

谷歌公布亚毫秒级的人脸检测算法BlazeFace
电子说
描述
谷歌近日公布亚毫秒级的人脸检测算法BlazeFace,这是一款专为移动GPU推理量身定制的轻量级人脸检测器,能够以200~1000+ FPS的速度运行,且性能非常卓越!
近年来,深度神经网络的各种架构改进使得实时目标检测成为可能。实验室可以不计一切地开发各种算法追求逼近极限的精度,而实际应用中,响应速度、能耗和精度都重要。这就要求算法的复杂度要低、适合硬件加速。
在移动应用中,实时目标检测往往只是视频处理流程的第一步,接下来是各种特定的任务,如分割、跟踪或几何推理。
因此,运行对象检测模型推理的算法要尽可能快,最好还具有比标准实时基准更高的性能。
谷歌刚刚上传到arXiv的一篇论文BlazeFace: Sub-millisecond Neural Face Detection on Mobile GPUs,推出了BlazeFace算法,这是一款专为移动GPU推理量身定制的轻量级人脸检测器,且性能非常卓越!
有多卓越呢?谷歌在其旗舰设备测试,结果发现BlazeFace能够以200~1000+ FPS的速度运行。
这种超实时性能使其能够应用于任何需要准确的面部区域,作为特定模型输入的增强现实应用中,例如2D/3D面部关键点或几何估计、面部特征或表情分类、以及面部区域分割等。
谷歌已经把该算法应用在工业中。
两大算法创新,一切为了又快又好
BlazeFace包括一个轻量级的特征提取网络,其灵感来自于MobileNetV1/V2,但又有所不同。还采取了一种修改过的SSD目标检测算法,使其对GPU更加友好。然后用改进的联合分辨率(tie resolution)策略来替代非极大抑制(Non-maximum suppression)。
BlazeFace可用于检测智能手机前置摄像头捕捉到的图像中的一个或多个人脸。返回的是一个边界框和每个人脸的6个关键点(从观察者的角度看左眼、右眼、鼻尖、嘴、左眼角下方和右眼角下方)。
算法创新包括:
1、与推理速度相关的创新:
提出一种在结构上与MobileNetV1/V2相关的非常紧凑的特征提取器卷积神经网络,专为轻量级对象检测而设计。
提出了一种基于SSD的GPU-friendly anchor机制,旨在提高GPU的利用率。Anchors是预定义的静态边界框,作为网络预测调整的基础,并确定预测粒度。
2、与预测性能相关的创新:
提出一种替代非极大抑制的联合分辨率策略,在重叠预测之间实现更稳定、更平滑的tie resolution。

BlazeBlock (左) 和 double BlazeBlock
BlazeFace的模型架构如上图所示,在设计方面考虑了以下4个因素:
扩大感受野(receptive field)的大小:
虽然大多数现代卷积神经网络架构(包括MobileNet)都倾向于在模型图中使用3×3的卷积核,但我们注意到深度可分离卷积计算主要由它们的点态部分控制。
本研究发现,增加深度部分的内核大小成本并不会增加很多。因此,我们在模型架构中使用了5×5的卷积核,用kernel size的增加来交换达到特定receptive field大小所需的bottlenecks总数的减少。
深度卷积的低开销还允许我们在这两个点卷积之间引入另一个这样的层,从而进一步加速达到所需receptive field。这形成了一个double BlazeBlock,如上图右边所示。
特征提取器(Feature extractor):
在实验中,我们将重点放在前置相机模型的特征提取器上。它必须考虑更小的对象范围,因此具有更低的计算需求。提取器采用128×128像素的RGB输入,包含一个2D卷积,以及5个BlazeBlock和6个 double BlazeBlock,如下表所示:

