更简单、通用的方案:乒乓机制的交错队列
我们相信我们可以更简单、更有效的方式来完成计算。为此,我们需要从全局上考虑我们的最终目标:我们需要在没有Vulkan 规范介入的前提下,使 GPU 能够在连续两个帧中交替工作。
Vulkan 规范团队中的精明者可能已经意识到,barrier是始终指向单个队列的构造器。
PowerVR(和许多其它设备)设备可能会暴露多个相同/可互换的通用队列(图形+计算以及可能的呈现)。
因此,在这种情况下,为在不重新调整帧前提下避免跨帧同步,我们可以在不同队列中为每个帧提交负载。这将允许一个帧中的任何负载与下一帧中的任何负载交错执行,即使具有多个不同的图形、顶点和计算任务,因为它们在不同队列上显式执行,可以不受制于彼此的barrier。
简单来说:从同一队列源中创建两个相同的队列,然后对于每个帧,您提交负载到与上一队列不同的队列上。队列源很重要,因为它可以使您不必担心资源队列所有权等问题。
因此,帧提交过程如下:
帧 0:获取下一个图像→ 渲染 0(A0)→ 图形/计算barrier→ 计算0(B0)→计算/图形barrier→渲染0′(C0)→提交到队列0 →呈现到队列 0
帧 1:获取下一个图像→ 渲染 1A1→ 图形/计算barrier→ 计算1B1→计算/图形barrier→渲染1′C1→提交到队列1→呈现到队列1
帧 2:获取下一个图像→ 渲染2 A2→ 图形/计算barrier→ 计算2B2→计算/图形barrier→渲染2′C2→提交到队列0 →呈现到队列 0
帧 3:获取下一个图像→ 渲染 3A3→ 图形/计算barrier→ 计算3B3→计算/图形barrier→渲染3′C3→提交到队列1→呈现到队列1
。..等等。
那么,这行得通吗?而且,如果可以,其原因是什么?
确实可行。BN(当前帧计算)和 CN(当前帧的后期图形)之间的barrier将阻止 CN在BN完成之前启动,但不会阻止 AN+1(下一帧的早期图形)启动,因为它在与Barrier不同的队列上提交(一个额外的好处,由于队列不同,AN+1与CN不需要强制排序)。
此技术解决了问题的核心:应用程序设置的barrier,旨在在单个帧中等待风险的发生,不会导致后续帧之间的任务间等待。我发现它相当令人欣喜,而且是迄今为止最简单的可实现方案——只要您的通用队列源中有多个队列,就可以使用单个计数器(甚至是布尔类型)并交换每一帧,此时无需进一步修改:只要我们确保 CPU 资源得到正确管理(与单个队列相同),不须施加额外同步。
简而言之,由于每个连续帧都在不同的队列中提交,因此 GPU 可以自由地在帧之间并行调度任务,预期结果为 (CN+1) 在(AN) 完成之后开始执行。它可确保渲染器及其相应的调度程序始终繁忙,并且中间的计算不会串行化帧。
—————–
计算工作负载:B0B1 B2B3 B4B5
图形工作负载:A0 A1 C0 C1 A2 A3 C2 C3 A4 A5 C4 C5 。..
或(基本相同的效果)如下:
计算工作负载:B0 B1 B2 B3 B4 B5
图形工作负载:A0 A1 C0 A2 C1 A3 C2 A4 C3 A5 C4 C5 。..
