

AI智能体的能力还会继续提高吗?
电子说
描述
虽然人类已经无望在电子竞技中打败AI多智能体,但DeepMind的研究仍在继续往前推进。最近他们公布了在强化学习方面的最新进展,并对未来进行了展望。AI智能体的能力还会继续提高吗?会有极限吗?
是的是的我们都知道,已经没有什么电子竞技能够让人类抱有哪怕1%稳赢的希望了。但是!你有没有想过,AI会不会有一个极限?它的潜力还有多少,无穷大?还是最终止步于某个境界?DeepMind的科学家也想知道。
他们最近更新了博客,以雷神之锤为例,为我们重新介绍了强化学习的最新发展、AI在《雷神之锤3·夺旗》中达到了什么样的程度,以及未来的期望。
多智能体最大的挑战:既要独自打拼,还要团队协作
掌握多人游戏中涉及到的策略、战术、团队配合,是AI研究的关键挑战。而DeepMind的科学家已经将AI调教到了和人类相当的水平,这一点在《雷神之锤3·夺旗》体现的淋漓尽致。
AI智能体在游戏中,无论是跟同类打配合,还是跟人类组团,完全天衣无缝,表现的不像个机器人。DeepMind的科学家已经在筹划将夺旗中的方法,应用在雷神之锤3的全部游戏模式中。
Quake III有非常多的游戏模式。自身提供4种,分别是Free For All(竞技场模式)、Team Deathmatch(红蓝两队对战模式)、Tournament(Duel)(单挑模式)、夺旗(红蓝两队夺旗模式)。其他包括MOD和以其开源游戏引擎衍生出的独立游戏也非常多。
https://zh.wikipedia.org/wiki/%E9%9B%B7%E7%A5%9E%E4%B9%8B%E9%94%A4III%E7%AB%9E%E6%8A%80%E5%9C%BA
作为社群生物,我们几十亿人类共同生活在同一个地球上,每个人都有自己独立的目标和行为,但仍然能够通过团队、组织和社会聚集在一起,展示出令人惊叹的集体智慧。这样的设置,我们称之为多智能体学习:每个智能体独立行动,同时要学会与其他智能体的互动以及合作。
参考系都是动态的,自由度非常高。想想我们人类之间团队配合的难度,就知道设计这样的多智能体有多难了!
多智能体克服难题的秘诀
具体到《雷神之锤3·夺旗》中,智能体面临的挑战是直接从原始像素中学习以产生动作。这种复杂性使得第一人称多人游戏成为AI社区内富有成效且活跃的研究领域。
