

区块链的底层网络技术P2P网络解析
区块链
描述
最近非常火的区块链技术对于大家来说应该并不陌生。但是很多人只是了解区块链技术的一些概念,对其底层的一些技术实现原理可能不是很了解。这篇文章会向你介绍区块链底层采用的通信网络技术及其网络中节点间的通信协议。
区块链的底层网络技术采用的是peer-to-peer网络,简称P2P网络。这是一种分布式网络通信技术,又称 “对等网络”。与传统的客户端/服务器端(client/server, C/S)结构不同的是,在P2P网络中各个节点之间没有主从之分,地位都是对等的,每一个节点既可以是服务器端也可以是客户端。
P2P网络根据其路由查询结构可以分为四种类型,分别是集中式、纯分布式、混合式和结构化模型。这四种类型也代表着P2P网络技术的四个发展阶段。
其中,比特币采用的身世混合式,而现今公链大多采用的是结构化类型。在结构化网络的具体实现上,大都采用DHT(Distributed Hash Table, 分布式哈希表)算法的思想。基于DHT算法思想的具体实现方案有Chord、Pastry、CAN和Kademlia等算法。其中Kademlia算法是以太坊网络使用的算法,本文中我们将对其进行详细描述。
比特币网络
区块链技术最早的使用是在比特币中,前面我们也说到了,比特币网络采用的结构是混合式网络。
比特币网络节点有四个功能,分别是:钱包、挖矿、区块链数据库、网络路由。这四大功能并不是比特币中所有节点都包含,不同类型的节点只包含部分功能,只有比特币核心(Bitcoin Core)节点才会包含所有的这四个功能。
依据其所包含的功能不同节点的类型也不同,但是所有的节点都会包含路由功能,因为所有的节点都要参与校验和广播(传播交易和区块信息),并且发现和维持与其他节点的连接。
除此之外,一些节点包含完整的区块链数据库,数据库中包含所有的交易数据,这类节点被称为 “全节点(Full Block Chain Node)”。全节点可以独立自主的校验所有交易。
还有一些节点只包含了部分区块链数据,一般只包含区块头,这类节点通过“简易支付验证(SPV)”的方式完成对交易的验证,该类节点被称为“SPV节点”或者“轻量级节点”。
矿工节点是通过在特殊的设备上面运行工作量证明(proof-of-work)算法的方式(挖矿)来相互竞争的生成新的区块。
矿工节点中有些节点是全节点,被称为“独立矿工(Solo Miner)”,另外一些矿工节点则需要依赖矿池服务器维护的全节点进行挖矿工作,这类矿工被称为“矿池矿工(Pool Miner)”,矿池矿工与矿池服务器形成矿池(Mining Pool),这是一个局部的集中式网络。它们之间通过特殊的矿池协议进行通信。
目前主流的矿池协议是Stratum协议。钱包功能一般是帮助用户来查看自己的余额、管理公私钥对以及发起交易,在比特币网络中除了比特币核心钱包是全节点之外,大部分的钱包都是轻量级节点。
一个包含了各种节点,不同节点之间运行着比特币主网络协议、Stratum网络协议和其他矿池网络协议的比特币扩展网络如下图所示:
以太坊网络
以太坊作为新一代以区块链作为底层技术的平台,在很多方面与比特币很类似,其节点同样具有钱包、挖矿、区块链数据库和路由四大功能、同样也是由于节点包含不同的功能而将其分为不同的类型、同样除了主网络之外还存在着许多的扩展网络。但是,与比特币不同的是其底层网络结构,比特币主网的P2P网络是无结构的,而以太坊使用P2P网络是有结构的,其P2P网络通过Kademlia(简称Kad)算法来实现。Kad算法作为DHT(分布式哈希表)技术的一种,可以在分布式环境下实现快速而又准确的路由和定位数据的功能。下面我们着重讲一下Kad算法的基本内容。
Kad算法作为一种分布式数据存储及路由发现算法,因其具有简单性、灵活性、安全性的特点,被以太坊用作底层P2P网络的主要算法。下面我们将通过一个例子来形象的说明Kad算法的主要内容及其运行过程。
问题描述与场景假设
我们假设这样一个场景:有若干图书供同学们共享,为了公平起见每个人保存其中的几本,如果你想要看其他的书,就需要向保存这本书的学生来借。那么问题是我们怎么能找到保存着这本书的学生呢?如果一个一个去问的话,效率显然极低。将这个问题放到P2P网络中,就是一个节点如果需要某个资源,它怎么获取这个资源?怎么快速地找到存储该资源的节点?
