

机器学习实时预测公交延迟!谷歌地图附加功能上线全球
电子说
描述
据统计,全世界有数亿人乘坐公交车进行日常通勤,世界上一半以上的交通都涉及公交,与地铁等出行方式不同,虽然公交运输公司有提供公交线路的发车时间表,但是公交车的运行时间会受限于实时的路况、路面上的交通指示灯等。这对于依靠公交车通勤的人来说,不确定的等待时间无疑会影响乘车的心情。
近日,谷歌地图的附加功能做到了!在之前应用的基础上引入了公交车的实时交通延误,预测了全球数百个城市的公交车延误情况,从亚特兰大到萨格勒布,从伊斯坦布尔到马尼拉等等, 这提高了六千多万人的通勤时间准确性。
在了解原理前,随文摘菌看下这款附加功能的演示吧!
印度首发!公交延迟实时了解
该系统于三周前首次在印度推出,由机器学习模型驱动,该模型将实时汽车交通预测与公交线路和站点数据相结合,以更好地预测公交车行程需要多长时间。以下的动图很好地演示了谷歌地图中的这项附加功能:
动图中展示了从当前位置到arsd(印度地名)的实时公交状况,与以往的搜索结果不同的是,在英国威廉希尔公司网站 中,添加了红色字体的延迟时间。
点开之后可以看到公交线路情况,红色的部分表示有延迟,蓝色部分表示正常通行,后续其他演示功能,详见下方链接:
https://india.googleblog.com/2019/06/stay-informed-about-local-bus-and-long.html
数据从哪来?没有公交实时数据也可以!
在没有来自公交机构实时预测数据的许多城市中,开发者借鉴了用户采用的一种巧妙的解决方法——使用谷歌地图的行车路线,考虑到公交运输的特殊性:加速,减速和转弯需要更长时间; 有时候甚至还有特殊的道路特权,比如公共汽车专用车道,所以此方法只适合粗略估计。另外研究者还结合了之前项目的数据库和来自用户提供的数据来扩充训练语料库,使得模型能够扩充到多个城市更加细粒度的公交线路。
如何建立模型?
为了构建开发模型,在参照公交机构发布的信息基础上,开发人员结合了一段时间内从公交车位置序列中提取的数据,同时也有考虑到公交线路上其他车辆的行进速度。
整个模型分为一系列时间轴单元 - 途经的街道路线和停靠站 - 每个单元对应一条公交车的时间线,独立地预测一段延迟,最后的输出是每个单元预测的逻辑求和。其次考虑到一些特殊情况,如:站点之间不频繁的通信、公交车车速较快、较短的街道路线和停靠点等,所以相邻站点之间的预测通常要跨越多个时间单元,以便综合考虑到各方面的因素,下面的图片很好地诠释了建立模型的过程:
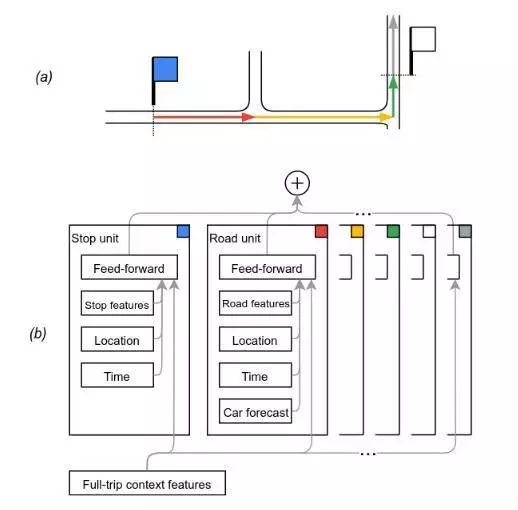
(a)图中蓝色的图标表示站点,公交车在此开始启动,在(b)图中将蓝色的站点抽象成Stop unit的时间单元,包括发车时间表Time、位置信息Location、站点周围的状况Stop features以及向前行进Feed-forward等一系列特征;
(a)图中的红色、黄色和绿色的线路表示公交车的行进路线,同理每个路线抽象建模成Road Unit,除了一些共有的Time、Lacation、Feed-forward特征外,还加入了路况信息Road features、以及路线上的其他车辆的速度预测Car forecast等信息。