夺旗原本是一项广受欢迎的户外运动,被广泛的应用于电子游戏中。在一张给定的地图中,红蓝双方保护自己的旗子并抢夺对方旗子,5分钟时间内,夺旗次数最多的队伍获胜。在游戏中,还可以标记敌方队员并将其送回出生点。
越是简单的规则,越能衍生出多种多样的玩法,在人类来说是增加了趣味性,在多智能体来讲就是增加了难度。为了继续刁难多智能体,游戏地图被设置成每局一换,以防止多智能体靠着优于人类的记忆来获得地利优势。
多智能体应对时局变化的诀窍,来自基于强化学习的三个概念:
训练一组多智能体而非只训练单一个体,使其能够在游戏中互相学习,提供多样化的队友和对手
每个智能体都学习自己的内部奖励信号,刺激智能体产生他们自己的内在目标比如抢到旗子。然后使用双层优化流程直接优化智能体的内部奖励以获胜,同时利用内部奖励的强化学习来了解智能体的政策。
智能体以快速和慢速两种速度运行,这提高了它们使用内存和生成一致动作序列的能力
由此产生的智能体,被称为For The Win(独孤求胜)智能体,学会了以非常高的水平来玩夺旗。至关重要的是,学到的智能体政策,对地图的大小、队友的数量以及团队中的其他玩家都很有用。
DeepMind组织了40个人,和多智能体一起随机组队。最终独孤求胜智能变得比强基线方法强大得多,超过了人类玩家的胜率。事后调查显示,智能体相比我们人类,更善于打配合!所以阻碍人类胜利的关键是人类不会好好打配合咯。
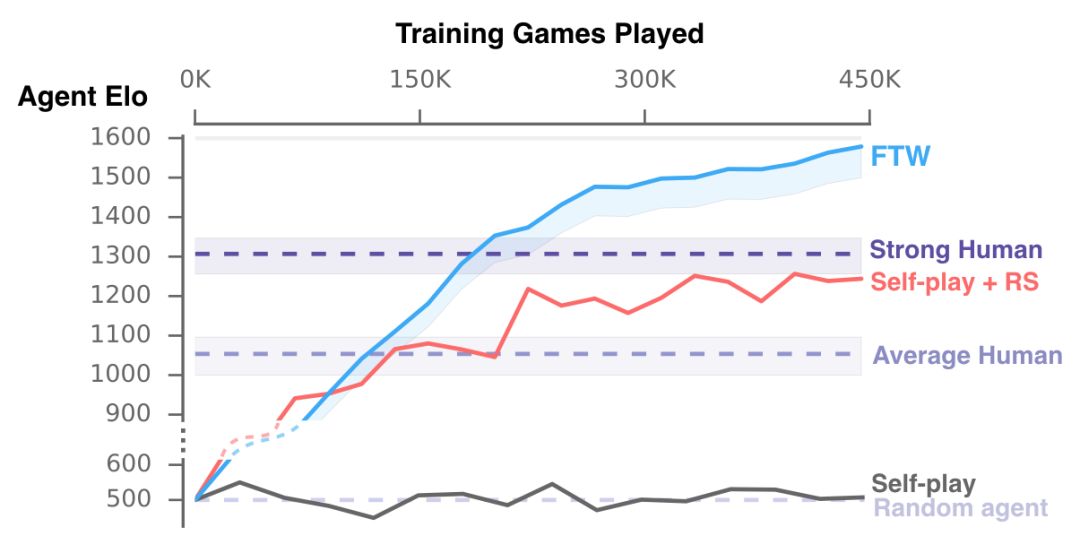
智能体在训练期间的游戏表现。我们训练的新智能体FTW游戏模式下的Elo得分比人类玩家和自游戏+ RS、自游戏的基线方法更高,该分数反映出游戏获胜的概率。
除了对游戏表现进行评估之外,了解这些智能体的行为和内部表示的复杂度也很重要。
为了理解智能体如何表示游戏状态,我们来看一下在平面上表示的智能体神经网络的激活模式。下图中的点集群表示在游戏期间与附近表示类似激活模式的点的游戏情况。这些点按照智能体发现自己的高级CTF游戏状态着色:在哪个房间?旗帜的状态是什么?可以看到哪些队友和对手?我们观察到相同颜色的聚类,表明智能体以类似的方式表示类似的高级游戏状态。
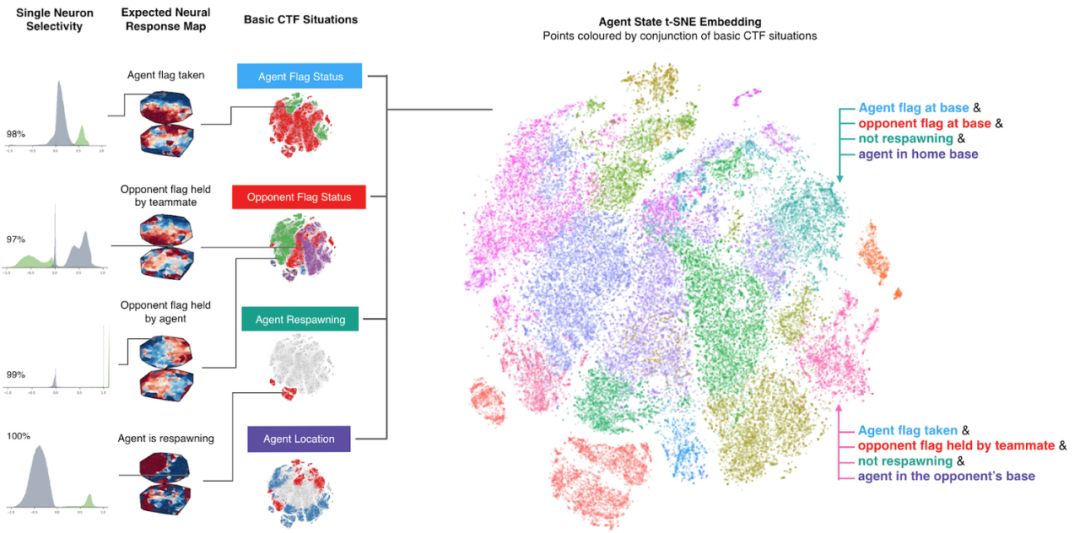