改进的Anchor 机制:
类似于SSD的对象检测模型依赖于预定义的固定大小的基本边界框,称为priors,或者Faster-R-CNN中提出的术语“Anchor”。
我们将 8×8,4×4 和 2×2 分辨率中的每个像素的 2 个 anchor 替换为 8×8 的 6 个 anchor。由于人脸长宽比的变化有限,因此将 anchor 固定为 1:1 纵横比足以进行精确的面部检测。
pipeline示例。红色:BlazeFace的输出。绿色:特定于任务的模型输出。
后处理机制(Post-processing):
由于我们的feature extractor并没有将分辨率降低到8×8以下,所以与给定对象重叠的anchor的数量会随着对象的大小而显著增加。在典型的非极大抑制场景中,只有一个anchor“胜出”,并被用作最终的算法结果。当这样的模型应用于随后的视频帧时,预测往往会在不同的anchor点之间波动,并表现出明显的人脸框抖动。
为了最小化这个问题,我们用一种混合策略代替了抑制算法,该策略将一个边界框的回归参数估计为重叠预测之间的加权平均值。它实际上不会给原始的NMS算法带来额外的成本。对于我们的人脸检测任务,这个调整使准确率提高了10%。
专为GPU设计,准确度超越MobileNetV2
超实时性能。解锁需要面部区域作为输入的“任务特定”模型的实时AR pipeline:
准确的3D面部几何
通过Blendshapes进行Puppeteering
面部分割
AR化妆试穿/美化
头发/嘴唇/虹膜重新着色
磨皮
专为移动GPU设计
专为移动GPU和CPU设计
轻量级特征提取网络
更适合GPU的anchor方案
改进了tie resolution策略

GPU上的快速推理
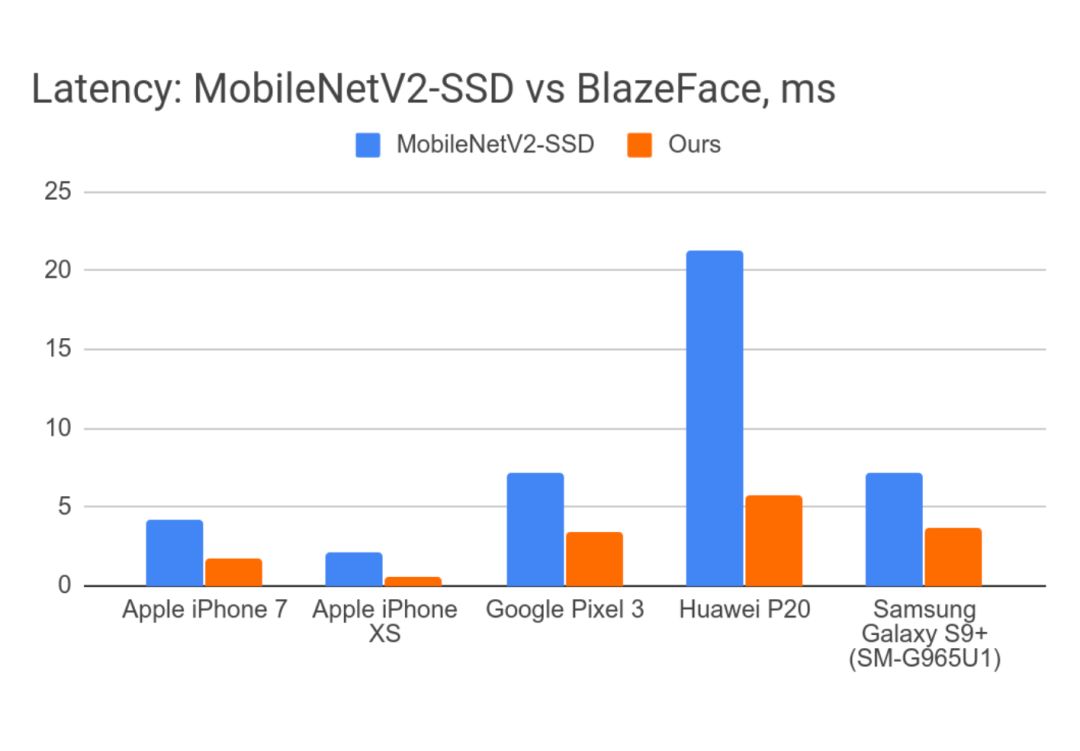
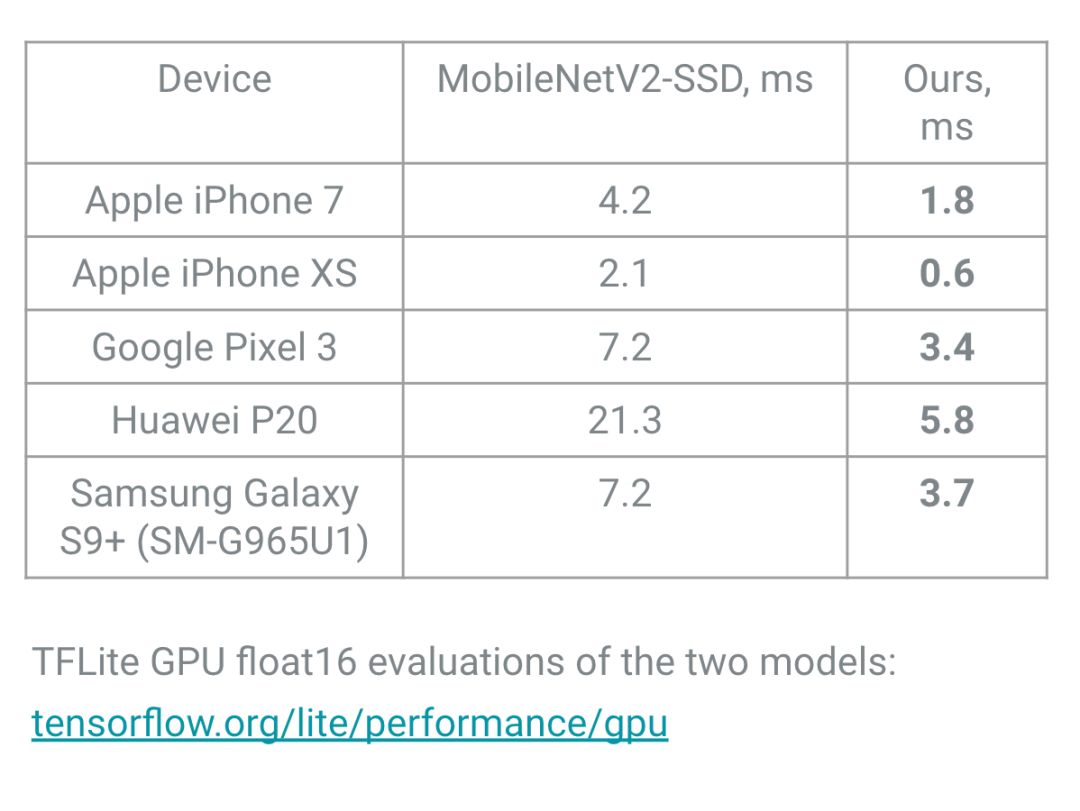
精度
眼间距离的平均绝对误差为10%左右就足够精确了
后续模型的面对齐
生成6个面部关键点坐标
在低端设备上仅使用此模型,实现耳朵等简单特效

