

并行MAC/减少内存访问,东芝发布第五代Visconti系列图像识别SoC
描述
自动驾驶需要相当复杂的传感器组合,而这些传感器提供的数据量远远高于现有汽车搭载的传感器。
为了满足对更强大的图像处理的需求,东芝欧洲公司(TEE)宣布推出一种集成了深度学习加速器的图像识别SoC。测试数据显示,新款SoC与该公司现有产品相比,图像识别速度提高了10倍,能效提高了4倍。
深度神经网络(Deep neural network, DNN)是一种以大脑神经网络为模型的算法,与传统的模式识别和机器学习相比,它能更准确地进行识别处理,并在自动驾驶技术研发领域被大量应用。
然而,传统处理器基于DNN的图像识别需要时间,因为它依赖于大量的multiply- aggregation (MAC)计算。使用传统高速处理器的DNN也会消耗太多电能。
与L3级及以下自动辅助驾驶系统相比,L4/L5级自动驾驶汽车对计算能力的要求提高了100倍。这包括需要处理来自汽车周围多个摄像头、雷达和激光雷达传感器的输入,解释数据,并使用这些数据做出驾驶决策。
芯片制造商英伟达去年10月发布的一份有关自动驾驶车载计算能力的报告。该公司称,一辆装有10个高分辨率摄像头的汽车每秒产生20亿像素的数据,每秒处理这些数据需要250万亿次操作。
三年前,东芝与日本汽车零部件供应商DENSO合作,共同开发上述深度神经网络技术。目前,东芝已经通过DNN加速器克服了这一问题,该加速器实现了硬件级的深度学习加速。
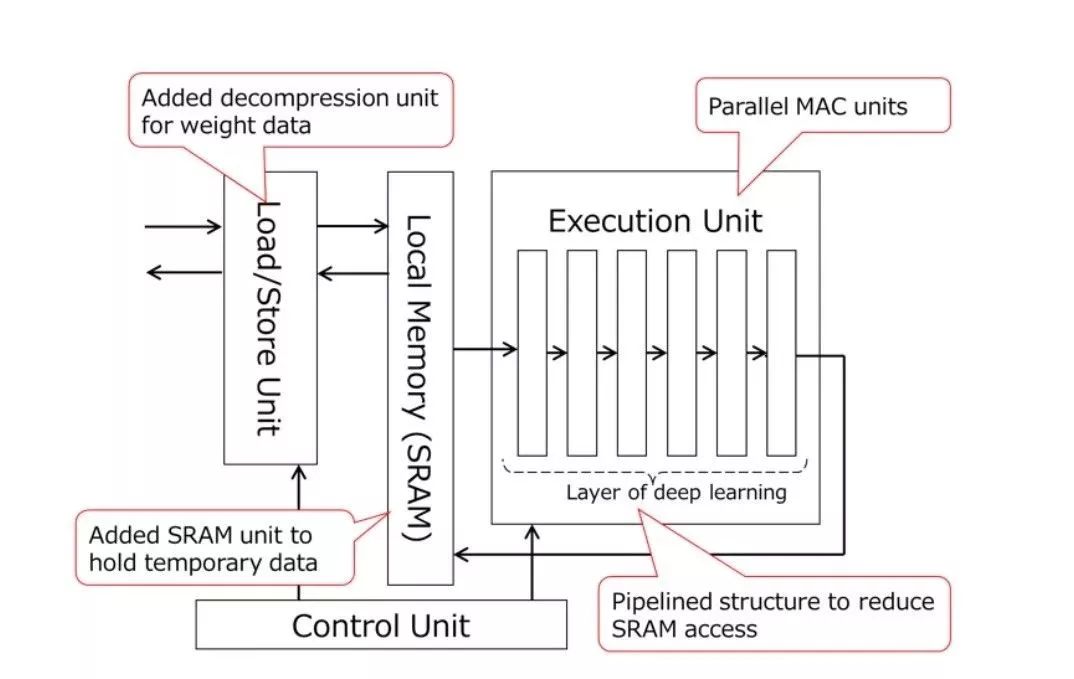
它有三个特点:
• 并行的MAC单元。DNN处理需要很多MAC计算。东芝的新设备有四个处理器,每个处理器有256个MAC单元。这提高了DNN的处理速度。
• 减少DRAM访问。传统的SoC没有本地内存来保持DNN执行单元附近的时间数据,并且访问本地内存会消耗大量的电能,加载权重数据(用于MAC计算)也会消耗电能。
在东芝的新产品中,SRAM是集成在DNN执行单元中,DNN处理分为子处理块,将时间数据保存在SRAM中,减少了DRAM的访问。
此外,东芝还为加速器增加了一个解压装置。通过解压缩单元加载预先压缩并存储在DRAM中的权重数据,这减少了从DRAM加载权重数据所涉及的功耗。
• 减少SRAM访问。传统的深度学习需要在处理完DNN的每一层后访问SRAM,这消耗了太多的能量。这款加速器在DNN执行单元中具有流水线的层结构,允许通过一个SRAM访问执行一系列DNN计算。
新的SoC符合ISO26262汽车应用功能安全标准。东芝还表示,将继续提高开发的SoC的功率效率和处理速度,并将于今年9月开始对下一代东芝图像识别处理器Visconti5(DNN硬件IP与传统图像处理技术集成)进行样品发货。

对于低成本的自动驾驶方案来说,摄像头和图像识别的作用更为明显。同时,在多传感器融合中,图像识别也被视为主传感器的角色。
此前,东芝已经提供了TMPV75和TMPV76两个系列的图像识别处理器,它们集成了RISC架构的媒体处理引擎(MPEs),以提高图像数据处理性能。该处理器能够实时处理1到4个摄像头的输入图像,并允许最多连接8个摄像头。
ARM等其他芯片制造巨头也都在推陈出新。去年9月,ARM推出了Cortex-A76AE (Automotive Enhanced),这是ARM专门为自动驾驶汽车设计的CPU架构。
ARM对A76平台进行了重新设计,增加了一种名为Split-Lock的功能,允许两个CPU内核以锁定步进(都执行相同的任务)或分割模式(执行不同的任务和应用程序)进行操作。
-
capsense第四代和第五代在感应模式上的具体区别是什么?2024-05-23 0
-
第五代移动通信技术的特点是什么2021-12-22 0
-
汇佳第五代25-29寸彩电威廉希尔官方网站 图2009-05-25 2310
-
iPod nano(第五代)功能指南手册2009-12-10 761
-
iPod 功能指南(第五代) de-CH.pdf2010-01-13 1147
-
IGBT/FWD功率损耗模拟系统 (英文,含第五代U系列IG2010-07-20 1175
-
东芝将推出Visconti2汽车专用图像识别处理器2011-10-20 1444
-
高拓讯达发布第五代DTMB/DVB-C解调芯片ATBM88692012-03-16 4309
-
东芝推出基于Cortex A9的Visconti 3图像识别双核芯片2013-03-01 1412
-
第五代增强型STC自动烧录器资料包2016-03-22 848
-
微软发布第五代小冰 “网红少女”进军物联网2017-08-23 1954
-
第五代新品重磅上市,它的优势优点是什么2020-11-24 1683
-
苹果有望在3月发布第五代iPad Pro2021-01-12 3583
-
wifi技术标准第四代第五代区别2022-01-01 37543
-
【机器视觉】欢创播报 | 比亚迪第五代DM混动技术正式发布2024-05-30 807
全部0条评论

快来发表一下你的评论吧 !
