 (代码源:Arm)
该模型还引入了dropout层的概念(清单3中的Dropout),它提供了一种称为正则化的模型优化形式。在模型训练算法中,正则化因子降低了模型追逐每个特征的趋势,这可能导致模型中的过度拟合。 Dropout通过将一组随机神经元从处理链中删除而执行同样的功能(图3)。
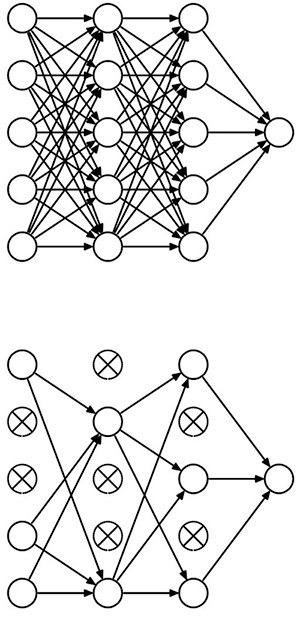
图3:Dropout通过随机禁用神经元在深层神经网络中提供正则化,有效地将完全连接的神经网络(顶部)转换为密度较低的版本(底部) 。 (图片来源:多伦多大学)
掌握完成的模型后,使用TensorFlow和其他框架内置的传统培训方法。对于非常复杂的模型,实际的培训过程可能需要数小时,数天甚至数周。虽然开发人员通常使用GPU来加速培训,但是像之前的应用程序一样,使用传输学习可以帮助减少培训时间。但是,在此多分类应用程序中使用完整模型会转化为更长的训练时间。 Arm指出,这个应用程序的培训时间在Raspberry Pi上可能很重要。相反,Arm建议开发人员在自己的工作站上安装TensorFlow,在工作站上进行培训,然后将训练好的模型复制回Raspberry Pi。
使用模型时,推理过程大部分遵循相同的系列先前为单个手势应用程序显示的调用。当然,对于这个应用程序,推理过程使用清单3中描述的自定义模型,而不是清单1中描述的单个手势预训练模型和浅层分类器。除了这个明显的差异之外,多分类模型开发还增加了一个额外的步骤用于在生产使用之前测试模型。
在此测试阶段,运行模型就像生产推理一样,但不使用一些新的输入数据,而是使用培训中保留的10%标记数据。由于已经知道每个测试图像推断的正确答案,因此测试脚本可以记录实际的准确度结果,以便与完成培训时获得的准确度结果进行比较。
除了作为硬度量标准的基本优势之外,测试阶段和模型响应测试数据的方式可以提供关于可能需要采取哪些步骤来改进模型的提示。因为该测试数据包括在训练中使用的相同类型的数据,所以训练的模型应该产生具有在训练期间实现的相同精度水平的预测。对于过度拟合的模型,减少输入特征的数量并应用更强大的正则化方法。对于有欠配合的模型,请做相反的事情;添加更多功能并减少正规化量。
基于MCU的应用程序
TensorFlow和其他框架均提供一致的模型开发方法,可应用于各种目标硬件平台。然而,它们绝不是唯一的方法。在基于Arm的平台上开发机器学习应用程序时,开发人员可以转向公司自己的库。
Arm Compute Library开发用于支持Arm Cortex-A系列MCU,提供了一整套实现CNN的功能。和其他机器学习算法。对于Arm Cortex-M系列MCU,Arm Cortex微控制器软件接口标准(CMSIS)包括神经网络(NN)库。正如CMSIS-DSP扩展用于DSP应用的CMSIS一样,CMSIS-NN提供机器学习功能,用于在基于Arm Cortex-M的平台上实现流行的NN架构。例如,使用CMSIS-NN库在STMicroelectronics NUCLEO-F746ZG开发板上实现CNN,该开发板是基于STMicroelectronics Arm Cortex-M7的STM32F746ZG MCU构建的。
用CMSIS实现神经网络-NN,开发人员可以从TensorFlow或其他框架导入现有模型。或者,他们可以通过一系列CMSIS-NN函数调用本地实现CNN。例如,为了实现能够处理行业标准CIFAR-10标记图像数据集的CNN,开发人员将逐层构建模型,类似于之前针对Keras所示的方法。在这种情况下,CNN层实现为一系列CMSIS-NN函数调用。最终的softmax层产生CIFAR-10所需的10个输出神经元(清单4)。
复制 int main(){。 。 。//conv1 img_buffer2 - > img_buffer1 arm_convolve_HWC_q7_RGB(img_buffer2,CONV1_IM_DIM,CONV1_IM_CH,conv1_wt,CONV1_OUT_CH,CONV1_KER_DIM,CONV1_PADDING,CONV1_STRIDE,conv1_bias,CONV1_BIAS_LSHIFT,CONV1_OUT_RSHIFT,img_buffer1,CONV1_OUT_DIM,(q15_t *)col_buffer,NULL); arm_relu_q7(img_buffer1,CONV1_OUT_DIM * CONV1_OUT_DIM * CONV1_OUT_CH);//pool1 img_buffer1 - > img_buffer2 arm_maxpool_q7_HWC(img_buffer1,CONV1_OUT_DIM,CONV1_OUT_CH,POOL1_KER_DIM,POOL1_PADDING,POOL1_STRIDE,POOL1_OUT_DIM,NULL,img_buffer2);//CONV2 img_buffer2 - > img_buffer1 arm_convolve_HWC_q7_fast(img_buffer2,CONV2_IM_DIM,CONV2_IM_CH,conv2_wt,CONV2_OUT_CH,CONV2_KER_DIM,CONV2_PADDING,CONV2_STRIDE,conv2_bias,CONV2_BIAS_LSHIFT,CONV2_OUT_RSHIFT,img_buffer1,CONV2_OUT_DIM,(q15_t *)col_buffer,NULL); arm_relu_q7(img_buffer1,CONV2_OUT_DIM * CONV2_OUT_DIM * CONV2_OUT_CH);//POOL2 img_buffer1 - > img_buffer2 arm_maxpool_q7_HWC(img_buffer1,CONV2_OUT_DIM,CONV2_OUT_CH,POOL2_KER_DIM,POOL2_PADDING,POOL2_STRIDE,POOL2_OUT_DIM,col_buffer,img_buffer2);//conv3 img_buffer2 - > img_buffer1 arm_convolve_HWC_q7_fast(img_buffer2,CONV3_IM_DIM,CONV3_IM_CH,conv3_wt,CONV3_OUT_CH,CONV3_KER_DIM,CONV3_PADDING ,CONV3_STRIDE,conv3_bias,CONV3_BIAS_LSHIFT,CONV3_OUT_RSHIFT,img_buffer1,CONV3_OUT_DIM,(q15_t *)col_buffer,NULL); arm_relu_q7(img_buffer1,CONV3_OUT_DIM * CONV3_OUT_DIM * CONV3_OUT_CH);//pool3 img_buffer-> img_buffer2 arm_maxpool_q7_HWC(img_buffer1,CONV3_OUT_DIM,CONV3_OUT_CH,POOL3_KER_DIM,POOL3_PADDING,POOL3_STRIDE,POOL3_OUT_DIM,col_buffer,img_buffer2); arm_fully_connected_q7_opt(img_buffer2,ip1_wt,IP1_DIM,IP1_OUT,IP1_BIAS_LSHIFT,IP1_OUT_RSHIFT,ip1_bias,output_data,(q15_t *)img_buffer1); arm_softmax_q7(output_data,10,output_data); for(int i = 0; i <10; i ++){printf(“%d:%d n”,i,output_data [i]); } return 0;}
清单4:在Arm示例CIFAR-10应用程序的这个片段中,主例程说明了用于构建CIFAR10目标卷积神经网络的一系列调用。 Arm Cortex微控制器软件接口标准(CMSIS)神经网络(NN)库。 (代码来源:Arm)
通用平台缺乏资源来提供基于GPU的系统可能的推理性能。结果,这些平台通常不能可靠地支持以维持无闪烁外观所需的通常帧速率操作的任何类型的“实时”视频推断。即便如此,上述CMSIS-NN CIFAR-10模型可以实现大约每秒10的推理速度,这可能足够快以支持需要有限更新速率的相对简单的应用程序。
持续发展简化的模型,如MobileNet和TensorFlow Lite和Facebook的Caffe2Go等框架,为物联网和其他连接应用的资源受限设备实现机器学习提供了更多选择。
结论
机器学习应用程序遵循典型的数据准备和培训开发模式,在不同的目标平台上保持概念上的一致性。因此,开发人员可以使用低成本开发板快速获得实现机器学习算法的经验。
随着机器学习库和针对这些板优化的框架的可用性,开发人员可以使用诸如Raspberry之类的板Pi 3或STMicroelectronics NUCLEO-F746ZG实现了有效的机器学习推理引擎,能够为具有适度要求的应用提供有用的结果。
-
使用Raspberry Pi上的OpenCV库构建人脸识别系统2022-09-07 1211
-
如何在Raspberry Pi 3上安装OpenCV4库2022-09-08 1598
-
基于Raspberry PI的应用程序的典型场景家庭自动化2023-06-13 225
-
Raspberry Pi 3和3 b +上的Android Pie 9.02020-09-29 0
-
使用计算库在Raspberry PI和HiKey 960上分析AlexNet2023-08-29 0
-
raspberry pi官网2020-03-07 6044
-
Eyer1951正在使用带有节拍检测应用程序的Raspberry Pi 3 B +2020-10-28 1547
-
如何在Raspberry Pi上安装TensorFlow2022-09-01 2215
-
在Raspberry Pi上安装Android的方法2022-09-05 18903
-
如何在Raspbian上设置没有显示器和键盘的Raspberry Pi2022-09-22 1657
-
如何使用Raspberry Pi3和蓝牙构建遥控汽车2022-11-21 2582
-
Raspberry Pi Zero便携终端的构建2023-01-05 397
-
如何在Raspberry Pi零2W上阻止带有Pi孔的广告2023-06-14 335
-
使用Raspberry Pi进行机器学习智能库存跟踪2023-06-26 369
-
使用Raspberry Pi来托管服务应用程序以及运行客户端程序2023-07-04 221
全部0条评论

快来发表一下你的评论吧 !
