

Solr如何管理索引库
处理器/DSP
描述
索引创建和搜索过程
1.创建索引
举例子:
文档一:solr是基于Lucene开发的企业级搜索引擎技术
文档二:Solr是一个独立的企业级搜索应用服务器,Solr是一个高性能,基于Lucene的全文搜索服务器
首先经过分词器分词,solr会为分词后的结果(词典)创建索引,然后将索引和文档id列表对应起来,如下图所示:
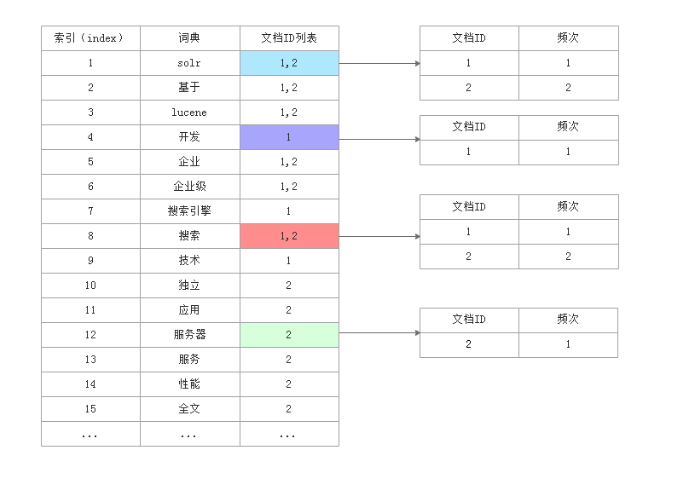
比如:solr在文档1和文档2中都有出现,所以对应的文档ID列表中既包含文档1的ID也包含文档2的ID,文档ID列表对应到具体的文档,并体现该词典在该文档中出现的频次,频次越多说明权重越大,权重越大搜索的结果就会排在前面。
solr内部会对分词的结果做如下处理:
1.去除停词和标点符号,例如英文的this,that等, 中文的“的”,“一”等没有特殊含义的词
2.会将所有的大写英文字母转换成小写,方便统一创建索引和搜索索引
3.将复数形式转为单数形式,比如students转为student,也是方便统一创建索引和搜索索引
2.索引搜索过程
知道了创建索引的过程,那么根据索引进行搜索就变得简单了。
1.用户输入搜索条件
2.对搜索条件进行分词处理
3.根据分词的结果查找索引
4.根据索引找到文档ID列表
5.根据文档ID列表找到具体的文档,根据出现的频次等计算权重,最后将文档列表按照权重排序返回
使用SolrJ管理索引库
使用SolrJ可以实现索引库的增删改查操作。
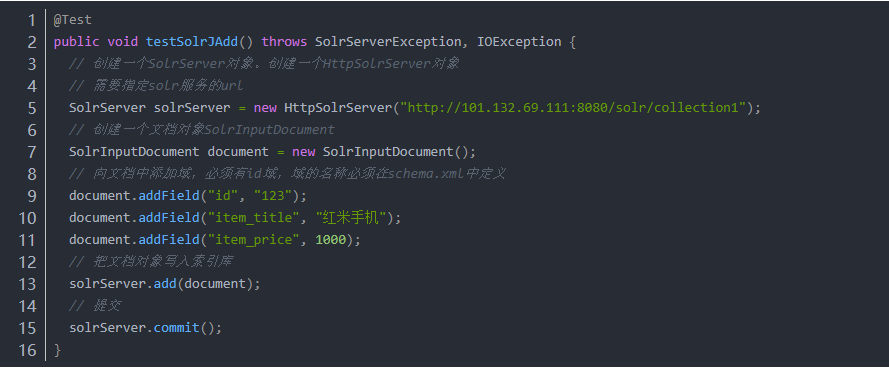
3.1 添加文档
第一步:把solrJ的jar包添加到工程中。
第二步:创建一个SolrServer,使用HttpSolrServer创建对象。
第三步:创建一个文档对象SolrInputDocument对象。
第四步:向文档中添加域。必须有id域,域的名称必须在schema.xml中定义。
第五步:把文档添加到索引库中。
第六步:提交。
3.2 删除文档
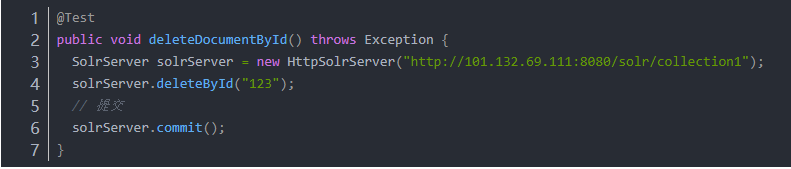
3.2.1 根据id删除
第一步:创建一个SolrServer对象。
第二步:调用SolrServer对象的根据id删除的方法。
第三步:提交。
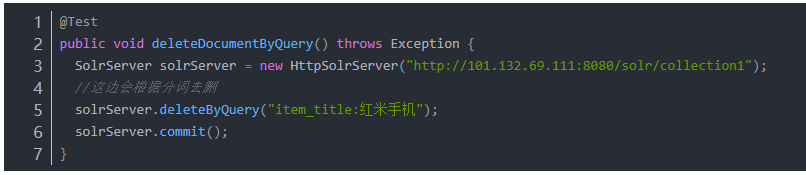
3.2.2 根据查询删除
3.3 查询索引库
第一步:创建一个SolrServer对象
第二步:创建一个SolrQuery对象。
3 向SolrQuery中添加查询条件、过滤条件。。。
第四步:执行查询。得到一个Response对象。
5 取查询结果。
第六步:遍历结果并打印。
3.3.1 简单查询
3.3.2 带高亮显示
@Test
public void searchDocumet() throws Exception {
// 创建一个SolrServer对象
SolrServer solrServer = new HttpSolrServer(“http://101.132.69.111:8080/solr/collection1”);
// 创建一个SolrQuery对象
SolrQuery query = new SolrQuery();
// 设置查询条件、过滤条件、分页条件、排序条件、高亮
// query.set(“q”, “*:*”);
query.setQuery(“手机”);
// 分页条件
query.setStart(0);
query.setRows(30);
// 设置默认搜索域
query.set(“df”, “item_keywords”);
// 设置高亮
query.setHighlight(true);
// 高亮显示的域
query.addHighlightField(“item_title”);
query.setHighlightSimplePre(“《div》”);
query.setHighlightSimplePost(“《/div》”);
// 执行查询,得到一个Response对象
QueryResponse response = solrServer.query(query);
// 取查询结果
SolrDocumentList solrDocumentList = response.getResults();
// 取查询结果总记录数
System.out.println(“查询结果总记录数:” + solrDocumentList.getNumFound());