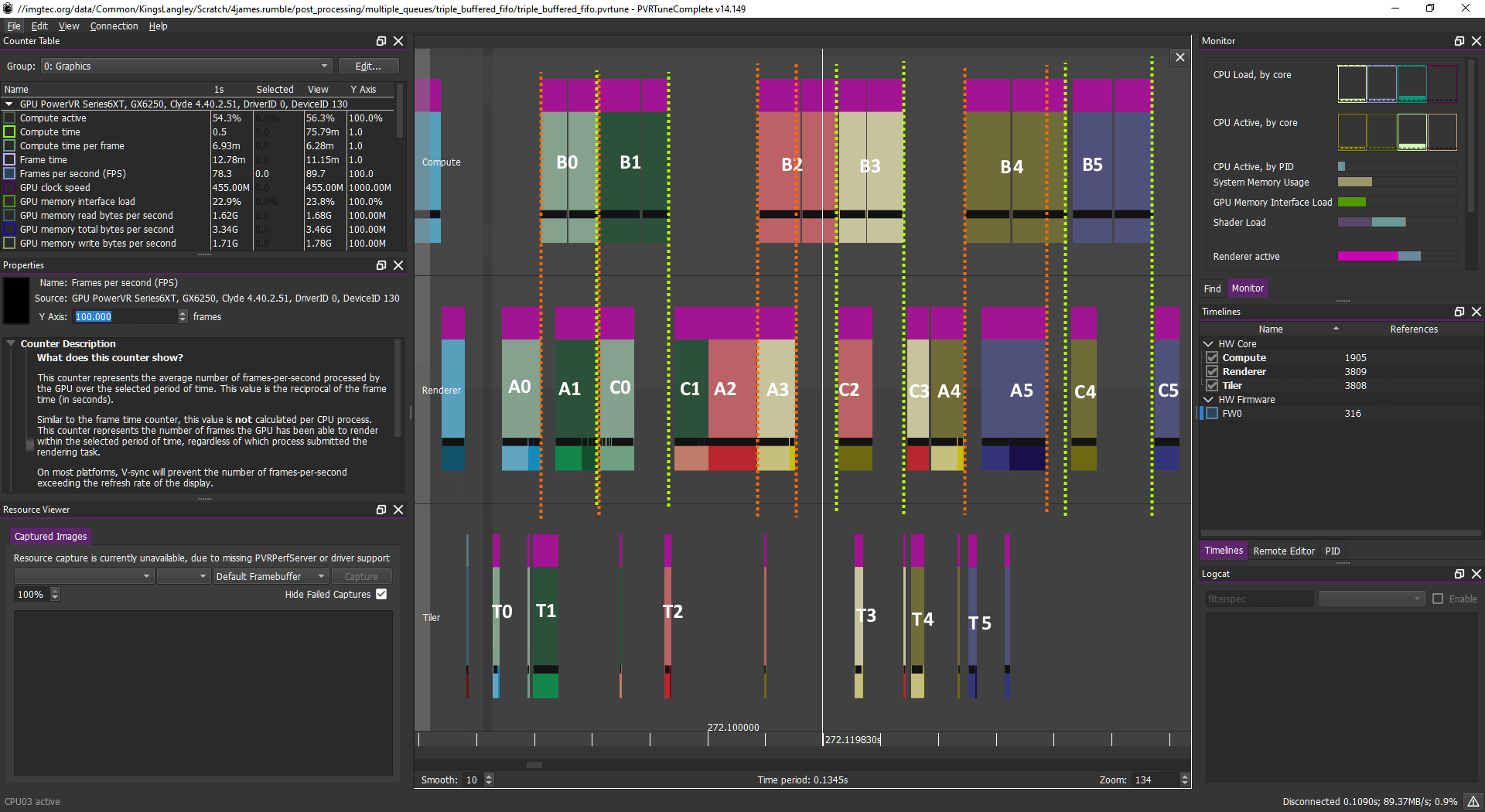
解决方案:通过使用多个队列,可以在上一帧的早期任务之后安排下一帧的早期片段任务,与计算任务重叠以获得出色的效率增益
乍一看,这看起来可能很复杂,但实际很简单。无论如何,该图示告诉我们,GPU 正在处理一个帧(N)的计算,同时处理下一帧 (N+1) 的早期图形或上一帧的后期图形。
完全封装的情况是“相当不可能”,它甚至没有必要达到这种水平的封装。但是,您应具备类似的特征,计算与顶点/片段任务一起调度,允许USC 加载使用尽可能多的容量。
更简单、通用的方案:乒乓机制的交错队列
我们相信我们可以更简单、更有效的方式来完成计算。为此,我们需要从全局上考虑我们的最终目标:我们需要在没有Vulkan 规范介入的前提下,使 GPU 能够在连续两个帧中交替工作。
Vulkan 规范团队中的精明者可能已经意识到,barrier是始终指向单个队列的构造器。
PowerVR(和许多其它设备)设备可能会暴露多个相同/可互换的通用队列(图形+计算以及可能的呈现)。
因此,在这种情况下,为在不重新调整帧前提下避免跨帧同步,我们可以在不同队列中为每个帧提交负载。这将允许一个帧中的任何负载与下一帧中的任何负载交错执行,即使具有多个不同的图形、顶点和计算任务,因为它们在不同队列上显式执行,可以不受制于彼此的barrier。
简单来说:从同一队列源中创建两个相同的队列,然后对于每个帧,您提交负载到与上一队列不同的队列上。队列源很重要,因为它可以使您不必担心资源队列所有权等问题。
因此,帧提交过程如下:
帧 0:获取下一个图像→ 渲染 0(A0)→ 图形/计算barrier→ 计算0(B0)→计算/图形barrier→渲染0′(C0)→提交到队列0 →呈现到队列 0
帧 1:获取下一个图像→ 渲染 1A1→ 图形/计算barrier→ 计算1B1→计算/图形barrier→渲染1′C1→提交到队列1→呈现到队列1
帧 2:获取下一个图像→ 渲染2 A2→ 图形/计算barrier→ 计算2B2→计算/图形barrier→渲染2′C2→提交到队列0 →呈现到队列 0