模型包含了上下文场景的预测信息,最终的结果是这些时间单元的逻辑求和。这种时间序列的建模结构非常适合neural sequence model(神经网络中的序列模型),最近成功应用于语音处理、机器翻译等。一般情况下使用标签数据(X,Y)(输入数据为X,输出数据为Y)的监督学习任务都需要使用序列模型,如在NLP领域内大放光彩的RNN模型,也是序列模型的应用。
考虑到汽车速度的影响
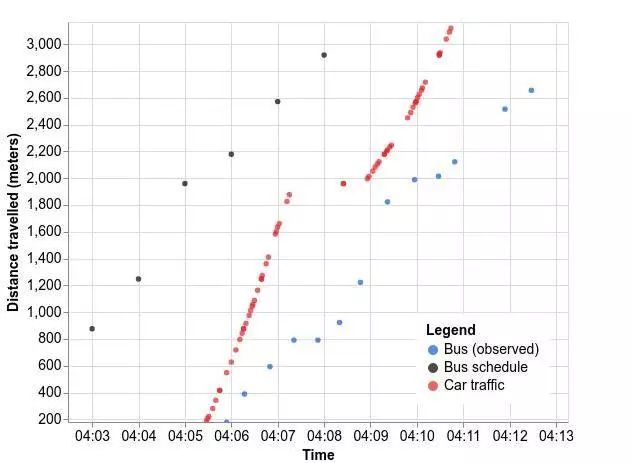
举例说明Car forecast对Road unit时间单元的影响,我们以周三下午乘坐Sydney(悉尼)的巴士为例。 公交车的实际运行状况(蓝色的线路)比公交运输机构公布的时间表(黑色的线路)滞后几分钟,从下图可以看到, 红色的线路也就是汽车的运动状态确确实实地影响了公交车的前行。
例如,明显看到图中红色标记在2000米处的断层和斜率的变化,这预示着汽车2000米处的减速,这一减速也同样体现在了蓝色的公交线路上,同样地,800米处的暂停,公交的停滞时间要比汽车长很多。
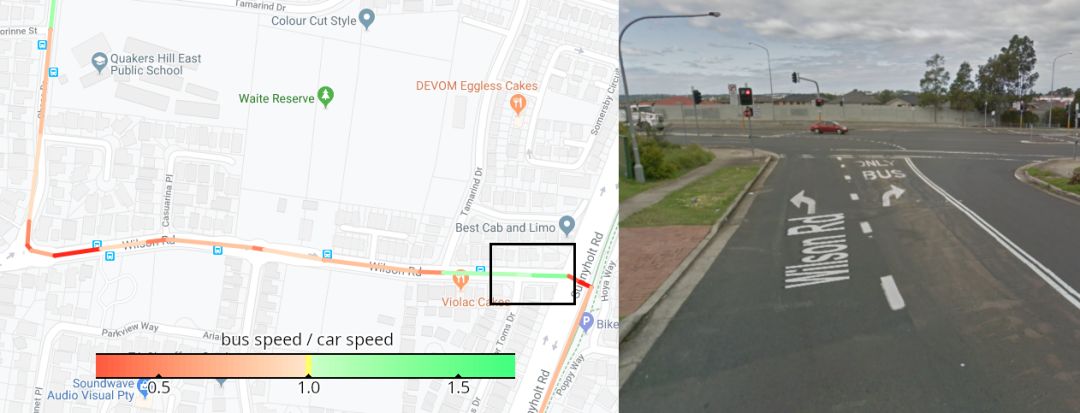
上文已经举例说明了汽车车速对公交车行进途中造成的影响,那么,如何将Car Speed(汽车速度)转换为公交速度呢?
在下图的左侧部分,模型对公交车行驶速度和汽车速度之间的预测比率进行了颜色编码。 较慢的红色部分,对应于停靠点附近的公共汽车减速。 至于速度较快的绿色部分,我们从右图StreetView中看到了一个只有公交车的转弯车道。(附:这条路线在澳大利亚,右转弯比左转慢,其他模型可能会欠缺这些细节方面的考量)
捕捉不同地区线路的差异
不同城市、社区和街道都有其独特性,那么模型如何捕捉这些差异呢?
为了使模型捕捉到更加细节的信息,开发者让模型学习不同大小区域的表示层次结构,以及每个时间轴单元的地理位置(道路或站点的精确位置),这些位置的表达,通过在时间轴单元中嵌入不同大小区域的位置表示,最终逻辑求和得到。
刚开始模型的训练,对特殊情况下的细粒度位置进行强化学习(对模型预测结果进行反馈评估),调整模型参数,使得模型能够更好地学习特征,并使用结果进行特征选择。 这样就可以确保考虑到百米内的更加全面的道路信息。
位置和时间相结合:适应不同城市的“节奏”
除了考虑到不同位置线路的独特性外,每个城市都有其不同的节奏,对于节奏较慢的小镇,下午6:30到下午6:45可能是偏安静的黄昏与日落,对于其他的城市可能是下班高峰期或用餐时间,因此需要在模型中嵌入时间表示。
在模型中嵌入当地时间和星期几这些时间表示,同时结合地理位置,可以捕捉到各城市高峰时段的公交线路,这是之前模型的又一个扩充。
这种扩充使得数据变成四维(星期几,几时,城市名称,站点),四维的数据很难可视化,为了更直观地解释,利用下图艺术家Will Cassella设计的图片,来讲解四维中的其中三维数据:
