打鼾是一种普遍的症状,严重影响睡眠呼吸障碍患者(单纯打鼾者)、阻塞性睡眠呼吸暂停(OSA)患者及其床伴的生活质量。研究表明,打鼾可用于OSA的筛查和诊断。因此,从夜间睡眠呼吸音频中准确检测打鼾声一直是最重要的部分之一。考虑到打鼾在世界各地被忽视的危险性,需要一种自动且高精度的打鼾检测算法。在这项工作中,我们设计了一种非接触式数据采集设备来记录受试者在私人卧室中的夜间睡眠呼吸音频,并提出了一种用于自动打鼾检测的混合卷积神经网络(CNN)模型。该模型由处理原始信号的一维(1D)CNN和表示通过可见性图方法映射的图像的二维(2D)CNN组成。在我们的实验中,我们的算法实现了89.3%的平均分类准确率、89.7%的平均灵敏度、88.5%的平均特异性和0.947的平均AUC,这超过了根据我们的数据训练的一些最先进的模型。总之,我们的研究结果表明,本研究中提出的方法对日常生活中OSA患者的大规模筛查是有效和有意义的。我们的工作为时间序列分析提供了一个替代框架。
打鼾是一种与呼吸有关的事件,它是由睡眠中上呼吸道解剖结构的振动产生的,如咽壁、软腭、悬雍垂和扁桃体。流行病学研究表明,习惯性打鼾影响了全球9-17%的成年人口,包括约40%的男性和24%的女性。打鼾会严重扰乱打鼾者和共享同一睡眠空间的人的睡眠质量和数量。因此,它经常导致白天嗜睡和注意力不集中,从而增加事故风险,以及某些健康状况,如睡眠障碍、系统性动脉高血压和冠状动脉疾病。然而,由于主观忽视和有限的医疗资源,发达国家约有80-90%的OSA患者仍未得到诊断和治疗,而这一问题的严重性在发展中国家更为明显。一般来说,打鼾发生在仰卧睡觉的时候。对于没有任何其他夜间呼吸道疾病的打鼾者(单纯打鼾),侧卧可以自然缓解。因此,一些小工具已经被开发出来,当打鼾发生时,通过向打鼾者提供某种通知来防止打鼾。此外,打鼾是最早和最普遍的夜间症状之一,70-90%的阻塞性睡眠呼吸暂停(OSA)患者出现打鼾11。研究表明,打鼾声的特征,如强度12、频谱13、音调相关特征14、15、时间和频率相关参数16、规律性参数17和其他一些特征18、19,可以用来描述单纯打鼾者和OSA患者之间的差异,以及OSA的严重程度。此外,与多导睡眠图(PSG)相比,记录音频信号的设备方便、低成本、无接触。因此,打鼾信号已成为评估打鼾者病情的主要生理指标之一。因此,打鼾声的自动检测在学术研究中引起了极大的关注,成为人们关注的一个突出领域。