帧 3:获取下一个图像→ 渲染 3A3→ 图形/计算barrier→ 计算3B3→计算/图形barrier→渲染3′C3→提交到队列1→呈现到队列1
。..等等。
那么,这行得通吗?而且,如果可以,其原因是什么?
确实可行。BN(当前帧计算)和 CN(当前帧的后期图形)之间的barrier将阻止 CN在BN完成之前启动,但不会阻止 AN+1(下一帧的早期图形)启动,因为它在与Barrier不同的队列上提交(一个额外的好处,由于队列不同,AN+1与CN不需要强制排序)。
此技术解决了问题的核心:应用程序设置的barrier,旨在在单个帧中等待风险的发生,不会导致后续帧之间的任务间等待。我发现它相当令人欣喜,而且是迄今为止最简单的可实现方案——只要您的通用队列源中有多个队列,就可以使用单个计数器(甚至是布尔类型)并交换每一帧,此时无需进一步修改:只要我们确保 CPU 资源得到正确管理(与单个队列相同),不须施加额外同步。
简而言之,由于每个连续帧都在不同的队列中提交,因此 GPU 可以自由地在帧之间并行调度任务,预期结果为 (CN+1) 在(AN) 完成之后开始执行。它可确保渲染器及其相应的调度程序始终繁忙,并且中间的计算不会串行化帧。
—————–
计算工作负载:B0B1 B2B3 B4B5
图形工作负载:A0 A1 C0 C1 A2 A3 C2 C3 A4 A5 C4 C5 。..
或(基本相同的效果)如下:
计算工作负载:B0 B1 B2 B3 B4 B5
图形工作负载:A0 A1 C0 A2 C1 A3 C2 A4 C3 A5 C4 C5 。..
解决方案:通过使用多个队列,可以在上一帧的早期任务之后安排下一帧的早期片段任务,与计算任务重叠以获得出色的效率增益
乍一看,这看起来可能很复杂,但实际很简单。无论如何,该图示告诉我们,GPU 正在处理一个帧(N)的计算,同时处理下一帧 (N+1) 的早期图形或上一帧的后期图形。
完全封装的情况是“相当不可能”,它甚至没有必要达到这种水平的封装。但是,您应具备类似的特征,计算与顶点/片段任务一起调度,允许USC 加载使用尽可能多的容量。

 举报
举报


 举报
举报