我们的智能体在游戏世界中的表示。在上图中,根据神经的相似程度绘制出给定时间的神经激活模式:图中两点在空间中距离越近,表明它们的激活模式越相似。然后根据实时比赛情况对它们进行上色:颜色相同,表示情况相同。这些神经激活模式是有组织的,形成了颜色簇,表明智能体以刻板、有组织的方式表示出有意义的游戏玩法。训练后的智能体甚至展示了一些人工神经元,用于直接针对游戏中的特定情形。
智能体从未被告知有关游戏规则的任何内容,但却了解基本的游戏概念,并对CTF产生了有效的直觉。事实上,我们可以找到直接为某些最重要的游戏状态编码的特定神经元,例如在智能体一方的旗子被夺时激活的神经元,或者当智能体的队友拿着旗帜时激活的神经元。本文对此提供了进一步的分析,包括了智能体对记忆和视觉注意力的应用。
超强智能体:强加反应延迟,游戏中仍然胜过人类
我们的智能体在游戏中表现如何?首先,它们的反应时间非常短。由于人类的生物信号传导速度较慢,人类处理和作用于感官输入的速度也就相对较慢。因此,我们的智能体在游戏中的卓越表现,可能是因为它们具备更快的视觉处理能力和运动控制的结果。
然而,在我们人为降低了智能体的瞄准精度和反应时间后,发现这其实只是其表现优秀的其中一个因素。在进一步的研究中,我们训练了内置延迟约四分之一秒(267毫秒)的智能体,也就是说,它们在观察世界之前存在267毫秒的延迟,这与人类游戏玩家的反应时间差不多。但这些自带反应延时的智能体仍然在游戏中的表现仍然优于人类玩家,后者的胜率只有21%。
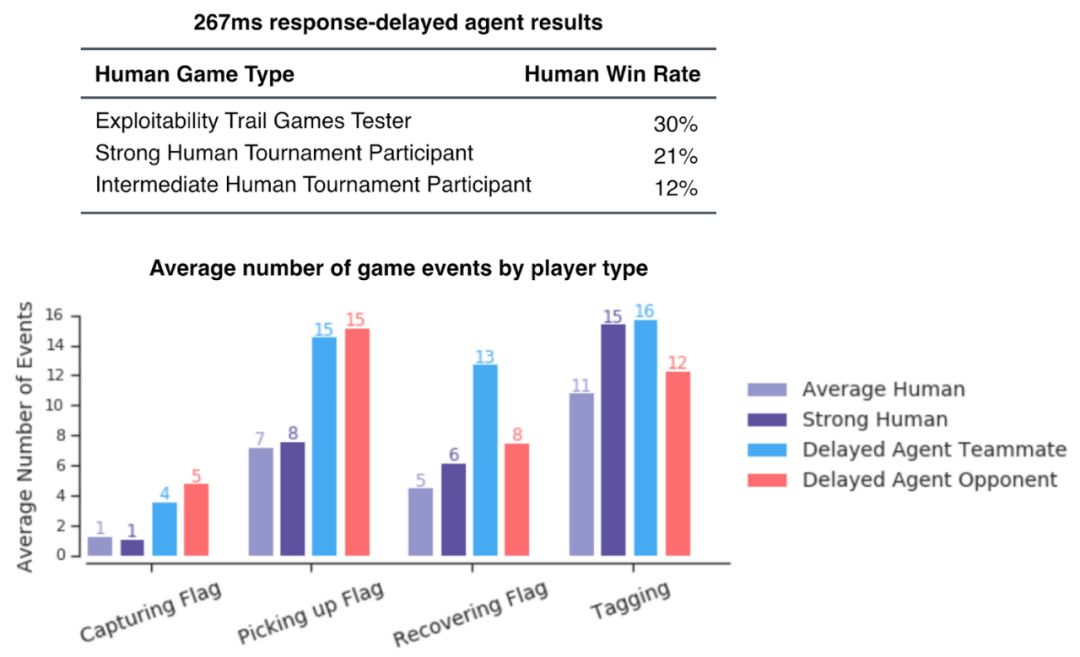
人类玩家面对响应延迟的智能体的胜率仍然很低,这表明,即使被加上了与人类相当的反应延时,智能体的游戏表现依然胜过人类玩家。此外,通过查看人类和相应延时的智能体的平均游戏事件数量,双方的标记事件数量差不多,表明这些智能体在这方面没有占据优势。
通过无监督学习,我们建立了代理人和人类的典型行为,发现智能体实际上学习了类似人类的行为,比如跟随队友并在对手的基地安营扎寨等。
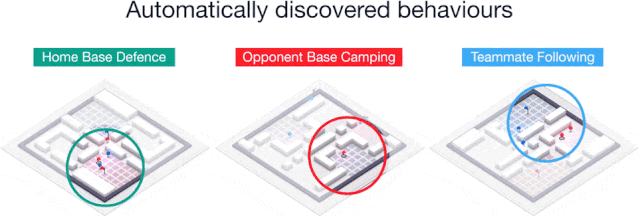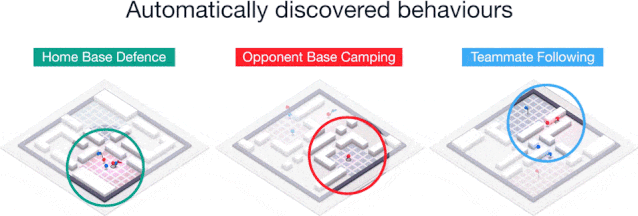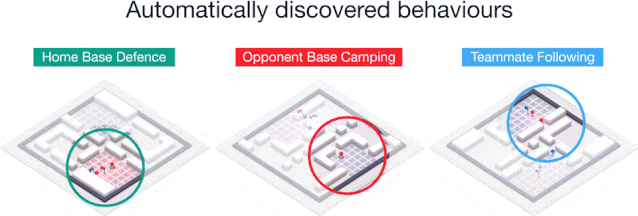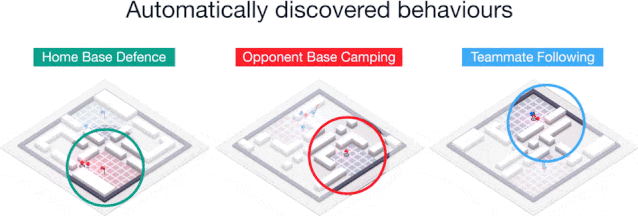
训练后的智能体做出的几种行为:防守己方基地、骚扰敌方基地、跟随队友。
