
资料下载


Peter Flach版机器学习教程对数据有意义的算法的艺术和科学免费下载
ah此生不换
分享资料个
作为一个最全面的机器学习文本周围,这本书公正的领域的难以置信的丰富,但没有失去统一的原则。
PeterFlach的清晰的、基于示例的方法首先讨论垃圾邮件过滤器的工作原理,它以最少的技术麻烦立即介绍了实际的机器学习。他涵盖了广泛的逻辑、几何和统计模型,以及最先进的主题,如矩阵分解和ROC分析。特别注意功能所扮演的中心角色。
机器学习将设定一个新的标准作为入门教材:
序言和第1章在线免费提供,提供了进入机器学习的第一步。
既有术语的使用与新的有用概念的引入是平衡的。
精心挑选的例子和插图构成了正文不可分割的一部分。
方框总结了相关的背景资料,并提供了修订的指针。
每章的结尾都有一个总结和进一步阅读的建议。
书后附有一份“要记住的重要要点”的清单,以及一份广泛的索引,帮助读者浏览材料。
这本书始于2008年夏天,当时我的雇主布里斯托尔大学授予我一年的研究奖学金。我决定开始写一篇关于机器学习的概论,有两个原因。一种是有空间写这样一本书,以补充现有的许多专业书籍;另一种是通过写作,我会学到新东西——毕竟,最好的学习方法是教书。
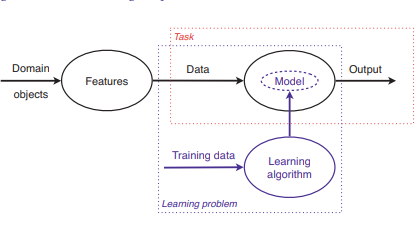
任何试图编写机器学习入门文本的人所面临的挑战是,在不忽视机器学习领域的统一原则的情况下,公正地对待机器学习领域的丰富性。过分强调学科的多样性,你就有可能最终得到一本没有太多连贯性的“食谱”;过分强调你最喜欢的范例,你可能会遗漏太多其他有趣的东西。在一定程度上,通过一个反复试验的过程,我得出了书中所体现的方法,即强调统一性和多样性:通过单独处理任务和特性来实现统一,这两种方法在任何机器学习方法中都很常见,但通常被认为是理所当然的;以及通过覆盖范围广泛的逻辑、几何和概率模型。
显然,我们不能指望在400页的篇幅内把所有的机器学习都覆盖到任何合理的深度。在结语部分,我列出了一些重要的研究领域,我决定不包括这些领域。在我看来,机器学习是统计和知识表示的结合,而这本书的主题就是为了强化这一观点。因此,在转向更具统计导向的材料之前,为树和规则学习预留了足够的空间。在整本书中,我特别强调直觉,希望通过大量使用示例和图形插图加以放大,其中许多都源自我在机器学习中使用ROC分析的工作。
你可能不知道,但很可能你已经是机器学习技术的常客了。目前大多数电子邮件客户机都采用了识别和过滤垃圾邮件(也称为垃圾邮件或未经请求的批量电子邮件)的算法。早期的垃圾邮件过滤器依赖于手工编码的模式匹配技术,如正则表达式,但很快就发现这很难维护,并且提供的灵活性不足——毕竟,一个人的垃圾邮件是另一个人的火腿!1使用机器学习技术可获得额外的适应性和灵活性S.spamasassin是一种广泛使用的开源垃圾邮件过滤器。它根据许多内置规则或SpamAssassin术语中的“测试”来计算传入电子邮件的分数,如果分数为5或更多,它会在电子邮件的标题中添加“垃圾邮件”标志和摘要报告。以下是我收到的电子邮件的示例报告:
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
- 相关下载
- 相关文章







