

端到端的自动驾驶研发系统介绍
电子说
描述
导读:近日,吴恩达的 Drive.ai 被苹果收购的消息给了自动驾驶领域一记警钟,但这个领域的进展和成果犹在。本文将介绍一些端到端的自动驾驶研发系统,让读者可以从系统层面对自动驾驶有更加深刻的认识。
虽然不赞成,但有必要列出来这种研究和demo工作。
英伟达驾驶员模拟器
Nvidia是比较早做端到端控制车辆工作的公司,其方法训练CNN模型完成从单个前向摄像头的图像像素到车辆控制的映射。 其系统自动学习一些处理步骤的内部表示,比如只用转向角作为训练信号去检测道路特征。
下图是其CNN模型训练的流程图,采用BP算法。而下下图是模型推理的框图,这时候只用一个中间的摄像头。


下图给出其数据收集系统的框架,包括3个摄像头(左,右,中)输入,输出控制方向盘。

PilotNet如图CNN模型架构细节,有2700万个连结,25万个参数。


驾驶仿真器

可以看出,这个模型不学习速度调整模型,如自适应巡航控制(ACC)那样。当年,该系统曾在旧金山的著名观景九曲花街做过演示,的确不需要控制速度,但是障碍物造成刹车也会造成人为接管。
Comma.ai 与 OpenPilot 驾驶模拟器
Comma.ai作为向特斯拉和Mobileye的视觉方法挑战的黑客,的确在端到端的自动驾驶开发是最早的探索者。
其思想就是克隆驾驶员的驾驶行为,并模拟今后道路的操作规划。采用的深度学习模型是基于GAN (generative adversarial networks)框架下的VAE(variational autoencoders)。利用一个行动(action)条件RNN模型通过15帧的视频数据来学习一个过渡模型(transition model)。下图给出了这个模拟器模型的架构,其中基于RNN的过渡模型和GAN结合在一起。

曾经在网上销售其系统:
该方法没有考虑感知模块的单独训练,安全性较差,比如缺乏障碍物检测,车道线检测,红绿灯检测等等。
从大规模视频中学习 E2E 驾驶模型
目的是学习一种通用的车辆运动模型,而这个端到端的训练架构学会从单目相机数据预测今后车辆运动的分布。如图应用一个FCN-LSTM 结构做到这种运动轨迹预测。


这种通用模型,输入像素,还有车辆的历史状态和当今状态,预测未来运动的似然函数,其定义为一组车辆动作或者运动粒度(离散和连续)。图将这种方法和其他两个做比较: “中介感知(Mediated Perception)“ 方法依赖于语义类别标签;“运动反射(Motion Reflex)” 方法完全基于像素直接学习表示; 而 FCN-LSTM ,称为“特权训练(Privileged Training)“ 方法,仍然从像素学习,但允许基于语义分割的附加训练。

基于逆向强化学习的人类自主驾驶开放框架
基于一个开放平台,包括了定位和地图的车道线检测模块,运动目标检测和跟踪模块(DATMO),可以读取车辆的里程计和发动机状态。采用逆增强学习(IRL)建立的行为学习规划模块(BEhavior Learning LibrarY,Belly) ,其中特征右横向偏移,绝对速度,相对车速限制的速度和障碍物的碰撞距离,输出规划的轨迹。图是其系统框图。

通过条件模仿学习进行端到端驾驶
模拟学习有缺陷,无法在测试时候控制,比如在交叉路口打U-turn。
提出条件模拟学习(Condition imitation learning),有以下特点:
训练时候,输入的不仅是感知和控制,还有专家的意图。
测试时候,直接输入命令,解决了感知电机(perceptuomotor)的多义性(ambiguity),同时可以直接被乘客或者拓扑规划器控制,就像驾驶员的一步一步操作。
无需规划,只需考虑驾驶的表达问题。
复杂环境下的视觉导航成为可能。
下面是实现条件模拟学习的两个NN架构:
第一个:命令输入。命令和图像等测试数据一起作为输入,可以用指向任务的向量取代命令构成任务条件的模拟学习。

第二个:分支。命令作为一个开关在专用的子模块之间的切换。

物理系统:

虚拟和实际环境:

