

DPCNN,究竟是多么牛逼的网络呢?
电子说
描述
ACL2017年中,腾讯AI-lab提出了Deep Pyramid Convolutional Neural Networks for Text Categorization(DPCNN)。论文中提出了一种基于word-level级别的网络-DPCNN,由于上一篇文章介绍的TextCNN 不能通过卷积获得文本的长距离依赖关系,而论文中DPCNN通过不断加深网络,可以抽取长距离的文本依赖关系。实验证明在不增加太多计算成本的情况下,增加网络深度就可以获得最佳的准确率。
DPCNN结构
究竟是多么牛逼的网络呢?我们下面来窥探一下模型的芳容。
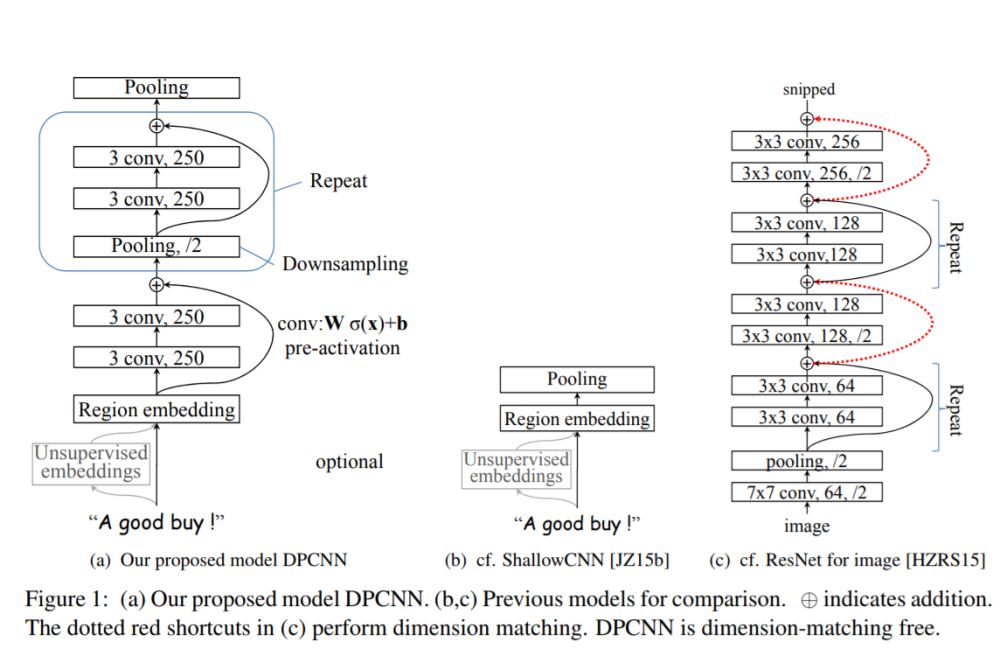
DPCNN结构细节
模型是如何通过加深网络来捕捉文本的长距离依赖关系的呢?下面我们来一一道来。为了更加简单的解释DPCNN,这里我先不解释是什么是Region embedding,我们先把它当作word embedding。
等长卷积
首先交代一下卷积的的一个基本概念。一般常用的卷积有以下三类:
假设输入的序列长度为n,卷积核大小为m,步长(stride)为s,输入序列两端各填补p个零(zero padding),那么该卷积层的输出序列为(n-m+2p)/s+1。
(1) 窄卷积(narrow convolution): 步长s=1,两端不补零,即p=0,卷积后输出长度为n-m+1。
(2) 宽卷积(wide onvolution) :步长s=1,两端补零p=m-1,卷积后输出长度 n+m-1。
(3) 等长卷积(equal-width convolution): 步长s=1,两端补零p=(m-1)/2,卷积后输出长度为n。如下图所示,左右两端同时补零p=1,s=3。
池化
那么DPCNN是如何捕捉长距离依赖的呢?这里我直接引用文章的小标题——Downsampling with the number of feature maps fixed。
作者选择了适当的两层等长卷积来提高词位embedding的表示的丰富性。然后接下来就开始 Downsampling (池化)。再每一个卷积块(两层的等长卷积)后,使用一个size=3和stride=2进行maxpooling进行池化。序列的长度就被压缩成了原来的一半。其能够感知到的文本片段就比之前长了一倍。
例如之前是只能感知3个词位长度的信息,经过1/2池化层后就能感知6个词位长度的信息啦,这时把1/2池化层和size=3的卷积层组合起来如图所示。

固定feature maps(filters)的数量
为什么要固定feature maps的数量呢?许多模型每当执行池化操作时,增加feature maps的数量,导致总计算复杂度是深度的函数。与此相反,作者对feature map的数量进行了修正,他们实验发现增加feature map的数量只会大大增加计算时间,而没有提高精度。
另外,夕小瑶小姐姐在知乎也详细的解释了为什么要固定feature maps的数量。有兴趣的可以去知乎搜一搜,讲的非常透彻。
固定了feature map的数量,每当使用一个size=3和stride=2进行maxpooling进行池化时,每个卷积层的计算时间减半(数据大小减半),从而形成一个金字塔。
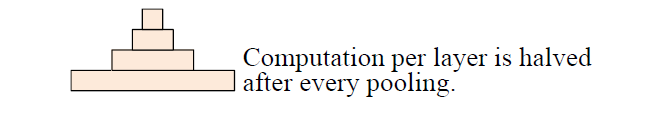
这就是论文题目所谓的 Pyramid。
好啦,看似问题都解决了,目标成功达成。剩下的我们就只需要重复的进行等长卷积+等长卷积+使用一个size=3和stride=2进行maxpooling进行池化就可以啦,DPCNN就可以捕捉文本的长距离依赖啦!
Shortcut connections with pre-activation
但是!如果问题真的这么简单的话,深度学习就一下子少了超级多的难点了。
(1) 初始化CNN的时,往往各层权重都初始化为很小的值,这导致了最开始的网络中,后续几乎每层的输入都是接近0,这时的网络输出没有意义;
(2) 小权重阻碍了梯度的传播,使得网络的初始训练阶段往往要迭代好久才能启动;
(3) 就算网络启动完成,由于深度网络中仿射矩阵(每两层间的连接边)近似连乘,训练过程中网络也非常容易发生梯度爆炸或弥散问题。
当然,上述这几点问题本质就是梯度弥散问题。那么如何解决深度CNN网络的梯度弥散问题呢?当然是膜一下何恺明大神,然后把ResNet的精华拿来用啦! ResNet中提出的shortcut-connection/ skip-connection/ residual-connection(残差连接)就是一种非常简单、合理、有效的解决方案。