for (SolrDocument solrDocument : solrDocumentList) {
System.out.println(solrDocument.get(“id”));
// 取高亮显示
Map《String, Map《String, List《String》》》 highlighting = response.getHighlighting();
List《String》 list = highlighting.get(solrDocument.get(“id”)).get(“item_title”);
String itemTitle = “”;
if (list != null && list.size() 》 0) {
itemTitle = list.get(0);
} else {
itemTitle = (String) solrDocument.get(“item_title”);
}
System.out.println(itemTitle);
System.out.println(solrDocument.get(“item_sell_point”));
System.out.println(solrDocument.get(“item_price”));
System.out.println(solrDocument.get(“item_image”));
System.out.println(solrDocument.get(“item_category_name”));
System.out.println(“=============================================”);
}
}
4. Solr服务器中的后台数据处理
这个其实是通过图形界面操作,只需手动填写查询条件,不需要进行代码处理。但是实际项目开发中,还是需要进行代码编写的。
6
4.1 solr的基础语法
q 查询的关键字,此参数最为重要,例如,q=id:1,默认为q=*:*,
fq (filter query)过虑查询,提供一个可选的筛选器查询。
返回在q查询符合结果中同时符合的fq条件的查询结果
sort 排序方式,例如id desc 表示按照 “id” 降序
start 返回结果的第几条记录开始,一般分页用,默认0开始
rows 指定返回结果最多有多少条记录,默认值为 10,配合start实现分页
fl 指定返回哪些字段,用逗号或空格分隔,注意:字段区分大小写,例如,fl= id,title,sort
df 默认的查询字段,一般默认指定
wt (writer type)指定输出格式,有 xml, json, php等
indent 返回的结果是否缩进,默认关闭
hl 高亮
hl.fl 设定高亮显示的字段
hl.requireFieldMatch 如果置为true,除非用hl.fl指定了该字段,查询结果才会被高亮。它的默认值是false。
hl.usePhraseHighlighter 如果一个查询中含有短语(引号框起来的)那么会保证一定要完全匹配短语的才会被高亮。
hl.highlightMultiTerm如果使用通配符和模糊搜索,那么会确保与通配符匹配的term会高亮。默认为false,同时hl.usePhraseHighlighter要为true。
hl.fragsize 返回的最大字符数。默认是100.如果为0,那么该字段不会被fragmented且整个字段的值会被返回。
-
时空数据库索引研究2009-09-17 456
-
化工搜索引擎索引库的研究和实现2009-12-18 688
-
数据库索引技术应用2011-11-04 456
-
AD元件库索引表详细资料免费下载2018-09-28 1125
-
如何在Oracle数据库中找出损坏索引?2018-10-18 3523
-
高性能搜索SOLR教程之SOLR的参数和使用学习手册免费下载2018-10-30 672
-
全文检索Solr集成HanLP中文分词2018-11-29 505
-
如何使用Solr和Lucene进行数字化古籍书库的研究与实现2019-01-23 739
-
solr管理后台操作维护索引库2019-06-03 1163
-
solr的索引库配置2019-06-03 894
-
数据库中的数据导入索引库2019-06-03 1075
-
Lucene和solr的区别2019-06-03 3600
-
数据库索引使用策略及优化2021-11-02 1715
-
面向关系数据库的智能索引调优方法2022-02-21 1319
-
索引是什么意思 优缺点有哪些2023-10-09 2927
全部0条评论

快来发表一下你的评论吧 !