昼夜更替,这种循环往复,使得模型的时间表示为一个类似钟表的“Loop”结构,但是细心地读者可能会发现这种钟表的盘面形成了很多的“褶皱”,这也是时间模型设计的精髓。这种“褶皱”结构可以在神经网络训练过程中,让神经元区分“半夜”“深夜”这样的概念。除此外,钟表盘面上16到21的刻度上有很大的“弯曲”,而2到5的刻度则表现的很“平坦”,这也体现着不同时段公交的拥堵情况,16到21的刻度代表着下午4点到晚上9点,而2到5的刻度则表示半夜或者是下午的时间。
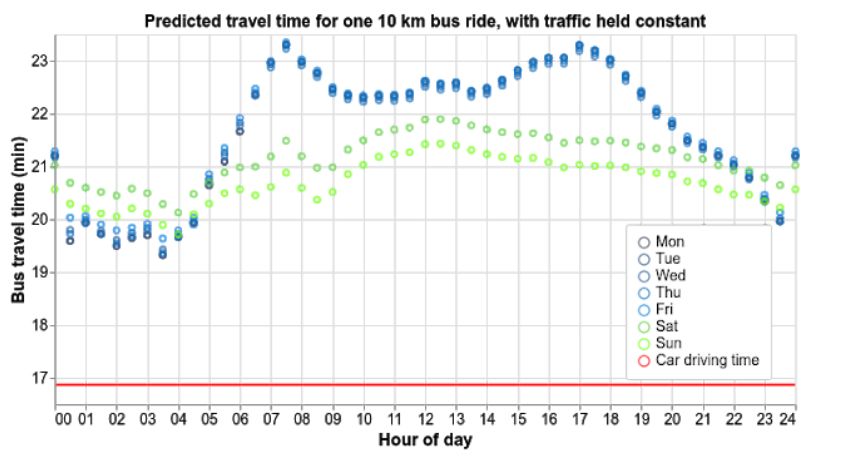
这种时间结构的设计,使得汽车速度是常量时,设计的模型也能感知到公交车的高峰拥堵情况,以New Jersey乘坐10km的公交巴士为例,模型呈现的效果如下图,从图中可以看到周一到周日每天特定时刻的公交运行时长,耗时较多的时刻集中在一天的7点到8点,也就是早高峰,同时17点到18点的Bus travel time也稍有上浮。
模型效果:让数据“开口”证明
在训练好模型后, 模型对Sydney(悉尼)的公交拥堵情况进行了实时的预测:
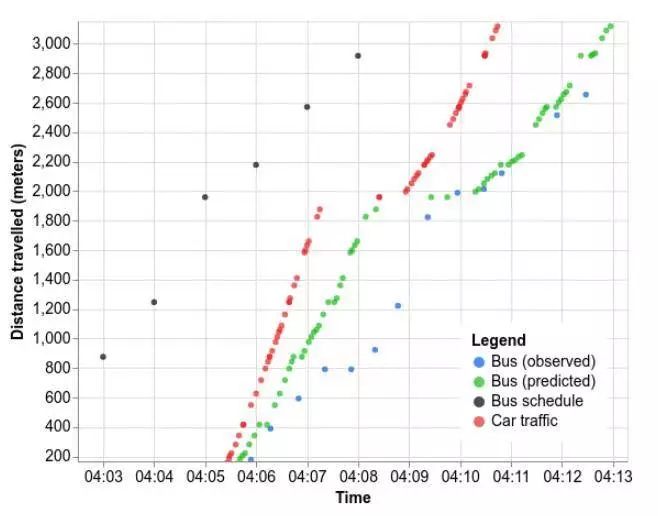
图中蓝色的线路是真实的公交行进状况,绿色的线路是预测后的公交运动路线,可以看到真实情况下,公交在800米处有大约半分钟(30s)左右的停车,预测模型有感知到差不多10s的停车,这有些许的误差,统计完后,整个模型的预测结果与真实的效果只差1.5分钟,这已经非常贴近真实值了。
预测不同城市的高峰时段
除了对Sydney(悉尼)的预测外,模型也对全世界各大城市的交通拥堵状况做了统计。
下图是对Chicago最拥堵的公交线路和经停站的统计:

-
No Output是什么意思? Generation与Compare在功能上有什么区别?2024-04-07 0
-
iOS版谷歌地图正式上架 定位准可语音导航2012-12-15 0
-
哪里可找到智能门锁功能上开发的公司2014-09-01 0
-
谷歌地图新添“驾驶模式”智能判断目的地2016-01-14 0
-
谷歌地图、百度地图,离线+在线2018-07-19 0
-
地铁公交可用手机刷,Samsung Pay公交卡功能上线了!2016-12-20 3892
-
RS232与RS485在功能上的区别2017-11-15 1421
-
谷歌官方机器学习速成课程上线2018-03-24 1127
-
使用机器学习预测公交车延误2019-07-12 3349
-
小爱同学可以实时查公交了,与高德地图合作开发2019-12-26 6837
-
谷歌地图将在美国推广近乎实时的火灾边界地图功能2020-08-21 800
-
汽车 LED 前灯在形式和功能上的演变2021-03-20 388
-
问界M5智驾功能上新 城区NCA智驾功能7月上线5城2023-06-29 1057
-
谷歌使用机器学习模型来预测哪条路线最省油或最节能2023-07-25 662
-
OpenAI一键调用GPTs功能上线2024-02-04 824
全部0条评论

快来发表一下你的评论吧 !