-
人脸检测算法及新的快速算法2013-09-26 0
-
基于openCV的人脸检测系统的设计2014-12-23 0
-
ARM嵌入式环境中FDDB第一的人脸检测算法的运行2019-07-29 0
-
基于ToF的3D活体检测算法研究2021-01-06 0
-
分享一款高速人脸检测算法2021-12-15 0
-
RK3399Pro是怎样去移植Tencent的mtcnn人脸检测算法的2022-02-15 0
-
基于层叠支持向量机的人脸检测研究2009-06-04 483
-
基于肤色的实时人脸检测算法研究2011-05-05 639
-
基于openCV的人脸检测识别系统的设计2012-06-15 4159
-
基于几何特征与新Haar特征的人脸检测算法_糜元根2017-03-19 887
-
一种复杂环境下鲁棒的精确人脸检测算法(结合VIOLA-JONES和CLM模型)2017-10-30 1266
-
支持向量机的人脸快速检测2018-01-23 848
-
人脸图像质量检测算法的原理及在小区人脸识别闸机中的应用2020-10-09 1300
-
基于tensorflow的BlazeFace-lite人脸检测器2022-02-07 457
-
BlazeFace: 亚毫秒级的人脸检测器(含代码)2022-02-07 405
全部0条评论

快来发表一下你的评论吧 !