自动驾驶的失败预测
驾驶模型在交通繁忙的地区、复杂的路口、糟糕的天气和照明条件下很可能失败。而这里就想给出一个方法能够学习如何预测这些失败出现,意识是估价某个场景对一个驾驶模型来说有多困难,这样可以提前让驾驶员当心。
这个方法是通过真实驾驶数据开发一个基于摄像头的驾驶模型,模型预测和真实操作之间的误差就称为错误度。 这样就定义了“场景可驾驶度(Scene Drivability),其量化的分数即安全和危险(Safe and Hazardous),图给出整个架构图。

图是失败预测模型训练和测试的流程图。预测失败其实是对驾驶模型的考
验,能及时发现不安全的因素。

结果如下

基于激光雷达的完全卷积神经网络
驱动路径生成
Note:past path (red),Lidar-IMU-INT’s future path prediction (blue).
这是一个机器学习方法,通过集成激光雷达点云,GPS-IMU数据和Google地图导航信息而产生驾驶通路。还有一个FCN模型一起学习从真实世界的驾驶序列得到感知和驾驶通路。产生与车辆控制相接近并可理解的输出,有助于填补低层的景物分解和端到端“行为反射”方法之间的间距。图给出其输入-输出的张量信号,如速度,角速度,意图,反射图等等。
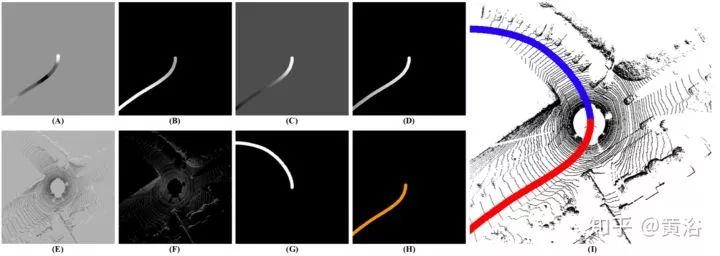

下面图每列中,顶图是过去/今后(红/蓝)通路预测,底图是驾驶意图近域(左)和驾驶意图方向(右)。A列是驾驶意图(右转)和直路无出口的分歧,B–D列是存在多个可能方向 。
Note:driving intention proximity (left),driving
intention direction (right).

上图是FCN模型参数。
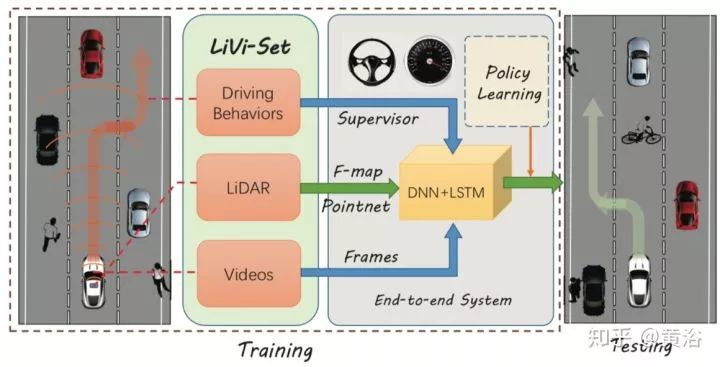
LiDAR视频驾驶数据集:有效学习驾驶政策
离散动作预测,预测所有可能动作的概率分布。但离散预测的局限是,只能在有限的定义好的动作进行预测。连续预测是把预测车辆的现行状态作为一个回归任务,如果准确预测在实际状态的驾驶策略,那么被训练的模型可以成功驾驶车辆。所以,把驾驶过程看成一个连续的预测任务,训练一个模型在输入多个感知信息(包括视频和点云)后能预测正确的方向盘转角和车辆速度。

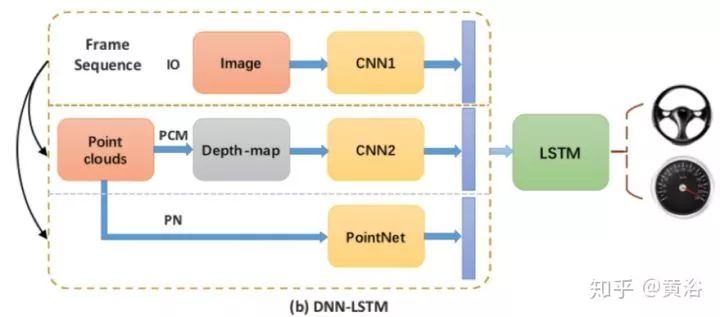
如图是其系统框图,其中深度学习模型是DNN加LSTM,激光雷达点云通过PointNet提取特征送入深度学习模型。
如图给出传感器数据在进入NN模型之前的预处理流水线框图,需要时间同步,空间对齐。