鉴于OSA的社区流行率不断上升,对医护人员和用品的需求不断增长20,在过去二十年中,研究人员致力于借助计算机技术实现打鼾事件的自动检测21。早期,对原始音频信号进行物理或数学特征的人工提取,随后将其应用于训练分类器,例如基于12个梅尔频率倒谱系数(MFCC)的隐马尔可夫模型(HMM)22,通过主成分分析(PCA)23,24,25基于共振峰频率或低维特征的无监督聚类算法,基于时间和谱域特征的AdaBoost分类器26,共振峰频率的二次判别分析27,由MFCC训练的K近邻(KNN)模型和经验模式分解28。由时间、能量和频域中的40个特征训练的高斯混合模型(GMM)29,基于子带中的平均归一化能量的线性回归模型30,基于时域中的多个特征的支持向量机(SVM)31和基于时间和频谱特征的人工神经网络(ANN)带32,33。结果证明了这些方法在打鼾识别中的有效性。然而,由于打鼾声音的多样性和非线性,确定最佳特征集仍然具有挑战性。
为了应对特征提取的挑战,研究人员成功地将深度学习算法应用于分析各种生理信号,包括心电图(ECG)34、冲击心电图(BCG)35、心电向量图(VCG)36、脑电图(EEG)37、肌电图(EMG)38等,深度学习算法在图像和自然语言的特征表示方面表现出了显著的性能。这些算法在随后表征夜间睡眠呼吸音频信号方面产生了有希望的结果。例如,Nguyen等人39和Çavuşoğlu等人40分别利用多层感知器神经网络(MLP)来区分打鼾声和非打鼾声;Arsenali等人41在提取MFCC后,应用长短期记忆(LSTM)模型对打鼾和非打鼾声音进行分类;Sun等人42提出了SnoreNet,这是一种一维CNN(1D CNN),它直接对原始声音信号进行操作,而无需手动制作特征;Khan等人8开发了一种二维CNN(2D CNN)来分析MFCC的图像,用于自动检测打鼾,并将其应用于可穿戴小工具;姜等人43发现了Mel声谱图和CNN-LSTM-DNN的可选组合用于打鼾识别;Xie等人44使用CNN从恒定Q变换(CQT)频谱图中提取特征,然后使用递归神经网络(RNN)处理顺序CNN输出,将音频信号分类为打鼾或非打鼾事件。
尽管大多数深度学习算法在打鼾和非打鼾发作的分类中表现良好,但这些研究仍存在一些不足。首先,培训数据的可用性有限,缺乏多样性。到目前为止,大多数研究的数据采集都是在睡眠实验室或医院进行的,与家里的私人卧室相比,那里的睡眠环境往往相对安静。这意味着所记录的音频信号的信噪比(SNR)可能更高。在一些在家里进行实验的研究中,只有不到10名参与者42。当使用来自同一时期和少量受试者的这些数据时,训练鲁棒分类器是负面的。其次,打鼾声需要一种新的表现形式。一些研究表明,谱图,特别是梅尔谱,在打鼾检测中的有效性,同时对于包括单个CNN8、LSTM41和混合模型43、44在内的许多分类器获得了几乎相同的精度。可以推断,目前打鼾检测的挑战之一是为原始音频信号找到更好的特征表示。