类似地,为了使深度网络的训练成为可能,作者为了恒等映射,所以使用加法进行shortcut connections,即z+f(z),其中 f 用的是两层的等长卷积。这样就可以极大的缓解了梯度消失问题。
另外,作者也使用了 pre-activation,这个最初在何凯明的“Identity Mappings in Deep Residual Networks上提及,有兴趣的大家可以看看这个的原理。直观上,这种“线性”简化了深度网络的训练,类似于LSTM中constant error carousels的作用。而且实验证明 pre-activation优于post-activation。
整体来说,巧妙的结构设计,使得这个模型不需要为了维度匹配问题而担忧。
Region embedding
同时DPCNN的底层貌似保持了跟TextCNN一样的结构,这里作者将TextCNN的包含多尺寸卷积滤波器的卷积层的卷积结果称之为Region embedding,意思就是对一个文本区域/片段(比如3gram)进行一组卷积操作后生成的embedding。
另外,作者为了进一步提高性能,还使用了tv-embedding (two-views embedding)进一步提高DPCNN的accuracy。
上述介绍了DPCNN的整体架构,可见DPCNN的架构之精美。本文是在原始论文以及知乎上的一篇文章的基础上进行整理。本文可能也会有很多错误,如果有错误,欢迎大家指出来!建议大家为了更好的理解DPCNN ,看一下原始论文和参考里面的知乎。
用Keras实现DPCNN网络
这里参考了一下kaggle的代码,模型一共用了七层,模型的参数与论文不太相同。这里滤波器通道个数为64(论文中为256),具体的参数可以参考下面的代码,部分我写了注释。
def CNN(x): block = Conv1D(filter_nr, kernel_size=filter_size, padding=same, activation=linear, kernel_regularizer=conv_kern_reg, bias_regularizer=conv_bias_reg)(x) block = BatchNormalization()(block) block = PReLU()(block) block = Conv1D(filter_nr, kernel_size=filter_size, padding=same, activation=linear, kernel_regularizer=conv_kern_reg, bias_regularizer=conv_bias_reg)(block) block = BatchNormalization()(block) block = PReLU()(block) return blockdef DPCNN(): filter_nr = 64 #滤波器通道个数 filter_size = 3 #卷积核 max_pool_size = 3 #池化层的pooling_size max_pool_strides = 2 #池化层的步长 dense_nr = 256 #全连接层 spatial_dropout = 0.2 dense_dropout = 0.5 train_embed = False conv_kern_reg = regularizers.l2(0.00001) conv_bias_reg = regularizers.l2(0.00001) comment = Input(shape=(maxlen,)) emb_comment = Embedding(max_features, embed_size, weights=[embedding_matrix], trainable=train_embed)(comment) emb_comment = SpatialDropout1D(spatial_dropout)(emb_comment) #region embedding层 resize_emb = Conv1D(filter_nr, kernel_size=1, padding=same, activation=linear, kernel_regularizer=conv_kern_reg, bias_regularizer=conv_bias_reg)(emb_comment) resize_emb = PReLU()(resize_emb) #第一层 block1 = CNN(emb_comment) block1_output = add([block1, resize_emb]) block1_output = MaxPooling1D(pool_size=max_pool_size, strides=max_pool_strides)(block1_output) #第二层 block2 = CNN(block1_output) block2_output = add([block2, block1_output]) block2_output = MaxPooling1D(pool_size=max_pool_size, strides=max_pool_strides)(block2_output) #第三层 block3 = CNN(block2_output) block3_output = add([block3, block2_output]) block3_output = MaxPooling1D(pool_size=max_pool_size, strides=max_pool_strides)(block3_output) #第四层 block4 = CNN(block3_output) block4_output = add([block4, block3_output]) block4_output = MaxPooling1D(pool_size=max_pool_size, strides=max_pool_strides)(block4_output) #第五层 block5 = CNN(block4_output) block5_output = add([block5, block4_output]) block5_output = MaxPooling1D(pool_size=max_pool_size, strides=max_pool_strides)(block5_output) #第六层 block6 = CNN(block5_output) block6_output = add([block6, block5_output]) block6_output = MaxPooling1D(pool_size=max_pool_size, strides=max_pool_strides)(block6_output) #第七层 block7 = CNN(block6_output) block7_output = add([block7, block6_output]) output = GlobalMaxPooling1D()(block7_output) #全连接层 output = Dense(dense_nr, activation=linear)(output) output = BatchNormalization()(output) output = PReLU()(output) output = Dropout(dense_dropout)(output) output = Dense(6, activation=sigmoid)(output) model = Model(comment, output) model.summary() model.compile(loss=binary_crossentropy, optimizer=optimizers.Adam(), metrics=[accuracy]) return model
DPCNN实战
上面我们用keras实现了我们的DPCNN网络,这里我们借助kaggle的有毒评论文本分类竞赛来实战下我们的DPCNN网络。
具体地代码,大家可以去我的GitHub上面找到源码:
https://github.com/hecongqing/TextClassification/blob/master/DPCNN.ipynb
-
图解:IGBT究竟是什么?2020-08-10 0
-
S参数究竟是什么?2021-03-01 0
-
我们仿真DDR究竟是仿真什么2021-03-04 0
-
电感饱和究竟是什么2021-03-11 0
-
真正软件定义无线电究竟是怎样的?2021-05-14 0
-
分贝究竟是什么?如何去理解它?2021-05-31 0
-
一文读懂eMMC究竟是啥?2021-06-18 0
-
SSD用久了速度会下降,这究竟是为什么呢?2021-06-18 0
-
spec究竟是什么?有谁可以分享一下吗2021-06-21 0
-
retain,copy与assign究竟是有什么区别呢2021-09-30 0
-
请问NTC热敏电阻的B值究竟是什么东西呢?2023-04-23 0
-
同步电机的转数同步究竟是与什么同步啊?2023-12-19 0
-
ARM和FPGA究竟是如何进行通信的呢?2023-02-16 13333
-
串口究竟是什么呢?2023-04-12 19763
全部0条评论

快来发表一下你的评论吧 !