节点信息
就像我们在学校中对每一个学生有着唯一的标识一样,在Kad算法中给每个节点设置了几个属性来唯一标识一个节点,分别是:节点ID、IP地址、端口号。对应到我们的例子中就是:节点ID对应着学生的学号,IP地址和端口号对应着学生的联系方式(电话号或者家庭住址)。
每个学生(节点)手中有以下信息:
· 分配给其的图书信息(分配到节点上的资源信息)。这里的信息指的是书名的hash值和书本的内容(对于节点资源中理解为资源的索引和资源的内容,将其以《key, value》的形式存储在节点上)。
· 一个通讯录,里面存储着若干条记录,每条记录是某本书的书名hash值和存储这本书的学生的学号和联系方式(一张路由表,每个路由项里面存储着某个资源的索引和存储该资源的节点信息,在Kad算法中,这个路由表称为“K-bucket”,后面我们将对“K-bucket”进行详细的介绍)。值得注意的是,这里每个学生存储的只是一部分同学的联系方式(节点的路由表中只存储着一部分节点的信息)。
资源存储及查找
那么问题来了,我们应该如何将书本分发给各个同学呢(将资源分配到节点上)?
在Kad算法中它是这样做的:将每本书的书名做一个hash计算,将得到书名的hash值作为书本的索引,然后在书本的索引与节点ID之间建立一个映射。如果一本书的hash值为000110,那么这本书就会被分配给学号为000110的学生。(这就要求hash算法的值域和节点ID的取值范围是一致的,在以太坊中,节点ID的是256位二进制。因为以太坊中采用的hash算法是sha-3,结果长度为256位二进制)
那这里就会有人问了,万一某一个学生联系不上了(节点下线或者退出网络)那么岂不是他保存的书(资源)就没有办法获得了?为了解决这个问题,Kad算法采取的方法是将这本书的副本存储在学号与000110最接近的若干位学生手里,这样学号为000111、000101等若干学生手里也会有这本书(在节点中就是将相同的资源存储在与目标节点ID最接近的几个节点上)。
当你需要找到这本书的时候,你只要对书名进行hash,就可以知道你要找的是哪一(几)个学生的联系方式了(对于节点中资源来说,我们只需要计算得到资源索引就可以知道要找哪一个或者哪几个节点了)。
节点定位
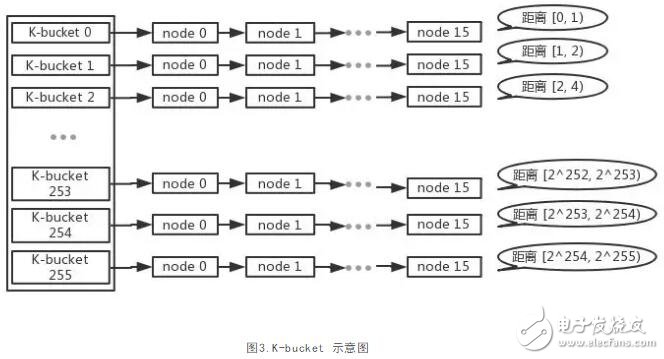
我们已经知道应该找哪一(几)个学生来获得图书,那么接下来的问题就是怎么找到他们的联系方式。这里我们对Kad算法中的路由表--“K-bucket”进行介绍,作为一张路由表,K-bucket里面存储的就是节点的路由信息,但是和一般的路由表不一样的是,在K-bucket中是通过距离来对节点进行分类的,如图3所示。这里提到了节点间的距离问题。我们先来看下在kad算法中是如何计算两节点间的距离的。
Kad算法中节点间的距离是逻辑距离,这个逻辑距离是通过对节点ID进行异或来计算的。目标节点到本节点的距离在[2(i-1), 2i)范围内时,该节点被归为 “K-bucket i”。比如节点ID为000111的节点与节点ID为000110、000011的节点之间的距离计算为:000111 Å 000110 = 000001(十进制1)、000111 Å 000011 = 000100(十进制4)。那么按照上述的算法就是,在节点ID为000111的K-bucket中,节点ID为000110的节点被分配到“K-bucket 1”中、节点ID为000011的节点被分配到“K-bucket 3”中。
其实这种使用异或来计算距离的方式,相当于将整个网络拓扑组织成一颗二叉前缀树如图4所示。这里所有的节点都分布在二叉前缀树的叶子节点上,这种组织形式相当于按其节点ID的每一位对节点距离进行分类。
以图中的编号为110的节点为例,因为节点000、001、010是第三位(从右往左数)与110不同,因此这三个节点就被分配到110 的“K-bucket 3”中,节点ID为100、101的节点因为是第二位(从右往左数)与110不同,因此这两个节点就被分配到110 的“K-bucket 2”中,最后节点ID为111的节点因为是第一位(从右往左数)与110 不同,因此它就被安排到110的“K-bucket 1”中。
回到以太坊中,在前面已经提到了每个节点ID是256位长,因此在以太坊中的节点的K-bucket大小分配为256行每行最多存储16节点的路由信息。