在本研究中,我们针对上述问题提出了几种解决方案。为了增加样本的多样性,我们设计了一个实验,涉及80多名参与者,持续了十多个月。此外,本实验中的数据采集是在受试者的习惯性睡眠环境下进行的。此外,还引入了可见性图(VG)方法,利用映射图像来表示打鼾声的非线性。然后,提出了一种结合1D-CNN和2D-CNN结构的新型打鼾识别混合模型。其中,1D CNN用于原始信号分析,2D CNN用于VG映射的相应图像。1D CNN和2D CNN生成的特征由下一个全连接层连接和分析。
本文的主要贡献如下:
这项工作建立了一个更大、更多样的夜间睡眠呼吸音频信号数据集,这些信号记录在受试者的私人住宅中。
首先引入VG方法来使用映射图像来表示打鼾声音。
提出了一种用于打鼾声音识别的混合1D-2D CNN框架,该框架比我们数据集上最先进的深度学习模型更准确、更稳健。
我们在2019年3月至2019年12月的实验中记录了88名年龄在12岁至81岁之间的个体,其中包括23名女性和65名男性。在我们的研究之前,他们所有人或其监护人代表他们签署了知情同意书。声音采集设备由我们自己设计,包括以I.MX6ULL为核心的控制模块、高分辨率麦克风(NIS-80V,广东峰火电子科技有限公司;20-2000Hz频率范围 45dB灵敏度)、电源模块以及允许在线和离线数据存储和传输的传输模块。在实验过程中,它被放置在受试者周围,距离范围为20–150厘米,并记录采样频率为16000赫兹的单声道夜间呼吸声。最后,这些信号被保存为一些波形文件,每个文件都是100M。另一方面,便携式PSG以10Hz的采样频率记录了各种生理信号,包括血氧饱和度、血压和呼吸,这些信号由医学专业人员用于诊断受试者的OSAHS。在我们的实验中,受试者包括简单打鼾者和不同严重程度的OSAHS患者。记录的呼吸声的平均持续时间为7小时26分钟。
在本文中,有几个预处理任务用于准备。所涉及的数据处理方法和工作流程如图1所示。
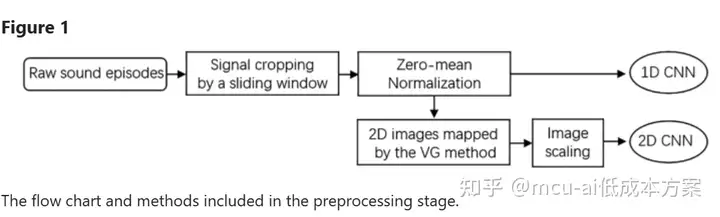
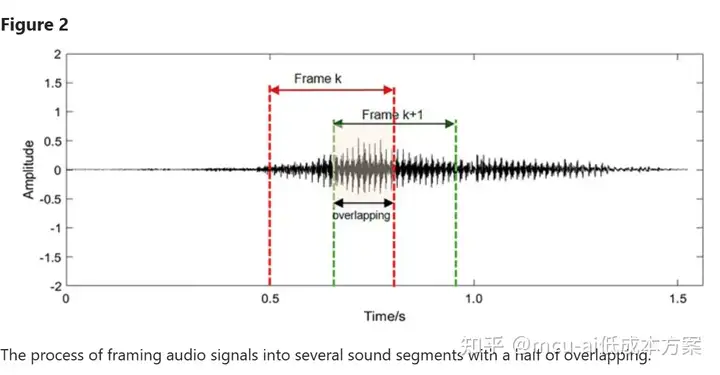