下面图是深度学习模型DNN和DNN+LSTM的架构图

使用环视摄像机和路线规划器进行驾驶模型的端到端学习
ETH的工作,采用一个环视视觉系统,一个路径规划器,还有一个CAN总线阅读器。 采集的驾驶数据包括分散的驾驶场景和天气/照明条件。集成环视视觉系统和路径规划器(以OpenStreetMap为地图格式的GPS坐标或者TomTom导航仪)的信息,学习基于CNN,LSTM和FCN的驾驶模型,如图所示。

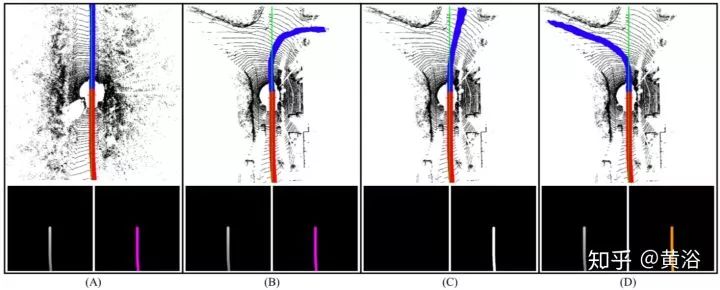
实验中,与采用单前向摄像头训练的模型还有人工操作比较(蓝/黄/红),如图所示:其中(1)-(3)对应三种不同的模型训练结果,即(1)只用TomTom路径规划器训练,(2)只用环视视觉系统训练, (3)用环视视觉和TomTom路径规划器一起训练。

深度学习的模型架构,包括路径规划器和环视系统5个输入通道,输出到方向
盘和加速踏板。

下面结果是左右拐弯时候的三种方法比较:人,前向摄像头和环视视觉加TomTom导航仪。

目前,该还没有加入目标检测和跟踪的模块(当然还有红绿灯识别,车道线检测之类的附加模块),但附加的这些模型能够改进整个系统的性能。
佐治亚理工学院端到端学习自动驾驶
还是模拟学习:采用DNN直接映射感知器数据到控制信号。下面系统框图:

下面是DNN 控制策略:

TRI自动驾驶端到端控制
端到端DNN训练,提出一种自监督学习方法去处理训练不足的场景。下图是自监督端到端控制的框架:NN编码器训练学习监督控制命令,还有量化图像内容的各种非监督输出。

提出新的VAE架构,如下图,做端到端控制: 编码器卷积层之后的图像特征,进入一个监督学习方向盘控制的潜在变量(latent variables )的可变空间。最后潜在向量进入解码器自监督学习重建原始图像。

特斯拉 SW 2.0
特斯拉的2.0软件思想,2018年8月提出。

自动雨刷:
-
自动驾驶真的会来吗?2016-07-21 0
-
细说关于自动驾驶那些事儿2017-05-15 0
-
如何让自动驾驶更加安全?2019-05-13 0
-
如何基于深度神经网络设计一个端到端的自动驾驶模型?2019-04-29 4891
-
基于端到端的自动驾驶系统只能做demo吗2020-12-26 504
-
浅谈自动驾驶的底层技术逻辑2022-11-29 1290
-
端到端自动驾驶到底是什么?2023-06-28 3626
-
佐思汽研发布《2024年端到端自动驾驶研究报告》2024-04-20 3168
-
智行者联合清华完成国内首套全栈式端到端自动驾驶系统的开放道路测试2024-04-22 776
-
理想汽车加速自动驾驶布局,成立“端到端”实体组织2024-07-17 1349
-
实现自动驾驶,唯有端到端?2024-08-12 724
-
Mobileye端到端自动驾驶解决方案的深度解析2024-10-17 355
-
Waymo利用谷歌Gemini大模型,研发端到端自动驾驶系统2024-10-31 1055
-
连接视觉语言大模型与端到端自动驾驶2024-11-07 231
-
端到端自动驾驶技术研究与分析2024-12-19 145
全部0条评论

快来发表一下你的评论吧 !