通过前面的内容我们已经知道了找到另一个学生联系方式(节点间的距离计算)的方法以及每个学生存储的通讯录是怎样的的结构(节点中K-bucket的存储结构)。那我们就来找一本书来看一下在Kad算法中查找某一确定节点的方式是怎样的。
学号为000111 的A同学想要找一本名叫《西游记》的书(节点ID为000111的节点想要找到某一个特定的资源),他首先通过对书名计算hash值来得到这本书的索引(得到资源的索引),经过计算得到《西游记》的hash值为001011,那么他就知道这本书被保存在学号为001011的B学生手里。接着,A同学就计算与这个学生的距离来查找他的通讯录(节点计算目标节点与自己的距离,在K-bucket中查找否有目标节点),经过异或计算:000111 &001011 = 001100(十进制12),经过计算发现这个距离12位于[23, 24)这个区间中,因此A同学就去他的通讯录的第4行去找有没有B同学的联系方式:
· 如果有--就直接联系B向他借书;
· 如果没有--就随便找一个也在第4行的C同学与其取得联系,让C同学在自己的通讯录中使用同样的方法找一下是否有B同学的联系方式。这里这样做的原因是C同学学号的第四位(从右往左数)一定与B同学学号的第四位一样,因此逻辑上C同学距离B同学的距离一定比A同学距离B同学要近。那么就会出现两种情况:
--如果C同学有B同学联系方式,那么他就将B同学的联系方式告诉A同学。
--如果没有,那么C同学就将与B同学在通讯录的同一行的另一位D同学的联系方式告诉A同学,之后A同学在将D同学的联系方式存储起来后与D同学联系,进行下一步查找。以此递归下去直到找到B同学为止。
这时有人就会问,上面提到一本书不是不仅仅保存在一个同学手里吗?我们为什么非要就找这一个同学?这是因为上面我们描述的是通过一个确定的节点ID来查找另一个节点的过程,对应着Kad算法中的FIND_NODE指令,当然问题中提到的做法是Kad算法中的另一个指令FIND_VALUE。这个指令是通过资源的索引值来搜索指定的资源,其操作过程与FIND_NODE非常类似,最后终止的条件就是有某一个节点返回了我们要查找的资源数据即可。
值得一提的是,K-bucket的这种更新机制是只有老的节点失效后,才会将新节点加入到K-bucket中,这样做会保证在线时间长的节点会有更大概率被保留,增加了网络的稳定性,避免网络中节点因大量新节点加入更新K-bucket而出现拒绝服务的情况。
总结
以上就是本文分享的所有内容,我们先介绍了P2P网络的基本知识,然后介绍了比特币网络的相关内容,最后着重介绍了以太坊网络中Kademlia算法的相关内容。
Trias中的goosip协议与Kad算法比较相关。相对于我们今天讲的Kad算法来说,二者对应的层面是不同的,Kad算法更接近底层,而goosip协议偏高层一点,底层Kad算法在开始将节点的路由表(K-bucket)创建好为goosip协议做准备,当goosip协议挑选a个节点进行广播同步信息时,Kad算法可以保证这a个节点都收到消息并将其存储下来。
-
P2P网络工作的步骤是什么?2020-03-16 0
-
混合式P2P网络事务管理策略2009-04-16 569
-
P2P协议通用仿真器模型设计2009-08-13 459
-
基于连接跟踪的P2P协议识别方法研究2009-08-28 511
-
基于兴趣的P2P网络应用研究2009-12-18 563
-
一种基于本体的P2P网络搜索方法2009-12-30 538
-
与P2P技术相关的信息安全问题2010-02-06 625
-
基于P2P模式的网络信息交互平台的研究与设计2010-08-31 648
-
P2P网络资源搜索Chord算法2011-01-06 1099
-
无结构P2P网络搜索及改进2011-06-28 695
-
基于JXTA平台的P2P网络传输方案2011-08-17 2162
-
CDN验证系统在P2P网络中的应用2012-04-13 933
-
P2P网络摄像机系统及运营2017-01-14 970
-
区块链P2P网络协议的类型及演进2019-04-23 6111
-
区块链的协议分层P2P网络介绍2019-06-24 3067
全部0条评论

快来发表一下你的评论吧 !