对于我们实验中记录的音频信号,我们使用具有适当宽度的时间窗口来捕捉连续的声音片段。为了尽可能多地保留信息,相邻的时间窗口可能具有一定百分比的重叠。将音频信号帧化成帧的过程如图所示2。值得注意的是,时间窗口的重叠率在不同的音频信号组中有所不同,以防止我们的数据集中数据不平衡的潜在问题45。同时,较短的音频信号帧可以保持CNN模型的紧凑性。在这项研究中,基于打鼾片段的最小持续时间,时间窗口的长度被设置为0.3秒。然后,通过z分数标准化对这些声音片段进行归一化,以提高我们的深度学习模型的精度和收敛速度。
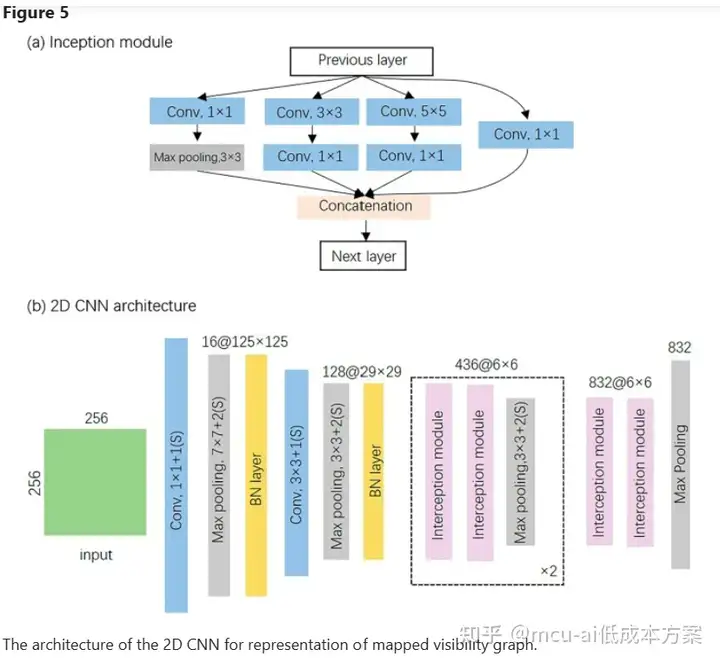
Lacasa等人46提出的可见性图(VG)方法基于可见性的几何原理将时间序列转换为图。研究表明,映射可见性图在结构上继承了级数的几个性质:周期级数转化为正则图,随机级数转化为随机图,分数级数转化为无标度图46,47。因此,它已被广泛用于分析不同领域的时间序列,包括心理学、物理学、医学和经济学48,49,50,51。在本文中,我们将时间序列的关联图视为图像,这使得能够进行基于CNN的分析。
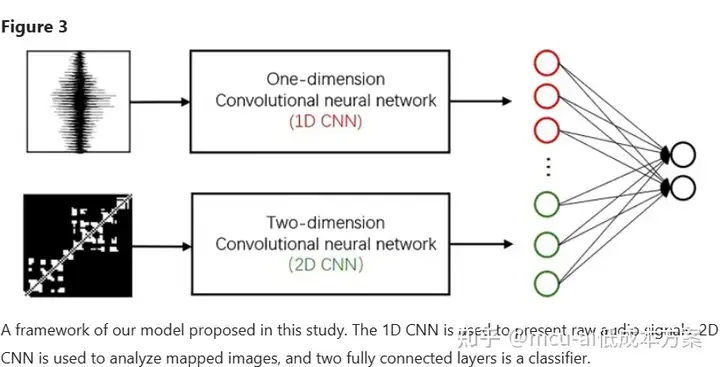
对于声音片段及其相应的可见性图,提出了一种结合1D CNN和2D CNN的深度神经网络来分别表示它们的特征。然后使用两个完全连接的层来将这些统一的特征识别为打鼾声或非打鼾声。框架如图3所示。
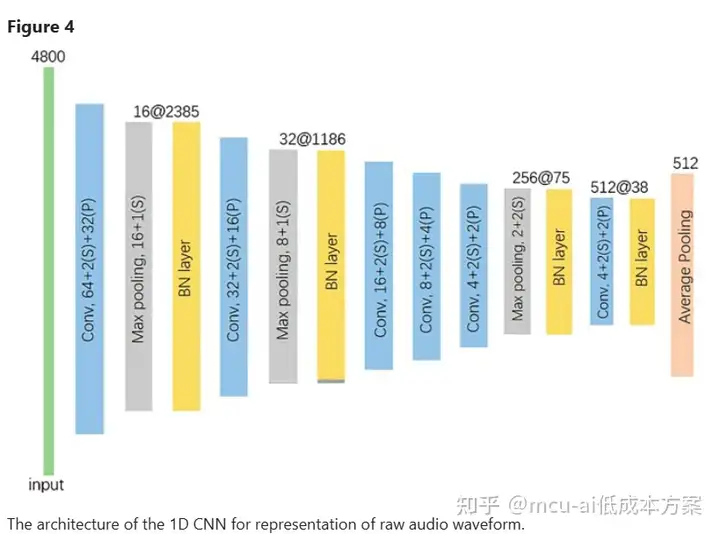
我们使用五重交叉验证策略来训练和测试所提出的模型。88名受试者被随机分为5组,包括3个18岁受试者组和2个17岁受试组。在每项试验中,四组用于训练,其余一组用于测试。通过确保受试者层面的独立性,我们可以降低训练集和测试集中来自同一受试者的数据所导致的高估风险。
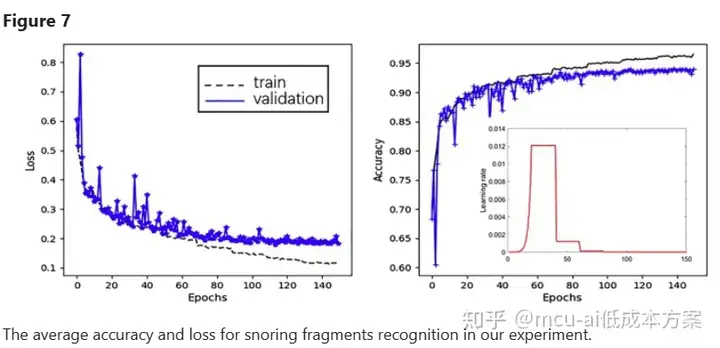
在我们的实验中,使用一批150个样本来训练我们的CNN模型,并对其进行了多达150个时期的训练。学习速率遵循20步逐步预热,从初始值1e−6开始,速率为1.6。之后,每20个时代,它的震级就降低到原来的10%。图7显示了我们的模型在追踪中识别打鼾碎片的损失和准确性的变化。很明显,我们的CNN模型随着迭代次数的增加而逐渐收敛,并在70次迭代后达到稳定。为了避免过度拟合,在迭代过程中,训练在90步处停止。在我们的实验中,我们实现了86.4%至91.2%的准确度,88.1%至91.6%的灵敏度,83.0%至91.8%的特异性,0.908至0.973的AUC。
更多回帖