这些行为在强化学习的训练过程中逐步出现,智能体能够逐渐学会以更加互补的方式进行合作。
一群独孤求胜智能体的训练进程。左上角:30个智能体的Elo评分,它们之间可以互相训练和进化。右上:进化事件树。下图显示了在整个智能体训练过程中知识进展、一些内部奖励机制和行为概率。
《星际争霸2》并不是极限,多智能体将继续前进
AI智能体在《雷神之锤》中的成功经验,被DeepMind应用在更复杂的即时战略游戏中。比如基于人口信息学的多智能体强化学习,构成了面向《星际争霸2》的AlphaStar智能体构建的基础。这款游戏被称为“人类最后的尊严”,但最终也没能挡住AIphaStar称霸的脚步。
而且,《星际争霸2》不会成为AI多智能体能力的极限,DeepMind还在不断给多智能体加大难度,利用多智能体训练中总结出的经验,用于开发高鲁棒性的、甚至可以与人类合作的强大智能体。
智能体在全尺寸地图上玩《雷神之锤3》其他多人游戏模式
-
深圳云栖大会人工智能专场:探索视频+AI,玩转智能视频应用2018-03-30 0
-
全球首家!讯飞AI电话能力平台开放合作!2018-09-10 0
-
新能力|AI为脑 · AR为眼,讯飞能力星云助你看见智能未来2018-09-14 0
-
微型微控制器与强大的人工智能(AI)世界有什么关系2021-11-01 0
-
用嵌入式AI技术提升智能硬件应用能力2022-10-09 0
-
AI 人工智能的未来在哪?2023-06-27 0
-
AI智能呼叫中心2023-09-20 0
-
AI时代到来 如何提高孩子创造未来的能力2019-05-09 2875
-
极视角发布首款软硬一体极光 帮助客户低成本拥有应用AI能力2022-05-25 2464
-
大模型不够用,还有“AI智能体”?2024-05-12 344
-
智能体逼近大爆发?李彦宏再谈AI应用2024-06-20 412
-
长虹发布沧海智能体AI TV与智汇家AI大模型2024-09-10 853
-
使用全新NVIDIA AI Blueprint开发视觉AI智能体2024-11-06 392
-
AI智能体生态圈和软件栈2024-12-03 124
-
AI智能体是什么_AI智能体如何重塑企业业务流程2024-12-19 245
全部0条评论

快来发表一下你的评论吧 !
